为提高存储效率,降低存储成本,表格数据库 HBase 版提供字典压缩功能。本文介绍如何开启字典压缩功能。
功能介绍
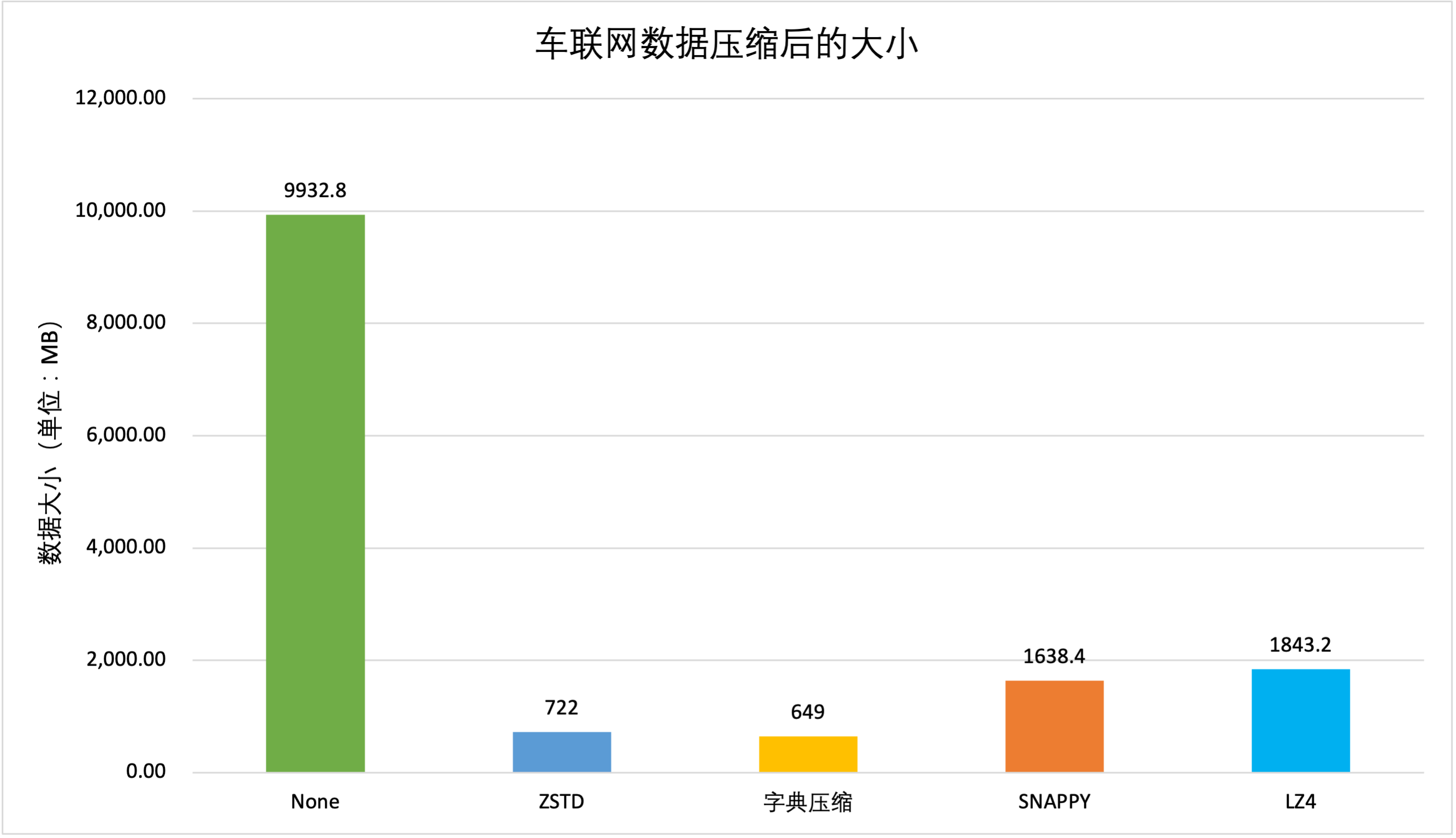
字典压缩(ZSTD_DICT)是 HBase 深度优化的压缩算法,在 ZSTD 压缩算法的基础上进行了字典采样的优化,能够进一步压缩存储空间,数据压缩比可高达 10:1 以上。经实际测试,当开启字典压缩功能后,数据量明显减少,不同压缩算法的对比结果如下:
| 数据类型 | 原始数据 | ZSTD | 字典压缩 | Snappy | LZ4 |
|---|---|---|---|---|---|
| 车联网数据 | 9.7GB | 722MB | 649MB | 1.6GB | 1.8GB |
操作步骤
使用字典压缩时,需要将 COMPRESSION 参数设置为 ZSTD_DICT,该参数为列族粒度控制。
说明
若只需要使用字典压缩,并没有其他特殊要求,仅设置 COMPRESSION 参数已经可以满足基本需求。若想要精准控制不同情况下使用不同压缩算法,表格数据库 HBase 版仍然保留了 COMPRESSION_COMPACT 参数的能力,即指定做 compact 时使用的压缩算法,该参数不设置时,会被 COMPRESSION 参数值覆盖。
Shell 客户端
在创建表时开启字典压缩。
hbase(main):007:0> create 'table_use_zstd_dict', {NAME => 'cf', COMPRESSION => 'ZSTD_DICT'}对已存在的表,使用字典压缩。
hbase(main):009:0> alter 'tls',{NAME => 'cf', COMPRESSION => 'ZSTD_DICT'}说明
修改表的压缩算法后,数据不会立即进行压缩,若想要存储空间立即下降,您需要手动执行
major_compact 'tableName'命令。
Java 客户端
Admin admin = connection.getAdmin(); TableDescriptor tableDescriptor = TableDescriptorBuilder.newBuilder(TableName.valueOf("table_use_zstd_dict")) .setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("cf1")) .setValue("COMPRESSION", "ZSTD_DICT") .build()).build(); admin.createTable(tableDescriptor); admin.close();
进阶设置
DATA_BLOCK_COUNT_FOR_TRAINING 参数用于设置训练数据 Data Block 的数量大小,该参数为缺省配置,默认值与 Data Block 大小相关。且训练数据的大小可以决定字典的大小,训练效果直接决定了压缩效果。因此,您也可以根据实际业务需要和字典压缩功能的使用经验,自行调整该参数值进行测试,根据不同的测试结果设置符合您业务场景的最佳数值。推荐值如下:
| 单个 Data Block 大小 | 32KB | 64KB | 128KB |
|---|---|---|---|
| Data Block 数量(推荐值) | 200 左右 | 100 左右 | 50 左右 |
注意
若 DATA_BLOCK_COUNT_FOR_TRAINING 设置得过大,为避免 OOM,系统会尽力采集足数的 Data Block 作为训练集。