E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南Airflow高阶使用
E-MapReduce组件操作指南Airflow高阶使用

在本章节中,通过一些主题讨论指引您更好地编写符合您需求的 DAG 源文件。
1 DAG 控制流
在实际生产中,我们的工作流往往不是线性的,需要处理比较多样的分支情况,Airflow 大体上为我们提供了四大类用以控制流的方式,下面为您一一说明。
1.1 Branching Operator
Airflow 提供了一个BranchPythonOperator,它接受一个python_callable,要求该函数返回一个task_id(或者是一个task_id的列表),用以决定当前流程往后执行时应该走向某个或者某些特定的分支。
需要注意的是,BranchPythonOperator必须作为各子分支的直接上游,或者说该python_callable返回的task_id必须是其直接下游。
在分支系统中可能存在这样的情况,一个任务同时作为 branch operator 与一个或者多个选定任务的下游。在这样的情况下,即使该任务没有被 branch operator 选中,只要其余条件满足,该任务也依然会被执行。
from datetime import datetime from airflow.decorators import dag from airflow.operators.dummy import DummyOperator from airflow.operators.python import BranchPythonOperator @dag(schedule_interval=None, start_date=datetime(2022, 9, 14), catchup=False, tags=['example']) def demo_dag(): start = DummyOperator(task_id="start") def get_selected_tasks(): return "branch_a" branching = BranchPythonOperator( task_id="branching", python_callable=get_selected_tasks ) task_a = DummyOperator(task_id="branch_a") task_after_a = DummyOperator(task_id="after_a") task_b = DummyOperator(task_id="branch_b") join = DummyOperator(task_id="join") start >> branching branching >> task_a >> task_after_a >> join branching >> join branching >> task_b dag = demo_dag()
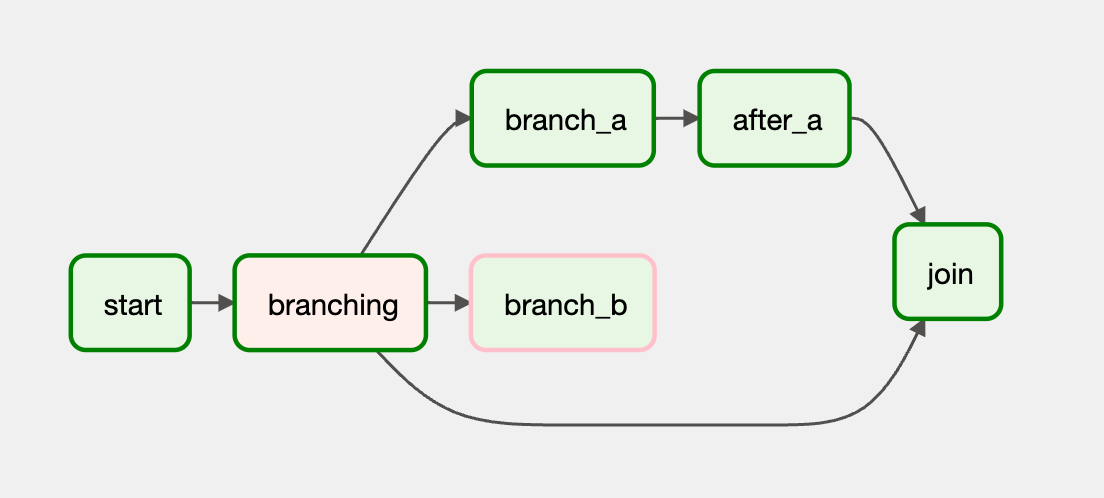
在以上示例代码中,我们的 branching 任务并没有选中 join 任务,但是作为 after_a 直接下游的它依然被执行了。
