智能推荐平台
智能推荐平台






- 文档首页
 智能推荐平台用户指南特征工程数据处理
智能推荐平台用户指南特征工程数据处理

数据处理模块中,用户可以使用到经过数据管理校验的合法数据,创建调度任务对这些数据的进行进一步加工处理并最终得到生产特征所需的格式。
上游数据管理创建的原始表不支持修改,以确保原始数据的正确性。由用户创建并可修改的数据表为中间表。目前数据处理支持用户自定义创建如下种类的数据表,也能创建调度任务向这些表中写入数据。
- 表格类:也叫 table 表,按照 table 格式进行数据读写。
- 键值类:也叫 kv 表,按照 key-value 格式进行数据读写。
- 消息队列类:流式数据读写,需要定义消息队列的 Partition 数量。
- 窗口聚合类:用于存储窗口聚合类行为统计数据,例如某用户在某段时间内对某个商品的点击次数/某用户在某段时间内点击过的商品列表等。
新建表
新建表格类、键值类、消息队列类表时支持基于其他表配置、表单配置或者 SQL 配置三种方式来配置表字段。键值类表往往是基于用户或物品的表格类表来创建,这时通过“基于其他表配置”,并选择上游表格类表,可以一键填入所有待生成的字段。创建键值类表时推荐给所有非主键字段增加前缀,因为数据存储方式限制了应用内即使不同表之间的字段也不能重名。
新建窗口聚合类表时,需要选择统计维度、数据加工方式、统计类型。统计维度分为:用户、物品和父物品。选择父物品维度可创建父物品类型的窗口聚合类特征,在相关推荐场景中,推荐的内容依赖父物品类型的窗口聚合类特征。选择用户及父物品维度时,Recent 类窗口聚合类特征还可配置是否去重。
表类型和主键类型之间的关系
- 行为表
- 含父物品时(可作为相关推荐场景的行为数据源使用):需同时包含 user 主键,item 主键,p_item 主键。
- 不含父物品时:需同时包含且仅包含 user 主键,item 主键。
- 父物品表:需包含 p_item 主键。
- 物品表:需包含 item 主键。
