自研基于dsp算法和深度学习的回声消除、噪声抑制、声音增强,兼顾强降噪与高保真。针对不同场景,采取精准优化措施,尤其在音乐场景下,可以在保证人声和背景音乐无损伤的前提下,更好地抑制噪声。
授权
音频降噪与增强能力集需要使用离线功能授权,在调用具体接口之前需要先申请appkey和token;
具体授权的细节见 授权介绍
集成指南
接入指南
名词解释
具体的算法有:使用详见对应接口的文档
降噪/去混响/去啸叫
回声消除
自动增益控制
使用必读
3A算法的使用顺序如下图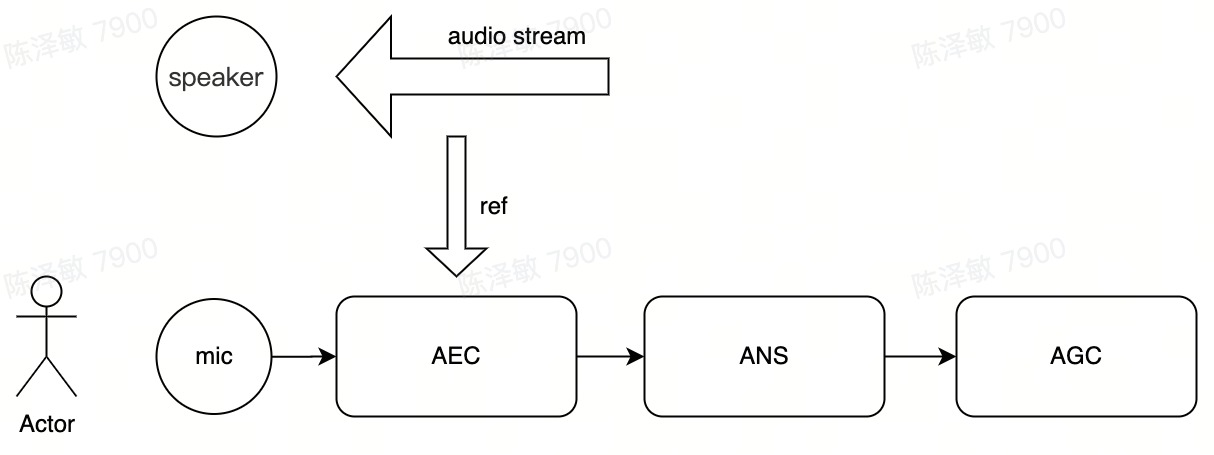
注意事项:
通用
在接入SAMI 3A算法之前不要接入其他处理,例如系统自带高通滤波、降噪、去回声等等,均会对mic信号作出修改,导致消除效果受影响。
尽量使用高采样率(44.1k/48k)
通常情况下顺序为ANS+AGC, 如有极小音量的情况,如-40LUFS以下,建议使用AGC+ANS
aec算法
aec信号处理必须在其他算法处理之前,其他信号的处理会影响mic的数据,导致消除效果受影响
使用过程,如果切换设备,比如从耳机切换到蓝牙,需要重新创建处理器,因为内部在一开始会去判断两个音频的延时时间并作为后续处理的标准