1.1.1 BaseBranchOperator
如果您有需求要实现自己的分支 operator 逻辑,可以继承自BaseBranchOperator做对应实现,要求提供一个方法choose_branch的实现。
和我们之前提供给BranchPythonOperator的方法很接近,实现的choose_branch也应当返回一个或多个task_id,这个范围以外的任务都会被跳过。
1.2 Depends On Past
这个模式指向一个比较特别的场景,可能某一个任务的执行与否,依赖于相同任务在前一次的 DAG Run 中的执行结果,只有前一次成功了,在本次调度中才会运行该任务。要使用该特性,应该在对应任务定义时,设置depends_on_past为True。
在 DAG 首次执行时,由于没有可以参考的前一次运行,Airflow 会直接执行该任务。
1.3 Only Latest
在很多时候,在我们运行的 DAG 的上下文中,其日期可能是过去的某个时间。比如说从之前的一个 Airflow 环境中迁移 DAG 到新的环境中,其定义中的 start_date 可能是很久以前,如果我们希望某些任务只基于当前时间,进行最近的一次调度,这时候可以通过使用LatestOnlyOperator来达成。LatestOnlyOperator在当前的 DAG Run 不是最新的时候,会自动跳过其所有下游。
import datetime from airflow import DAG from airflow.operators.dummy import DummyOperator from airflow.operators.latest_only import LatestOnlyOperator from airflow.utils.trigger_rule import TriggerRule with DAG( dag_id='latest_only_with_trigger', schedule_interval=datetime.timedelta(hours=6), start_date=datetime.datetime(2022, 9, 1), catchup=True, tags=['example3'], ) as dag: latest_only = LatestOnlyOperator(task_id='latest_only') task1 = DummyOperator(task_id='task1') task2 = DummyOperator(task_id='task2') task3 = DummyOperator(task_id='task3') task4 = DummyOperator(task_id='task4', trigger_rule=TriggerRule.ALL_DONE) latest_only >> task1 >> [task3, task4] task2 >> [task3, task4]
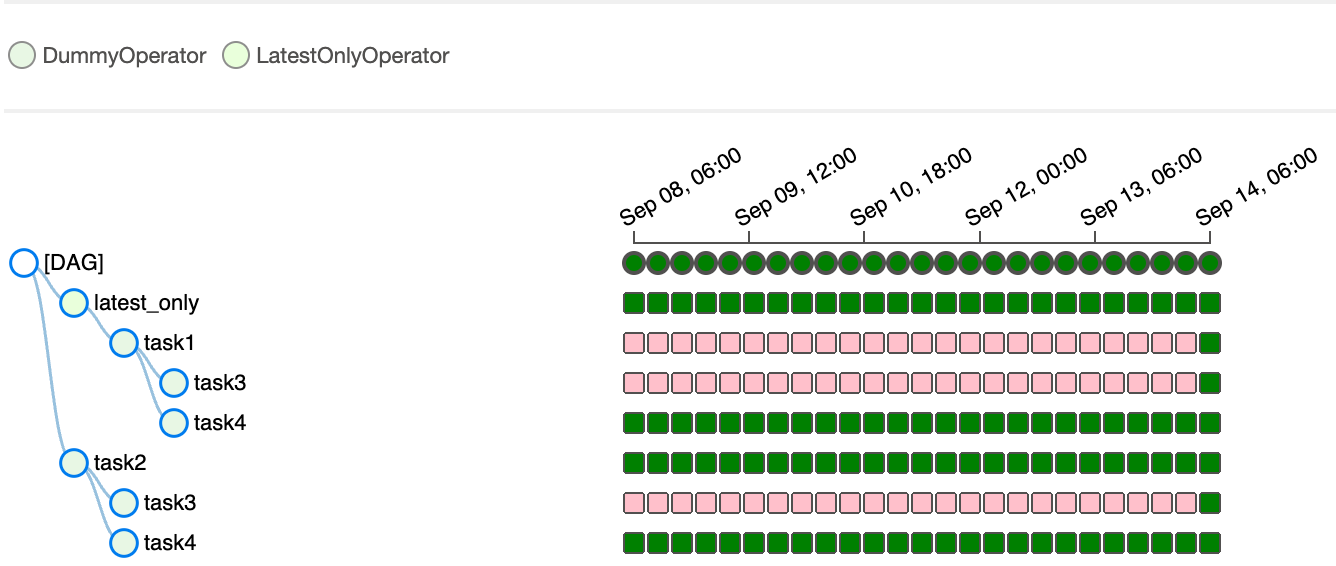
1.4 Trigger Rules
默认来说,一个任务只有在其全部上游任务都执行成功的时候才会进行自己的运行,但这个行为是可以被改变的,Airflow 提供了很多的触发规则来提供灵活度。