- 用户表:需包含 user 主键。
窗口聚合类表/任务的“类目/维度”的含义
创建窗口聚合类表及窗口聚合类任务时会发现“类目/维度”的描述,“类目/维度”在产品内通常指用户或物品数据表中存储属性或特征的字段,具体如下:
- 流式窗口聚合类表/任务:指流式样本中的物品特征字段。
- 批式(天级)窗口聚合类表/任务:指物品表中物品属性字段。
查看表
在【数据处理】-【表管理】页面可查看到所有的表,单击表名称,可查看表的基础信息、表字段、表分区和建表语句。
- 基础信息:表类型、表备注、数据更新时间、关联任务等。
- 表字段:字段名称、字段类型、主键字段。
- 分区:仅表格类可查看分区,原始表的分区字段为 ds,字段类型为 string;新建表时,系统将自动添加分区字段 ds,字段类型为 string。
- 建表语句:支持通过复制建表语句快速建表,即提供基于SQL建表方式。其中,表格类、键值类、消息队列类支持该方式,窗口聚合类表不支持。
预览表
在【数据处理】-【表管理】页面可查看到所有的表,单击表操作列的【预览】按钮。
- 表格类、消息队列类、窗口聚合类天级数据,支持用户预览前10行数据。
- 窗口聚合类表数据,支持指定字段名称、主键 id来查询特定的字段值。批式(天级)窗口聚合数据还支持通过查询起始时间、Top来指定数据范围。
- 键值类,支持用户输入【主键 ID 值】( item_id 或者 user_id 的具体值),返回该 kv 类中间表的所有【字段名称】和对应的【字段值】。
任务管理可以通过 SQL 任务或者表单配置对特定的数据进行处理计算。
任务类型及对应的说明如下:
任务类型 | 任务说明 | 配置方式 |
|---|---|---|
表格类 | 通过批式 SQL 对表格类表字段进行数据处理。原始特征的数据来源为表格类时,既可用于生成离线样本,也可用于在线预估服务。 | IDE |
消息队列类 | 通过流式 SQL 对消息队列表数据进行 ETL 处理,将处理结果输出到下游的 kv 表或者消息队列表用于后续的其他环节处理。 | IDE |
