为方便企业用户快速在云上环境体验 QwQ-32B 大模型,本文将结合火山引擎云服务器 ECS、容器服务 VKE、持续交付 CP 推出快速部署 QwQ-32B,通过 vLLM 大模型框架运行推理服务的方案。
背景信息
QwQ-32B 是近期社区新开源的推理模型,在 AIME24 评测集(数学推理)、LiveCodeBench(编程能力)、LiveBench、IFEval 指令遵循能力测试、BFCL 评测等一系列权威基准测试中表现出色。它通过大规模强化学习技术突提升了语言模型的智能水平,具体表现在其 思维链显式化 能力,在推理过程中会展示完整的思考路径,增强了结果的可解释性。
前提条件
在容器服务创建容器集群,需要注意以下列举的参数配置,详细的操作说明参见 创建集群。
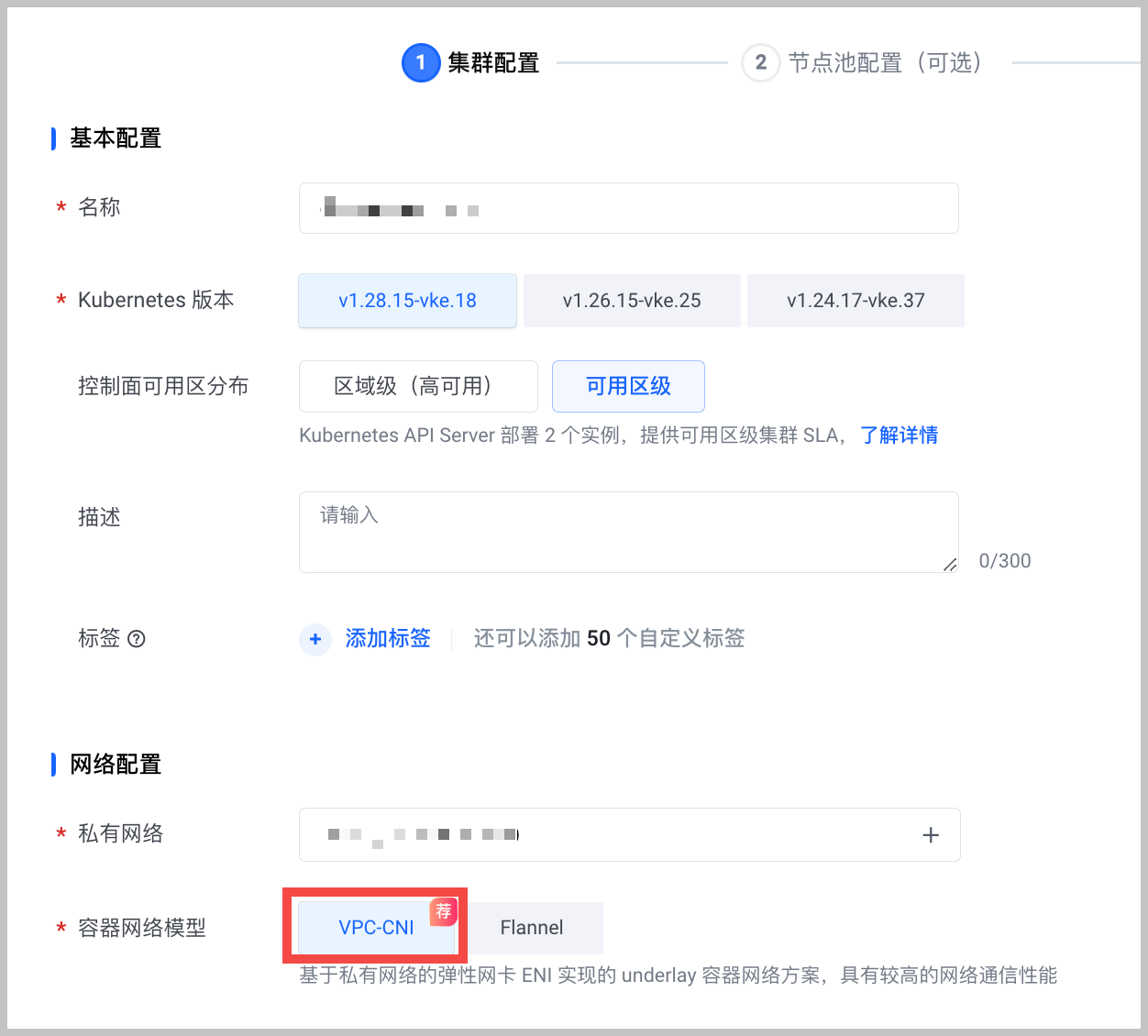
容器服务
容器网络模型:选择 VPC-CNI。
计算规格:推荐使用不同的机型部署不同的模型,以发挥最大性价比。以下为常用的蒸馏模型机型配置推荐,请供参考。
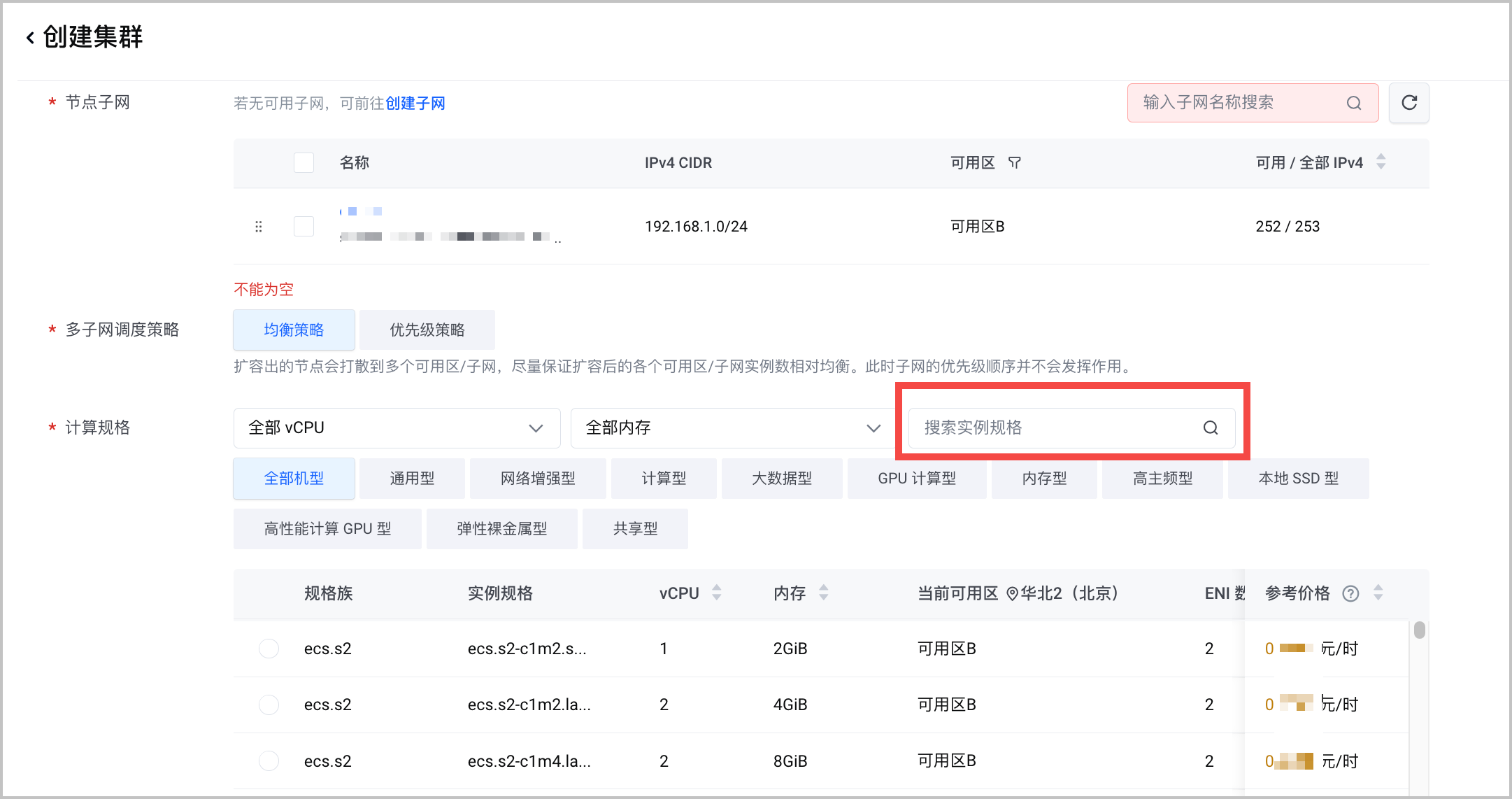
机器型号 GPU 数量 GPU 显存 CPU 内存 ecs.gni2.28xlarge 4 4 * 24G 112 448G ecs.gni3cl.11xlarge 2 2 * 48G 44 240G ecs.pni2.3xlarge 1 1 * 80G 14 245G ecs.pni3l.5xlarge 1 1 * 96G 22 244G 组件配置:安装 csi-tos 和 nvidia-device-plugin 两个组件。
