本文介绍基于开源 Ollama 项目,使用火山引擎 API 网关和函数服务(veFaaS)快速部署 DeepSeek-R1 蒸馏模型推理服务,满足您的业务需求。
背景信息
DeepSeek-R1 蒸馏模型是由中国 AI 初创公司深度求索(DeepSeek)发布的开源大语言模型之一,具有小体积低能耗的特性,同时保持较高的性能,便于部署在多样化的设备上,适合资源受限的场景。
本文主要介绍基于开源 Ollama 项目使用 veFaaS,以 Serverless 方式快速部署 DeepSeek-R1 蒸馏模型(例如 1.5b、7b、14b、32b)。相比 vLLM、SGLang 等方案,Ollama 更多提供了开箱即用的使用体验,本地测试更便捷,推理框架镜像体积更小(1.5 GiB),结合 veFaaS 的较强灵活性和便捷性特点,对于用户的上手成本更友好。
前提条件
使用 veFaaS 部署 DeepSeek-R1 蒸馏模型前,需要完成如下前置工作:
- 准备本地开发环境:
- 联系您的火山引擎售前经理或解决方案经理,申请如下功能的邀测试用:
- 申请函数服务 GPU 功能及相关卡型的邀测试用。
- 申请函数服务 ollama 公共镜像的邀测试用。
- 开通火山引擎相关产品:
- 开通 火山引擎 API 网关 产品。
- (可选)开通 火山引擎对象存储(TOS) 产品。
说明
如需使用开源 Ollama 项目支持的其他模型,可自行将模型上传到 TOS 并挂载到函数服务对应路径。
部署模型
步骤一:在 veFaaS 上创建 Ollama 模型推理服务
- 在 函数服务控制台 顶部导航栏选择 华北 2(北京) 地域后,创建函数。需要注意以下列举的参数配置,其余参数说明和详细的操作步骤请参见 创建 Web 应用。
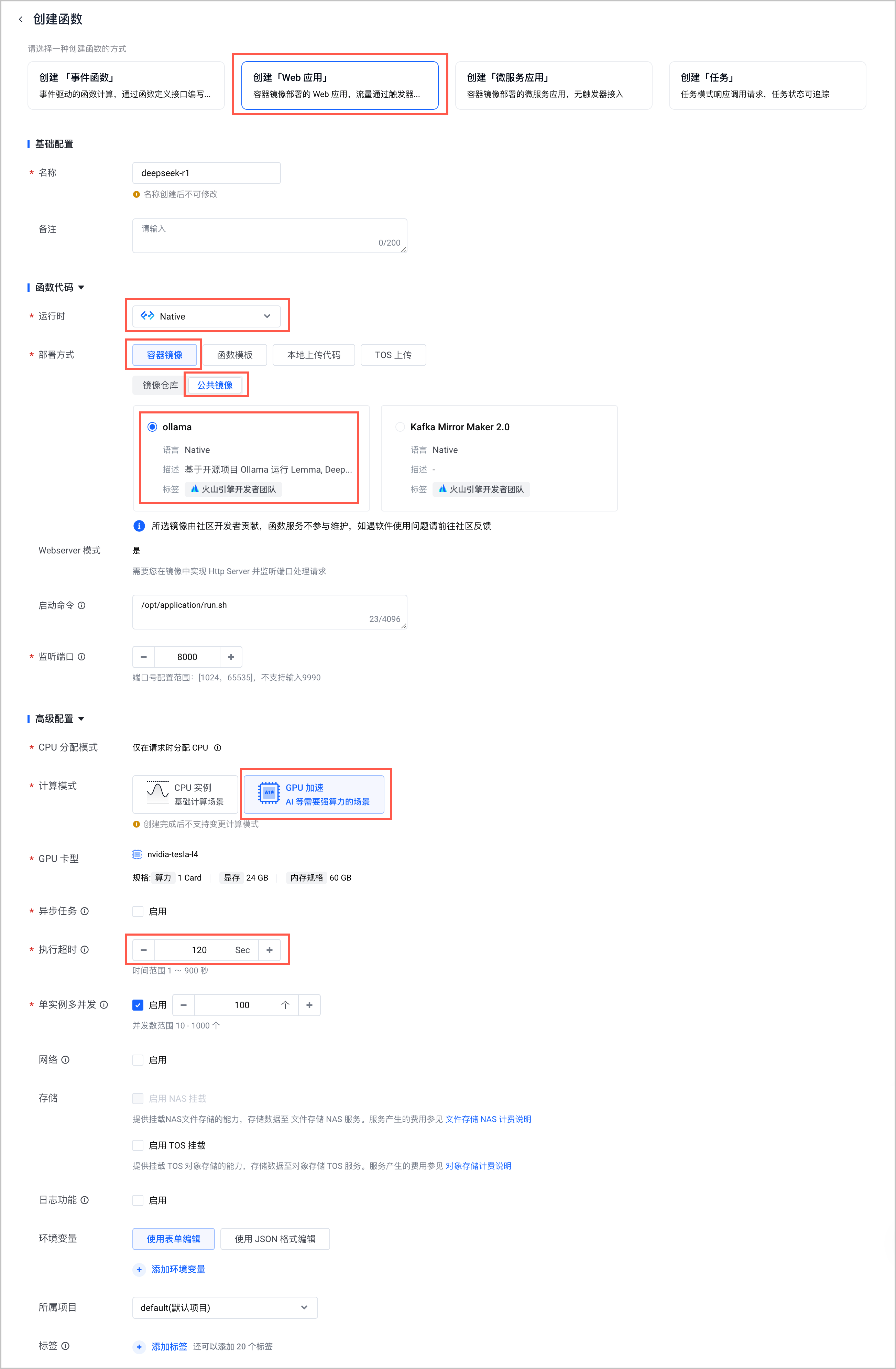
配置项 说明 创建函数的方式 选择 创建「Web 应用」。 运行时 选择 Native。 部署方式 选择 容器镜像 > 公共镜像 > ollama。 计算模式 选择 GPU 加速。 GPU 卡型 选择您 前提条件 中申请的 GPU 卡型。 执行超时时间 针对模型推理请求,建议配置 120 秒执行时长。 - 发布函数。详细的操作步骤和参数说明,请参见 发布函数。
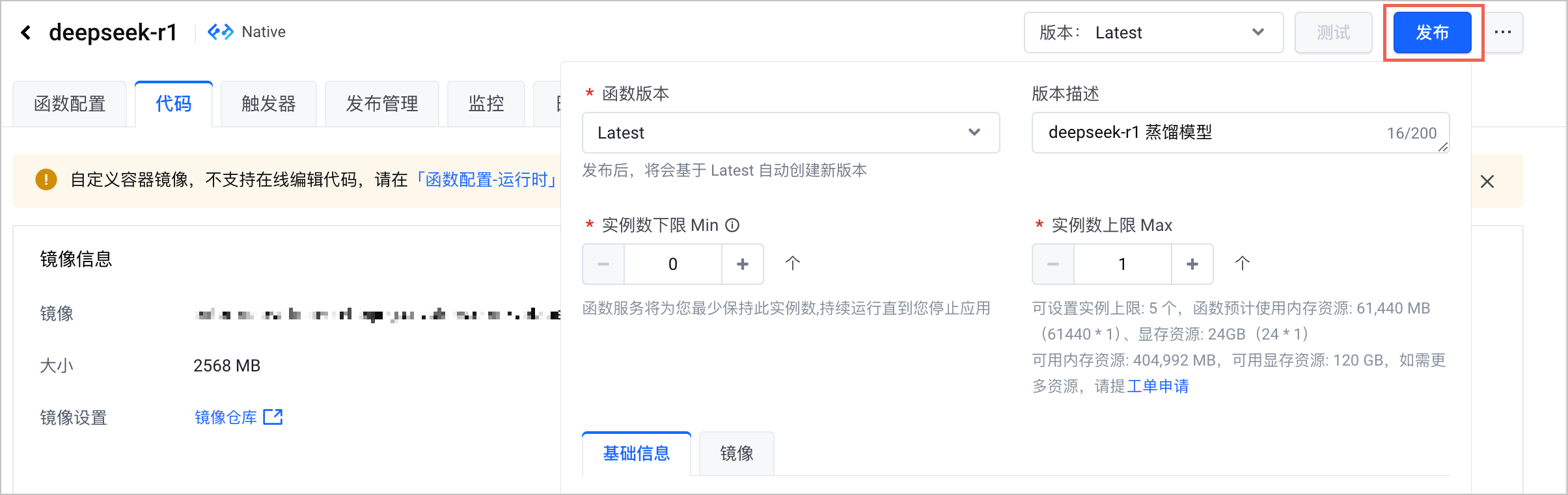
