E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南YARN最佳实践YARN Node Label介绍与最佳实践
E-MapReduce组件操作指南YARN最佳实践YARN Node Label介绍与最佳实践

基本介绍
YARN(Yet Another Resource Negotiator)Node Label是YARN中用于标识Node Manager节点,并对节点进行“分组/分区”管理的一种机制。通过给节点打上不同的标签,YARN可以根据标签将任务分配到特定分区的节点上执行。
Node Label特性有着广泛的应用场景,常用于集群中节点异构、多种场景/计算框架的负载隔离等。
目前,所有的EMR版本所附带的YARN组件,都支持Node Label特性。
注意
配置了Node Label后,弹性伸缩功能中,按负载弹性伸缩功能会因为指标变化而无法正常工作。
Node Label
目前一个节点只能设置属于某一个Node Label,所以可以使用 Node Label将整个YARN集群划分为不相交的节点集合。默认节点属于DEFAULT分区(partition="",空字符串)。
Node Label分为两类:
- exclusive:只允许请求和该分区匹配的容器调度到该分区的节点上。
- non-exclusive:除了分配该分区容器请求外,还允许在有空闲资源时将请求为DEFAULT分区的容器调度上来(或请求未特殊制定分区)
说明
目前只有Capacity Scheduler调度器支持Node Labels分区调度。
一般情况下,Node Label会搭配队列使用。用户需要配置不同队列可以使用每个分区的多少资源。您可以通过调度器配置或者计算引擎node-label-expression参数让队列上的任务容器调度到队列可访问的分区上。