尽可能采用实际录制得到而非仿真产生的数据,仿真数据和真实场景存在偏差,可能会导致模型消除效果变差
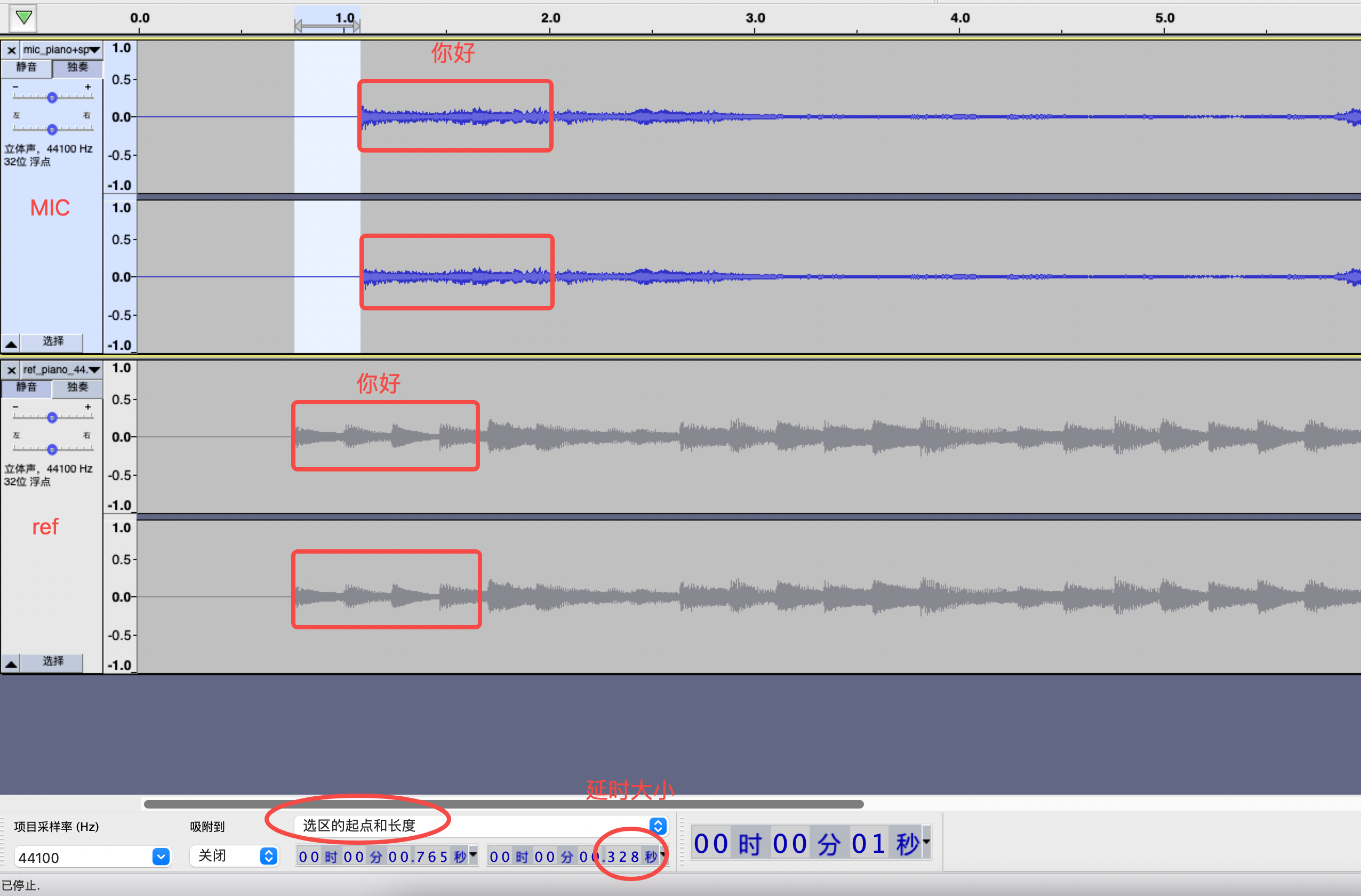
使用mic数据必须在播放数据之后(例如实时播放“你好”的音频,数据流同时送给aec当作参考信号,播放后mic采集到数据,再送给aec作为处理信号,“你好”的位置,从aec的视角参考信号应该在mic信号之前。),且延时不能超过模型支持的最大延时,模型的最大延时可在aec具体接口文档中查看。如果出现<=0延时或>模型支持的最大延时,处理效果会大打折扣。
ANS算法
数据类型:真实使用场景下的数据,尽量避免用白噪音等仿真数据来模拟;除非特殊情况尽量使用原始的录音数据(未经过设备处理过的数据)。
音量要求: 处于正常的音量范围以内,尽量避免过小的音量音频,如-40LUFS以下, 如实际场景有特别小的音量情况,应在降噪前加入agc模块。
信噪比:一些极端的case例如信噪比过低,噪声已经盖过过人声,人肉耳也很难听清楚的case,处理效果有限
AGC算法
采样率要求: 如非特殊情况尽量使用高采样率(44.1k/48k)
数据类型:真实使用场景下的数据,如非特殊情况尽量使用原始的录音数据(未经过设备处理过的数据)。