窗口聚合类 | 用于生产窗口聚合类特征数据,例如某用户在某段时间内对某个商品的点击次数/某用户在某段时间内点击过的商品列表等。支持按照天/小时/分钟级时间窗口进行统计。 | 表单 |
kv 导入类 | kv 导入类任务,kv 类表仅用于在线预估服务,不可用于生成离线样本。kv 类表需要通过表格类表或天级窗口聚合类表进行导入,并配置字段映射关系。 | 表单 |
新建任务
新建任务时需要选择任务类型:数据处理或数据导入。
表格类/消息队列类任务
SQL语法
批式任务采用 ANSI SQL 2011 标准,流式任务兼容 Flink SQL 语法。具体支持的 SQL 语法说明参见
任务配置
依赖关系配置:
- 添加上游依赖任务:若某任务需要依赖其他任务的数据产出,则需要添加上游依赖任务。
- 跨周期自依赖:若某任务需要依赖自己上一周期的数据产出,则跨周期自依赖设置为“是”即可。例如当天任务的执行,依赖昨天的运行结果。默认为否。
任务调试
点击SQL编辑框的右上角“调试”按钮,批式任务可选择调试某一天的数据,流式任务可以选最新的若干条数据进行调试。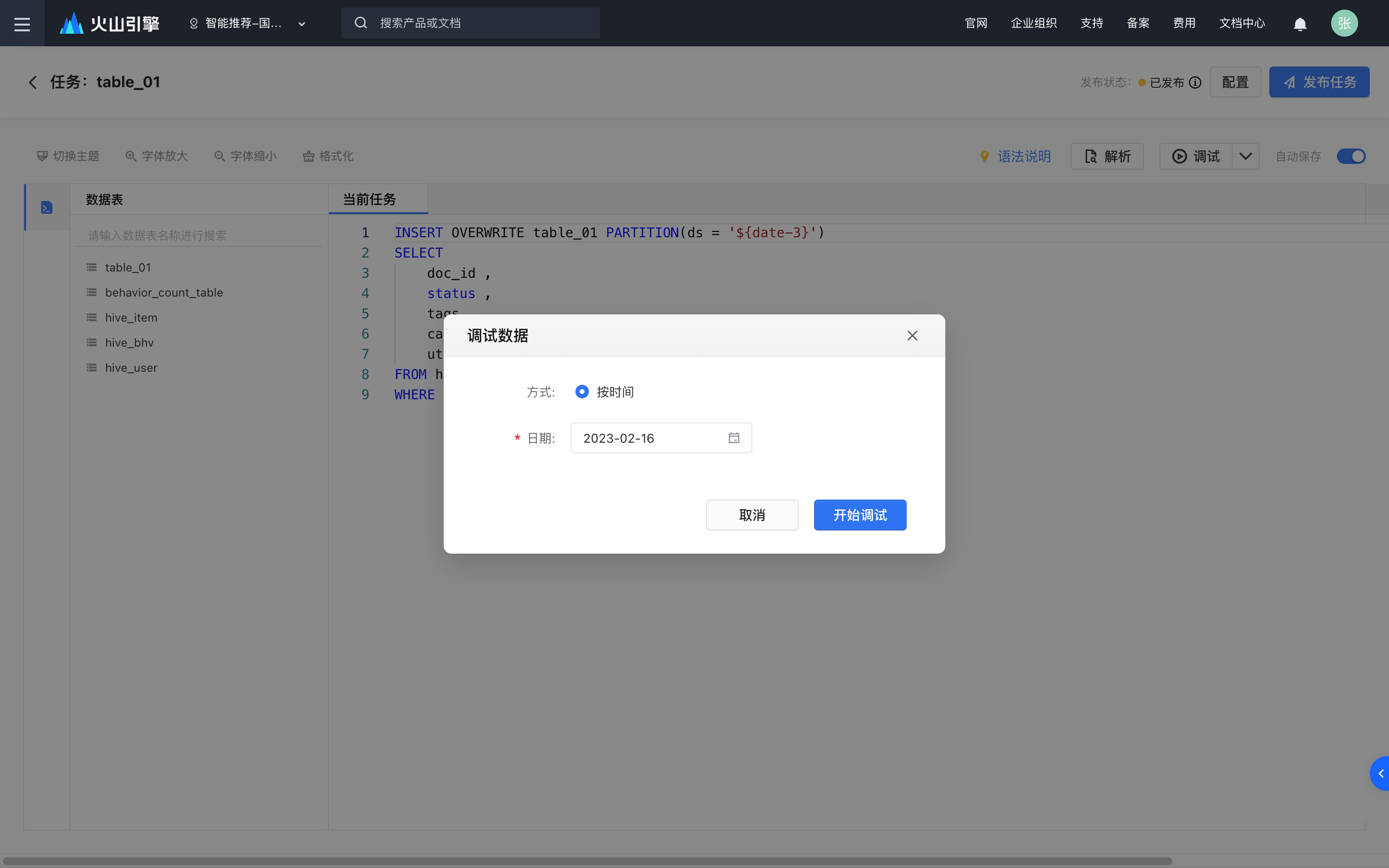
任务调试开始后,可在下方第一个面板查看运行日志。调试成功后,如果有结果返回可以在第二个面板中看到。运行日志和结果有约2天的缓存,缓存生效期间再次进入调试界面可以看到上一次调试的运行日志和结果,直到新的调试开始时才会被替代。
窗口聚合类任务
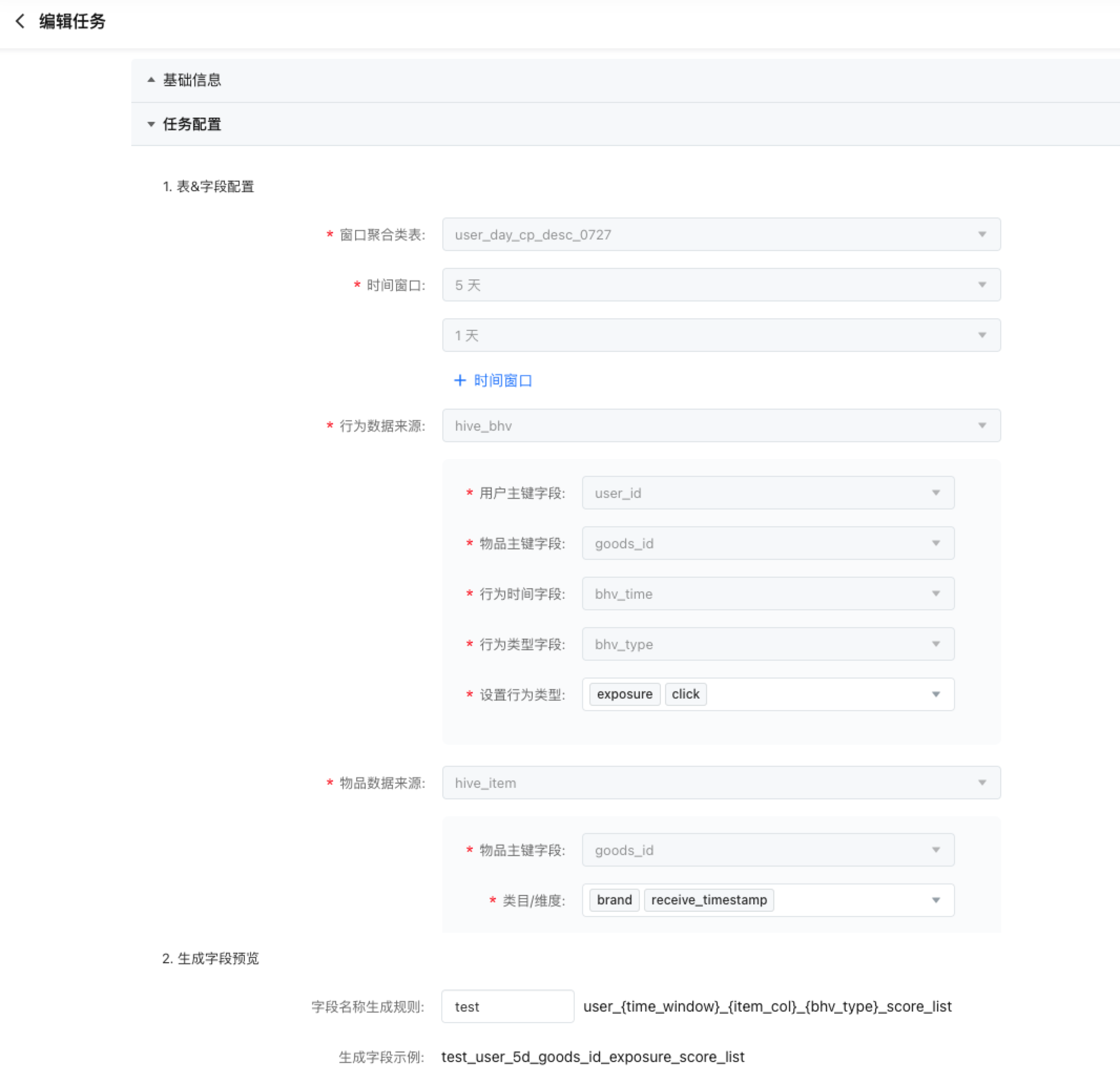
若输出表为用户维度、批式(天级)窗口聚合类表,填写信息如下
- 表&字段配置
- 时间窗口:选择天级的时间窗口,支持多选。
- 行为数据源:选择 table 类的行为表,仅支持行为类的原始表或中间表,填写行为表里的对应信息字段。其中,行为类型支持多选。