接下来我们介绍下Node Label的基本用法和常规实践。
Node Label 功能开启
- 登录 EMR 控制台。
- 在左侧导航栏中,单击集群列表 > 集群名称,进入到具体集群详情界面。
- 在集群详情界面,单击服务列表>YARN>服务参数,在服务参数页面搜索yarn.node-labels.enabled 。
- 修改yarn.node-labels.enabled 的值由 false 改为 true。
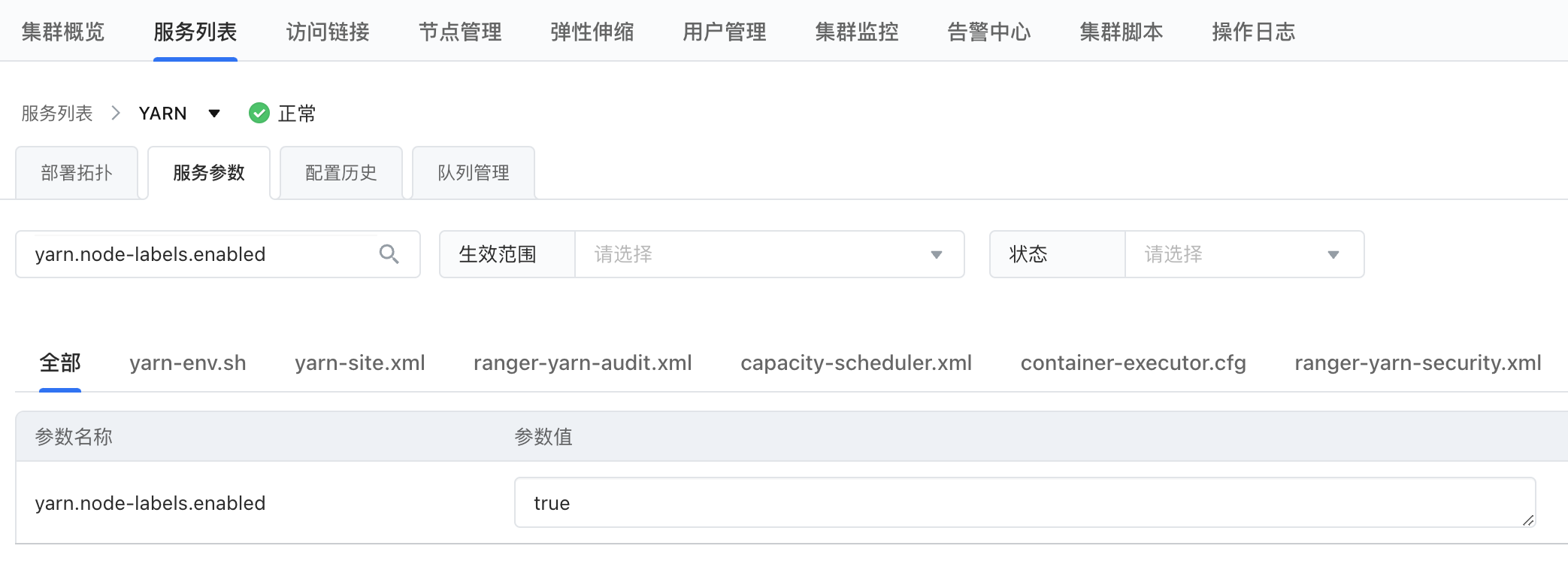
- 修改yarn.node-labels.fs-store.root-dir 的值
yarn.node-labels.fs-store.root-dir 的默认值为:/system/yarn/node-labels。但是为了保证集群的高可用,避免 RM 宕机而丢失标签信息,建议将标签信息保存在 HDFS 上。先在HDFS上新建一个文件目录:
hadoop fs -mkdir -p /yarn/node-labels
然后将该配置参数修改为HDFS的实际地址。
Node Label 新建
登录master-1-1所在的ecs节点,执行如下命令,获取yarn当前所有的node labels:
yarn cluster --list-node-labels
执行一下操作,创建标签
yarn rmadmin -addToClusterNodeLabels "streaming,batch"
再执行list命令查看标签被创建成功
在集群详情界面,单击访问链接>YARN ResourceManager UI,打开YARN Web UI。点击左侧“Node Labels”菜单,可以看到两个label已经在UI上可见了,但从后面的“Num Of Active NMs”列可以看到,它们都还没有绑定节点。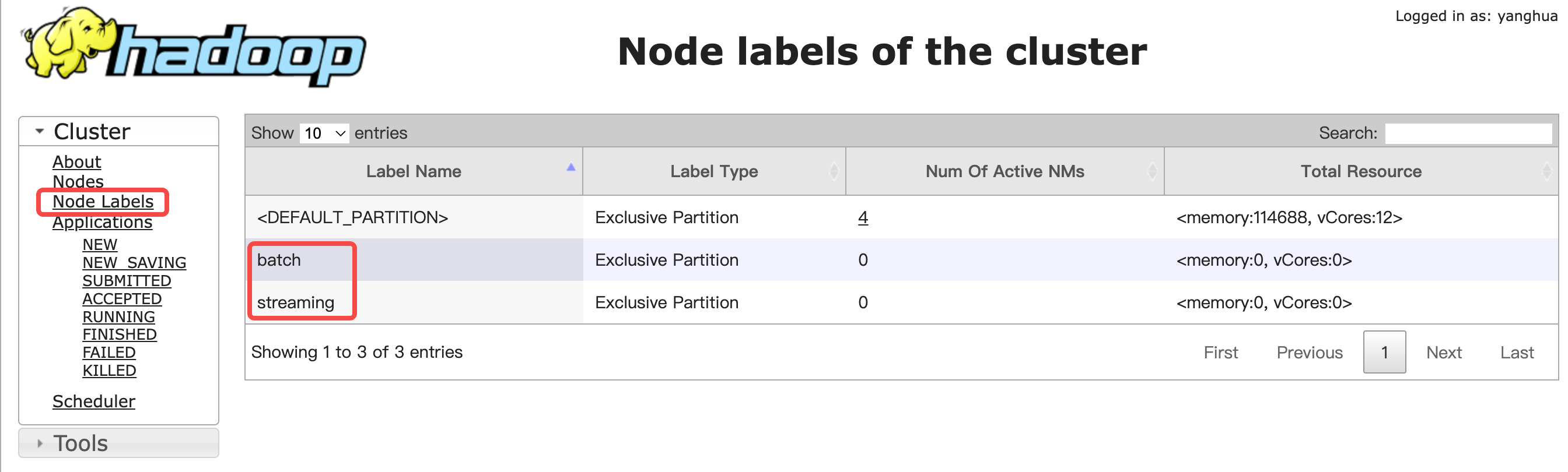
