


方案能力
方案架构
应用场景
客户案例
接入流程
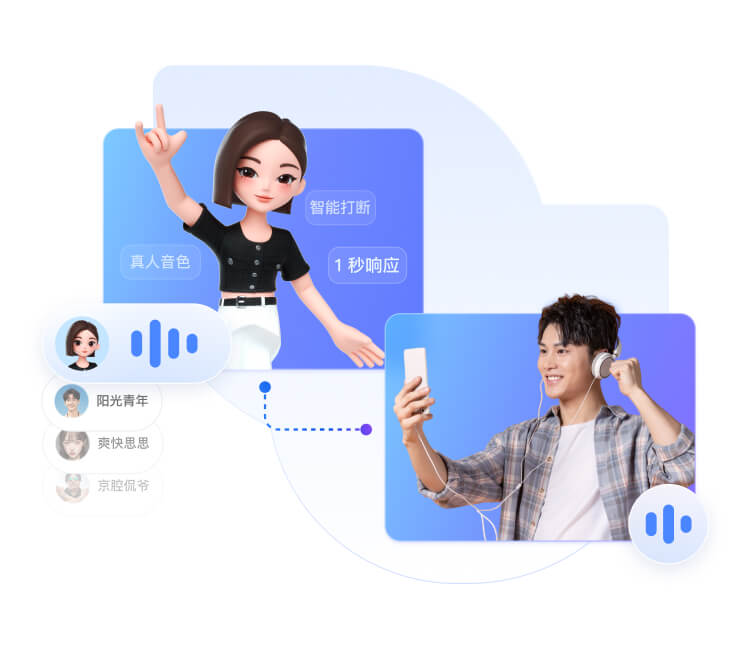
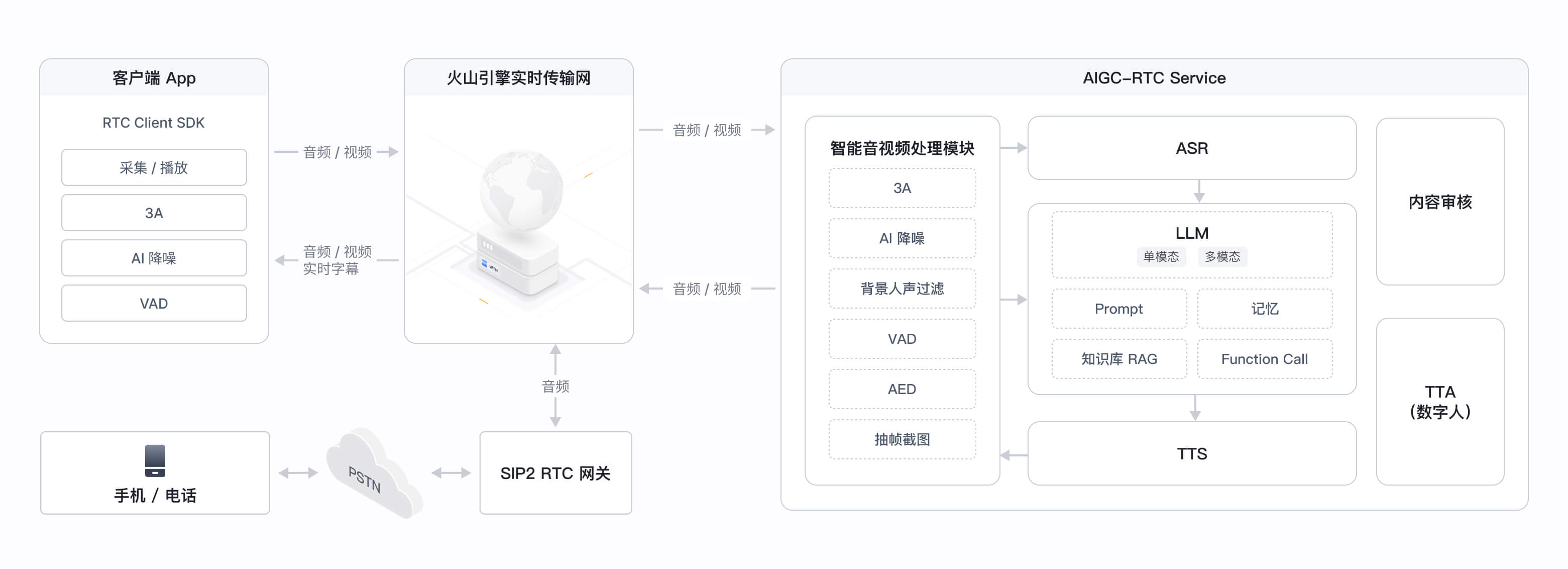
让大模型像真人一样会听会看会说
端上降噪
智能打断
超低延时
抗弱网
真人音色
灵活扩展