步骤二:创建和配置 API 网关触发器
- 在 API 网关控制台 ,创建 API 网关实例。需要注意以下列举的参数配置,其余参数说明和详细的操作步骤请参见 创建实例。
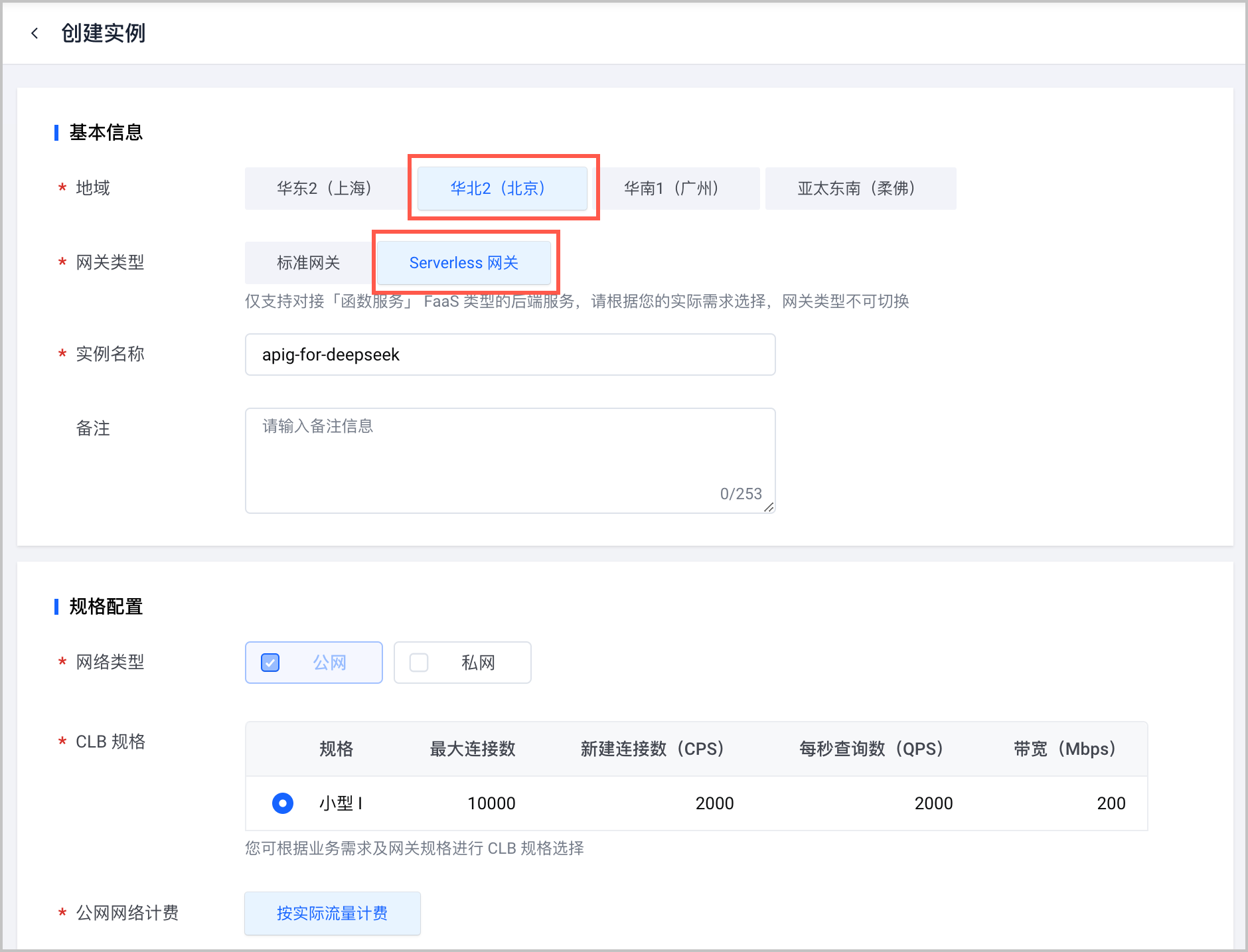
配置项 说明 地域 选择 华北 2(北京)。 网关类型 选择 Serverless 网关。 - 在 API 网关控制台 ,创建 API 网关服务(域名),关联上一步创建的 API 实例。详情请参见 创建服务。
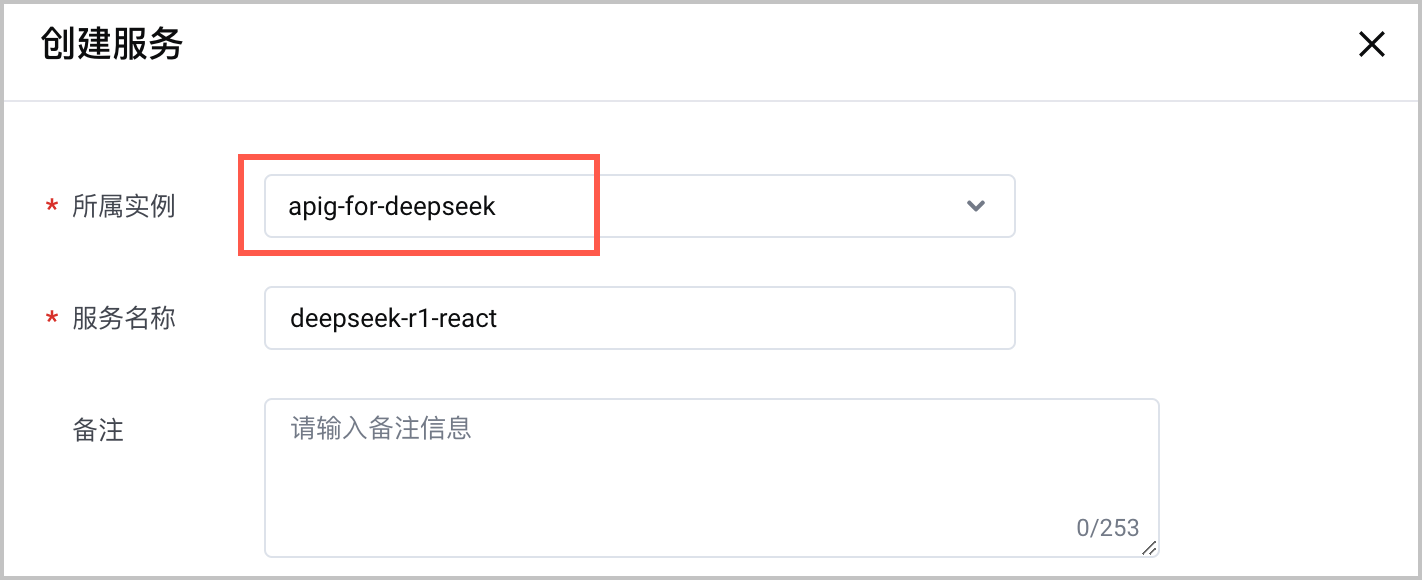
- 在 函数服务控制台 找到 步骤一 创建的函数,为该函数创建 API 网关触发器。需要注意以下列举的参数配置,其余参数说明和详细的操作步骤请参见 创建 API 网关触发器。
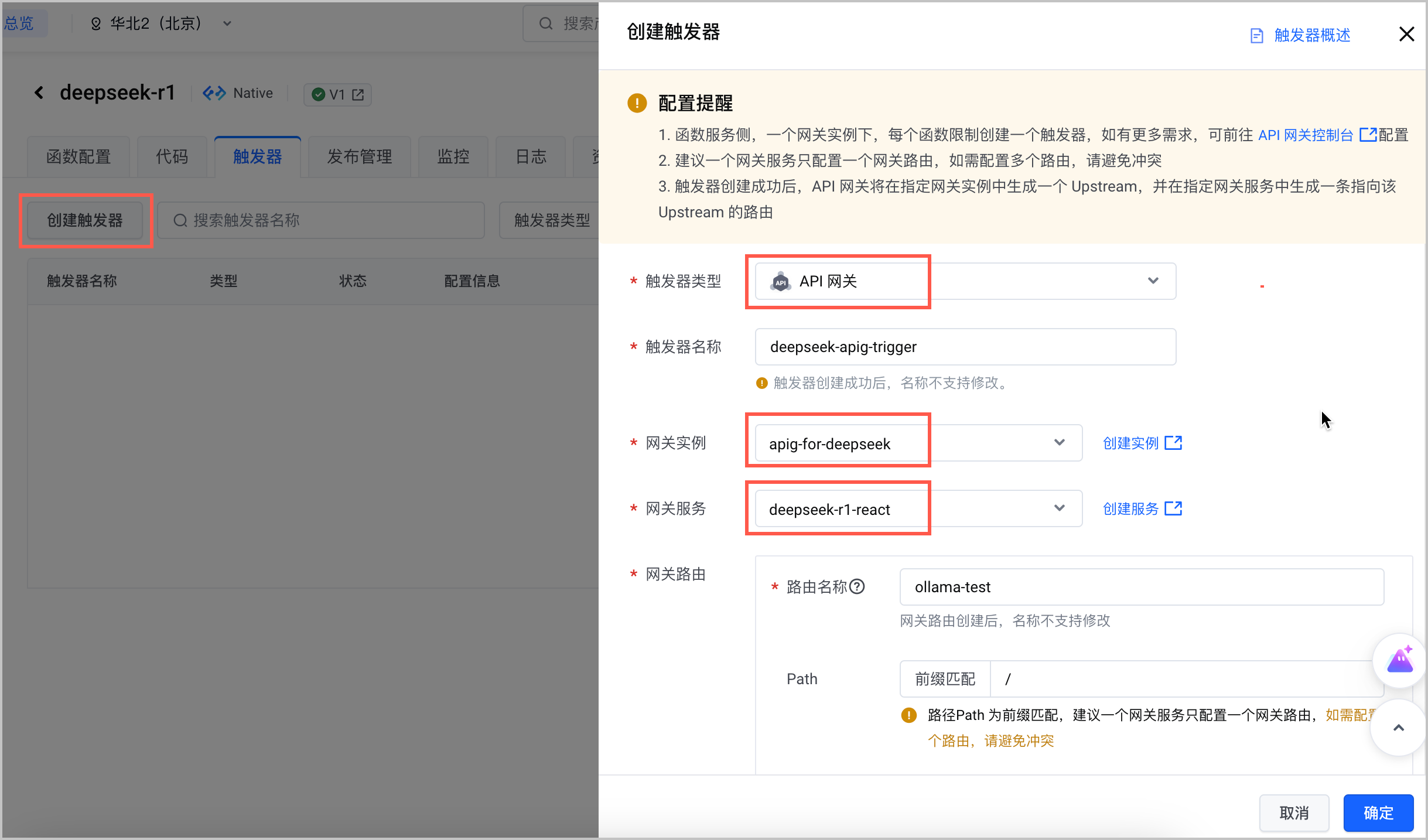
配置项 说明 网关实例 选择已创建的 API 网关实例。 网关服务 选择已创建的 API 网关服务(域名)。 - 创建 API 网关触发器成功后,获取触发器的 公网访问 地址,以备后续使用。