Node Label 绑定节点
以已有两个worker节点(core/task),如下图:
在节点管理>节点组列表,复制节点组名称,如“core-1-1”节点绑定到“batch” label,将“core-1-2”开头的节点绑定到“streaming”label。
执行如下命令即可完成:
yarn rmadmin -replaceLabelsOnNode "core-1-1.emr-xxx.cn-beijing.emr-volces.com:45454=batch" yarn rmadmin -replaceLabelsOnNode "core-1-2.emr-xxx5.cn-beijing.emr-volces.com:45454=streaming"
在“Node Labels”页面,就能看到两个Label都绑定了对应的NodeManager: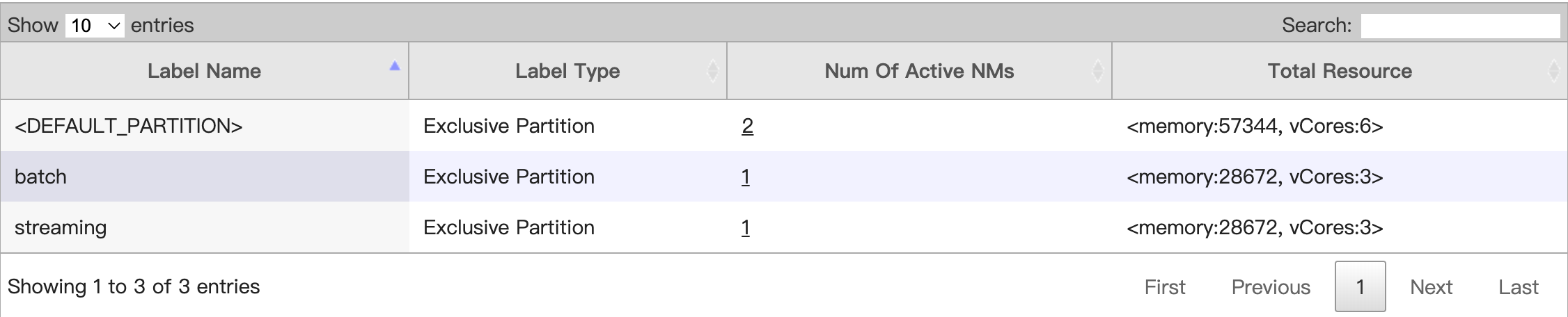
同时在“Nodes”列表页的第一列也会展示相应的Label: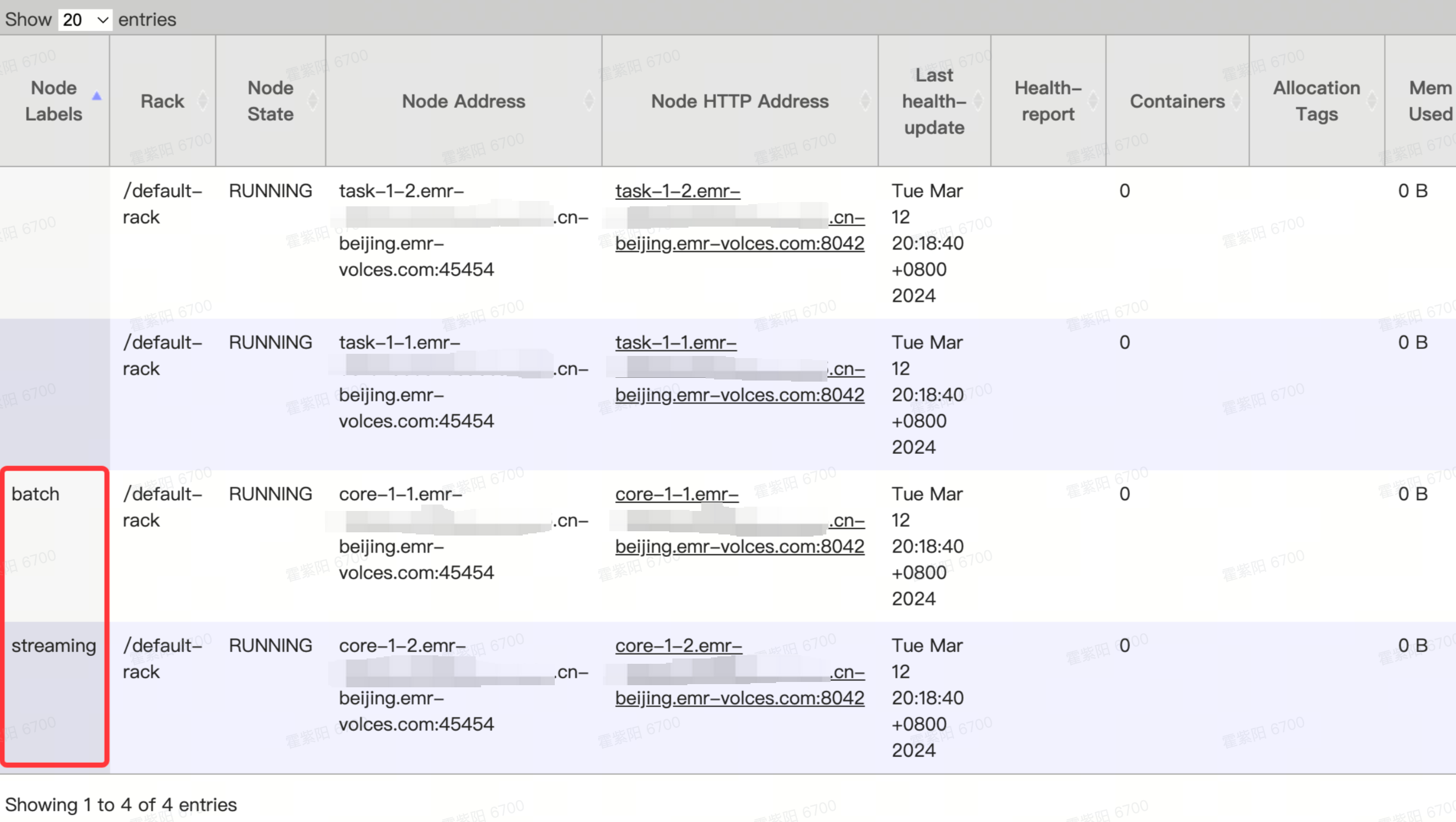
Node Label 绑定弹性节点
Node Label中绑定的节点可以借助于EMR YARN组件的弹性伸缩能力以及EMR集群的“集群脚本”功能进行弹性伸缩。这里我们简单介绍下使用教程:
- 在节点管理页面点击右侧“新增节点组”,创建一个task节点组:
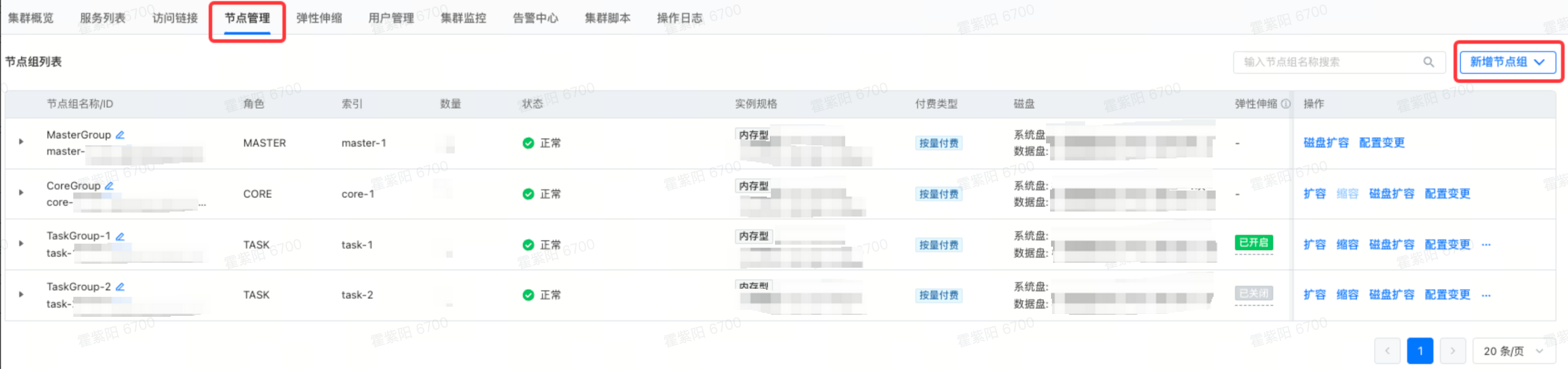
- 在集群脚本页面,在右侧单击添加集群脚本
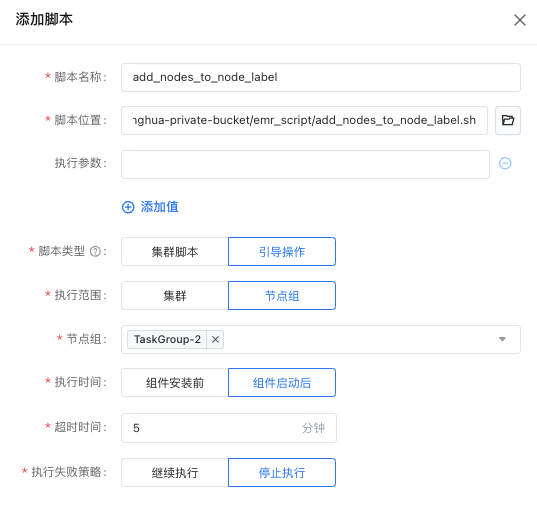
复制脚本位置文本框中内容到本地,修改TASK_GROUP和NODE_LABEL变量
- TASK_GROUP:节点组名称前缀,节点组名称的需要与选择的节点组一只