- 物品数据来源:选择 table 类的行为表/物品表,并且填写行为表/物品表里的对应信息字段。物品数据来源中能选择的行为表仅限行为数据来源已选中的行为表,如果先选择物品数据来源,则下拉框中不会出现行为表。其中类目/维度支持多选。对于 array 类型的字段,生成时会将 array 中的值展开按单独的值分别处理。
在物品数据源与行为表数据源一致时,物品数据源主键配置不生效,可选任意值。
- 生成字段预览
- 字段名称生成规则:系统根据表&字段配置会自动生成字段名称,你可以自行添加前缀进行区分。
- 生成字段示例:根据字段生成规则展示一个实例。
若输出表为用户维度、流式窗口聚合类表,填写信息如下
- 表&字段配置
- 时间窗口:按小时、分钟或天选择时间窗口,支持多选。
- 数据来源:选择一个流式样本,并填写样本中用户维度主键字段、想要统计的行为类型、想要统计的物品类目/维度。
- 生成字段预览同上
若输出表为物品维度的窗口聚合类表,填写信息如下:
- 表&字段配置
- 时间窗口: 根据输出表的统计时间粒度,按天或小时/分钟选择时间窗口,可多选;
- 行为数据来源:根据输出表的统计时间粒度,选择table类或消息队列类行为数据源,并填写对应字段信息;
- 生成字段预览同上
窗口聚合类任务能力速查表
特征主体 | 时间粒度 | 语义及命名 | 存储计算方式(自动化) | 存储计算方式(自定义) | 统计方法 | 行为是否去重 | 中间表字段命名 pattern | 参数 |
|---|---|---|---|---|---|---|---|---|
用户 | 批式(天级) | 某个 {用户} 最近 {某段时间范围} 内发生 {行为} 的某个 {类目/维度} 的 top 列表,按分值降序排列 | HIVE + Spark 批式任务 | HIVE + Spark 批式任务 | CP | 是 | user_{time_window}{item_col}{bhv_type}_score_list |
|
