.jpeg)

核心能力
方案架构
方案优势
视频演示
合作案例
核心能力
立即咨询
AI 生态
丰富推理框架兼容
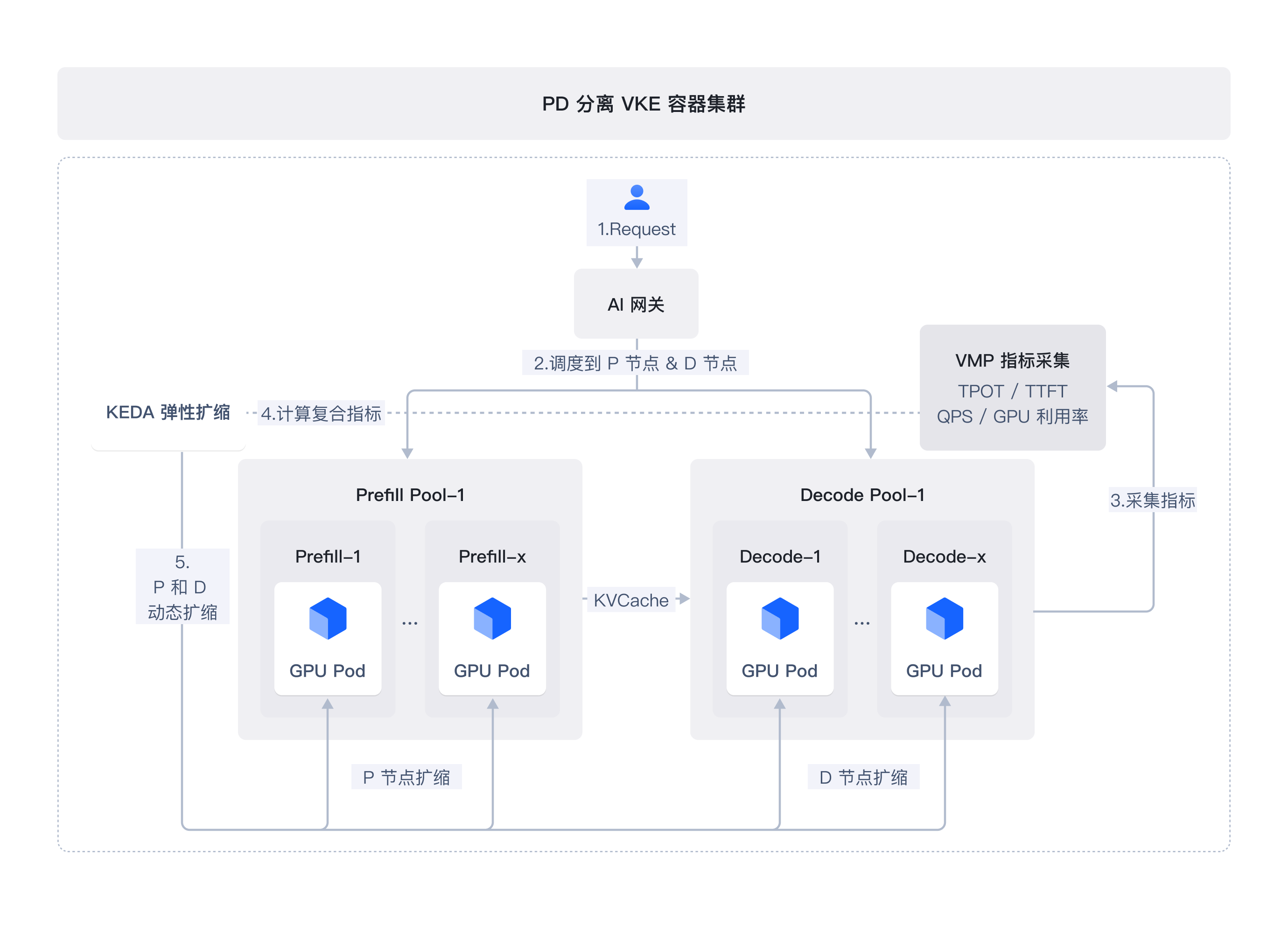
深度适配 vLLM/SGLang/Dynamo 等主流推理框架,率先支持 Dynamo 