大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据集成数据源列表MySQL配置 MySQL 数据源
大数据研发治理套件用户指南数据集成数据源列表MySQL配置 MySQL 数据源

MySQL 数据源为您提供读取和写入 MySQL 的双向通道数据集成能力,实现不同数据源与 MySQL 之间进行数据传输。本文为您介绍 DataSail 的 MySQL 数据同步的能力支持情况。
说明
火山引擎 VeDB-MySQL 数据库与 MySQL 数据源配置基本一致,您可参考本文进行 VeDB 数据源任务的配置操作。
1 支持的版本
- MySQL 离线读写:
- 支持火山引擎云数据库 MySQL 版;
- 支持自建 MySQL 5.6.x、MySQL 5.7.x、MySQL 8.0.x。
- VeDB MySQL 离线读写
- 仅支持火山引擎云数据库 VeDB MySQL 8.0 版本。
2 使用前提
2.1 账号与权限
子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见管理成员。对账号及其相关权限的要求如下:
建议创建专用同步账号
为保障安全性和可追溯性,建议为数据集成任务创建一个专用的 MySQL 账号,避免使用业务账号或高权限账号进行数据同步。离线读 MySQL 数据时,配置的账号需拥有同步表的读(SELECT)权限。授权 SQL 示例如下:
-- 授予指定库所有表的读权限 GRANT SELECT ON your_database.* TO 'datasail_user'@'%'; -- 或授予指定表的读权限 GRANT SELECT ON your_database.your_table TO 'datasail_user'@'%';离线写 MySQL 数据时,配置的账号需拥有同步表的写(INSERT、DELETE、UPDATE)权限。授权 SQL 示例如下:
GRANT INSERT, UPDATE, DELETE ON your_database.* TO 'datasail_user'@'%';数据同步解决方案(实时 Binlog 读取) 使用该 MySQL 数据源,配置实时方案读取 Binlog 时,需要先执行以下授权 SQL 命令给配置的账号:
说明
MySQL 5.x 版本仅提供了
IDENTIFIED BY语法,该语法在 MySQL 8.0 中已被移除,直接执行会报错,下面按版本区分提供正确的授权方式。MySQL 5.6 / 5.7 版本
GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'datasail_user'@'%' IDENTIFIED BY 'your_password';MySQL 8.0 及以上版本
-- 第一步:创建用户(如用户已存在可跳过) CREATE USER 'datasail_user'@'%' IDENTIFIED BY 'your_password'; -- 第二步:授予权限 GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'datasail_user'@'%'; -- 第三步:刷新权限 FLUSH PRIVILEGES;