- NODE_LABEL:用户希望将节点加入到的Node Label,在脚本执行之前,确保Node Label已在集群中被正确创建;
#!/bin/bash source /etc/profile # 需人为调整的变量 TASK_GROUP="task-2-" NODE_LABEL="batch" # 执行yarn node -list命令并获取输出 output=$(yarn node -list) # 循环遍历输出的每一行 while IFS= read -r line; do # 检查当前行是否以TASK_GROUP开头 if [[ $line =~ ^$TASK_GROUP.* ]]; then # 使用awk提取行的第一部分,即节点名称 nm_node=$(echo "$line" | awk '{print $1}') # 检查是否成功提取了节点名称 if [[ -n $nm_node ]]; then # 执行yarn rmadmin命令,替换节点标签 yarn rmadmin -replaceLabelsOnNode "$nm_node=$NODE_LABEL" fi fi done <<< "$output"
注意
为了保证脚本能读取到一系列的环境变量,“source /etc/profile”这一行命令是必要的。
脚本验证
进入访问链接>YARN ResourceManager UI页面查看当前集群中Node与Node Label的映射关系。
此时TaskGroup-2组下有一个节点,但没有被打上Label。然后在节点管理为TaskGroup-2节点组扩容一个节点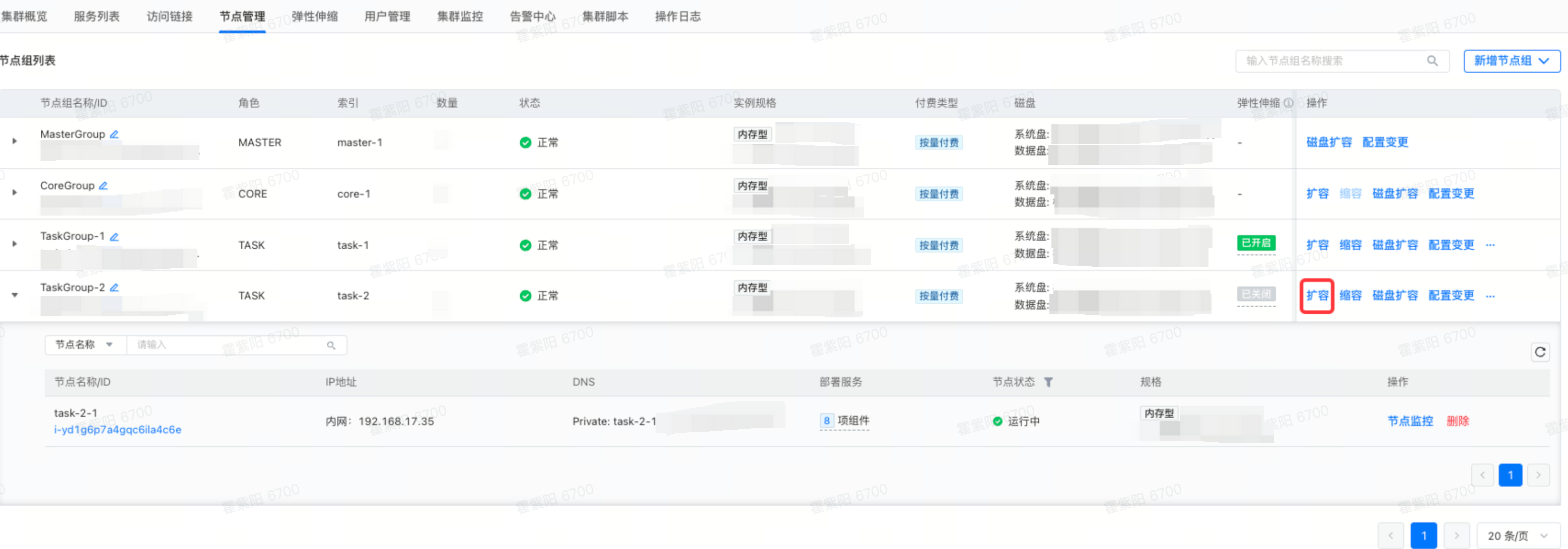
等到新增节点状态从“初始化中”变成“运行中”后,进入访问链接>YARNResourceManager UI>Node Label的列表,查看TaskGroup-2下的两个节点都打上“batch”标签。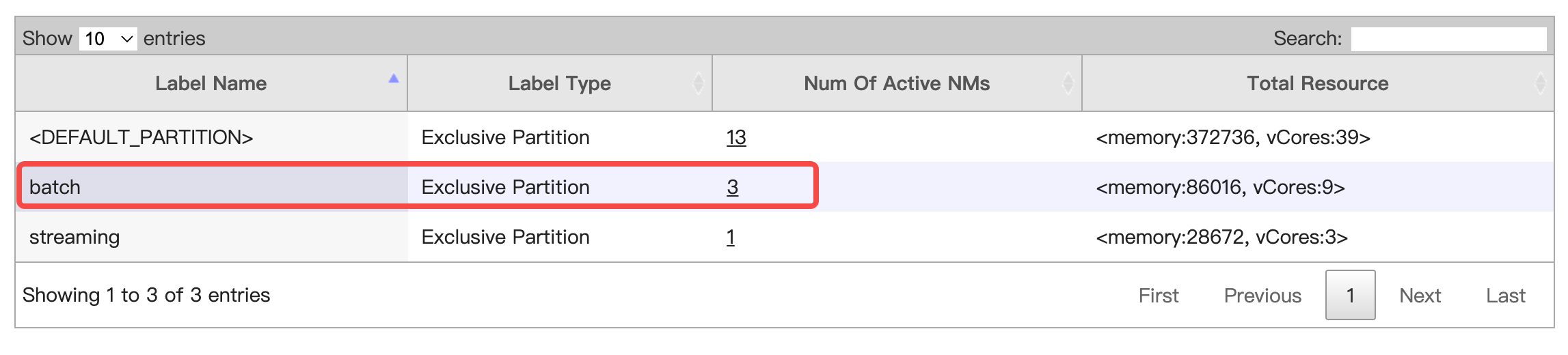