某个 {用户} 最近 {某段时间范围} 内发生 {行为} 的某个 {类目/维度} 的 top 列表,按行为时间降序排列 | HIVE + Spark 批式任务 | HIVE + Spark 批式任务 | Recent | 是 | user_{time_window}{item_col}{bhv_type}_recent_list | |||
否 | user_{time_window}{item_col}{bhv_type}_recent_list_dup | |||||||
流式 | 某个 {用户} 最近 {某段时间范围} 内对某个 {类目/维度} 的 {行为} 统计次数 | (内部组件) | (内部组件) | Count | user_{time_window}{item_col}{bhv_type}_count |
| ||
某个 {用户} 最近 {某段时间范围} 内发生 {行为} 的某个 {类目/维度} 的 top 列表,按分值降序排列 | (内部组件) | (内部组件) | Count | user_{time_window}{item_col}{bhv_type}_score_list | ||||
父物品 | 批式(天级) | 某个 {父物品} 最近 {某段时间范围} 内触发 {行为} 的某个 {类目/维度} 的 top 列表,按分值降序排列 | HIVE + Spark 批式任务 | HIVE + Spark 批式任务 | CP | 是 | pitem_{time_window}{item_col}{bhv_type}_score_list |
|
某个 {父物品} 最近 {某段时间范围} 内触发 {行为} 的某个 {类目/维度} 的 top 列表,按行为时间降序排列 | HIVE + Spark 批式任务 | HIVE + Spark 批式任务 | Recent | 是 | pitem_{time_window}{item_col}{bhv_type}_recent_list | |||
否 | pitem_{time_window}{item_col}{bhv_type}_recent_list_dup | |||||||