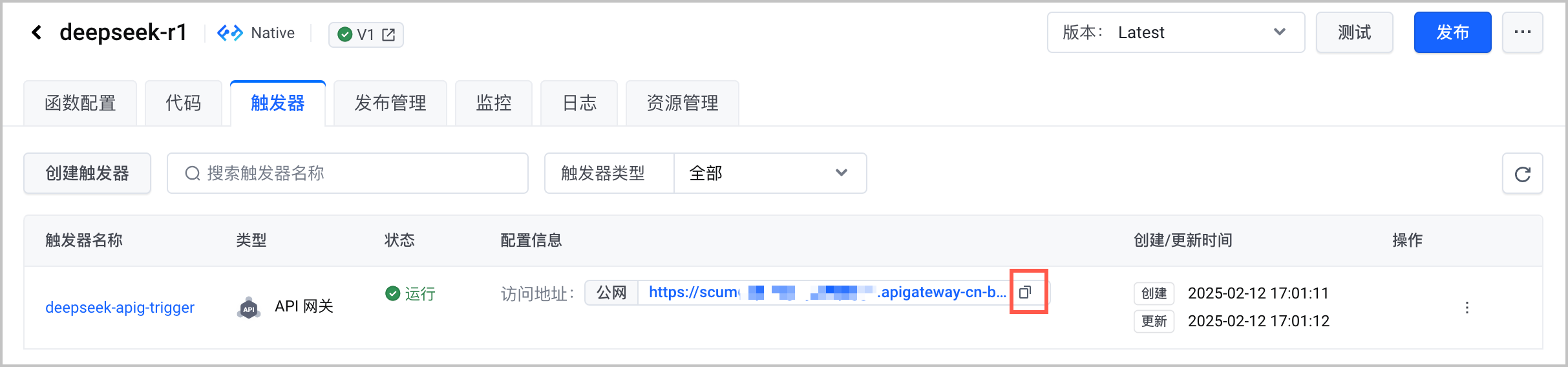
测试模型
通过 Docker 使用开源项目 Open WebUI,在本地启动前端控制台,访问 部署模型 中配置好的 Ollama 服务,测试模型。
注意
在启动参数中,函数服务做了如下动作:
- 指定 Open WebUI 使用 Ollama 作为推理后端,并指定了 Ollama 后端地址。
- 禁用了 openAI API 的访问。
- 为方便测试,禁用了访问鉴权。
- 禁用了 Open WebUI 中自带的 Embedding 模型和 Whisper 模型的自动更新。
- 在本地终端,通过 Docker 命令,使用 Ollama 部署 DeepSeek-R1 模型。
说明
本示例中使用了
3001端口号,若您本地有其他服务正在使用3001端口号,您可以自行替换其他端口号。docker run -p 3001:8080 \ -v open-webui:/app/backend/data \ --name open-webui-new \ --restart always \ --env=OLLAMA_BASE_URL=${替换为实际的 