在Node列表里相关信息如下: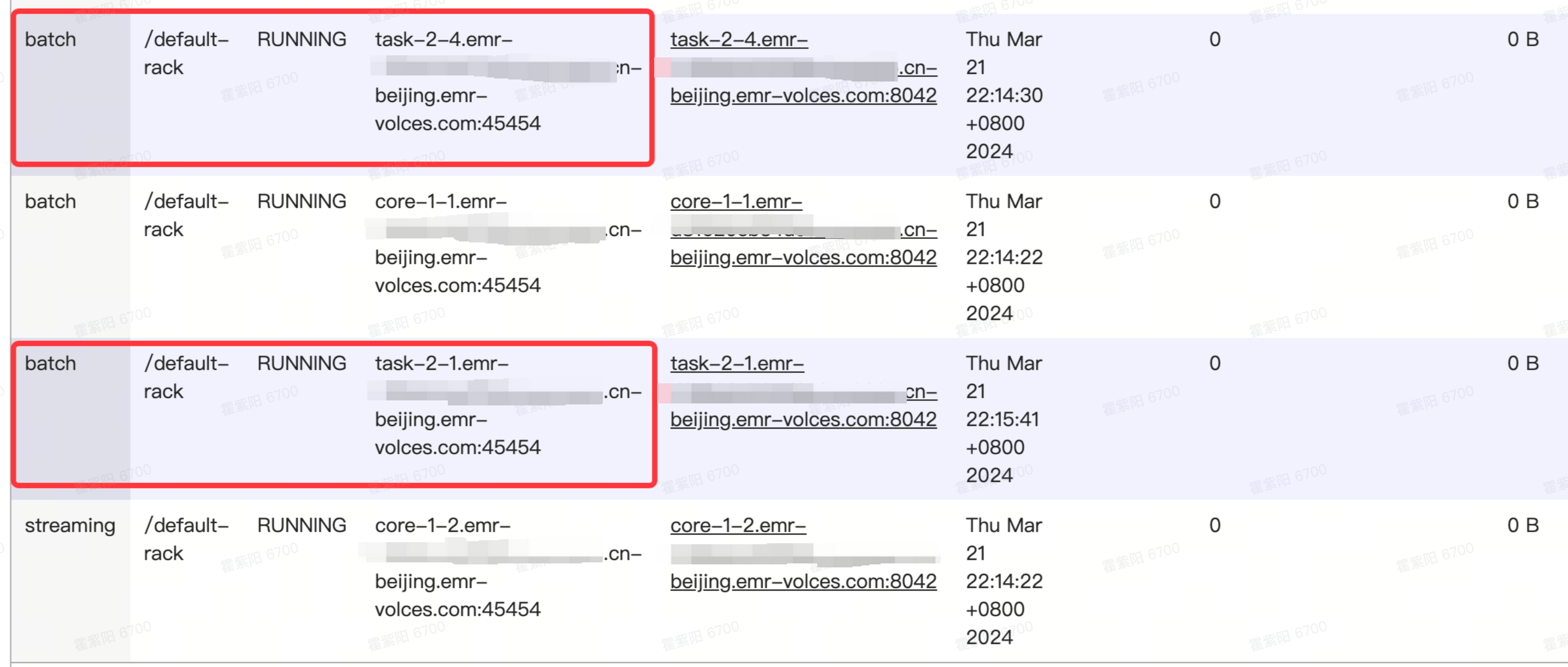
在集群脚本>执行记录页面,查看执行记录。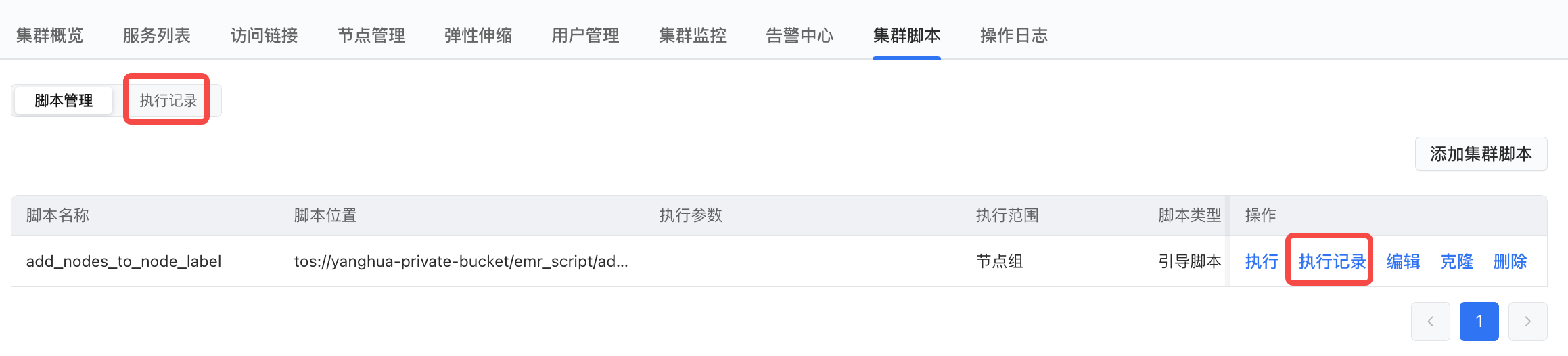
点击“执行”,在现有的节点上“DEBUG”脚本,确认逻辑正确后,可以应用到弹性扩缩容上。
在执行记录页面,点击单条的执行记录, 查看详细执行记录。
执行日志分为两类:
- 执行脚本日志:会展示加载的脚本信息和脚本内容;
- 在扩容节点上的日志:会展示脚本执行的标准输出stdout/stderr;
Node Label 绑定弹性节点的最佳实践
Node Label与弹性扩缩容的能力可以结合起来,从而提供更灵活、更便捷的打“Node Label”的机制。
弹性扩缩容是火山引擎EMR的优势之一,弹性扩缩容的管理中围绕“TaskGroup”。EMR将扩缩容的节点划分为一个个的Group,伸缩规则也应用在TaskGroup上。这一点跟YARN引入Node Label来对集群分区/分组,在类比上是极其类似的。推荐Nodel Label的使用逻辑与TaskGroup对应。EMR也是支持用于打“Label”的脚步在一个TaskGroup维度下的所有Node上执行。
Node Label 使用的最佳实践
Node Label提供了对节点的分区,这使得YARN在调度时可以据此在物理上对不同类型的负载进行隔离。建议用户对差异巨大且又不能互相影响的业务负载进行划分并创建Node Labels。
常见的划分可以为:
- 不同的业务类型:
- Data ingestion(入湖、入仓);
- 离线ETL;
- 实时ETL;
- 机器学习(数据预处理..)
- AD Hoc
- ...