数据同步解决方案使用 VeDB 数据源配置时,需给数据源中配置的用户执行以下授权 SQL 命令:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user';
2.2 Binlog 服务端配置(实时同步必读)
注意
如果您需要使用实时同步(解决方案中的 Binlog 读取),必须在 MySQL 服务端完成以下配置。配置不正确会导致实时同步任务启动失败或数据丢失。
第一步:检查并修改 MySQL 配置文件(my.cnf / my.ini)
在 MySQL 配置文件的[mysqld]节下,添加或修改以下参数:[mysqld] # 【必须】开启 Binlog,并指定日志文件前缀名 log-bin = mysql-bin # 【必须】设置 Binlog 格式为 ROW(行级记录),DataSail 仅支持 ROW 格式 binlog_format = ROW # 【必须】设置唯一的 server-id,取值范围 1 ~ 4294967295,集群内不能重复 server-id = 1 # 【推荐】Binlog 日志保留天数,建议至少保留 7 天 # MySQL 5.x / 8.0 早期版本使用: expire_logs_days = 7 # MySQL 8.0.11 及以上版本推荐使用(单位秒,604800 = 7天): # binlog_expire_logs_seconds = 604800 # 【可选】启用 GTID 模式,便于同步位点管理和故障恢复 # gtid_mode = ON # enforce_gtid_consistency = ON第二步:重启 MySQL 服务
修改配置文件后,需要重启 MySQL 服务使配置生效:sudo systemctl restart mysqld注意
- 火山引擎云数据库 MySQL 版已默认开启 ROW 格式 Binlog,通常无需手动配置。您可在控制台 > 参数配置中确认。
- 自建 MySQL 数据库需要手动完成上述配置。
第三步:验证配置是否生效
-- 检查 Binlog 是否开启 SHOW VARIABLES LIKE 'log_bin'; -- 期望结果:ON -- 检查 Binlog 格式 SHOW VARIABLES LIKE 'binlog_format'; -- 期望结果:ROW -- 检查 server-id SHOW VARIABLES LIKE 'server_id'; -- 期望结果:非 0 的正整数 -- 检查 Binlog 过期时间 SHOW VARIABLES LIKE 'expire_logs_days'; -- 期望结果:大于等于 7 -- 查看当前 Binlog 位点 SHOW MASTER STATUS;
2.3 读副本建议
对于生产环境的大表全量同步,建议在 MySQL 只读副本(Read Replica) 上进行数据采集,而非直接读取主库,以避免对线上业务造成性能影响。
- 火山引擎云数据库 MySQL 版支持创建只读实例,相关操作详见云数据库 MySQL 只读实例文档。