API 触发器公网访问地址} \ --env=ENABLE_OPENAI_API=false \ --env=ENABLE_WEBSOCKET_SUPPORT=false \ --env=ENABLE_RAG_WEB_SEARCH=true \ --env=RAG_WEB_SEARCH_ENGINE=duckduckgo \ --env=WEBUI_AUTH=false \ --env=RAG_RERANKING_MODEL_AUTO_UPDATE=false \ --env=WHISPER_MODEL_AUTO_UPDATE=false \ --env=RAG_EMBEDDING_MODEL_AUTO_UPDATE=false \ ghcr.io/open-webui/open-webui:main - 在浏览器中访问
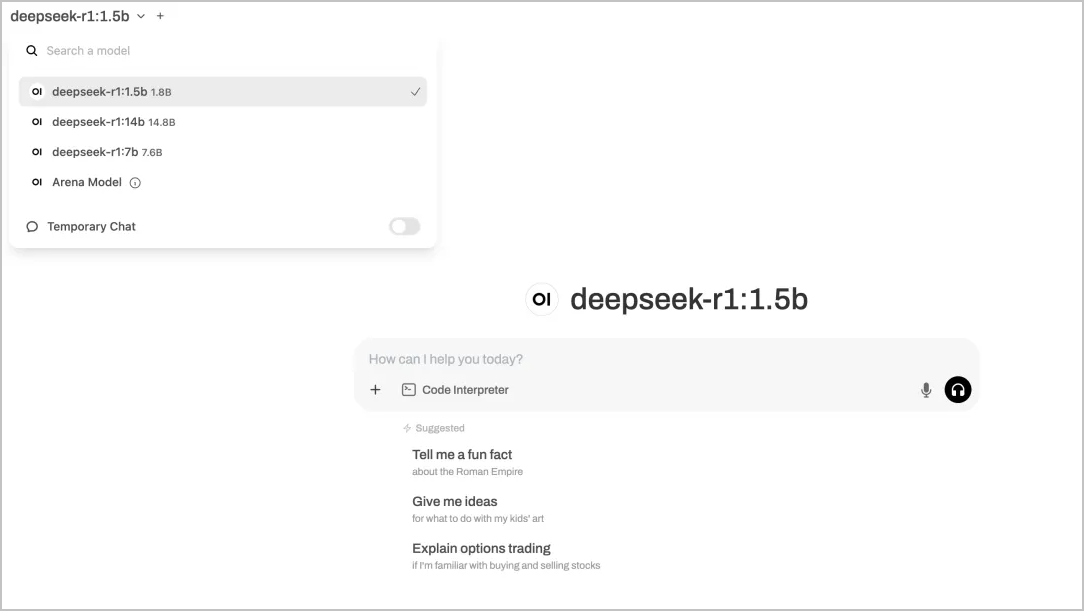
localhost:端口号(例如localhost:3001),测试模型部署效果。
预期结果如下图所示。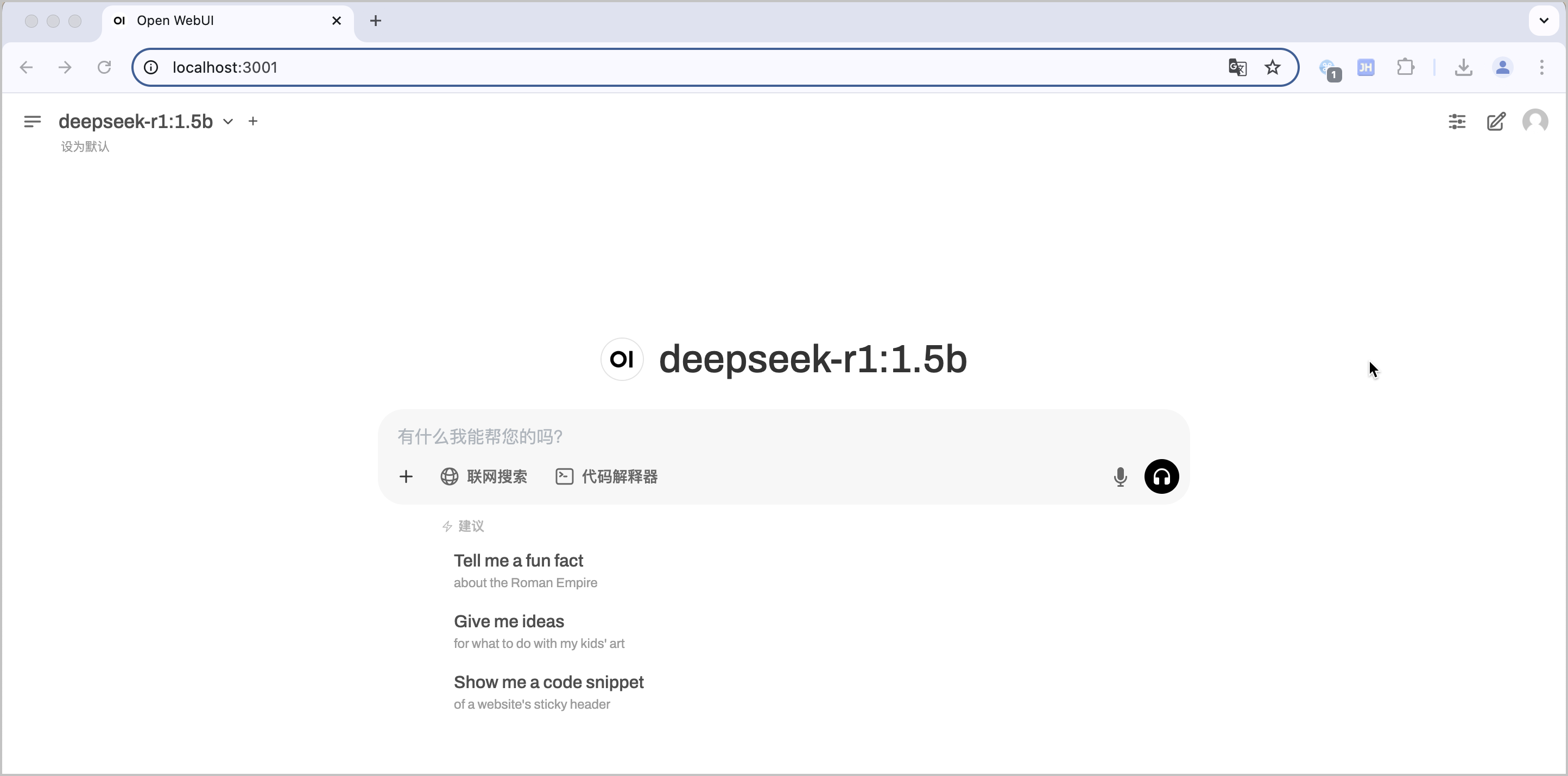
使用更多模型