端上降噪
通过 RTC SDK 实现对复杂环境的音频降噪能力,有效降低背景噪音、背景音乐的干扰,提高用户语音打断的准确性
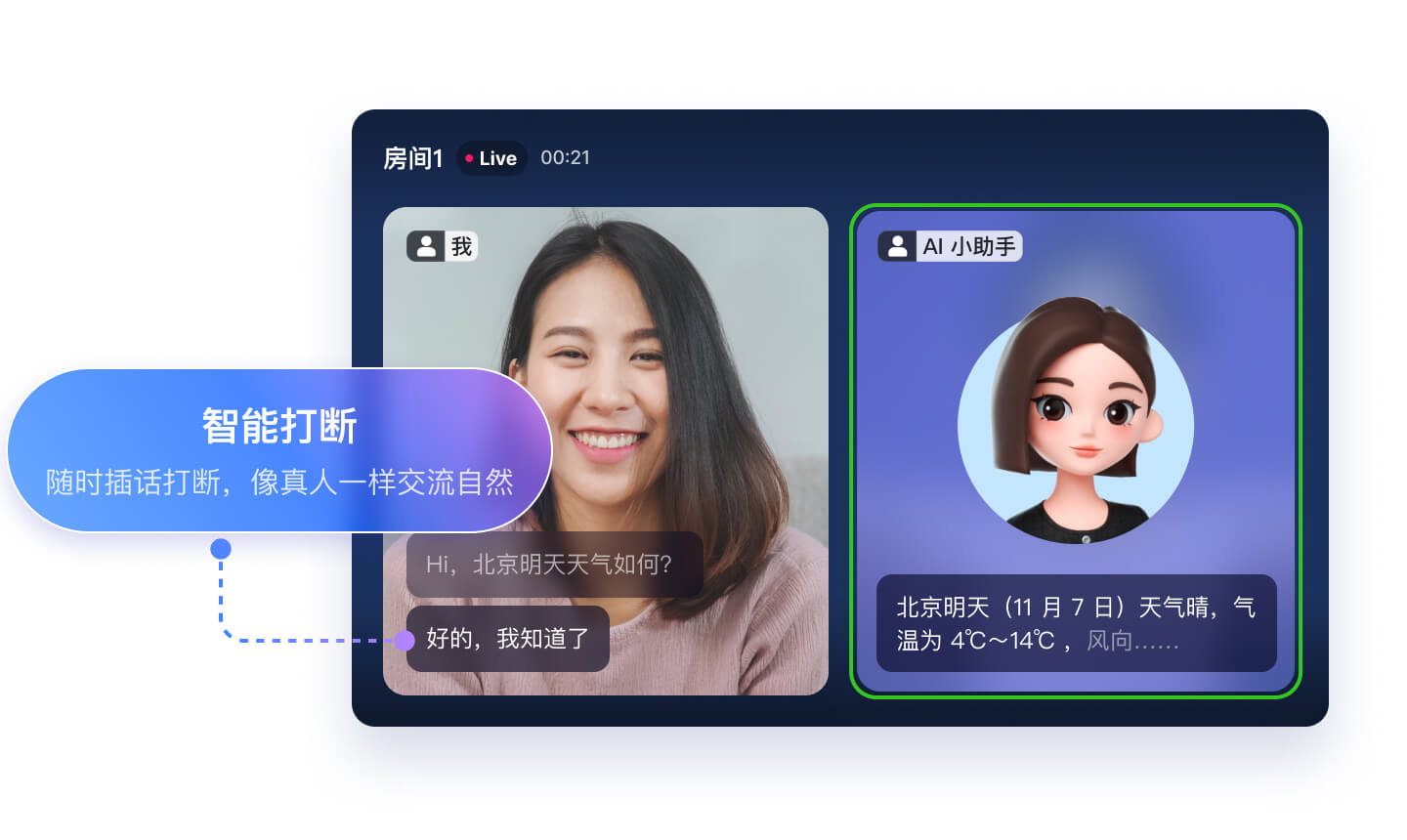
智能打断
支持全双工通信及音频帧级别的人声检测(VAD),随时插话打断,交流更自然