- 或异构的节点类型:
- 高性能计算型/高性能IO型;
- 旧规格配置/新规格配置;
以上的划分方式无绝对,看用户对业务的可用性要求。例如,有的用户对实时作业的SLA要求极高,就不建议用Node Label隔离,而是建议单独拆物理集群。因为有些时候调参会涉及集群的重启,会导致一些实时业务无法接受。
Queue
Node Lable的灵活性需要结合Queue才能发挥到最佳。这里将对 Queue 进行简单的介绍以及创建。
Queue 介绍
YARN Queue是YARN中用于资源管理和任务调度的一种机制,是一个资源池的逻辑表示。 在YARN中,所有的任务都需要提交到一个特定的Queue中,然后YARN的资源管理器(ResourceManager)会根据任务的优先级、可用资源等因素,将任务分配到合适的节点上执行。 YARN Queue可以用来隔离不同类型的任务,以确保不同类型的任务可以在不同的资源池上执行,从而提高系统的可靠性和效率。
Queue 创建
Queue 定义配置项介绍
- 在集群详情界面,单击服务列表>YARN>服务参数,在服务参数页面搜索
capacity-scheduler.xml。 - yarn.scheduler.capacity.root.queues 该参数用于定义容量调度器下拥有多少Queue。
YARN中的Queue设计可以是一个树结构。所以,Queue的标准写法,是从root开始的“点分法”,形如:root.xxx.xxx
- yarn.scheduler.capacity..capacity 该参数设置Queue可以访问的属于DEFAULT分区内节点资源的百分比。每个父项下的直接子项的 DEFAULT 容量总和必须等于 100。
添加Queue
方式一:可以通过,修改服务参数添加队列
- 服务列表>YARN>服务参数,在服务参数页面点击capacity-scheduler.xml
- 添加自定义参数 yarn.scheduler.capacity.root.queues、yarn.scheduler.capacity..capacity 创建队列
方式二:
在服务列表>YARN>队列管理, 单击右侧 添加队列 按钮,进行新增队列操作。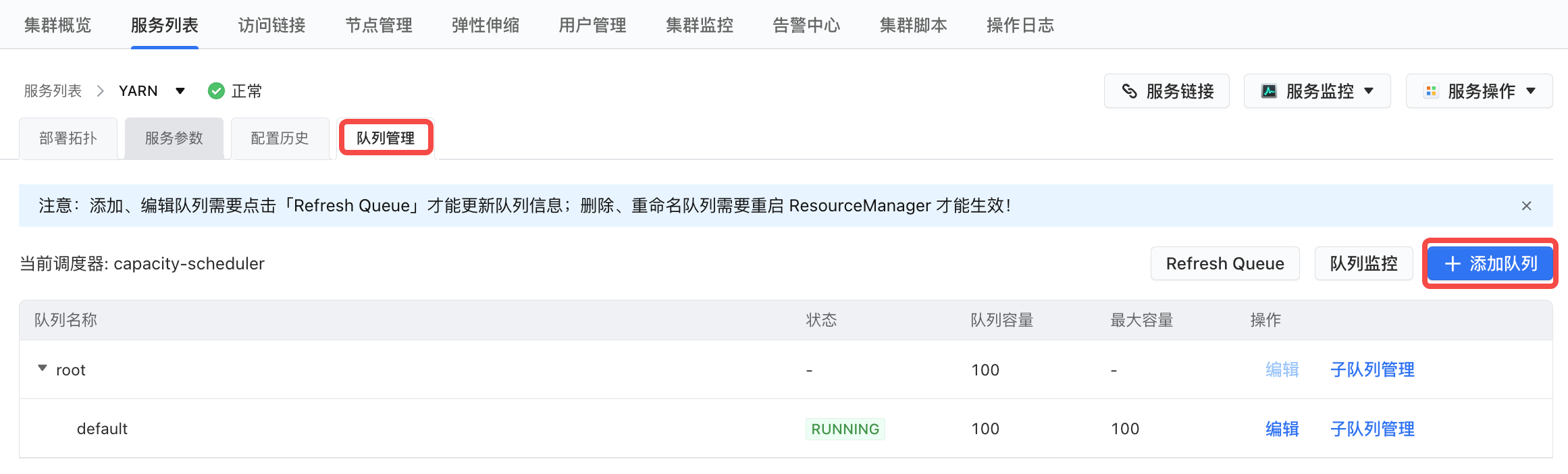
队列添加成功后,进入访问链接>YARN ResourceManager UI 点击左侧 Scheduler 菜单,展开Application Queues面板内的折叠按钮,查看Queue是否创建成功以及容量分配是否正确。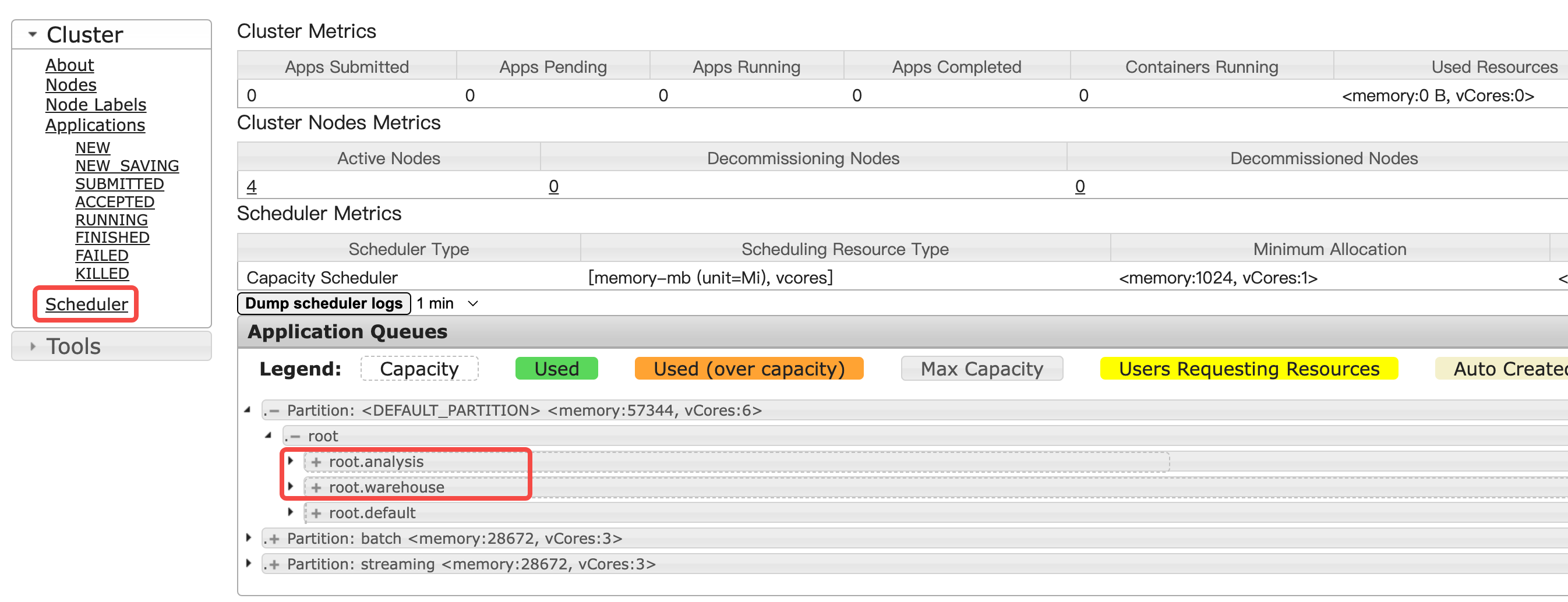
可以看到相关的队列在DEFAULT分区已经创建成功。继续展开root.analysis或root.warehouse,可以查看具体的容量分配是否正确。查看root.warehouse 容量占比和创建队列保持一致。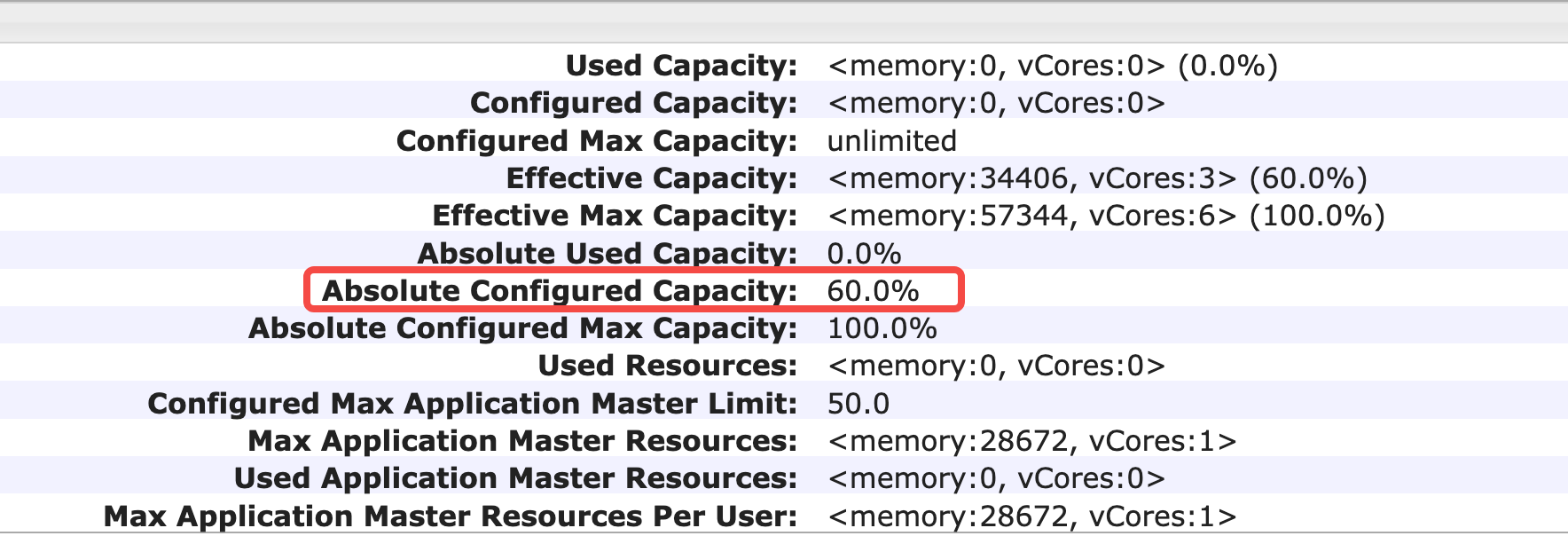
Queue 的最佳实践
YARN的Queue机制非常灵活,Queue的划分方式,业界没有固定的标准。考虑到其设计是一个“树形结构”,跟一般企业的组织架构有一定的共性。所以,推荐的实践可以按组织架构(或与此接近的团队、职能)来进行划分。
例如,针对离线ETL的这种负载场景。通常会有很多团队都会涉及这种类型的负载,例如:数仓、业务团队、数据分析团队、机器学习团队(智能营销、智能风控、数据挖掘...)。也可以在一个Queue底下,再细分各个子Queue来应对组织或团队的关系,从而形成类似租户级的资源管理能力。
在日常的的使用场景中,建议为default队列留一些buffer资源,用于“应急”和“错配/漏配”后fallback使用。
建议队列足够扁平,一般情况下一层、两层足够了(因为capacity-scheduler.xml配置起来非常繁琐,而且容易算错)。一些场景可以带上XXX_核心队列,xxx_弹性队列。核心队列,视为高保队列,不弹性。
Queue与Node Label结合实现灵活的资源管理
上面已经介绍了Node Label以及Queue的创建方式以及基本作用。Queue与Node Label结合实现的灵活的资源管理主要通过Capacity Scheduler来实现。