所有的 trigger_rule 如下:
- all_success:缺省值,需要全部上游任务都成功。
- all_failed:需要全部上游任务处于
failed或者upstream_failed状态。 - all_done:所有上游都完成各自的执行。
- one_failed:至少有一个上游任务失败,不需要等待所有上游结束。
- one_success:至少有一个上游任务成功,不需要等待所有上游结束。
- none_failed:所有上游任务要么成功,要么被跳过。
- none_failed_min_one_success:所有上游任务至少有一个成功,且没有失败的情况。
- none_skipped:没有任何上游任务被跳过。
- always:没有任何上游依赖,处于随时可以被调度执行的状态。
同 Depends On Past 结合使用可以更灵活。
在使用 all_success 或者 all_failed 时,如果结合 branching operator,那么可能导致任务被级联跳过,示例如下:
from datetime import datetime from airflow.decorators import dag from airflow.operators.dummy import DummyOperator from airflow.operators.python import BranchPythonOperator @dag(schedule_interval=None, start_date=datetime(2022, 9, 14), catchup=False, tags=['example']) def demo_dag_c(): start = DummyOperator(task_id="start") def get_selected_tasks(): return "branch_a" branching = BranchPythonOperator( task_id="branching", python_callable=get_selected_tasks ) task_a = DummyOperator(task_id="branch_a") task_after_a = DummyOperator(task_id="after_a") task_b = DummyOperator(task_id="branch_b") join = DummyOperator(task_id="join") start >> branching branching >> task_a >> task_after_a >> join branching >> join branching >> task_b >> join dag = demo_dag_c()
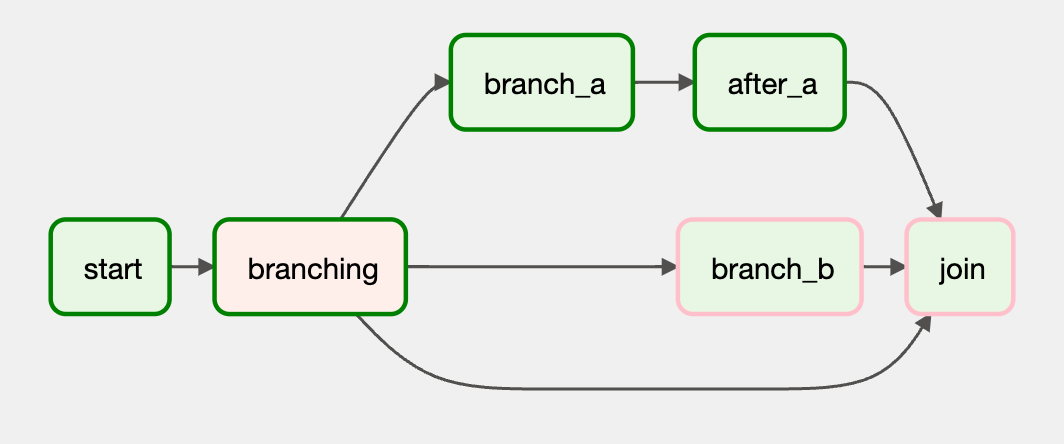
如果我们简单改动一下 join 的 trigger_rule,比如改为 none_failed_min_one_success,就可以让 join 被调度。