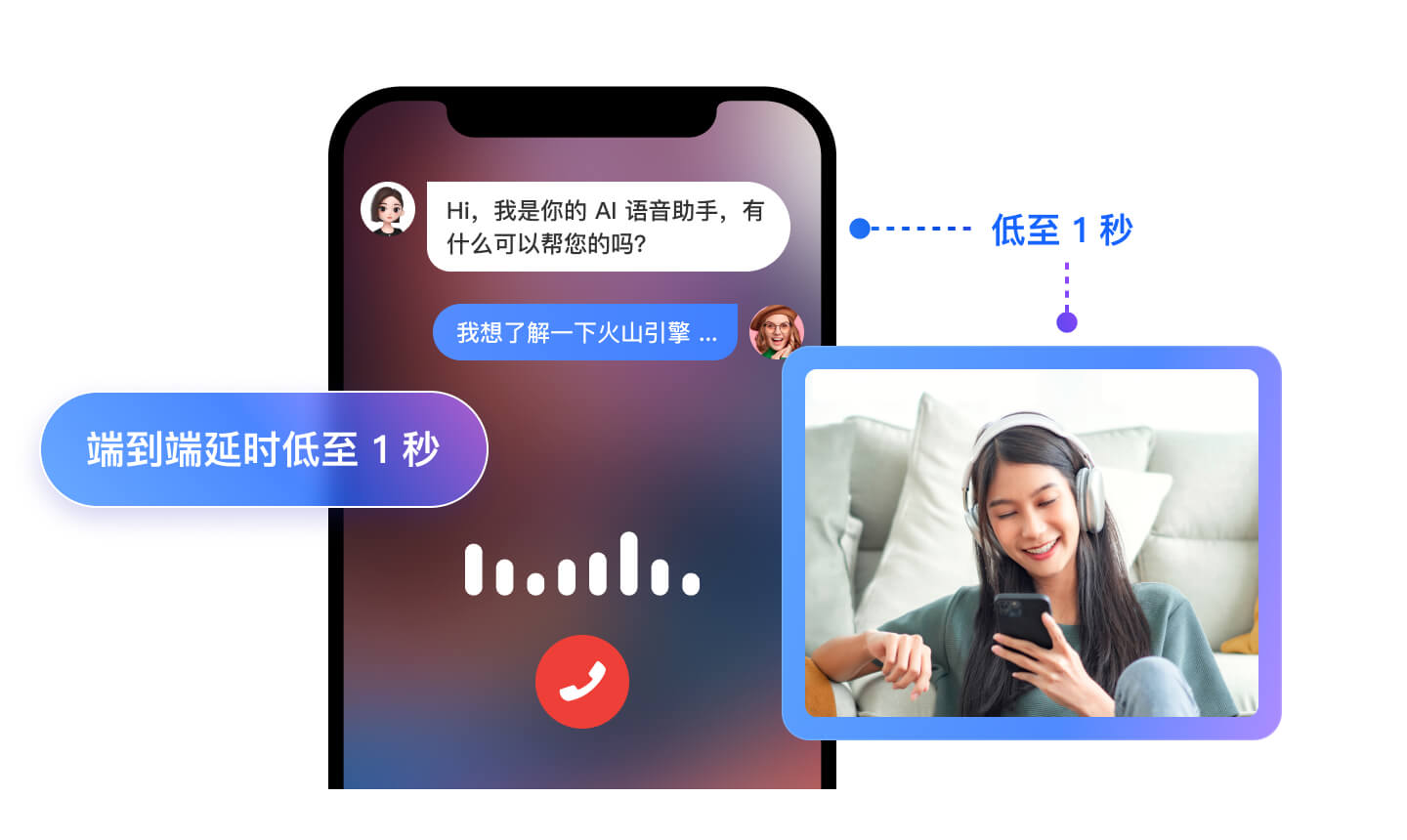
超低延时
通过音频流式处理算法,优化 RTC+ASR+LLM+TTS 各个环节的交互延时,端到端整体时延低至 1 秒
抗弱网
通过智能接入、RTC 云端协同优化,在复杂和弱网环境下确保低延时和传输可靠性,避免因丢字引起大模型理解错误