配置介绍
在capacity-scheduler.xml文件中与此有关的几个参数介绍:
- yarn.scheduler.capacity..accessible-node-labels
指定每个Queue可以访问的标签,用逗号分隔,如 "hbase,storm "表示Queue可以访问标签 hbase 和 storm。
- yarn.scheduler.capacity..accessible-node-labels..capacity
设置Queue可以访问属于 分区内节点资源的百分比。每个父级下的直接子级的 容量总和必须等于 100。默认情况下,为 0。
- yarn.scheduler.capacity..accessible-node-labels..maximum-capacity
类似于 yarn.scheduler.capacity..maximum-capacity,它用于配置每个队列标签的最大容量。默认为 100。
- yarn.scheduler.capacity..default-node-label-expression
类似于 "hbase "的值,这意味着:如果应用程序向队列提交的资源请求中没有指定节点标签,则会使用 "hbase "作为默认节点标签表达式。默认情况下,该值为空,因此应用程序将从无标签的节点获取容器。
配置示范与演练
以已有两个node label和两个queue为例,进行实际配置与演练。
node label,分别为“batch”和“streaming”,批和流处理的负载必须进行物理隔离,防止互相影响。
queue,分别是“warehouse”和“analysis”,数仓和数分两个团队需要占用YARN上一定配比的资源。
业务操作场景:
- 数仓团队(queue: warehouse)要使用70%的离线资源(node label: batch)和80%的流处理资源(node label:streaming);
- 数分团队(queue: analysis)要使用30%的离线资源(node label: batch)和20%的流处理资源(node label:streaming);
需在服务列表>YARN>服务参数,在服务参数页面点击capacity-scheduler.xml
文件中以XML格式的规范来配置参数并实现以上的需求,相关配置如下:
注意
要想让子队列获取node label的资源容量,其父队列必须先拥有该label的资源容量,建议父队列拥有这些label的100%的资源容量配比。
<property> <name>yarn.scheduler.capacity.root.accessible-node-labels.batch.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.accessible-node-labels.streaming.capacity</name> <value>100</value> </property>
配置两个队列都可以访问这两个Node Label:
<property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels</name> <value>batch,streaming</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels</name> <value>batch,streaming</value> </property>
进行容量的分配,首先是数仓团队:
