E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduceEMR Serverless 实例操作指南(OLAP)数据湖查询(StarRocks)外部表读取Hadoop集群中的数据
E-MapReduceEMR Serverless 实例操作指南(OLAP)数据湖查询(StarRocks)外部表读取Hadoop集群中的数据

本文为您介绍如何配置EMR Serverless StarRocks实例,以查询Hadoop高可用集群中的数据。
1 前提条件
已创建包含了HDFS服务,并且开启了服务高可用的集群,详情请参见创建集群。
已创建EMR Serverless StarRocks实例,详情请参加创建实例。
2 操作步骤
进入EMR Serverless StarRocks实例配置页面。
a. 登录EMR Serverless控制台。b. 在顶部菜单栏处,根据实际情况选择地域。
c. 在实例列表页,单击待查看的实例名称。
d. 单击实例配置页签。
修改hdfs-site.xml配置。
a. 单击hdfs-site.xml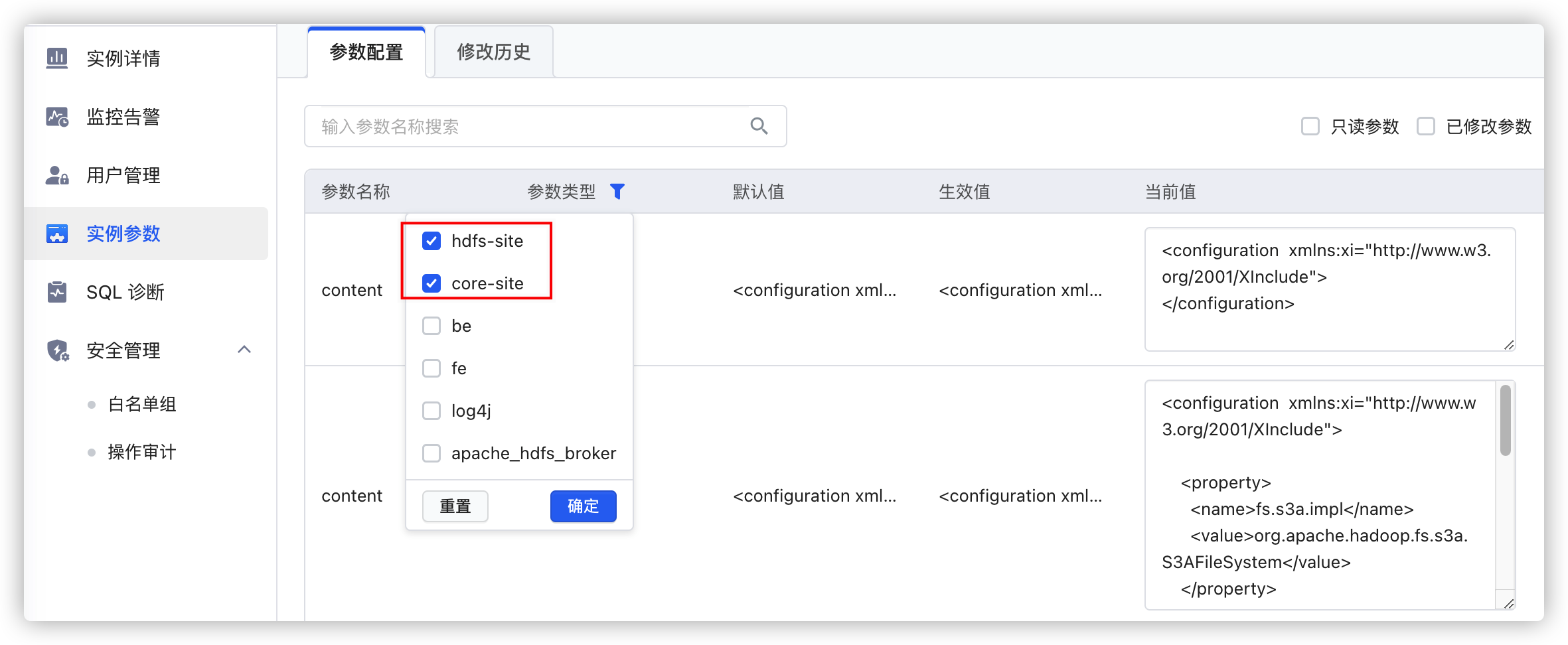
b. 修改或新增以下配置项。参数 描述 dfs.nameservices
配置值与已有高可用集群HDFS服务hdfs-site.xml配置文件里dfs.nameservices的值保持一致。默认值为emr-cluster。
dfs.ha.namenodes.<cluster_name>
配置值与已有高可用集群HDFS服务hdfs-site.xml配置文件里的相应配置项的值保持一致。
dfs.namenode.rpc-address.<cluster_name> dfs.client.failover.proxy.provider.<cluster_name> c. 单击确定。
保存配置。
a. 单击提交参数。b. 在弹出的对话框中,输入原因说明,单击确定。
3 示例
在Hadoop集群中准备Parquet格式的测试数据
启动hive cli执行以下命令
CREATE TABLE table1(name STRING, id INT) STORED AS PARQUET; INSERT INTO table1 values('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5), ('f', 6);
通过SHOW CREATE TABLE table1,确定数据在HDFS上的位置。
在StarRocks实例控制台,修改hdfs-site.xml参数,示例如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.nameservices</name> <value>emr-cluster</value> </property> <property> <name>dfs.ha.namenodes.emr-cluster</name> <value>emr-f65a635e7a7d7a1146c4-master-1,emr-f65a635e7a7d7a1146c4-master-2</value> </property