- 自建 MySQL 可通过主从复制搭建只读副本。
注意
使用只读副本时,请确保副本上的 Binlog 同样已开启并配置为 ROW 格式。
2.4 网络连通
确保集成同步任务使用的独享数据集成资源组,具有 MySQL 数据库节点的网络访问能力。网络互通方案详见网络连通解决方案。
- 数据源为 RDS MySQL 云数据库实例时,需要将集成资源组所在 VPC 中的 IPv4 CIDR 地址添加到 MySQL 访问白名单中:
注意
- 如果 MySQL 数据源实例所在的 VPC 和独享集成资源组所在的 VPC 相同时,您仅需将 VPC 中的 IPv4 CIDR 地址添加到 MySQL 访问白名单中;
- 如果 MySQL 数据源实例所在的 VPC 和独享集成资源组所在的 VPC 不同时,您需要先通过 CEN 云企业网打通两个 VPC 网络,然后将集成资源组 VPC 和 MySQL 所在 VPC 中的两个 IPv4 CIDR 地址,均添加到 MySQL 访问白名单中。
- 确认集成资源组所在的 VPC:
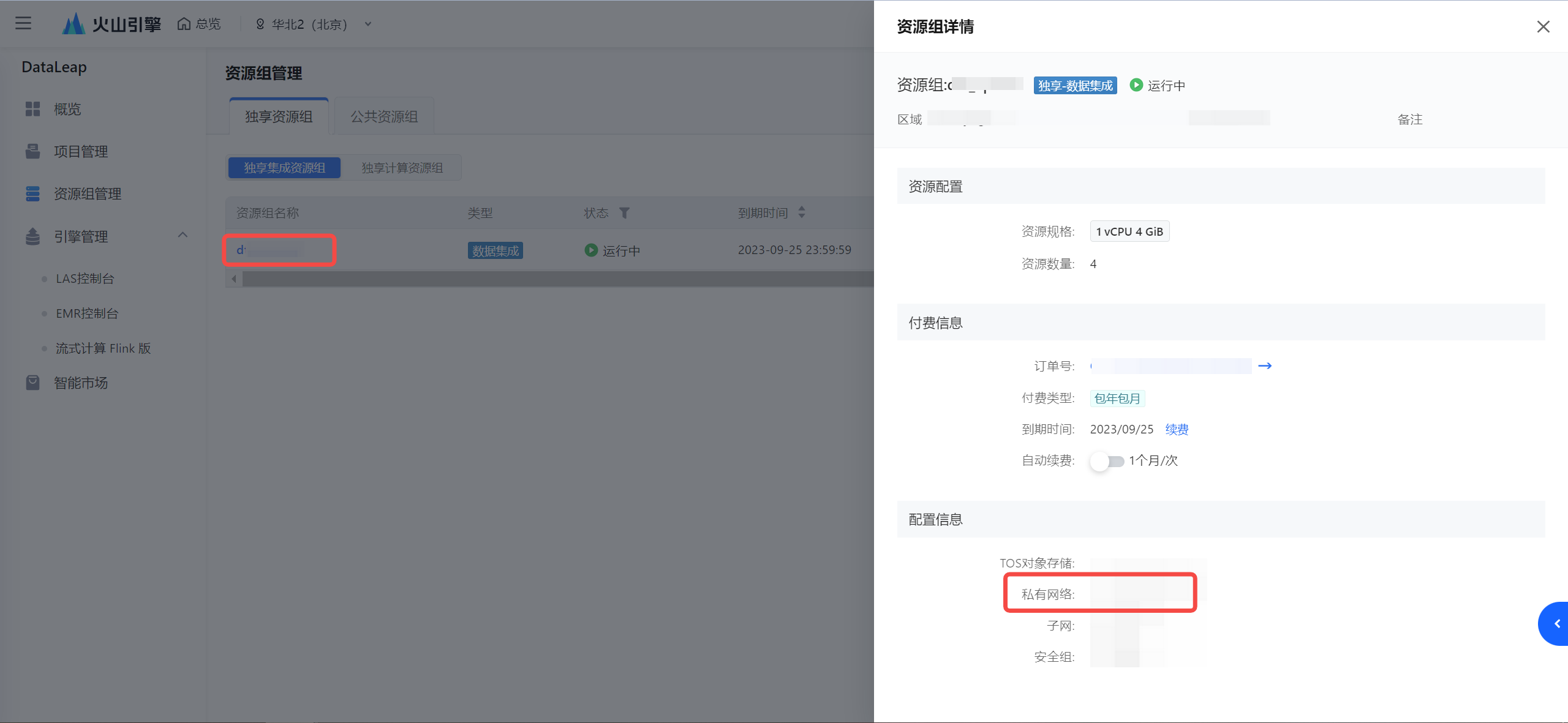
- 查看 VPC 的 IPv4 CIDR 地址:
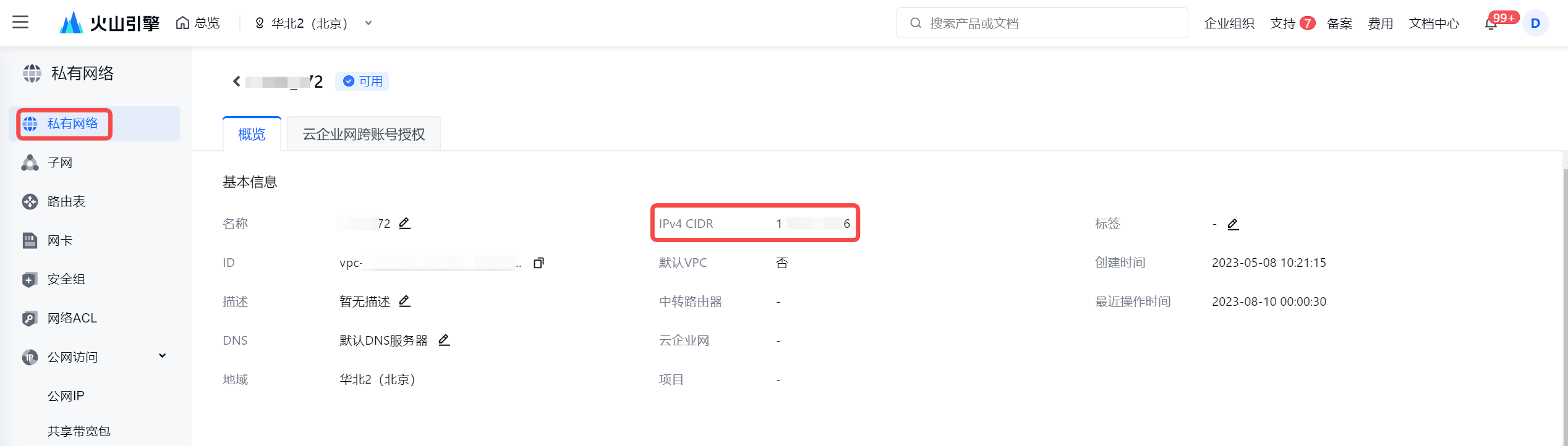
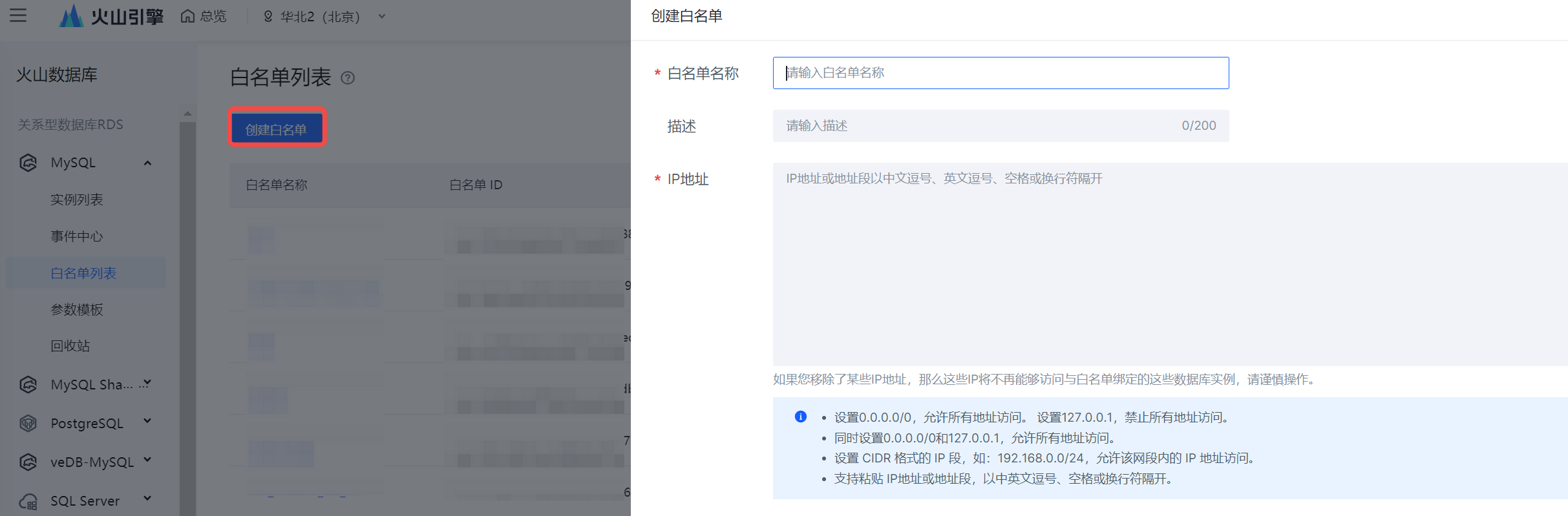
- 将获取到的 IPv4 CIDR 地址添加进 MySQL 数据库白名单中,添加操作详见创建白名单。
- 数据源为公网自建数据源,需通过公网形式访问:
- 集成资源组开通公网访问能力,操作详见开通公网。
- 并将公网 IP 地址,添加进 MySQL 数据库白名单中。
注意
- DataSail 不支持通过负载均衡器(Load Balancer)连接 MySQL 数据库,请使用数据库实例的直连地址。
- 如需通过 SSH 隧道连接内网数据库,请先配置 SSH 数据源,并在 MySQL 数据源中关联 SSH 连接信息。详见配置 SSH 数据源。
2.5 连接安全(TLS/SSL)
注意
对于跨公网传输的数据同步场景,强烈建议启用 TLS/SSL 加密连接,防止数据在传输过程中被窃取或篡改。
- 火山引擎云数据库 MySQL 版默认支持 SSL 连接,您可在实例详情中下载 CA 证书。
- 自建 MySQL 需自行配置 SSL,详见 MySQL 官方文档 - Using Encrypted Connections。
说明
在 DataSail 连接串形式中,您可通过高级参数 connection_parameters 追加 SSL 相关参数,例如:useSSL=true、requireSSL=true 和 verifyServerCertificate=true。
3 支持的字段类型
当前主要字段类型支持情况如下:
字段类型 | 离线读(MySQL Reader) | 离线写(MySQL Writer) |
|---|---|---|
TINYINT | 支持 | 支持 |
SMALLINT | 支持 | 支持 |
INTEGER | 支持 | 支持 |
BIGINT | 支持 | 支持 |