的 PD 分离架构,助力推理效率提升。
灵活高效
推理算力提效
支持流量和算力灵活调度,基于复合指标实现海量算力弹性、精准、快速调用和出让,提升整体 GPU 资源利用率。
卓越性能
LLM 推理加速
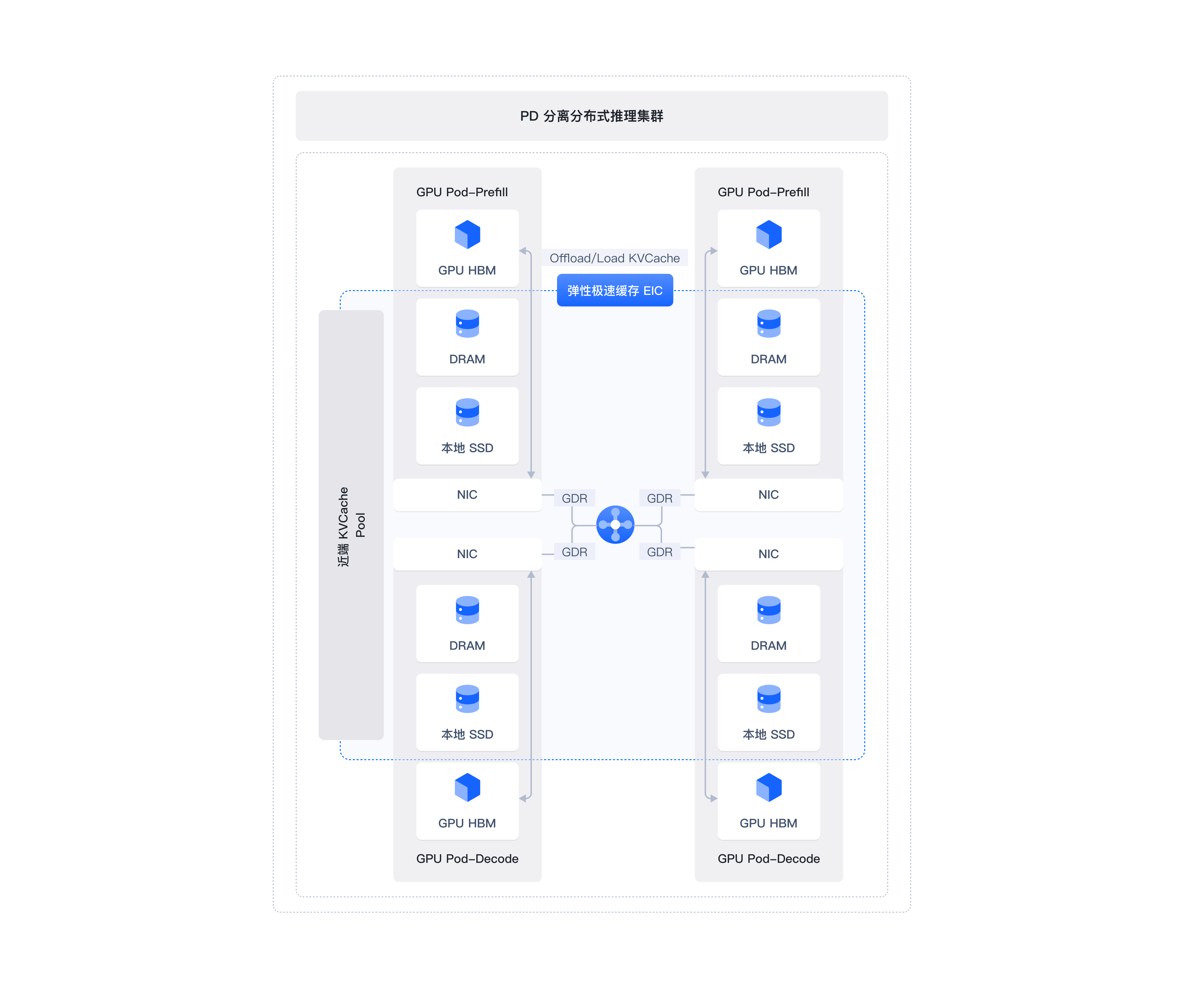
