近期AIGC如同“上了热搜”一般,火热程度居高不下。当然除了名头格外响亮,突破也是绝对斐然:输入自然语言就可自动生成图像、视频甚至是3D模型,你说意不意外?
但在音频音效的领域,AIGC的“福利”似乎还差了一些。由于高自由度音频生成需要依靠大量文本-音频对数据,同时长时波形建模还有诸多困难。为了解决上述疑难,浙江大学与北京大学联合火山引擎,共同提出了一款创新的文本到音频的生成系统,即Make-An-Audio。TA可以将自然语言描述作为输入,而且是任意模态(例如文本、音频、图像、视频等)均可,同时输出符合描述的音频音效,广大网友很难不为其可控性以及泛化性点赞。
论文链接:https://arxiv.org/abs/2301.12661
项目链接:https://text-to-audio.github.io
短短两天,Demo视频在Twitter上获得了45K的播放量。
2023年除夕后,以“Make-An-Audio”、 MusicLM等大量音频合成文章涌现,48小时内就已经有4篇论文发布。
广大网友们纷纷表示,AIGC音效合成将会改变电影、短视频制作的未来。
更有群众发出这样的感叹:“audio is all you need……”
这款“网红”模型的内在技术原理究竟是?
深度解析“网红”模型的神奇内在,还要回到在数据稀少情况下的音频-自然语言客观问题上。对此,浙大北大联合火山引擎共同提出了Distill-then-Reprogram文本增强策略,即使用教师模型获得音频的自然语言描述,再通过随机重组获得具有动态性的训练样本。
具体来说,在Distill环节中,使用音频转文本与音频-文本检索模型,找到语言缺失(Language-Free)音频的自然语言描述候选(Candidate),通过计算候选文本与音频的匹配相似度,在阈值下取得最佳结果作为音频的描述。该方法具有强泛化性,且真实自然语言避免了测试阶段的域外文本。“在Reprogram环节中,我们从额外的事件数据集中随机采样,并与当前训练样本相结合,得到全新的概念组合与描述,以扩增模型对不同事件组合的鲁棒性。”研究团队表示。 Distill-then-Reprogram文本增强策略框架图
Distill-then-Reprogram文本增强策略框架图
如上图所示,自监督学习已经成功将图片迁移到音频频谱,利用了频谱自编码器以解决长音频序列问题,并基于Latent Diffusion生成模型完成对自监督表征的预测,避免了直接预测长时波形。 Make-An-Audio模型系统框架图
Make-An-Audio模型系统框架图
此外在研究中团队还探索了强大的文本条件策略,包括对比式Contrastive Language-Audio Pretraining (CLAP)、语言模型(LLM) T5及BERT等,验证了CLAP文本表征的有效性和计算友好性。同时还首次使用CLAP Score来评估生成的音频,可以用于衡量文本和生成场景之间的一致性;使用主、客观相结合的评估方式,在benchmark数据集测试中验证了模型的有效性,展示了模型出色的零次样本学习(Zero-Shot)泛化性等。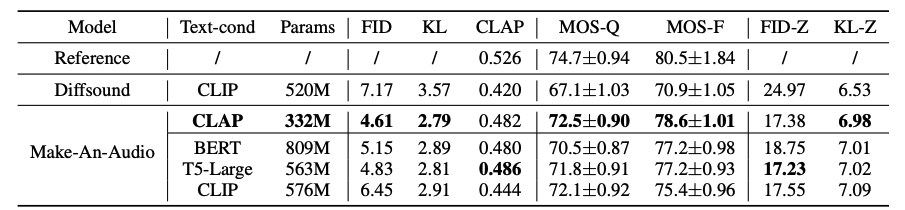 Make-An-Audio与基线模型主客观评测实验结果
Make-An-Audio与基线模型主客观评测实验结果
神奇模型的应用前景知多少?