FLOAT | 支持 | 支持 |
DOUBLE | 支持 | 支持 |
DECIMAL | 支持 | 支持 |
REAL | 支持 | 支持 |
VARCHAR | 支持 | 支持 |
JSON | 支持 | 支持 |
TEXT | 支持 | 支持 |
MEDIUMTEXT | 支持 | 支持 |
LONGTEXT | 支持 | 支持 |
VARBINARY | 支持 | 支持 |
BINARY | 支持 | 支持 |
TINYBLOB | 支持 | 支持 |
MEDIUMBLOB | 支持 | 支持 |
LONGBLOB | 支持 | 支持 |
ENUM | 支持 | 支持 |
Blob | 支持 | 支持 |
SET | 支持 | 支持 |
BOOLEAN | 支持 | 支持 |
BIT | 支持 | 支持 |
DATE | 支持 | 支持 |
DATETIME | 支持 | 支持 |
TIMESTAMP | 支持 | 支持 |
TIME | 支持 | 支持 |
YEAR | 支持 | 支持 |
MULTIPOLYGON | 支持 | 不支持 |
LINESTRING | 不支持 | 不支持 |
POLYGON | 不支持 | 不支持 |
MULTIPOINT | 不支持 | 不支持 |
MULTILINESTRING | 不支持 | 不支持 |
GEOMETRYCOLLECTION | 不支持 | 不支持 |
说明
MySQL 空间数据类型(Geometry 系列)目前支持有限:仅 MULTIPOLYGON 支持离线读取,其他空间类型暂不支持。如您有空间数据同步需求,建议在源端将空间数据转换为 WKT(Well-Known Text)文本格式后,通过 VARCHAR/TEXT 字段进行同步。
4 数据源注册
新建数据源操作详见2 新建数据源,下面为您介绍不同接入方式的 MySQL 数据源配置相关信息。
说明
- 在多环境模式的项目下,数据源能够开发环境与生产环境实现注册隔离。并且在进行离线集成任务配置时,多环境下的数据源信息均需要进行注册。
- 网络相关配置详见上方2 使用前提说明。
4.1 配置信息填写
火山引擎 MySQL 数据源
参数
说明
基本配置
数据源类型
MySQL
接入方式
火山引擎 MySQL
数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
RDS 实例 ID
火山引擎云数据库MySQL的实例ID,下拉选择。
数据库名
下拉选择实例下,已创建的 MySQL 数据库名称。
用户名
有权限访问数据库的用户名信息。
密码
输入用户名对应的密码信息。
连接串形式 MySQL 数据源
参数
说明
基本配置
数据源类型
MySQL
接入方式
连接串
数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
主机名或IP地址
填写 MySQL 数据库的主机名称或者 IP 地址。
也支持填写通过火山引擎私网解析(Private Zone)映射的自定义域名。详见私网解析说明。端口
主机的端口号。MySQL 默认端口为 3306。
数据库名
输入已创建的 MySQL 数据库名称。