部署 PD 分离架构的推理服务,结合引擎优化、算子优化及分布式缓存的运用,大幅提升端到端大模型推理性能。
全面追踪
全链路推理观测
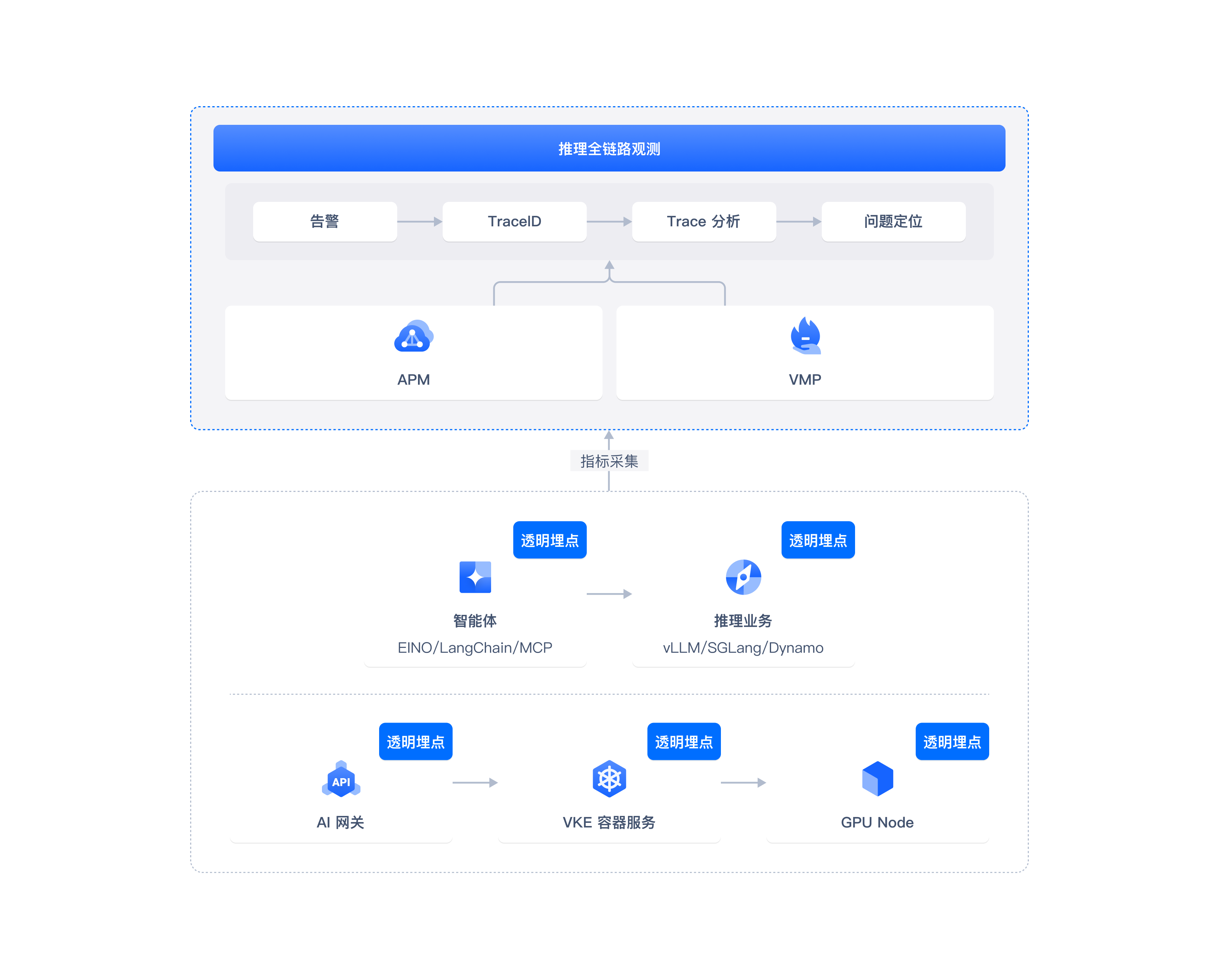
火山方舟同款观测服务:推理全链路透明埋点,全方位覆盖 AI 推理引擎观测指标,推理问题分钟级精准定位。