总体来看,Make-An-Audio模型实现了高质量、高可控性的音频合成,并提出了“No Modality Left Behind”,对文本条件音频模型进行微调(finetune),即能解锁对任意模态输入的音频合成(audio/image/video)。 Make-An-Audio首次实现高可控X-音频的AIGC合成,X可以是文本/音频/图像/视频
Make-An-Audio首次实现高可控X-音频的AIGC合成,X可以是文本/音频/图像/视频
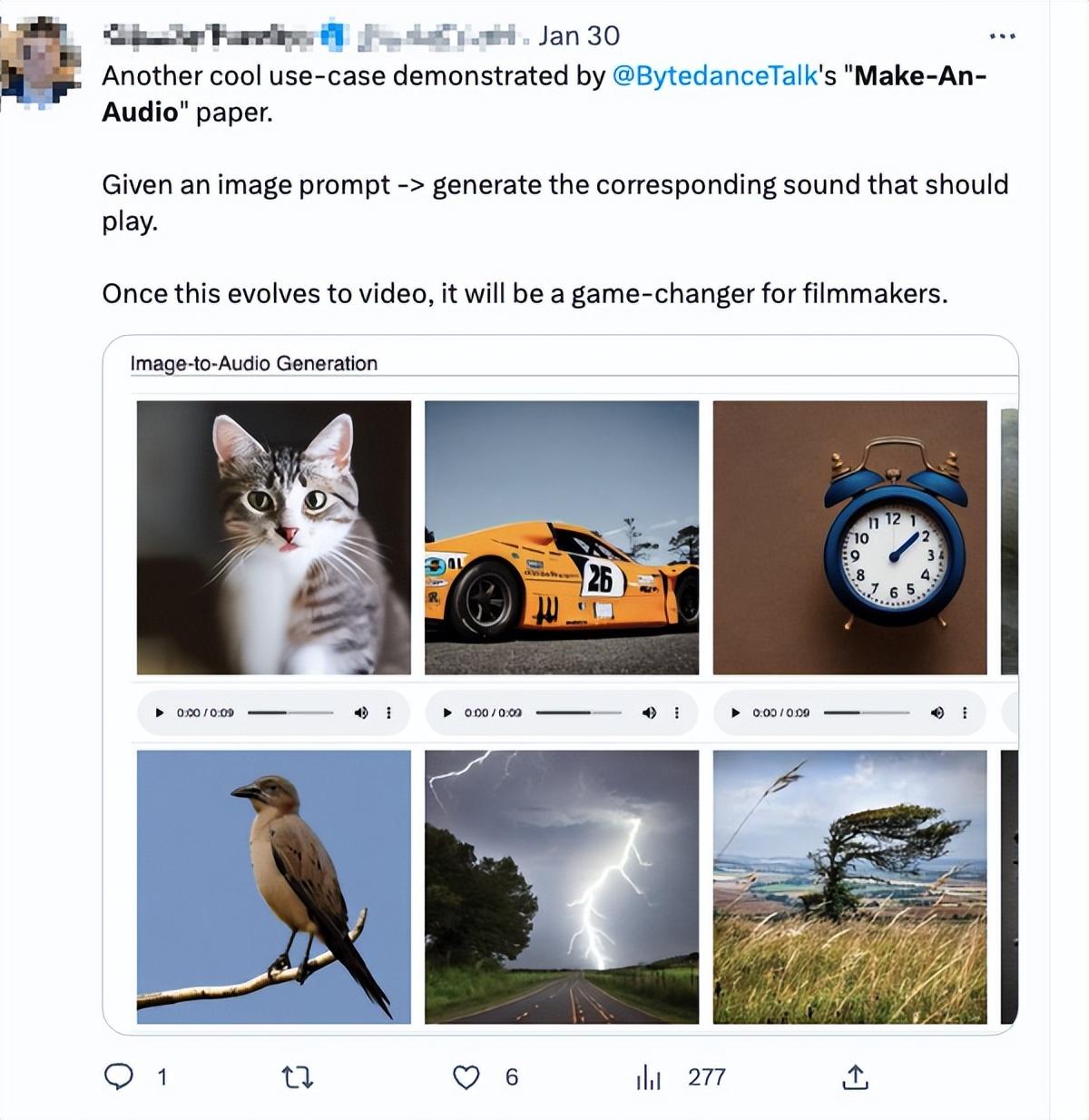
在视觉指导的音频合成上,Make-An-Audio以CLIP文本编码器为条件,利用其图像-文本联合空间,能够直接以图像编码为条件合成音频。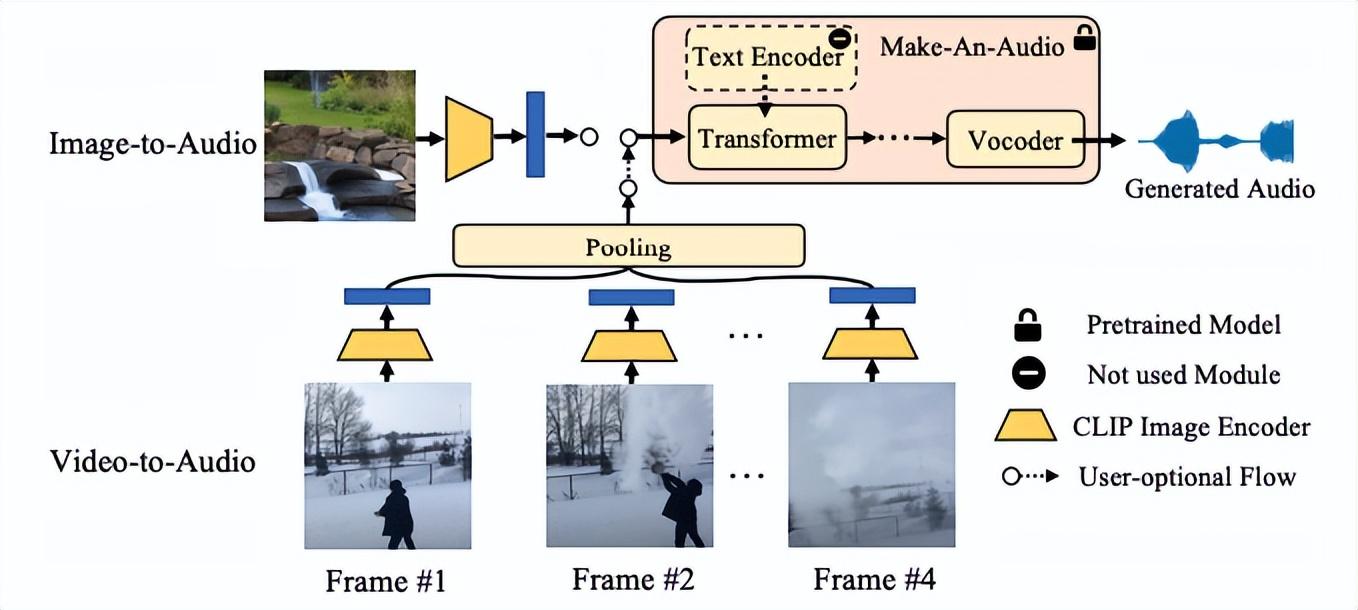 Make-An-Audio视觉-音频合成框架图
Make-An-Audio视觉-音频合成框架图