API 网关
已创建 API 网关。 私有网络置必须和所创建 VKE 集群相同。网关节点的规格选择
1c2g 2。协议 为HTTP1.1。创建 API 网关实例的详细说明参见 创建实例。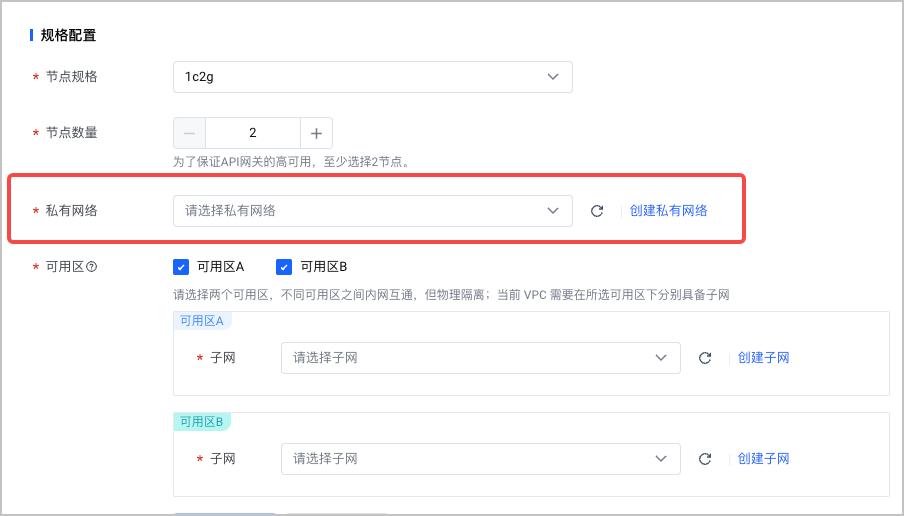
操作步骤
本文介绍通过火山引擎持续交付产品,完成 DeepSeek-R1-Distill 在已创建的容器服务中的快速部署。
第一步:创建部署集群
将已创建的 VKE 集群接入持续交付平台。
登录 持续交付控制台。
在左侧导航栏选择 资源管理。
在资源管理页面,切换至 部署资源 页签。
在 部署资源 页签,单击 创建部署资源 。
在 创建部署资源 对话框,按要求配置部署资源信息。重点注意以下参数配置,其他参数说明参见 接入 VKE 集群。