> <property> <name>dfs.namenode.rpc-address.emr-cluster.emr-f65a635e7a7d7a1146c4-master-1</name> <value>192.168.xx.xx:8020</value> </property> <property> <name>dfs.namenode.rpc-address.emr-cluster.emr-f65a635e7a7d7a1146c4-master-2</name> <value>192.168.xx.xx:8020</value> </property> <property> <name>dfs.client.failover.proxy.provider.emr-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>在StarRocks中查询HDFS文件中的数据
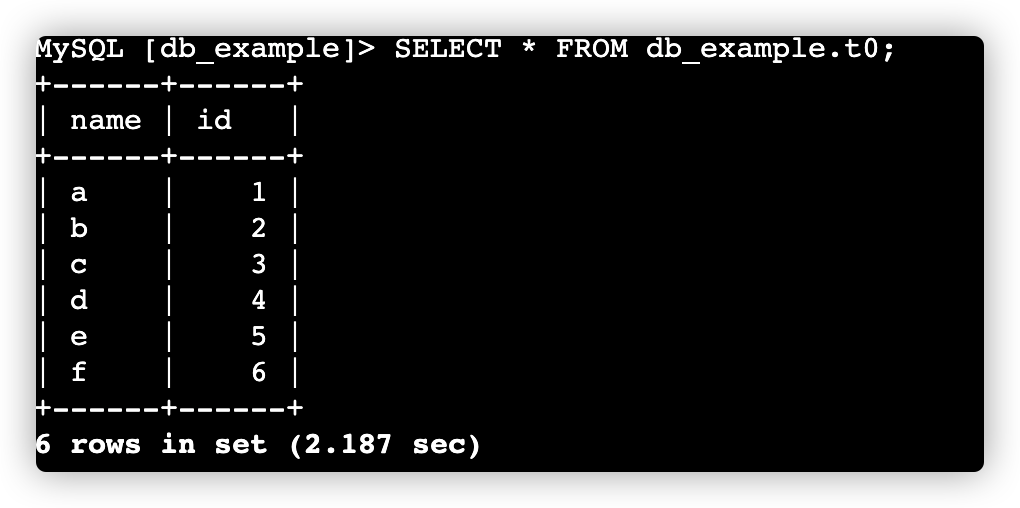
CREATE DATABASE db_example; USE db_example; CREATE EXTERNAL TABLE t0 ( name string, id int ) ENGINE=file PROPERTIES ( "path"="hdfs://emr-cluster/warehouse/tablespace/managed/hive/table1/", "format"="parquet" ); --查询表中数据 SELECT * FROM db_example.t0;
4 访问keberos的集群
4.1 Kerberos与StarRocks混合部署
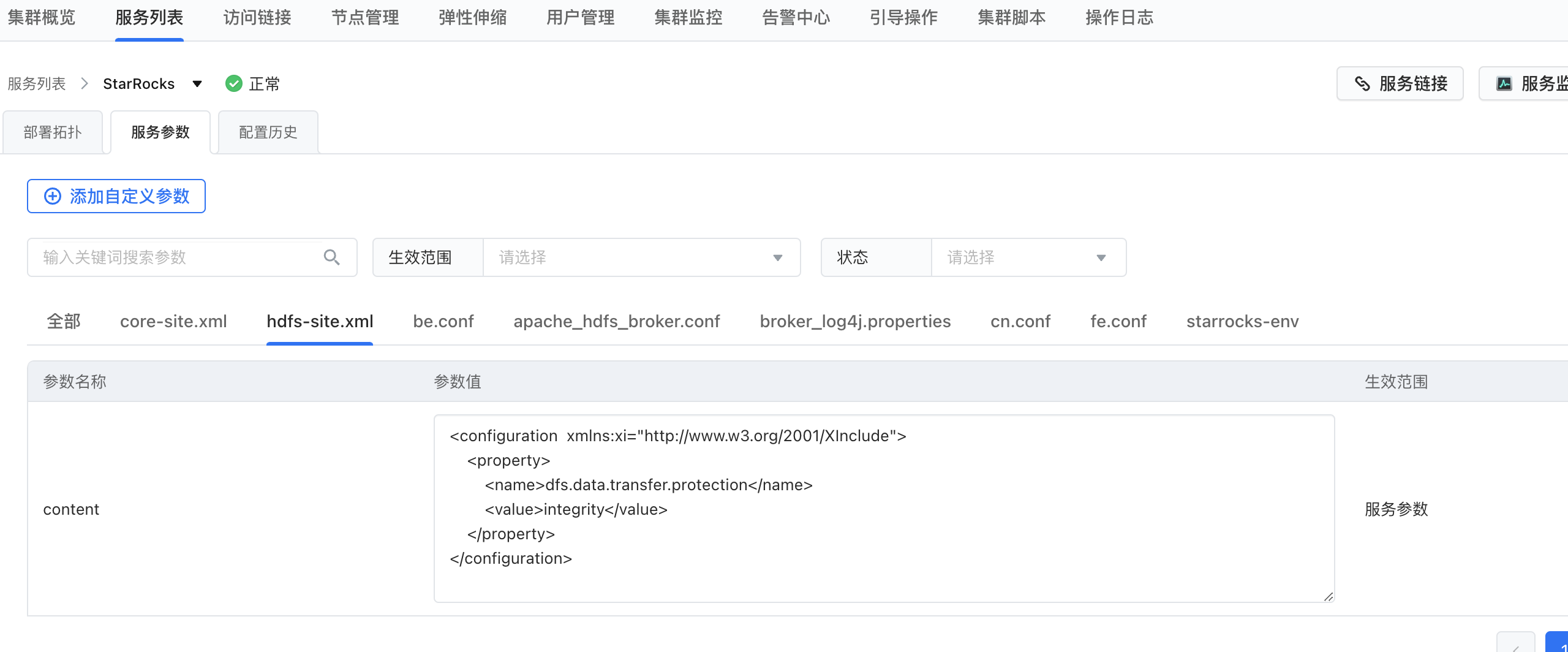
在hdfs-site.xml 文件增加属性,重启StarRocks集群
<property> <name>dfs.data.transfer.protection</name> <value>integrity</value> </property>
4.2 Kerberos与StarRocks独立部署
注意
首先要将hadoop 中core-site.xml文件的内容拷贝到starrocks的配置项中,重启集群
社区版 HDFS 支持简单认证和 Kerberos 认证两种认证方式(Broker Load 默认使用简单认证),并且支持 NameNode 节点的 HA 配置。如果存储系统为社区版 HDFS,您可以按如下指定认证方式和 HA 配置:
认证方式
- 如果使用简单认证,请按如下配置
StorageCredentialParams:
"hadoop.security.authentication" = "simple" "username" = "<hdfs_username>", "password" = "<hdfs_password>"StorageCredentialParams包含如下参数。