from datetime import datetime from airflow.decorators import dag from airflow.operators.dummy import DummyOperator from airflow.operators.python import BranchPythonOperator from airflow.utils.trigger_rule import TriggerRule @dag(schedule_interval=None, start_date=datetime(2022, 9, 14), catchup=False, tags=['example2']) def demo_dag_d(): start = DummyOperator(task_id="start") def get_selected_tasks(): return "branch_a" branching = BranchPythonOperator( task_id="branching", python_callable=get_selected_tasks ) task_a = DummyOperator(task_id="branch_a") task_after_a = DummyOperator(task_id="after_a") task_b = DummyOperator(task_id="branch_b") join = DummyOperator(task_id="join", trigger_rule=TriggerRule.NONE_FAILED_MIN_ONE_SUCCESS) start >> branching branching >> task_a >> task_after_a >> join branching >> join branching >> task_b >> join dag = demo_dag_d()
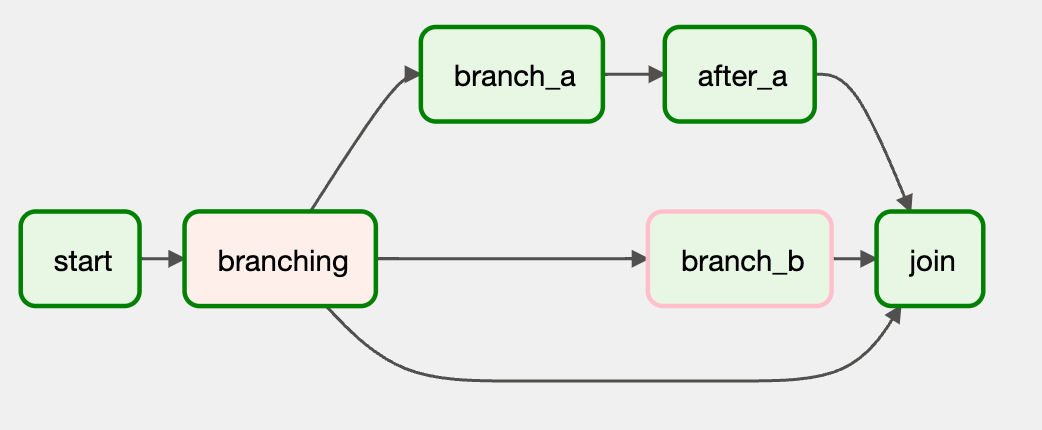
2 DAG 可视化定义
在 Airflow 中,对 DAG 的可视化展示有两个途径,一个是通过 Airflow UI,另外一个可以通过命令行airflow dags show {dag_id}得到对应的 digraph 结构。推荐来说,对 Airflow 负载的查看还是统一在 UI 进行比较友好,除了对应的图像展示外,还有配套的所有重点数据都能够方便获取到。
随着业务发展,对应的 DAG 逻辑可能会越来越复杂,这时候您可能希望针对 DAG 的逻辑图有一些定制与说明,下面是两种主要的方式:
2.1 任务分组
如果有一些任务在逻辑上可以用一个分组来统一纳入,这些分组在页面呈现时,支持折叠,可以有效减少逻辑图的复杂度;这是一个纯粹的 UI 上的概念,组内的 task 依然在 DAG 的上下文内。
with TaskGroup("group1") as group1: task1 = DummyOperator(task_id="task1") task2 = DummyOperator(task_id="task2") task3 = DummyOperator(task_id="task3") group1 >> task3
在 Group 级别,支持传入 default_args 替换 DAG 全局定义的部分。