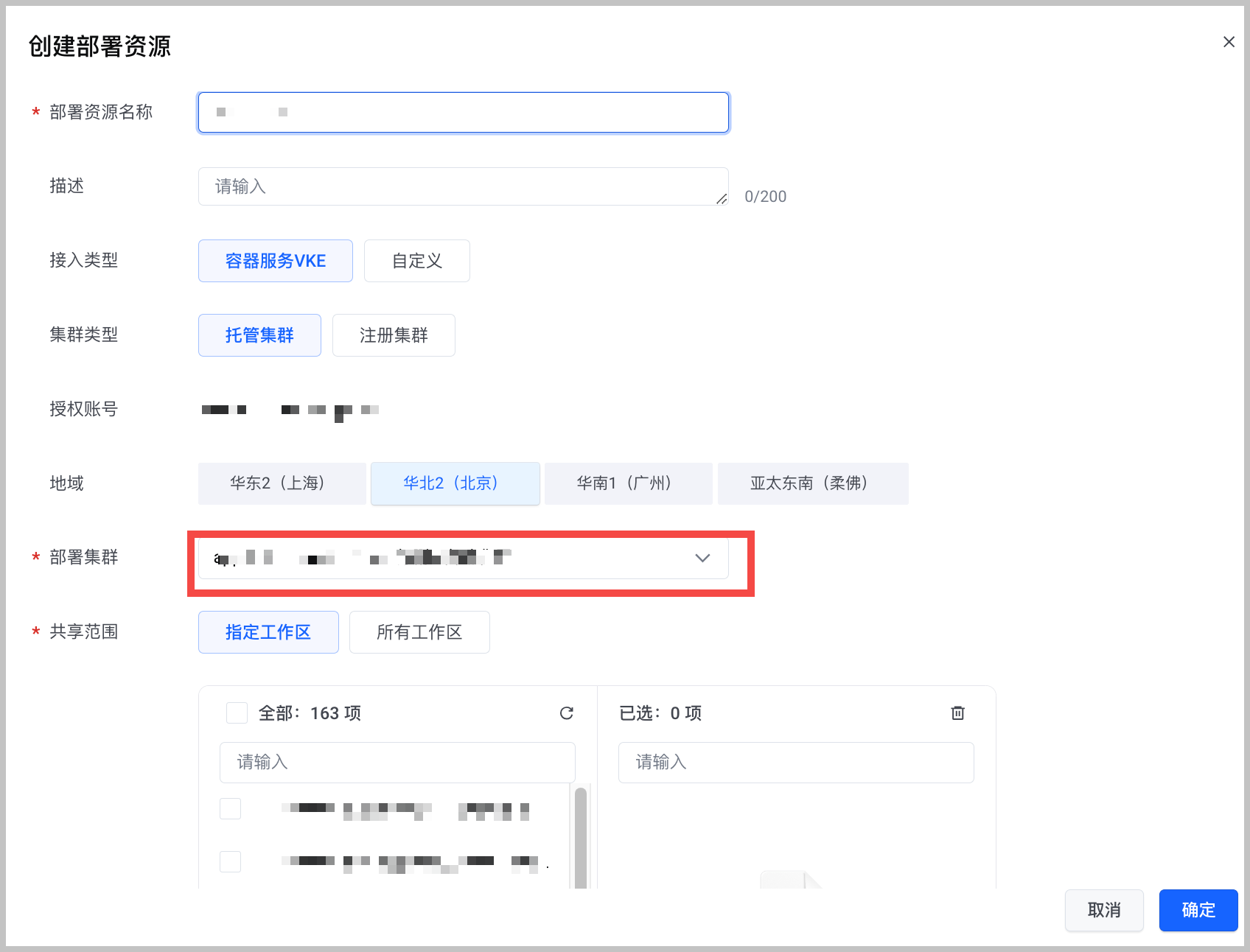
配置项 说明 接入类型 选择 容器服务 VKE。 地域 选择已创建容器服务集群所在的地域。 共享范围 选择 所有工作区。
第二步:创建 AI 应用
在持续交付的 AI 应用 模块,部署大模型应用。
- 登录 持续交付控制台。
- 在左侧导航栏选择 AI 应用。
- 在 AI 应用页面,单击 创建应用。
- 选择 自定义创建 模板,并单击 下一步:应用配置。
- 按要求填写应用的相关配置信息。配置完成后单击 确定,应用将开始创建并部署。重点注意以下参数配置,其他参数说明参见 创建和部署 AI 应用(自定义创建)。
部署集群
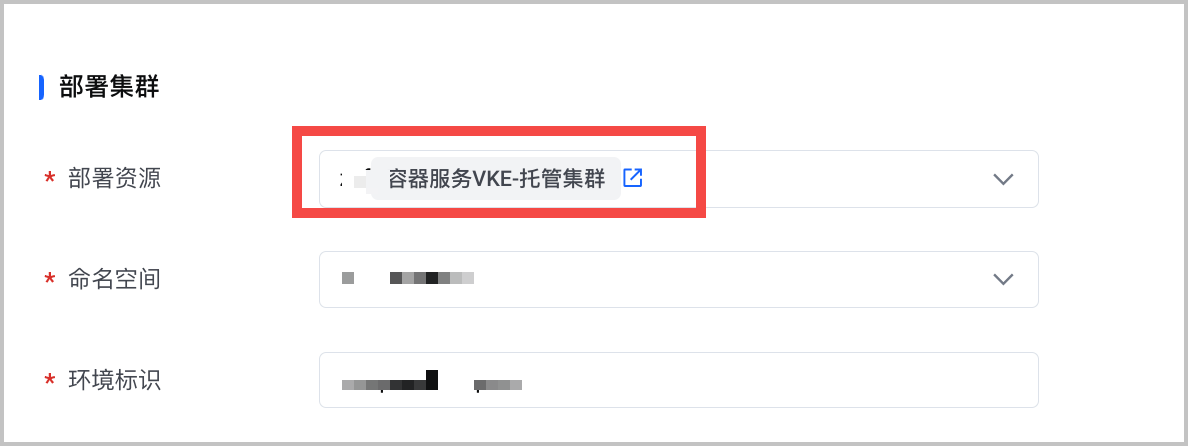