<property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.batch.capacity</name> <value>70</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.batch.maximum-capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.default-node-label-expression</name> <value>batch</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.batch.state</name> <value>RUNNING</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.streaming.capacity</name> <value>80</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.streaming.maximum-capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.warehouse.accessible-node-labels.streaming.state</name> <value>RUNNING</value> </property>
然后是数分团队:
<property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.batch.capacity</name> <value>30</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.batch.maximum-capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.batch.state</name> <value>RUNNING</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.streaming.capacity</name> <value>20</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.streaming.maximum-capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.analysis.accessible-node-labels.streaming.state</name> <value>RUNNING</value> </property>
基本原则:当yarn.scheduler.capacity.root.accessible-node-labels.<label>.capacity配置大于0后,和常规的yarn.scheduler.capacity.<queue-path>.capacity规则一样,要求直接子队列的相同分区capacity之和为100。
YARN 调度验证
通过让YARN在调度Spark APP的过程中,加入指定Node Label和queue的参数来验证YARN调度的正确性。
spark任务可以通过在提交时指定如下参数来指定Node Label:
- spark.yarn.am.nodeLabelExpression
- spark.yarn.executor.nodeLabelExpression
通过指定queue参数来设置Queue,作业提交命令如下:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 2g --conf spark.yarn.am.nodeLabelExpression=batch --conf spark.yarn.executor.nodeLabelExpression=batch --queue=warehouse examples/jars/spark-examples_2.12-3.3.3.jar 10
提交作业后,在访问链接>YARN ResourceManager UI 上查看detail信息,可以看到该作业以按照预期的方式被调度执行。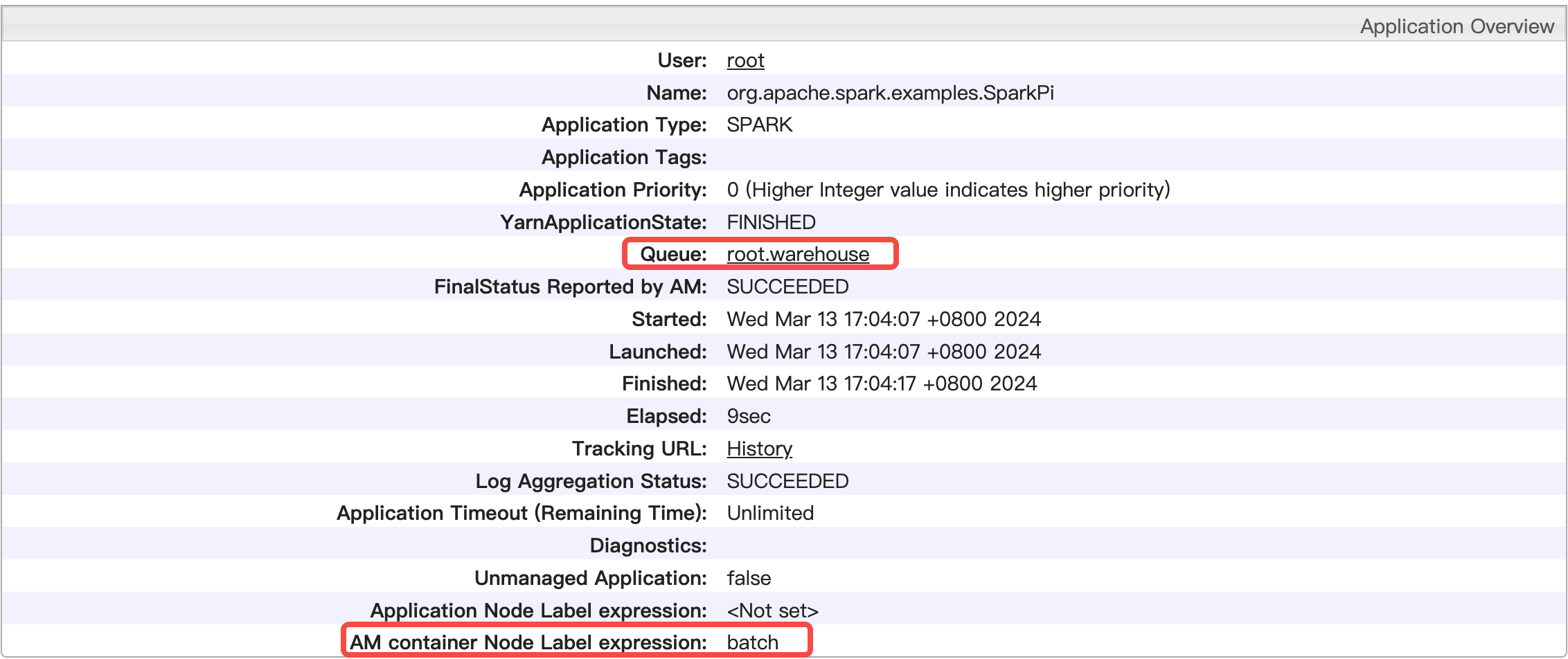
结论
通过合理使用YARN Node Label和Queue,可以提高资源分配的灵活性和效率,更好地满足业务需求。在实际应用中,可以根据自身的业务特点和集群环境进行合理规划和调整,以达到最佳的资源利用效果。