with DAG(dag_id='dag1', default_args={'scope': 'DAG'}) as dag: with TaskGroup("group1", default_args={'scope': 'group1'}) as group1: task1 = DummyOperator(task_id="task1") task2 = DummyOperator(task_id="task2") task3 = DummyOperator(task_id="task3") group1 >> task3
默认的,一个 Taskgroup 中的 task 对应的 task_id 是以该组的 group_id 为前缀的,这可以确保组内任务有自己独特的 id,当然该行为可以关闭,通过设置prefix_group_id=False即可。
2.2 边的标签化
如果一个 DAG 足够复杂,特别是有很多分支情况时,我们可能想要在不同分支延伸出去的边上有对应的描述,更直观,而不需要参照着 DAG 的代码定义来理解该工作流。
可以直接在>>与<<操作符的中间插入一个 Label 对象,即可对对应边进行描述。
from airflow.utils.edgemodifier import Label my_task >> Label("When empty") >> other_task
如果使用的是对象方法来定义上下游,可以通过属性来定义。
from airflow.utils.edgemodifier import Label my_task.set_downstream(other_task, Label("When empty"))
示例
3 SubDAGs
在很多时候,您发现可能在很多 DAG 中有相似的 task 定义,希望能将这些任务抽取出来在各个 DAG 中进行复用,可以使用 SubDagOperator 来实现,这个算子接受一个返回 DAG 对象的方法,这个 DAG 中可以包含不定数量的方法,这些方法有一些独立于外部 DAG 的属性和用法,下面一一为您梳理。
首先我们定义一个方法,返回一组任务对象:
from datetime import datetime from airflow import DAG from airflow.operators.dummy import DummyOperator def subdag(parent_dag_name, child_dag_name, args): """ Generate a DAG to be used as a subdag. :param str parent_dag_name: Id of the parent DAG :param str child_dag_name: Id of the child DAG :param dict args: Default arguments to provide to the subdag :return: DAG to use as a subdag :rtype: airflow.models.DAG """ dag_subdag = DAG( dag_id=f'{parent_dag_name}.