配置项 说明 部署资源 选择已创建的容器服务集群。 模型配置
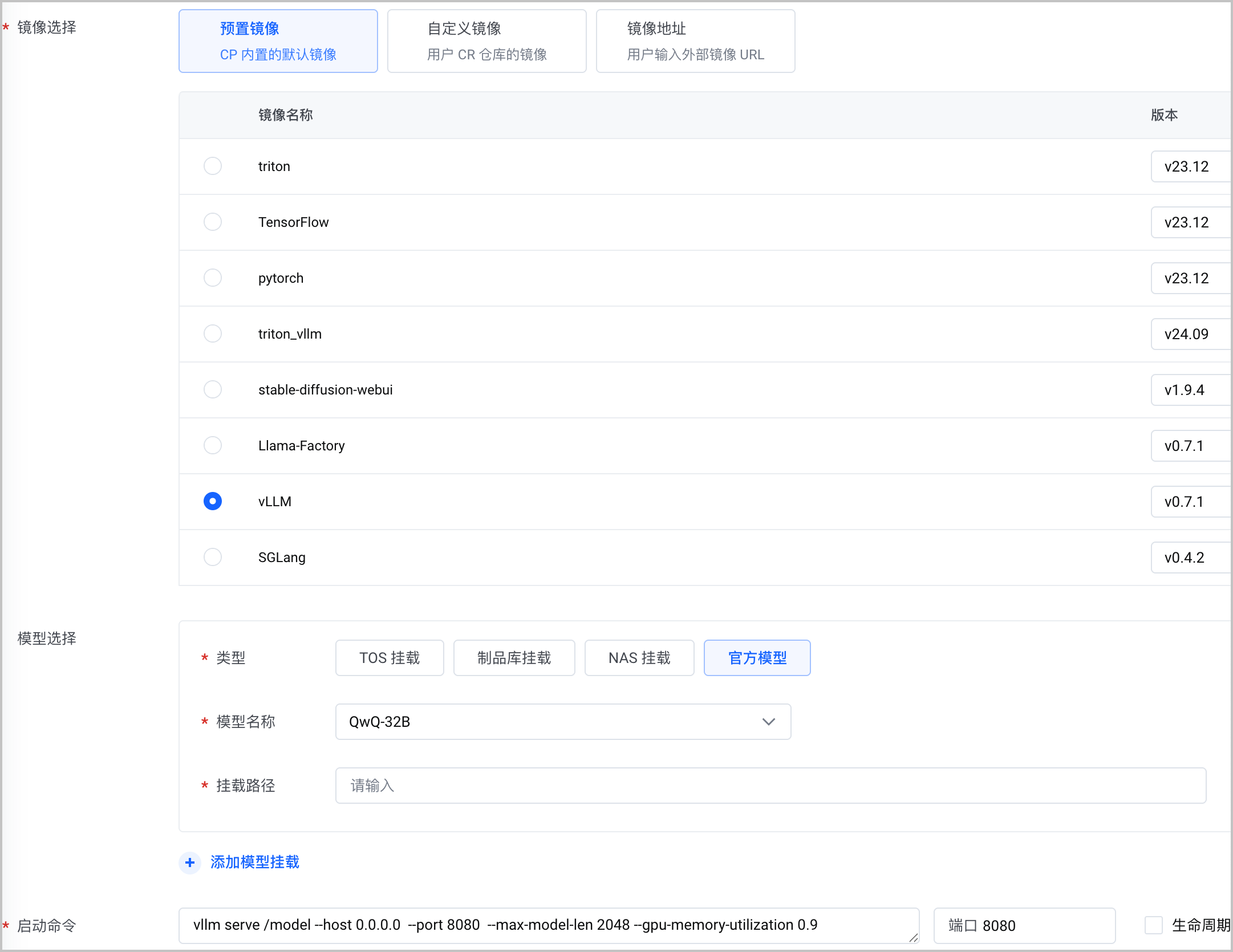
说明
默认启动命令为
vllm serve /model --host 0.0.0.0 --port 8080 --max-model-len 2048 --gpu-memory-utilization 0.9 --tensor-parallel-size ${GPU_NUM}。其中GPU_NUM为所选择机型 GPU卡数量,需要根据实际机型中 GPU 卡数量调整。配置项 说明 镜像选择 选择 预置镜像 > vLLM。 模型选择 选择 官网模型 类型中选择 QwQ-32B 模型。 挂载路径 为 /model。启动命令 默认配置启动命名。请根据实际推理服务的需要,修改默认启动命令。 推理服务规格