用户名
有权限访问数据库的用户名信息。
密码
输入用户名对应的密码信息。
4.2 测试连通性
数据源注册完成后,单击测试连通性按钮。系统将依次检查以下项目:
测试项 | 说明 | 常见失败原因 |
|---|---|---|
网络连通 | 资源组能否访问 MySQL 主机和端口 | 白名单未配置、VPC 未打通、防火墙拦截 |
认证校验 | 用户名和密码是否正确 | 密码错误、账号不存在、Host 限制 |
权限检查 | 账号是否具备所需权限 | 缺少 SELECT / REPLICATION 权限 |
数据库存在性 | 指定的数据库是否存在 | 数据库名拼写错误 |
如果测试失败,请根据错误提示逐项排查。您也可以在 MySQL 客户端执行以下命令自行验证:
-- 验证账号是否能连接 -- mysql -h <host> -P <port> -u <user> -p -- 验证权限 SHOW GRANTS FOR 'datasail_user'@'%'; -- 验证 Binlog 配置(实时同步场景) SHOW MASTER STATUS; SHOW VARIABLES LIKE 'binlog_format';
5 同步方式选择指引
DataSail 提供多种 MySQL 数据同步方式,请根据您的业务场景选择合适的方式:
同步方式 | 适用场景 | 实时性 | 对源库影响 | 操作入口 |
|---|---|---|---|---|
离线全量同步 | 首次迁移、定期全量刷新 | 低(按调度周期) | 较大(需全表扫描) | 数据开发 > 数据集成 > 新建任务 |
离线增量同步(带过滤条件) | 按时间字段增量拉取 | 低(按调度周期) | 较小 | 数据开发 > 数据集成 > 新建任务 |
实时整库同步(解决方案) | 整库实时入仓、CDC 场景 | 高(秒级延迟) | 极小(仅读取 Binlog) | DataSail 控制台 > 数据同步方案 > 新建 |
流式写入 | 实时写入 MySQL 目标表 | 高 | N/A(作为目标端) | 数据开发 > 数据集成 > 新建任务 |
下面列举解决方案和单表任务同步操作时,在不同维度的差异:
对比维度 | 单表任务(数据集成入口) | 解决方案(数据同步方案入口) |
|---|---|---|
操作入口 | 数据开发 > 数据集成 > 新建任务 | DataSail 控制台 > 数据同步方案 > 新建 |
同步粒度 | 单表级别,需逐表配置 | 整库级别,一次选择最多 2000 张表 |
同步模式 | 离线批式读/写、流式写(需分别创建) | 全增量一体(自动创建全量批任务 + 增量流任务) |
目标表创建 | 需手动提前创建 | 支持自动建表、使用已有表 |
DDL 同步 | 不支持 | 支持新建表、新增列、删除列、重命名列、修改列类型等 DDL 策略 |
数据缓存 | 不支持 | 支持通过 Kafka/BMQ/DataSail 内置 Topic 缓存,提升稳定性 |
数据转换 | 支持基础模式/转换模式 | 支持自定义 SQL 转换规则 |
适用场景 | 定期同步少量表、简单 ETL | MySQL 实时入仓、整库迁移、CDC 场景 |