函数服务提供的 ollama 公共镜像中自带 DeepSeek-R1-Distill-Qwen-1.5B 模型。如果希望在函数服务中使用 Ollama 支持的其他模型,可自行将相关模型下载到 TOS 存储桶(Bucket)并挂载到函数服务对应路径。
Ollama 支持的全部模型,请参见 Ollama 官网内容。
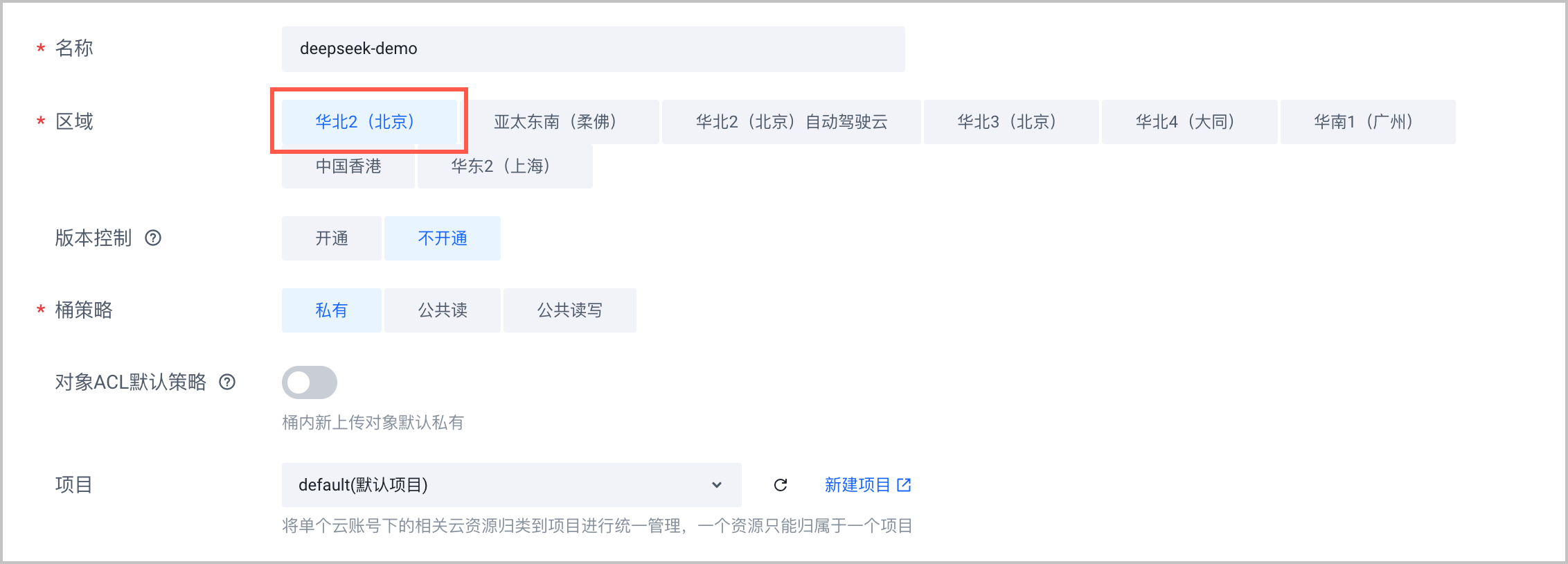
- 在 对象存储控制台 创建 TOS Bucket,用于存放模型文件,需要注意 区域 选择 华北 2(北京)。详细的操作步骤和参数说明,请参见 创建存储桶。
- 在 TOS Bucket 中创建
ollama/文件夹。详细的操作步骤和参数说明,请参见 创建文件夹。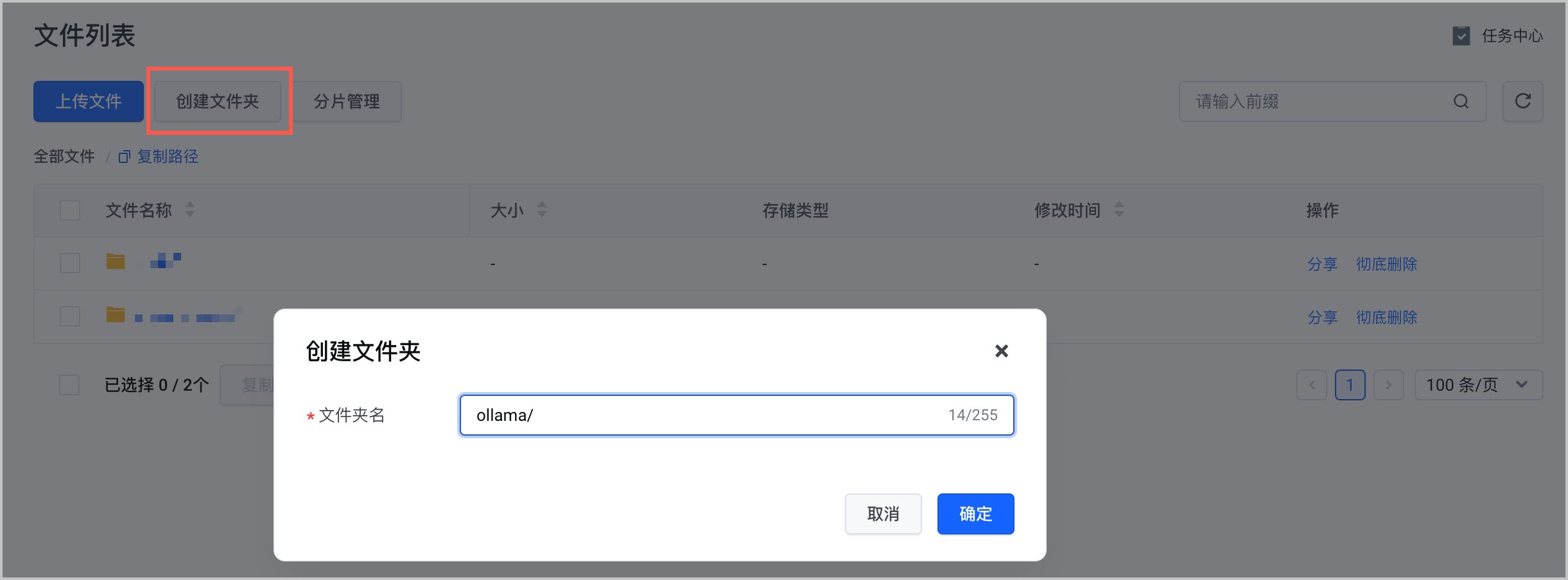
- 将需要的 Ollama 其他模型下载到本地。
为方便快速测试,此处以 DeepSeek-R1-Distill-Qwen-7B 为例,您可以自行替换其他模型。
预期返回结果如下,您可以自定义输入内容,与模型对话:ollama run deepseek-r1:7b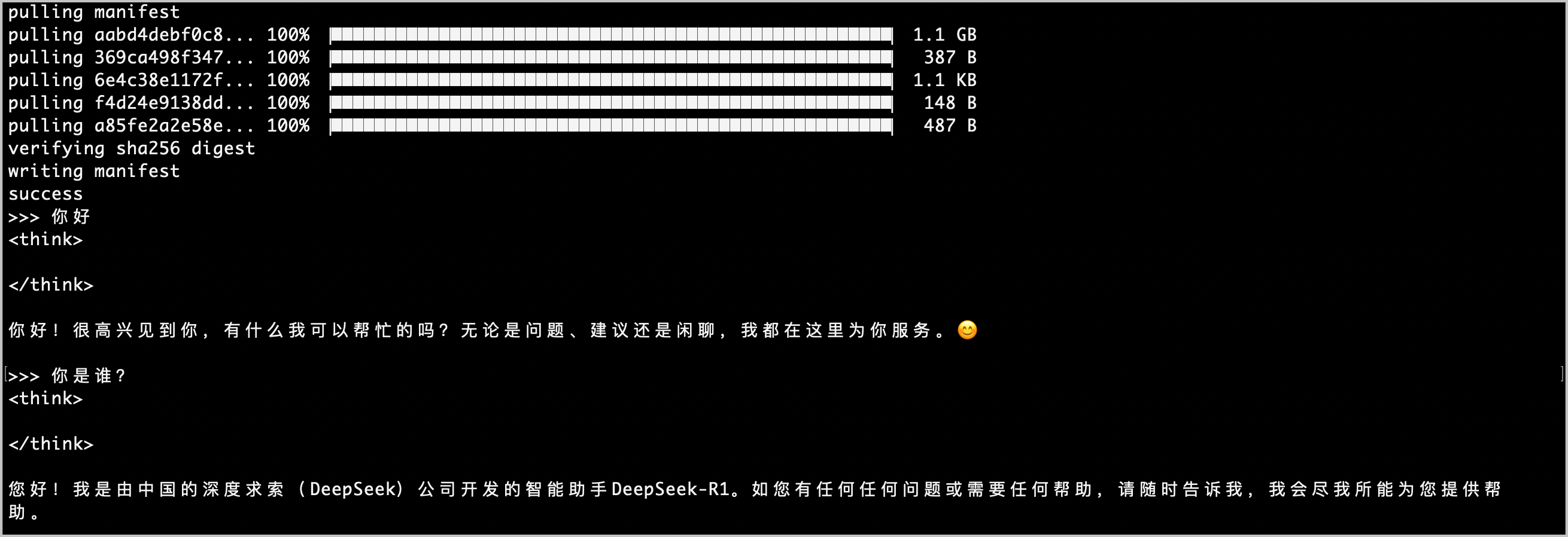