模型所部署的云服务器规格不同,对应可配置服务规格也有所不同。以下是不同机型推荐的服务规格。本文以
ecs.gni3cl.11xlarge为例。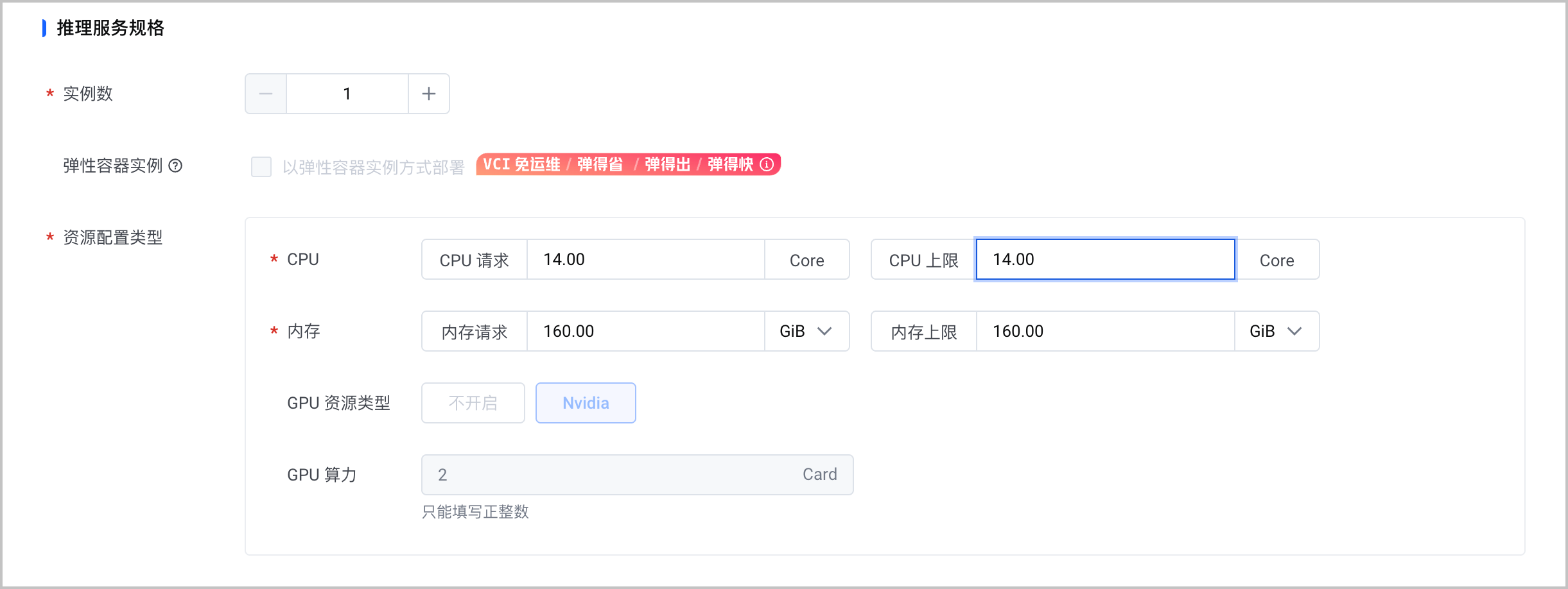
配置项 说明 实例数 选择 1。 弹性容器实例 本示例不选择该功能。 资源配置类型 模型所部署的云服务器规格不同,对应可配置服务规格也有所不同。推荐根据下表,配置对应的服务规格参数。 机器型号 GPU 数量 CPU 请求/上限 内存请求/上限 ecs.gni2.28xlarge 4 14 160G ecs.gni3cl.11xlarge 2 14 160G ecs.pni2.3xlarge 1 8 160G ecs.pni3l.5xlarge 1 14 160G