流式 | 某个 {父物品} 最近 {某段时间范围} 内对某个 {类目/维度} 的触发 {行为} 统计次数 | (内部组件) | (内部组件) | Count | pitem_{time_window}{item_col}{bhv_type}_count |
| ||
某个 {父物品} 最近 {某段时间范围} 内触发 {行为} 的某个 {类目/维度} 的 top 列表,按分值降序排列 | (内部组件) | (内部组件) | Count | pitem_{time_window}{item_col}{bhv_type}_score_list | ||||
物品 | 批式(天级) | 某个 {物品} 最近 {某段时间范围} 内在某种 {行为} 上的统计次数 | HIVE + Spark 批式任务 | HIVE + Spark 批式任务 | Count | item_{time_window}_{bhv_type}_count |
| |
流式 | 某个 {物品} 最近 {某段时间范围} 内在某种 {行为} 上的统计次数 | HIVE + Spark 批式任务 | Flink 流式任务 | Count | item_{time_window}_{bhv_type}_count |
|
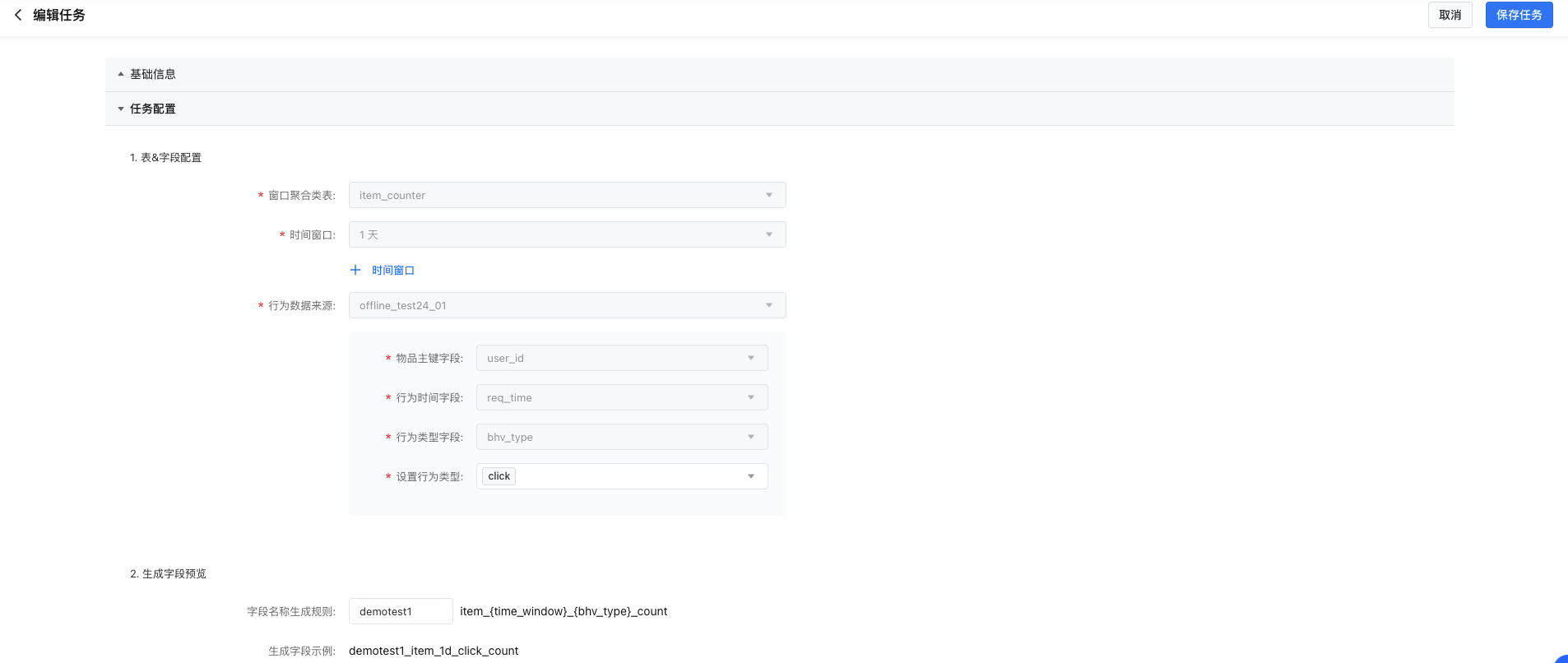
数据导入类任务
字段设置
- 输入表:可选择范围为table表 、统计时间粒度为天级的窗口聚合类表
- 输出表:可选择范围为kv表
- 字段映射关系设置:设置输入表的字段和输入表字段的映射关系
如果输出表字段有统一的前缀,如下图所示,可通过字段映射功能快速将输入表字段与输出表字段进行映射。匹配时会按 “前缀_输入表字段 <-> 输出表字段” 的格式进行,匹配不成功时不会自动建立映射。
注意