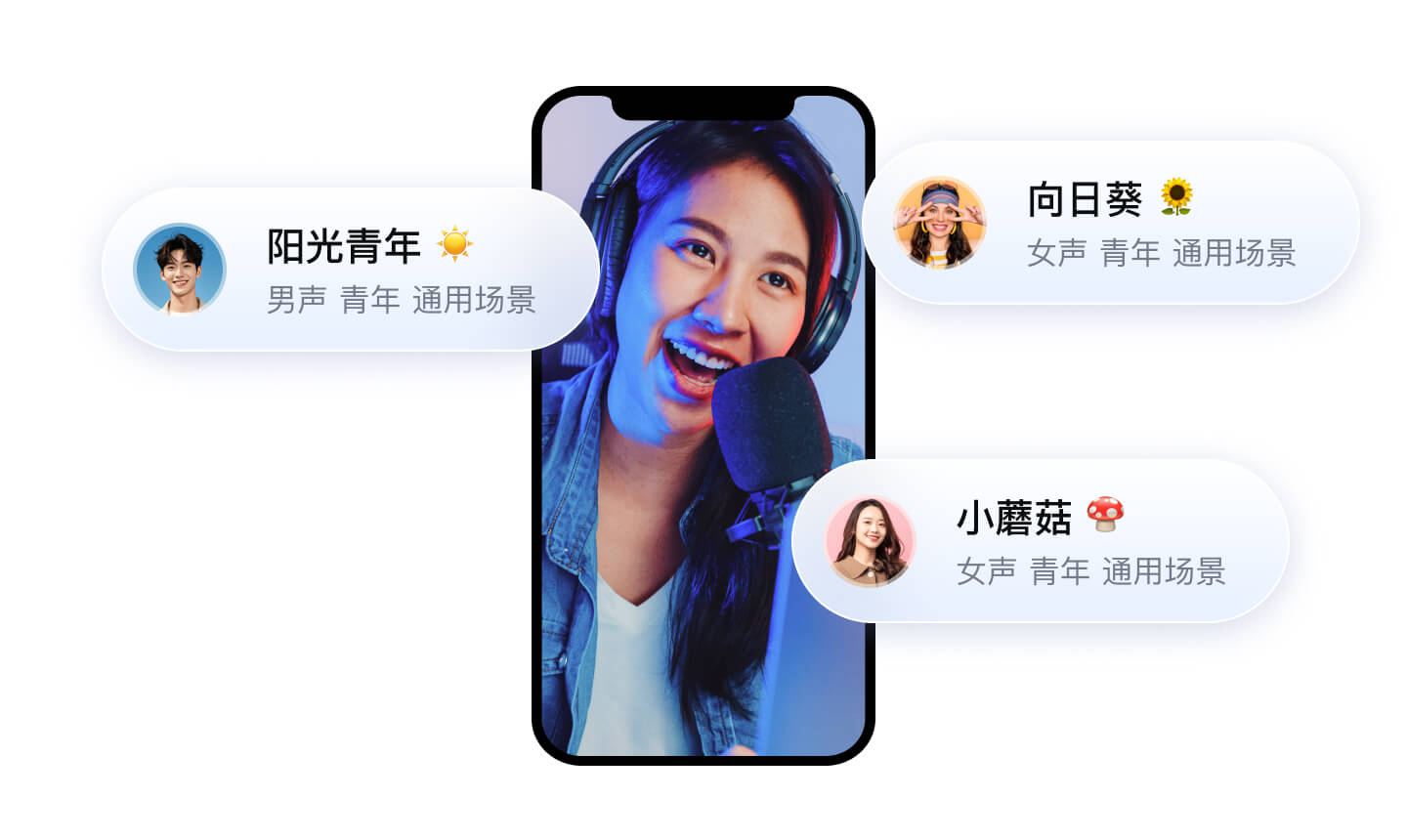
真人音色
支持豆包同款音色,自然生动,善于演绎
支持声音复刻,1:1 还原,个性化定制
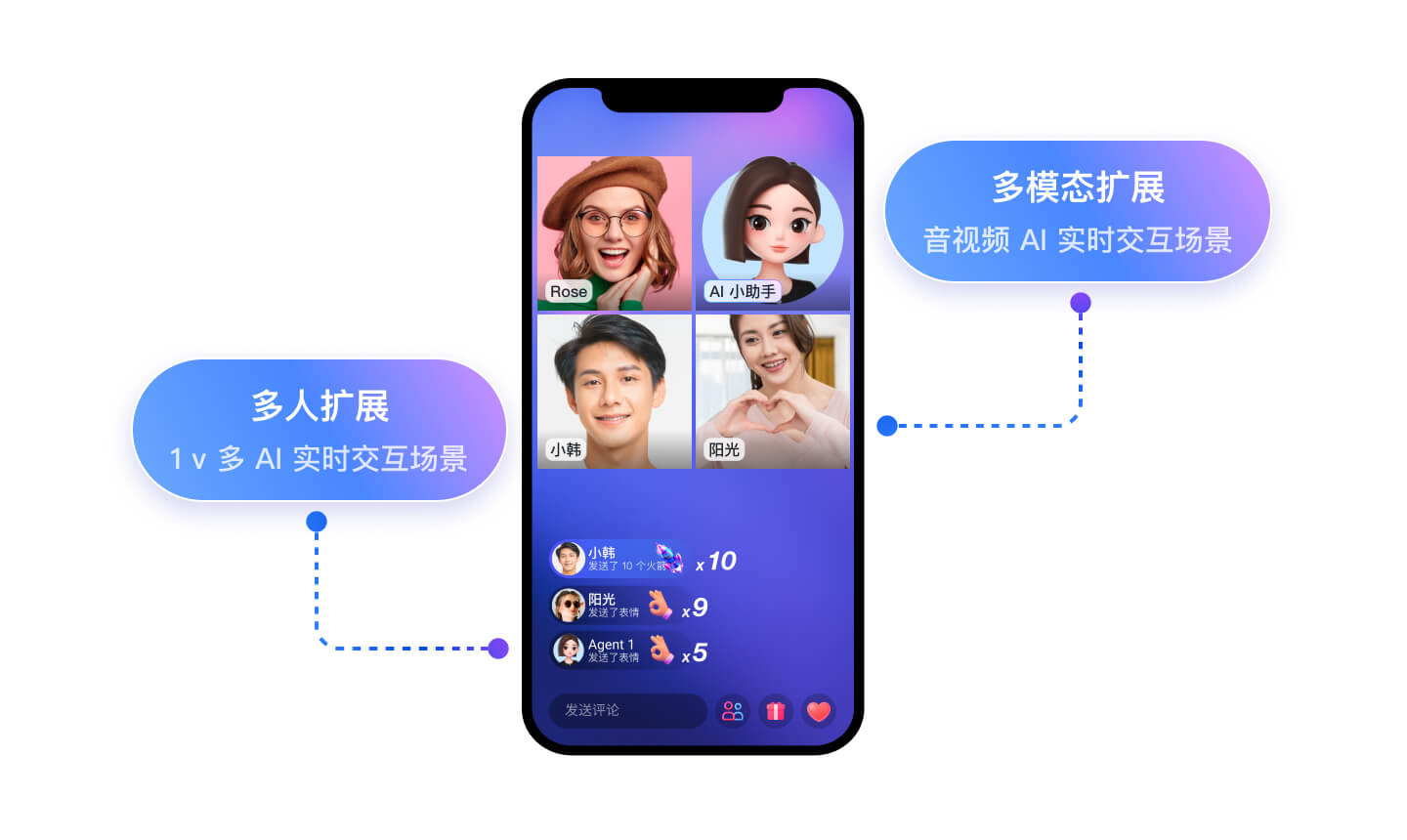
灵活扩展
多人扩展:可无缝扩展至 1v多 AI 实时交互场景