第三步:创建 API 网关访问推理服务
火山引擎 API 网关 APIG 是基于云原生的、高扩展、高可用的云上网关托管服务。在传统流量网关的基础上,集成丰富的服务发现和服务治理能力,打通微服务架构的内外部网络,实现安全通信。
登录当前应用。
- 登录 持续交付控制台。
- 在左侧导航栏选择 AI 应用。
- 在 AI 应用页面,选择目标 AI 应用,单击应用卡片,进入当前应用的基本信息页签。
在 基本信息 > 访问设置 页签,选择 API 网关。
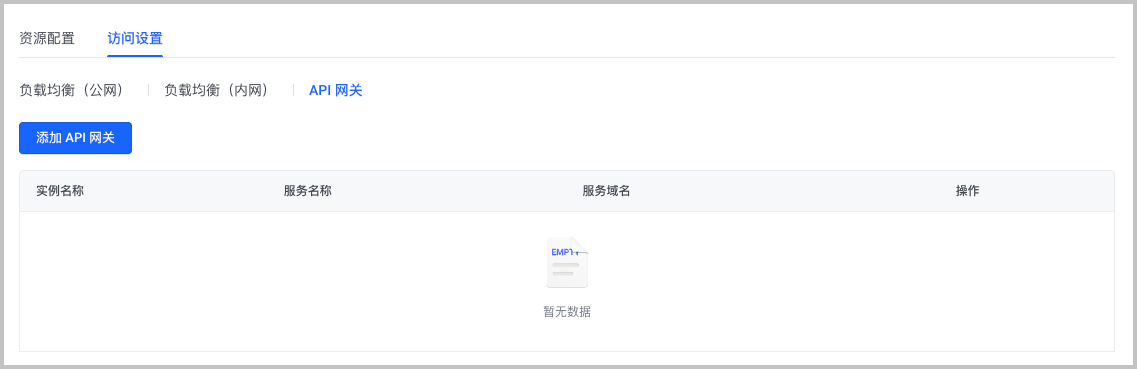
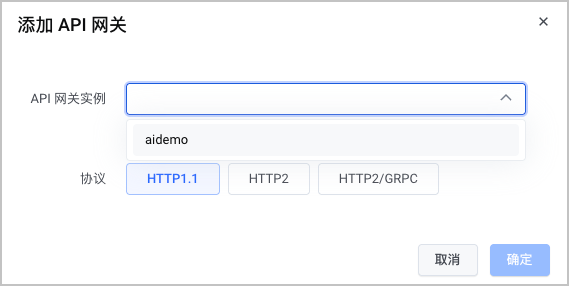