参数名称 参数说明 hadoop.security.authentication 指定认证方式。取值范围:simple 和 kerberos。默认值:simple。simple 表示简单认证,即无认证。kerberos 表示 Kerberos 认证。 username 用于访问 HDFS 集群中 NameNode 节点的用户名。 password 用于访问 HDFS 集群中 NameNode 节点的密码。 - 如果使用 Kerberos 认证,请按如下配置
StorageCredentialParams:
"hadoop.security.authentication" = "kerberos", "kerberos_principal" = "nn/zelda1@ZELDA.COM", "kerberos_keytab" = "/keytab/hive.keytab", "kerberos_keytab_content" = "YWFhYWFh"StorageCredentialParams包含如下参数。
参数名称 参数说明 hadoop.security.authentication 指定认证方式。取值范围:simple 和 kerberos。默认值:simple。simple 表示简单认证,即无认证。kerberos 表示 Kerberos 认证。 kerberos_principal 用于指定 Kerberos 的用户或服务 (Principal)。每个 Principal 在 HDFS 集群内唯一,由如下三部分组成:username 或 servicename:HDFS 集群中用户或服务的名称。instance:HDFS 集群要认证的节点所在服务器的名称,用来保证用户或服务全局唯一。比如,HDFS 集群中有多个 DataNode 节点,各节点需要各自独立认证。realm:域,必须全大写。举例:nn/zelda1@ZELDA.COM。 kerberos_keytab 用于指定 Kerberos 的 Key Table(简称为“keytab”)文件的路径。 kerberos_keytab_content 用于指定 Kerberos 中 keytab 文件的内容经过 Base64 编码之后的内容。该参数跟 kerberos_keytab 参数二选一配置。 - 需要注意的是,在多 Kerberos 用户的场景下,您需要确保至少部署了一组独立的 Broker,并且在导入语句中通过
WITH BROKER "<broker_name>"来指定使用哪组 Broker。另外还需要打开 Broker 进程的启动脚本文件 start_broker.sh,在文件 42 行附近修改如下信息让 Broker 进程读取 krb5.conf 文件信息:
export JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx1024m -Dfile.encoding=UTF-8 -Djava.security.krb5.conf=/etc/krb5.conf"- 如果使用简单认证,请按如下配置
说明
- /etc/krb5.conf 文件路径根据实际情况进行修改,Broker 需要有权限读取该文件。部署多个 Broker 时,每个 Broker 节点均需要修改如上信息,然后重启各 Broker 节点使配置生效。
- 您可以通过 SHOW BROKER 语句来查看 StarRocks 集群中已经部署的 Broker。