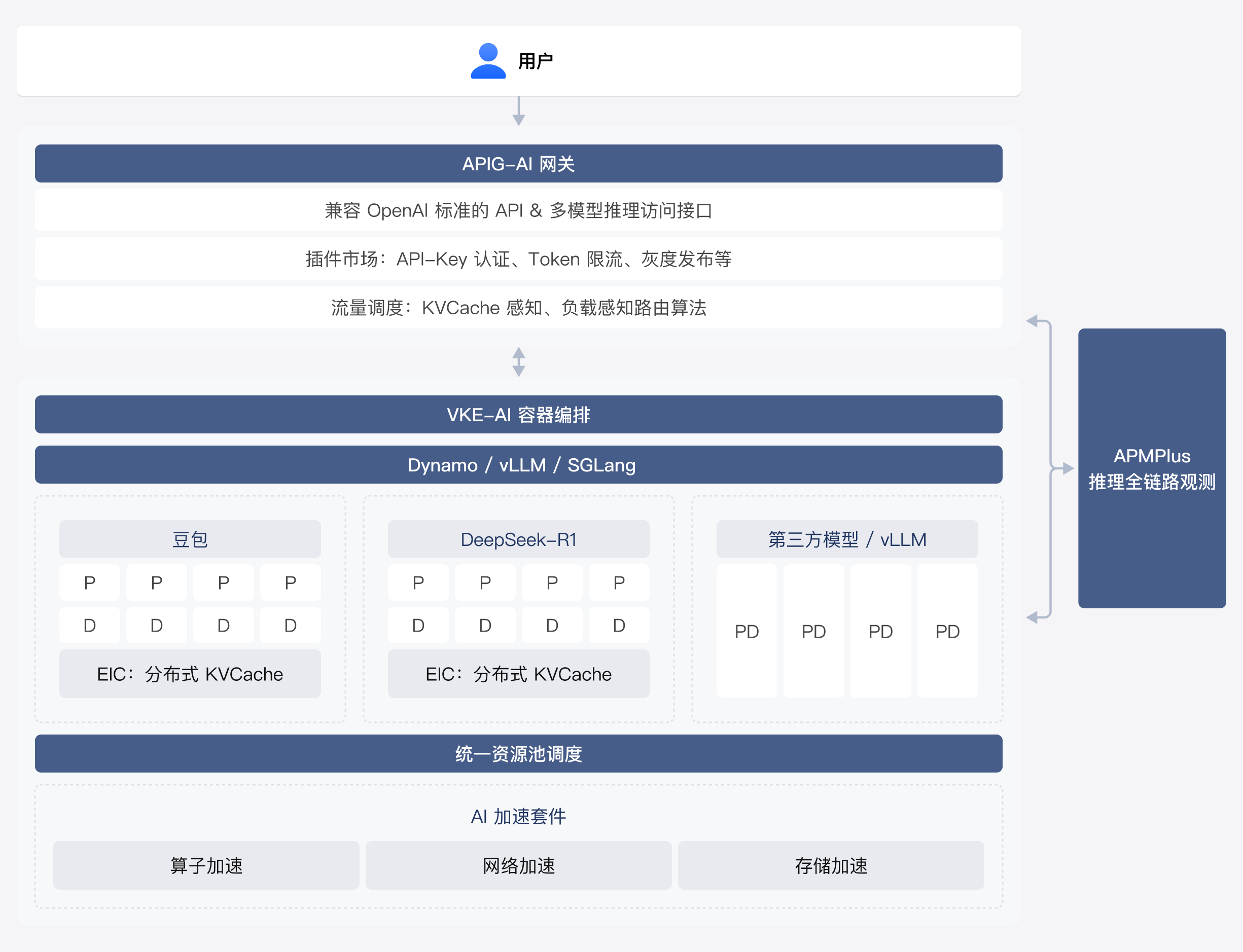
方案优势
模型极速启动
算子加速
AI 网关
PD 分离编排
多级分布式缓存
推理全链路观测
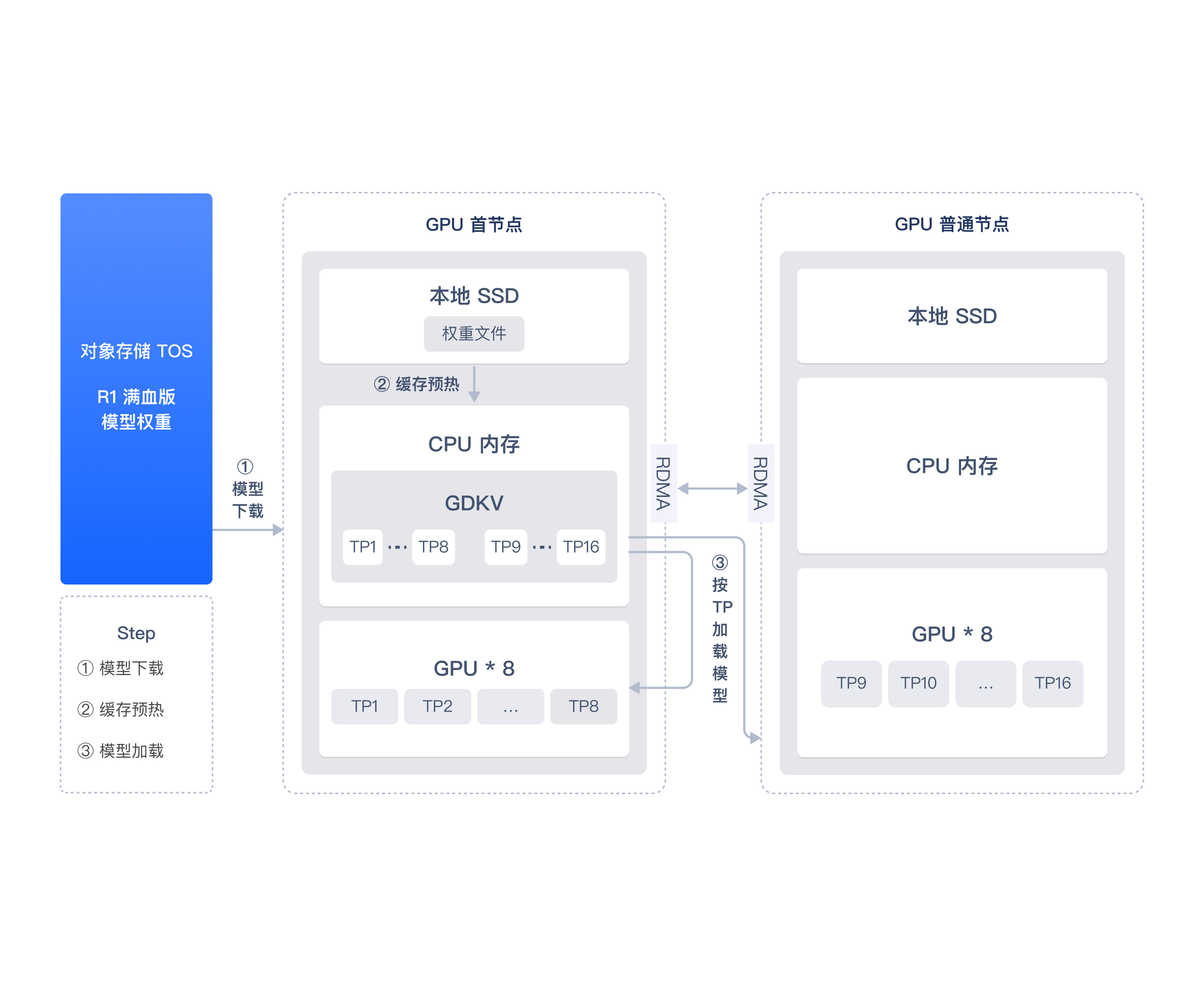