多模态扩展:可无缝扩展至音视频 AI 实时交互场景

适用于不同场景的AI应用
社交陪伴
儿童陪伴
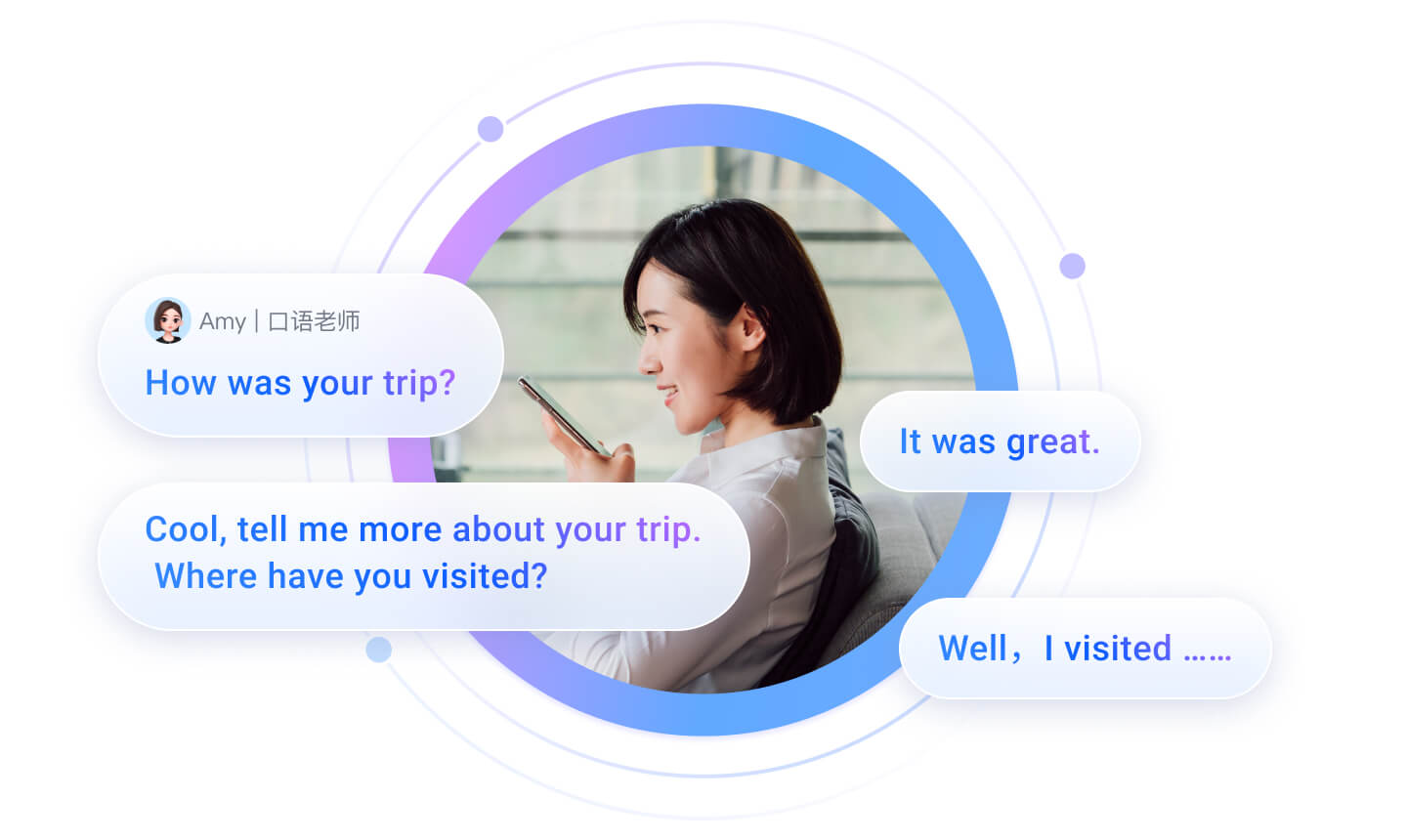
口语教学
智能硬件
智能客服




社交陪伴
儿童陪伴
口语教学
智能硬件
智能客服
社交陪伴
儿童陪伴
口语教学
智能硬件
智能客服












创建你的第一个实时对话式AI应用
了解开发流程,试试无代码跑通「实时对话式AI」Demo
01
开通服务
注册并开通火山引擎RTC/ASR/TTS/LLM
02
集成SDK
集成火山引擎RTC SDK实现采集与进房通话功能
03
调用智能体
调用相关OpenAPI接口实现智能体实时交互能力