{child_dag_name}', default_args=args, start_date=datetime(2021, 1, 1), catchup=False, schedule_interval="@daily", ) for i in range(5): DummyOperator( task_id=f'{child_dag_name}-task-{i + 1}', default_args=args, dag=dag_subdag, ) return dag_subdag
注意到这里定义 dag_id 与 task_id 时用了一些前缀,这是一个比较好的实践,保持 id 独特的同时自描述避免混淆。
这里定义的 DAG 需要有一个调度逻辑并且是 enabled 的,不能将schedule_interval设置为None或者@once,否则在实际使用的时候,会被直接设置为 succeed 状态并且什么也不执行。
from airflow import DAG from airflow.example_dags.subdags.subdag import subdag from airflow.operators.dummy import DummyOperator from airflow.operators.subdag import SubDagOperator from airflow.utils.dates import days_ago DAG_NAME = 'example_subdag_operator' args = { 'owner': 'airflow', } with DAG( dag_id=DAG_NAME, default_args=args, start_date=days_ago(2), schedule_interval="@once", tags=['example'] ) as dag: start = DummyOperator( task_id='start', ) section_1 = SubDagOperator( task_id='section-1', subdag=subdag(DAG_NAME, 'section-1', args), ) some_other_task = DummyOperator( task_id='some-other-task', ) section_2 = SubDagOperator( task_id='section-2', subdag=subdag(DAG_NAME, 'section-2', args), ) end = DummyOperator( task_id='end', ) start >> section_1 >> some_other_task >> section_2 >> end # [END example_subdag_operator]
在主体 DAG 中,有两个 SubDagOperator 对象,没有额外定义重复的 task。注意到在创建 SubDAG 对象时将外部 DAG 的 args 传给了构造的方法,这是一种保持内外环境一致的好实践。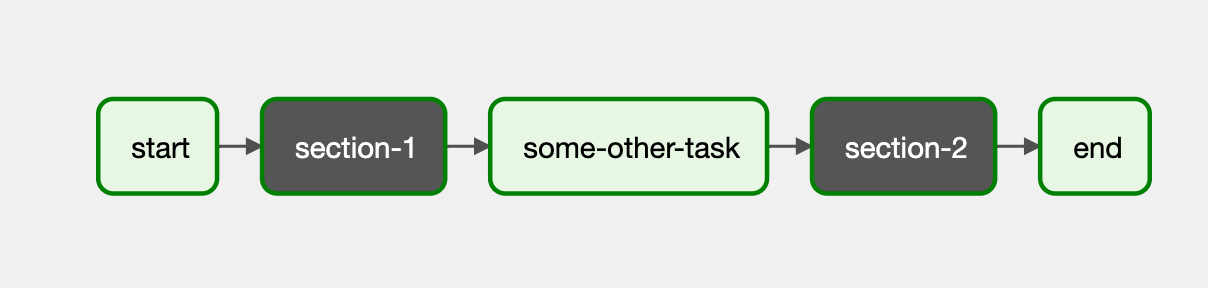