可以预见的是,音频合成AIGC将会在未来电影配音、短视频创作等领域发挥重要作用,而借助Make-An-Audio等模型,或许在未来人人都有可能成为专业的音效师,都可以凭借文字、视频、图像在任意时间、任意地点,合成出栩栩如生的音频、音效。但现阶段Make-An-Audio也并不是完美无缺的,可能由于丰富的数据来源以及不可避免的样本质量问题,训练过程中难免会产生副作用,例如生成不符合文字内容的音频,Make-An-Audio在技术上被定位是“辅助艺术家生成”,可以肯定的一点,AIGC领域的进展确实令人惊喜。
火山引擎语音合成产品技术能力来自于字节跳动AI Lab Speech & Audio智能语音与音频团队。火山引擎将打磨多年的语音技术能力面向市场并开放给外部企业,提供行业领先的AI语音技术能力以及卓越的全栈语音产品解决方案,包括音频理解、音频合成、虚拟数字人、对话交互、音乐检索、智能硬件等。火山引擎的语音识别和语音合成覆盖了多种语言和方言,多篇技术论文入选各类AI顶级会议,为抖音、剪映、飞书、番茄小说、Pico等业务提供了领先的语音能力,并适用于短视频、直播、视频创作、办公以及穿戴设备等多样化场景。