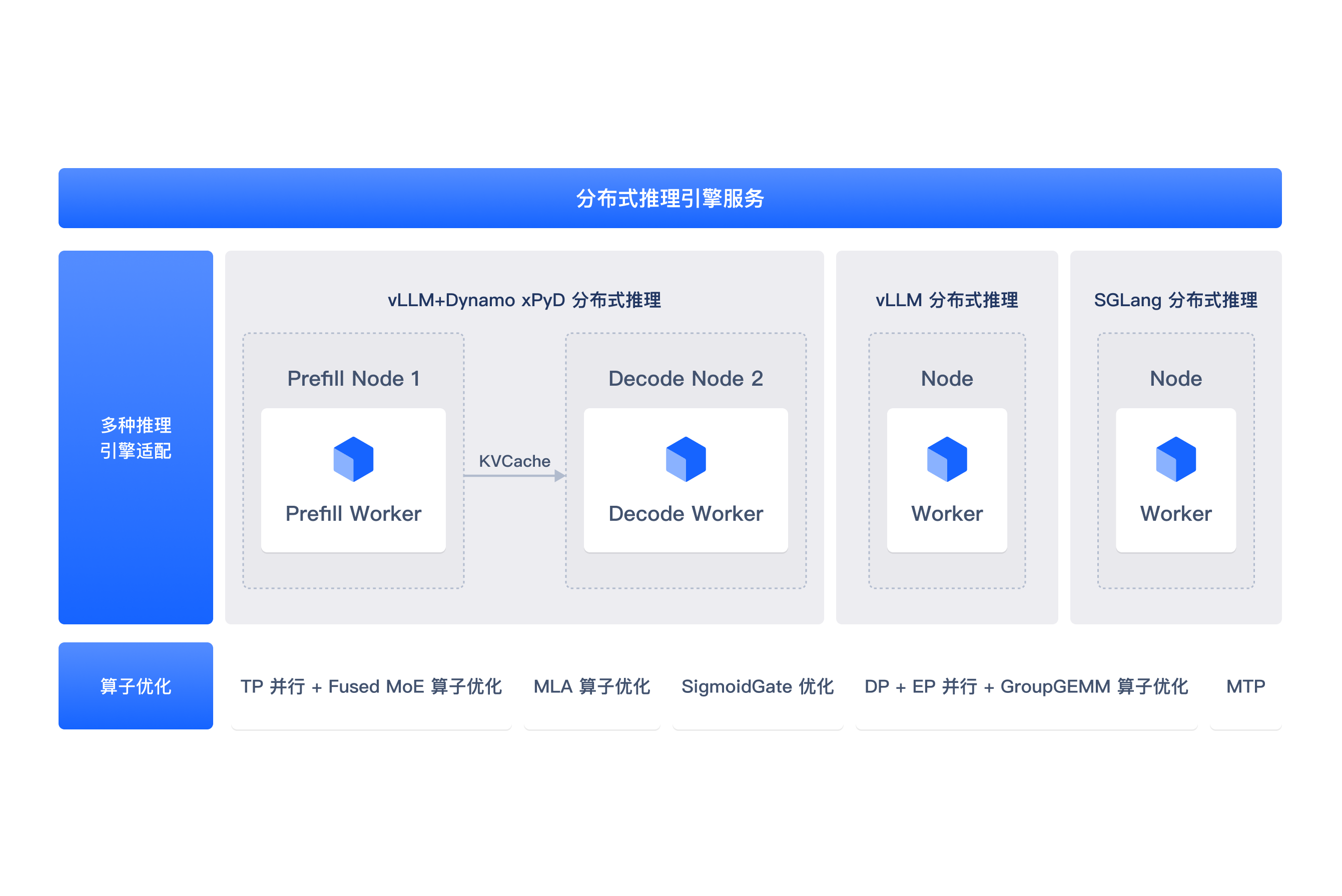
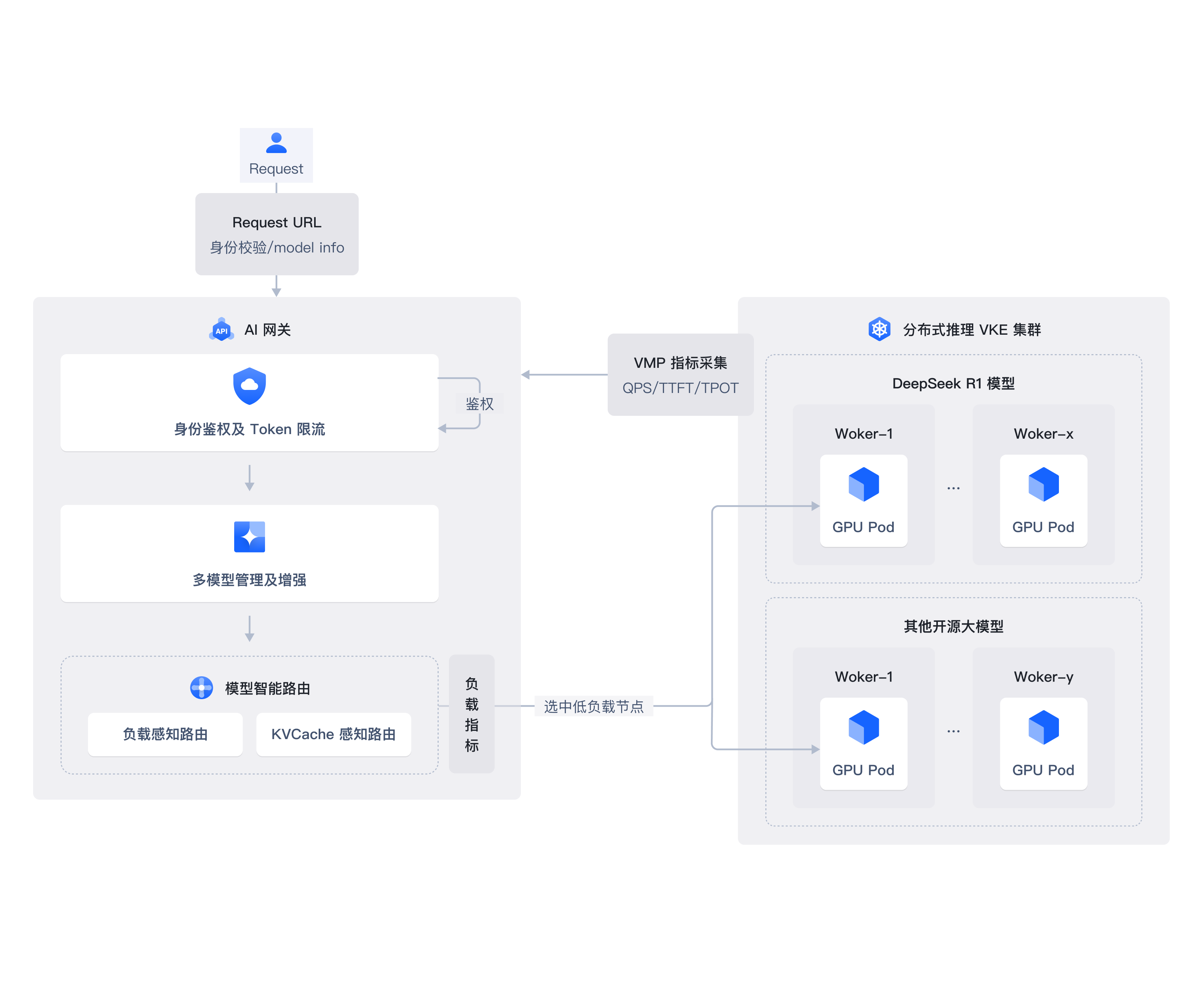
大模型时代更开放普惠的 AI 云服务
大模型时代更开放普惠的 AI 云服务
大模型时代更开放普惠的 AI 云服务
大模型时代更开放普惠的 AI 云服务
合作案例
借鉴真实成功案例经验,助力业务增长
“传统搜索和 AI 大模型结合,直播间的用户在搜索场景得到更优的体验。”
——虎牙直播
“基于火山引擎推理套件部署 R1,TTFT(mean) 优化约 230%, TPOT(mean) 优化约 17%。”
——某出海客户
“传统搜索和 AI 大模型结合,直播间的用户在搜索场景得到更优的体验。”
——虎牙直播
“基于火山引擎推理套件部署 R1,TTFT(mean) 优化约 230%, TPOT(mean) 优化约 17%。”
——某出海客户

上火山引擎,用豆包大模型