- 查看本地存放模型的文件夹。
在本地安装 Ollama 后,Ollama 模型文件默认存在于~/.ollama/models目录下。
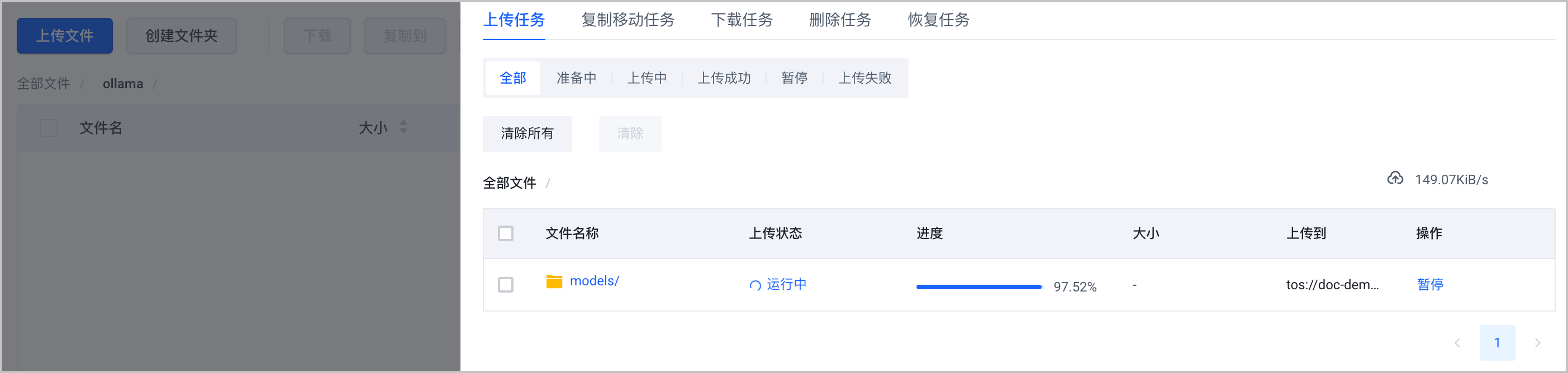
预期返回结果如下:ls -lbh ~/.ollama/modelstotal 0 drwxr-xr-x@ 22 bytedance staff 704B Feb 6 13:49 blobs/ drwxr-xr-x@ 3 bytedance staff 96B Feb 3 23:45 manifests/ - 返回 对象存储控制台,找到 TOS Bucket 中已创建的
ollama/文件夹,将本地存放模型的文件夹(models/),上传到该文件夹下。详细的操作步骤,请参见 上传文件。注意
TOS 控制台上传文件时,最大能够上传 5 GiB 文件。如有大文件上传需求,请自行安装 TOS 官方提供的命令行工具 tosutil 到本地。详情请参见 tosutil 下载与安装。
