火山引擎入门实验
火山引擎入门实验



文档指南

请输入


- 文档首页
 火山引擎入门实验中间件使用Logstash消费Kafka中的数据并写入到云搜索
火山引擎入门实验中间件使用Logstash消费Kafka中的数据并写入到云搜索

使用Logstash消费Kafka中的数据并写入到云搜索
前言
Kafka 是一个分布式、支持分区的(partition)、多副本的(replica) 分布式消息系统, 深受开发人员的青睐。
云搜索服务是火山引擎提供的完全托管的在线分布式搜索服务,兼容 Elasticsearch、Kibana 等软件及常用开源插件,为您提供结构化、非结构化文本的多条件检索、统计、报表
在本教程中,您将学习如何使用 Logstash 消费 Kafka 中的数据,并写入到云搜索服务中。
关于实验
预计部署时间:20分钟
级别:初级
相关产品:消息队列 - Kafka & 云搜索
受众: 通用
环境说明
如果还没有火山引擎账号,点击此链接注册账号
如果您还没有VPC,请先点击链接创建VPC
消息队列 - Kafka
云搜索
云服务器ECS:Centos 7
在 ECS 主机上准备 Kafka 客户端的运行环境,提前安装好Java运行环境
在 ECS 主机上安装 Logstash
实验步骤
步骤一:准备 Logstash 配置文件
Logstash 配置文件有如下格式:
input{ 数据源 } filter{ 处理方式 } output{ 输出目标端 }
我们使用如下配置文件:在如下配置文件中的 input 部分,我们使用了 Kafka 的默认接入点地址,同时指定了需要消费的 Topic。在 output 部分,我们指定了需要连接的 云搜索集群地址,索引以及用户名密码。
input { kafka { bootstrap_servers => "xxxxxx.kafka.ivolces.com:9092" topics => "quickstart-events" } } output { opensearch { hosts => ["https://xxxxxxx.escloud.volces.com:9200"] index => "kafkatoes" user => "xxx" password => "xxxxx" ssl_certificate_verification => false } }
步骤二:启动 Logstash
您可以使用如下方式来启动 Logstash
[root@rudonx bin]# pwd /root/logstash-8.4.0/bin [root@rudonx bin]# ./logstash -f /root/logstash.conf
步骤三:生产消息
您可以使用 Kafka 提供的 console consumer 来生产消息,使用命令如下:
[root@rudonx kafka_2.11-2.2.2]# pwd /root/kafka_2.11-2.2.2 [root@rudonx kafka_2.11-2.2.2]# ./kafka-console-producer.sh --broker-list xxxxxx.kafka.ivolces.com:9092 --topic quickstart-events > 1 rudonx > 2 liwangz >
步骤四:在云搜索中查查看数据
我们可以在云搜索控制台找到 Kibana 地址,进行登录后运行如下语句:
GET kafkatoes/_search { "query": { "match_all": {} } }
会有如下输出: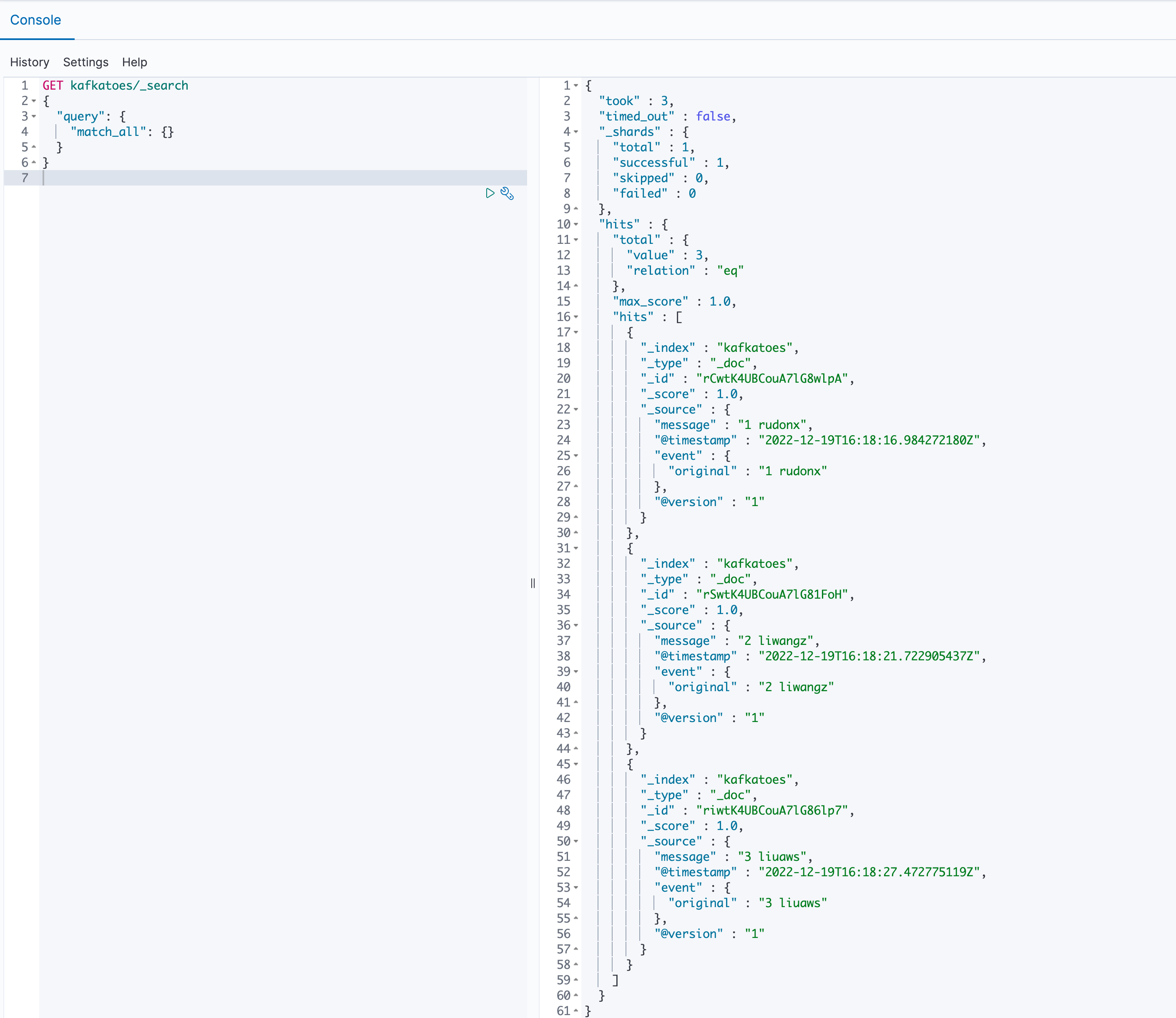
步骤五:清除数据并删除集群
您可以从 Kafka & 云搜索控制台中轻松删除集群。您可以删除不再使用的实例,以免继续为其付费。
如果您有其他问题,欢迎您联系火山引擎技术支持服务。
最近更新时间:2022.12.20 20:46:35
这个页面对您有帮助吗?
有用
有用
无用
无用