对于subDAG,点击后通过弹窗的Zoom into Sub DAG按钮可以查看该 DAG 内部具体任务实例的状态。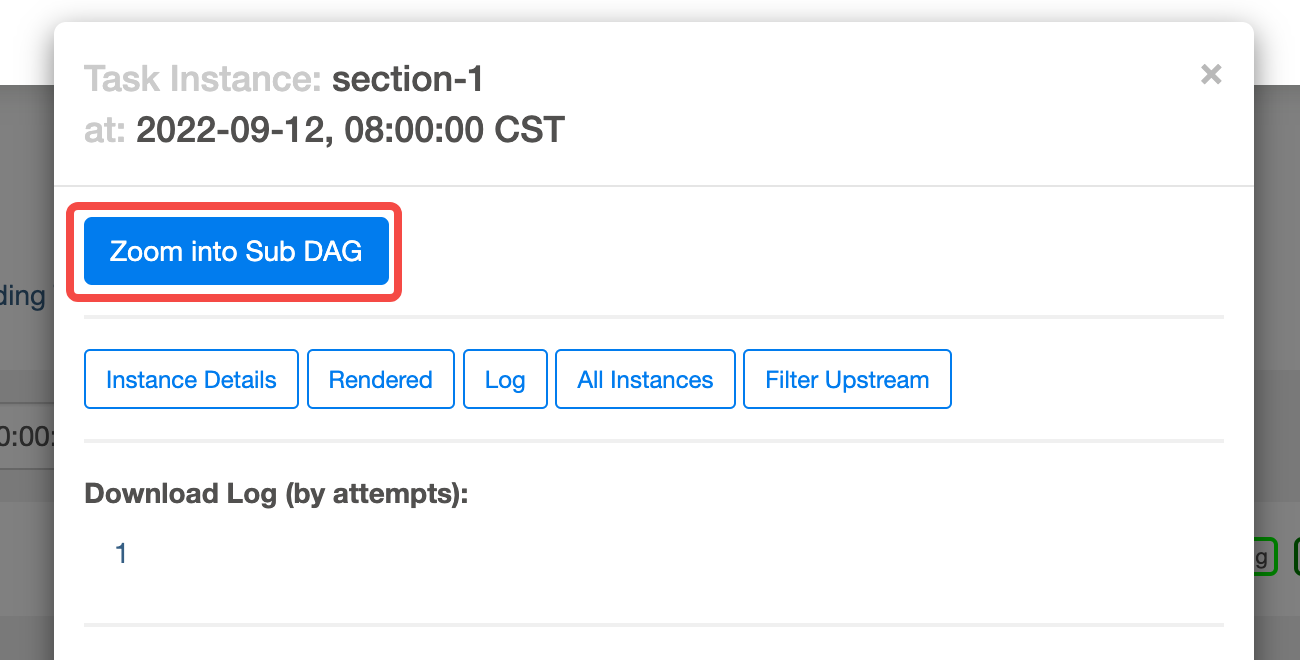
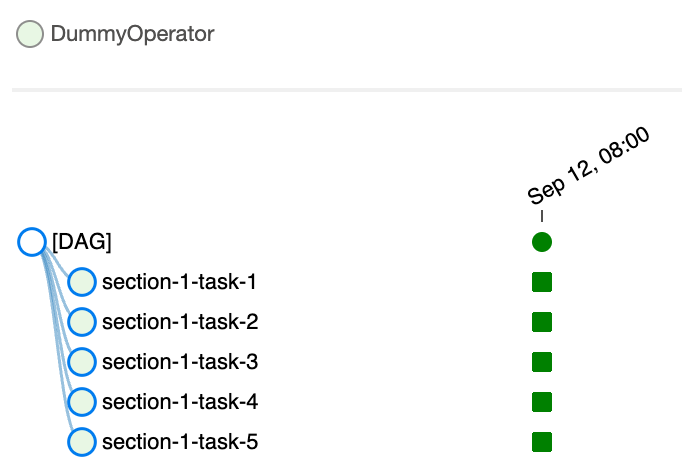
对于一个 SubDAG 的 clear,会连带着将其内部所有 task 的状态清除。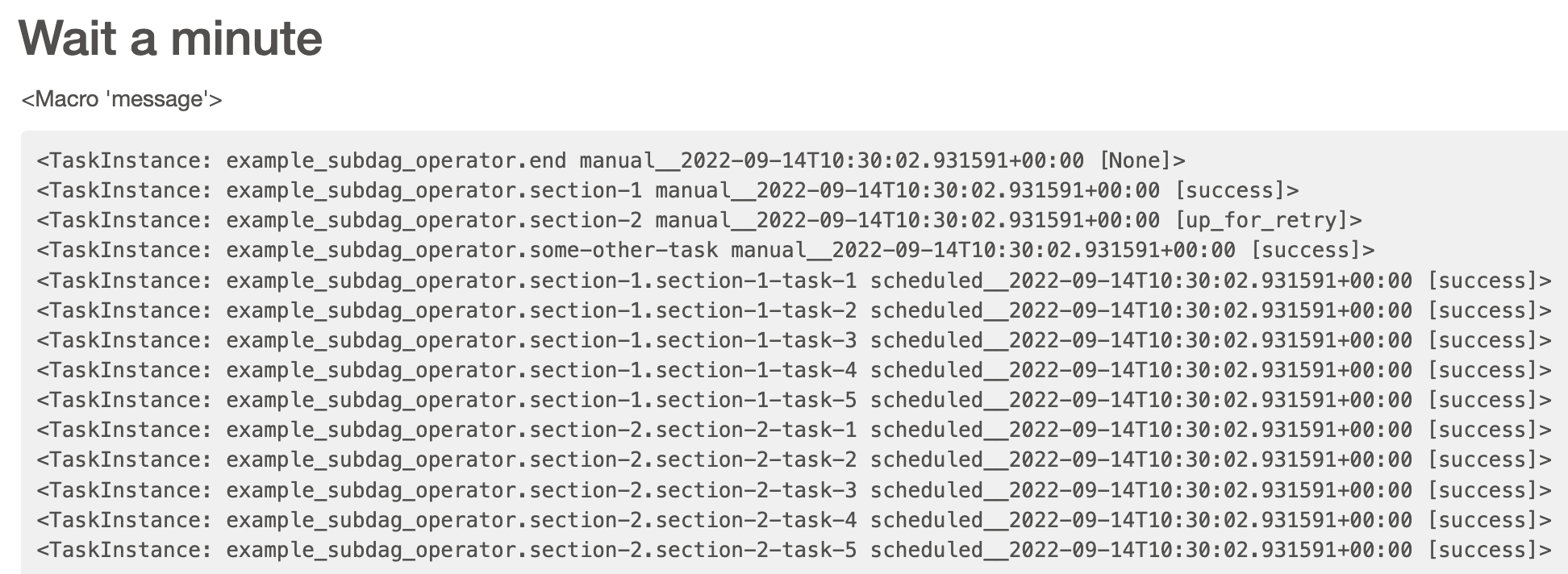
需要注意的是,对于 SubDAG 来说,是没有 Pool 的概念的,所以它在执行的时候,是可能占用超过我们预设的资源量的。
4 高可用访问集群内其他服务
本文档主要解决在高可用集群中 Airflow 访问集群内其他服务存在的单点问题。
在高可用集群中会在不同节点上部署多个组件实例,比如 Presto 的 Coordiantor 组件,那么您在 Airflow 中执行 Presto 作业时预期 Presto 能够应对 Presto 的单点故障,可以实时切换到可用 Presto Coordinator 组件实例上。但实际上 Airflow 在实现上只能配置一个 Presto Coordinator 的地址,无法满足高可用的需求。下面会以 Presto 和 Trino 为例,引入火山引擎上的负载均衡服务来解决高可用访问的问题,其余服务都可以通过类似的方式来解决。
准备工作
首先,您需要购买或者选择一个已有的负载均衡实例,该实例需要与您的集群在同一个 VPC,且该实例的网络类型为 私网。
高可用访问配置:Presto/Trino
Airflow 默认访问第一个 Presto/Trino Coordinator 实例(master-1-1),如果该 Coordinator 实例不可用, 则 Airflow 执行Presto任务会失败,这时候需要通过负载均衡来将 Airflow 的流量路由到可用的 Coordinator 实例。
- 首先,您需要确定 Presto/Trino Coordinator 部署的 ECS 实例,这可以通过 EMR 控制台的服务列表-部署拓扑查找。
- 然后在所选的负载均衡内创建后端服务器组,并将相应的 ECS 加入该后端服务器组, 其中的端口就是 Coordinator 的监听端口,可以通过查询 Presto/Trino 的服务参数
http-server.http.port(http-server.https.enabled 为 true 时,查找 http-server.https.port) 来获得。 - 然后添加监听器,根据 Coordinator 的情况填写 负载均衡协议(TCP),后端服务器组选择刚创建的后端服务器组,开启健康检查,健康检查路径、超时时间均为默认值即可(注意这边需要在 ECS 所在安全组内放通负载均衡的网段,否则会造成健康检查异常和访问异常)。
- 创建完监听器,则可以将上述负载均衡的 IP 地址配置到 Airflow 中。需要登录访问 Airflow 的 WebUI 界面,修改 Presto 的 Connection 配置。
- 将 Host 修改为负载均衡的 私网/公网 IP 地址,然后点击 Save 保存即可。
说明
议配置为私网IP,如果您开启了公网,并且在CLB的黑白名单没有限制也可以配置为公网IP。