- 在 函数服务控制台 找到 步骤一 创建的函数,编辑函数配置,以读写方式挂载上述 TOS Bucket。需要注意以下列举的参数配置,其余参数说明和详细的操作步骤请参见 挂载 TOS 对象存储。
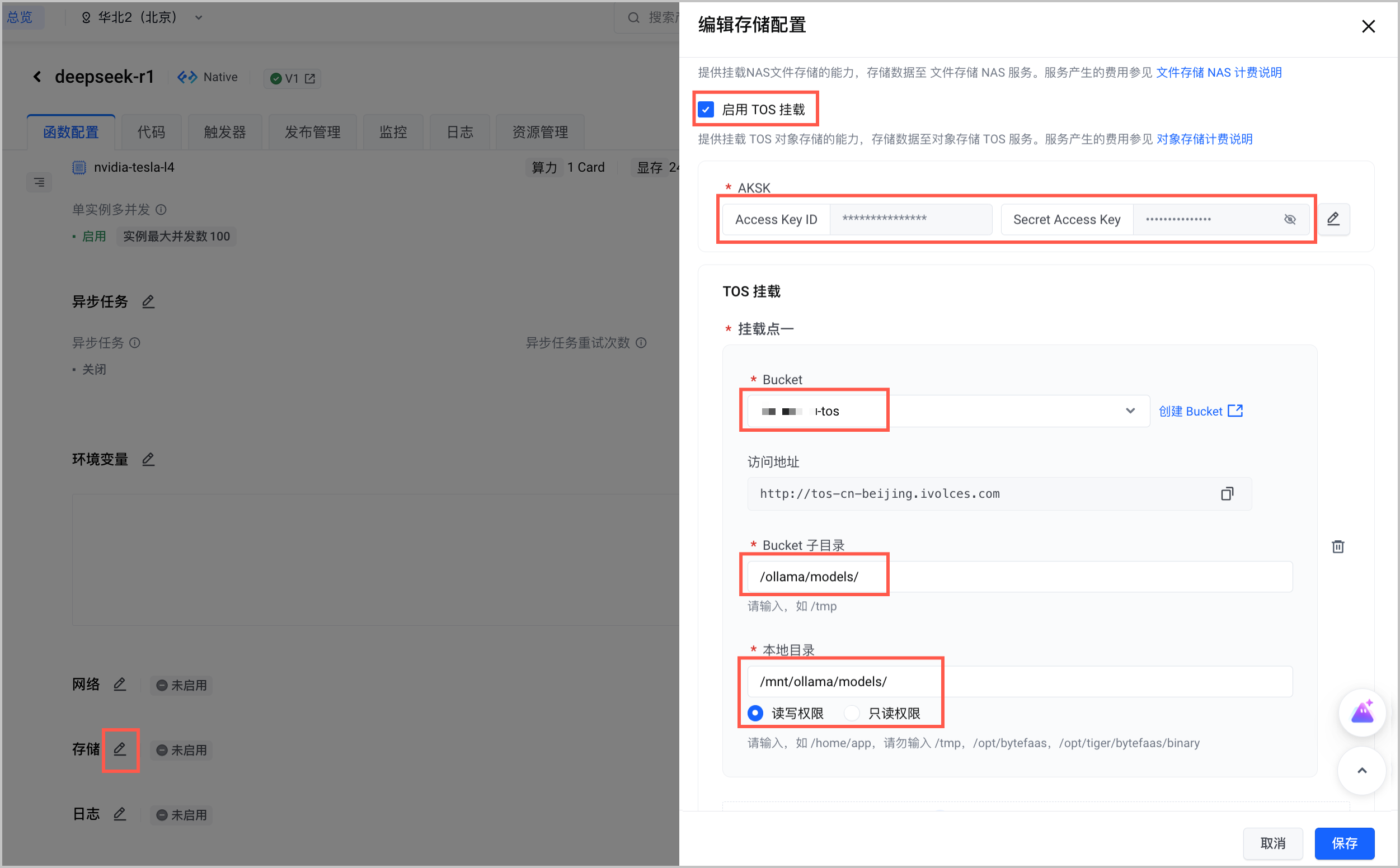
配置项 说明 启用 TOS 挂载 勾选 启用 TOS 挂载。 AKSK 配置拥有 TOS Bucket 读写权限的火山引擎账号 AccessKey ID(AK)和 Secret Access Key(SK)。AK/SK 获取方法,请参见 API访问密钥管理。 TOS 挂载
单击 添加 TOS 挂载点,配置如下参数:
- Bucket:选择。
- Bucket 子目录:设置为
/ollama/models/,即 TOS 中存放模型文件的目录。 - 本地目录:设置为
/mnt/ollama/models。 - 权限:选择 读写权限。
- 设置环境变量
OLLAMA_MODELS为模型挂载路径。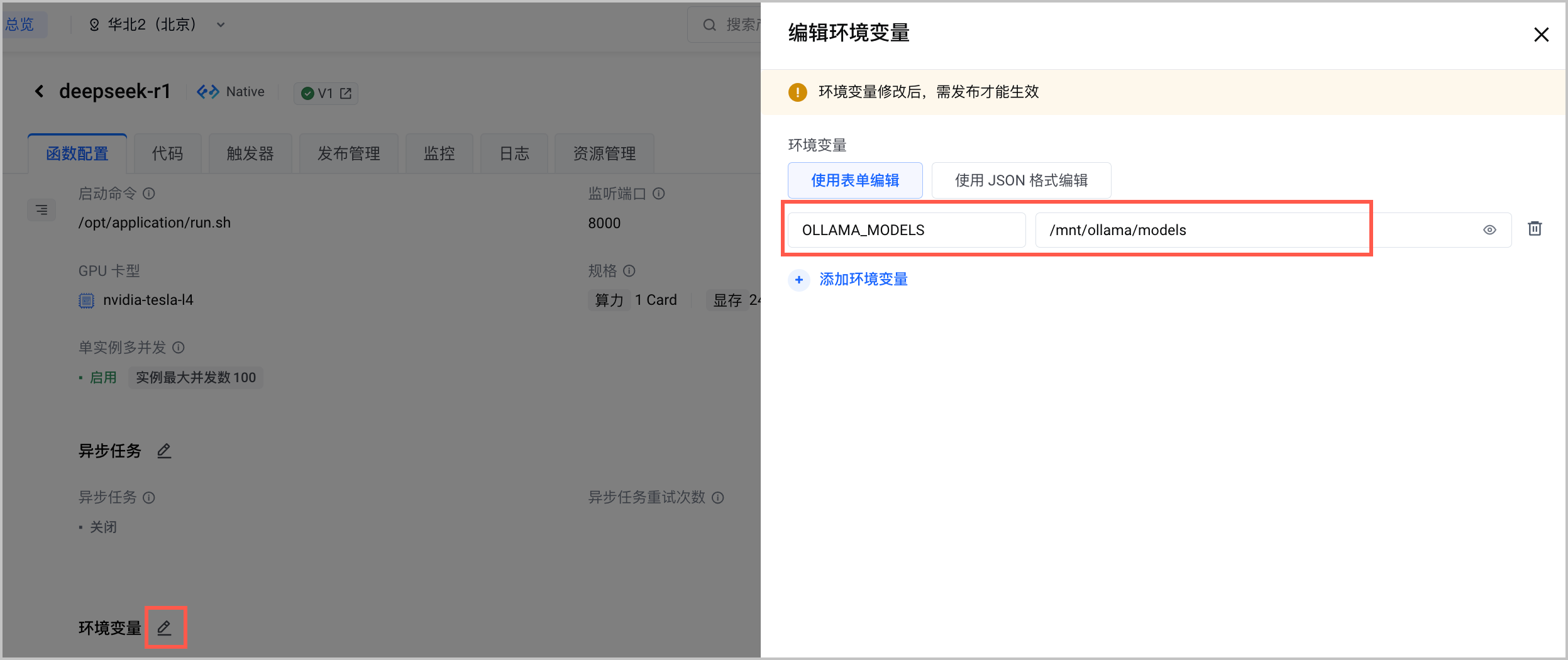
- 重新发布函数,使挂载信息和环境变量生效。详情请参见 发布函数。
- 重复 测试模型 的操作步骤,可以看到多个模型选项。