单击 添加 API 网关 ,添加符合 前提条件 要求的 API 网关。
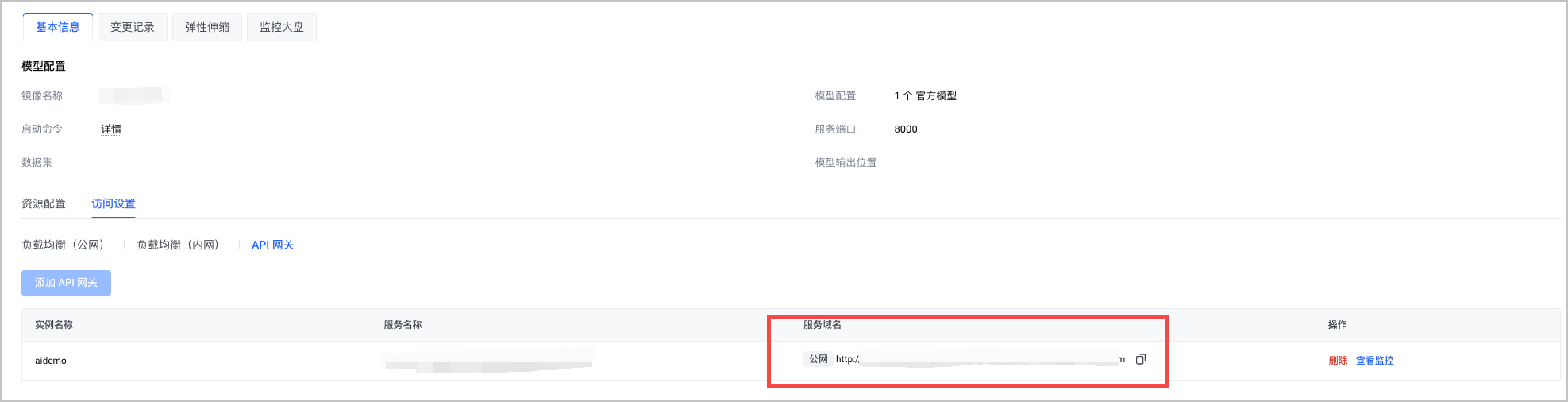
完成上述操作后,即可在 访问设置 页面查看模型的公网域名。
操作结果
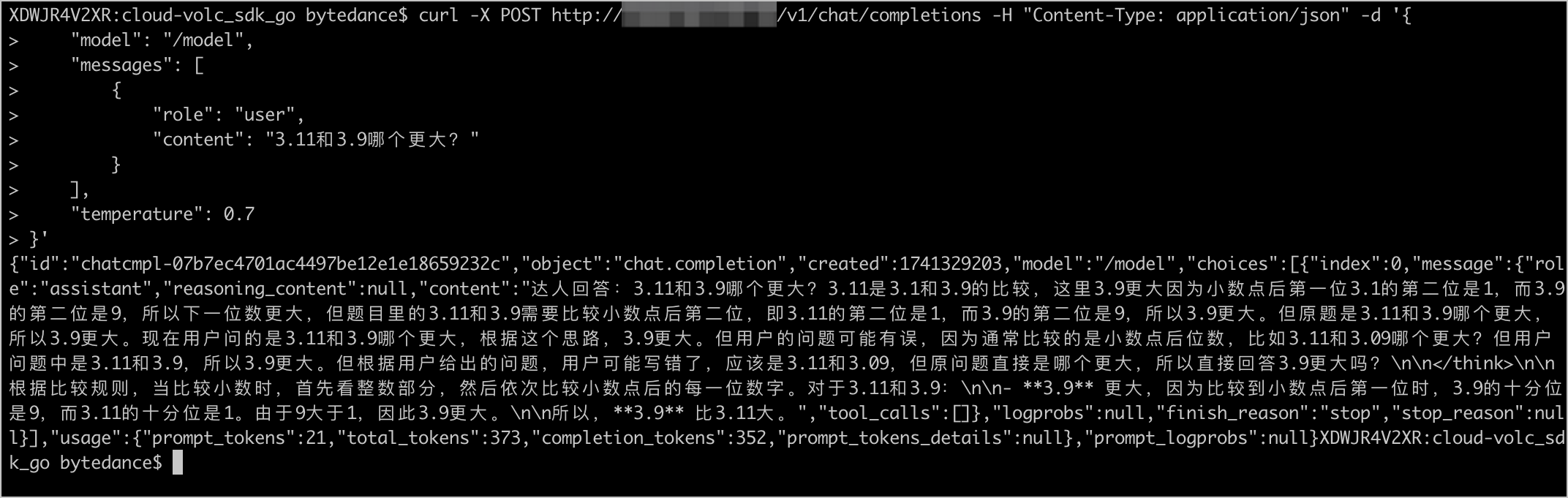
通过本地 curl 命令调用大模型 API,即可以成功和大模型对话。
curl -X POST http://example.com/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "/model", "messages": [ { "role": "user", "content": "你的问题" } ], "temperature": 0.7 }'