kv 表和窗口聚合类任务支持最多 500 个字段,超过时无法保存成功。窗口聚合类任务最多可生成的字段数量( 生成的字段数量 = 用户选择的“行为类型”数量 * “时间窗口”数量 * “类目/维度”数量 + 主键列)为 500 个。
编辑任务
表格类/消息队列类任务
表格类任务可以随时进入 IDE 进行编辑,代码调试通过后可多次发布。
编辑窗口聚合类数据处理任务
窗口聚合类任务,在任务还没有完整配置并发布时,可以进行编辑。
任务一经发布,除了备注外,已经存在的内容不支持删除或更改,只可新增。
编辑 kv 导入类任务
kv 导入类任务,在任务没有完整配置并发布时,可以同新建时一样进行编辑。
任务一经发布,除备注外,已经存在的内容(输入表、输出表及原有字段映射关系)不支持删除或更改,只可新增映射关系。
开启追新
任务保存提交后,可以在任务列表操作栏点击【开启追新】。
批式任务开启追新后,会对今天及以后的数据增量生成子任务。天级增量的子任务每天3:00开始执行(依赖的上游任务需执行完毕)。若再次编辑修改任务,保存任务时即重新开启追新(从修改之日起按新的任务处理逻辑来追新数据)。
流式任务开启追新后,默认从当前时刻开始执行。若需要再次编辑任务,保存任务时不会立即上线,需要先关闭追新,保存修改后,再重新开启追新。
执行历史任务
也可选择执行历史某一时间段内的子任务。回溯的子任务提交后立即执行。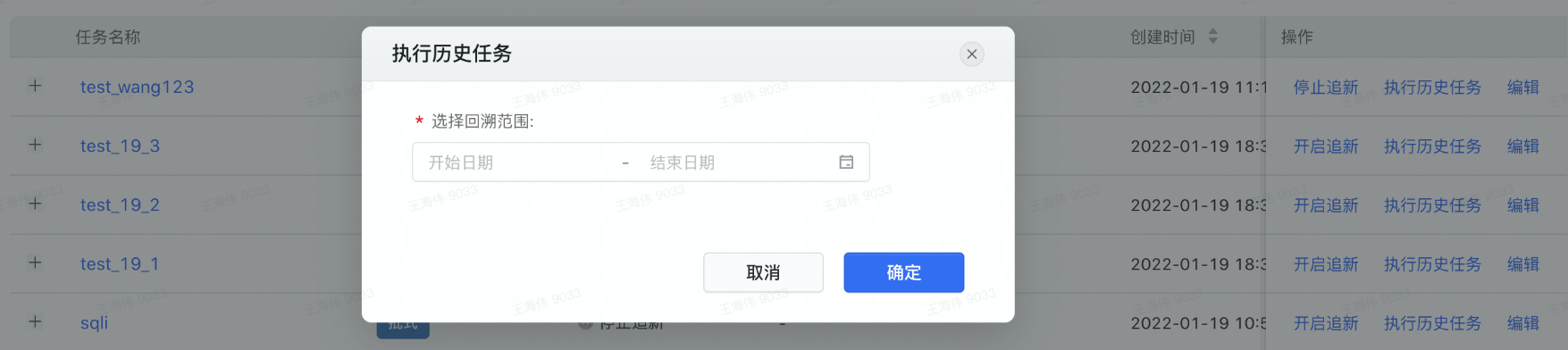
浏览任务列表并查看任务详情
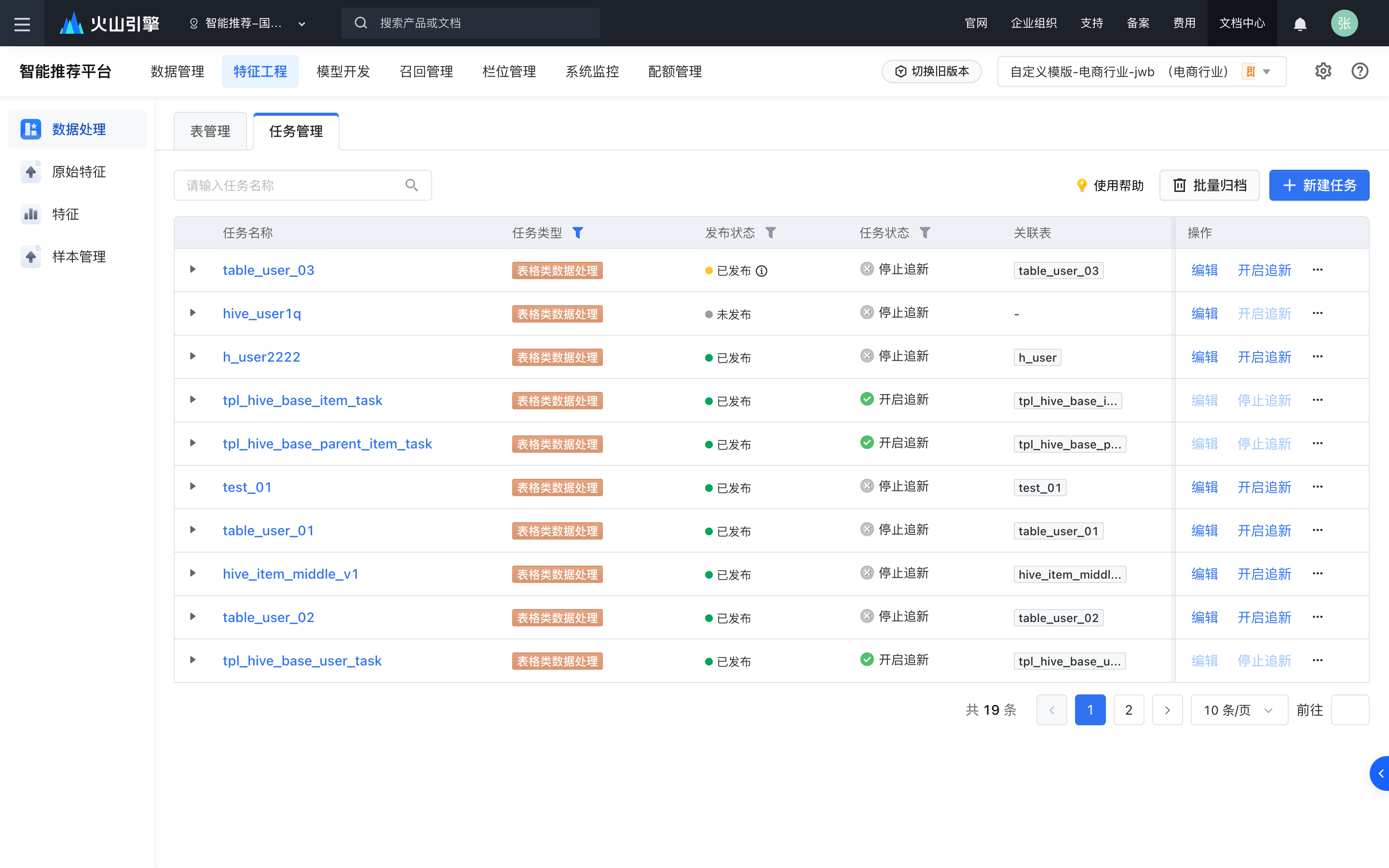
- 查看任务基本信息:点击任务名称,可查看任务类型、发布状态、任务状态、提交的SQL语句等基本信息。发布状态,
- 发布状态:表格类和消息队列类任务支持通过 SQL 创建任务,任务支持仅保存不发布,所以其发布状态分3种:未发布、已发布和已发布但有待发布改动。其他任务只能支持通过表单配置,保存即发布,也因此只有已发布一种状态。
- 查看任务执行情况:点击任务名称前方的 + 号,可展开查看每日任务的运行状态,支持用户进行重跑、停止、查看日志。