本文就如何利用云数据库 PostgreSQL 版和大语言模型技术(Large Language Model,简称 LLM),实现企业级智能交互式问答系统进行介绍。
通过本文,您将学习了解到:交互式问答系统原理、PostgreSQL 向量化存储和检索技术,以及大语言模型交互技术等。
背景
在大数据时代,企业纷纷建立自己的知识库,并提供检索的方式实现知识的查询。然而,随着知识库内容的增加,普通信息检索的方式已经出现检索时费时费力的问题,难以获得有效结果。随着 ChatGPT 等生成式人工智能(AI Generated Content,简称 AIGC)的出现,人们看到了一种更智能的实现方式,通过问答的方式,多方面提高知识获取的效率、准确性和用户体验。
然而,对于特定垂直领域的企业来说,生成式人工智能的局限性也显而易见,例如大模型训练周期长、缺乏对某一领域专业知识等,导致常常出现 AI“幻觉”问题(即 AI 的“一本正经的胡说八道”)。为了解决这一问题,一般会采用以下两种方式进行:
Fine Tune 方法,“驯服”大语言模型
利用领域知识,对大语言模型进行监督微调(Supervised Fine Tune)和蒸馏(Distillation)。这种方式可塑性强,但需要大量的算力和人才资源,综合成本高。此外,企业还需要持续监控和更新模型,以确保与不断变化的领域知识保持同步。
Prompt Engineering 方法,改变“自己”
该方法基于向量数据库,补充足够的对话上下文和参考资料,完善与大语言模型进行交互的问答问题(Prompt),其本质是将大语言模型的推理归纳能力与向量化信息检索能力相结合,从而快速建立能够理解特定语境和逻辑的问答系统。该方法的实现成本相对较低。
接下来,本文针对 Prompt Engineering 方法,来演示将云数据库 PostgreSQL 版作为向量数据库的使用方法。
核心概念及原理
核心概念:嵌入向量(Embedding Vectors)
向量 Embedding 是在自然语言处理和机器学习中广泛使用的概念。各种文本、图片或其他信号,均可通过一些算法转换为向量化的 Embedding。在向量空间中,相似的词语或信号距离更近,可以用这种性质来表示词语或信号之间的关系和相似性。例如,通过一定的向量化模型算法,将如下三句话,转换成二维向量(x,y),我们可通过坐标系来画出这些向量的位置,它们在二维坐标中的远近,就显示了其相似性,坐标位置越接近,其内容就越相似。如下图所示:
“今天天气真好,我们出去放风筝吧” “今天天气真好,我们出去散散步吧” “这么大的雨,我们还是在家呆着吧”

Prompt Engineering 过程原理
如上所说,使用者需要不断调整输入提示,从而获得相关领域的专业回答。输入模型的相关提示内容越接近问题本身,模型的输出越趋近于专业水平。通俗理解就是,模型能够利用所输入的提示信息,从中抽取出问题的答案,并总结出一份专业水准的回答。
整个 Prompt Engineering 工作流程如下图所示: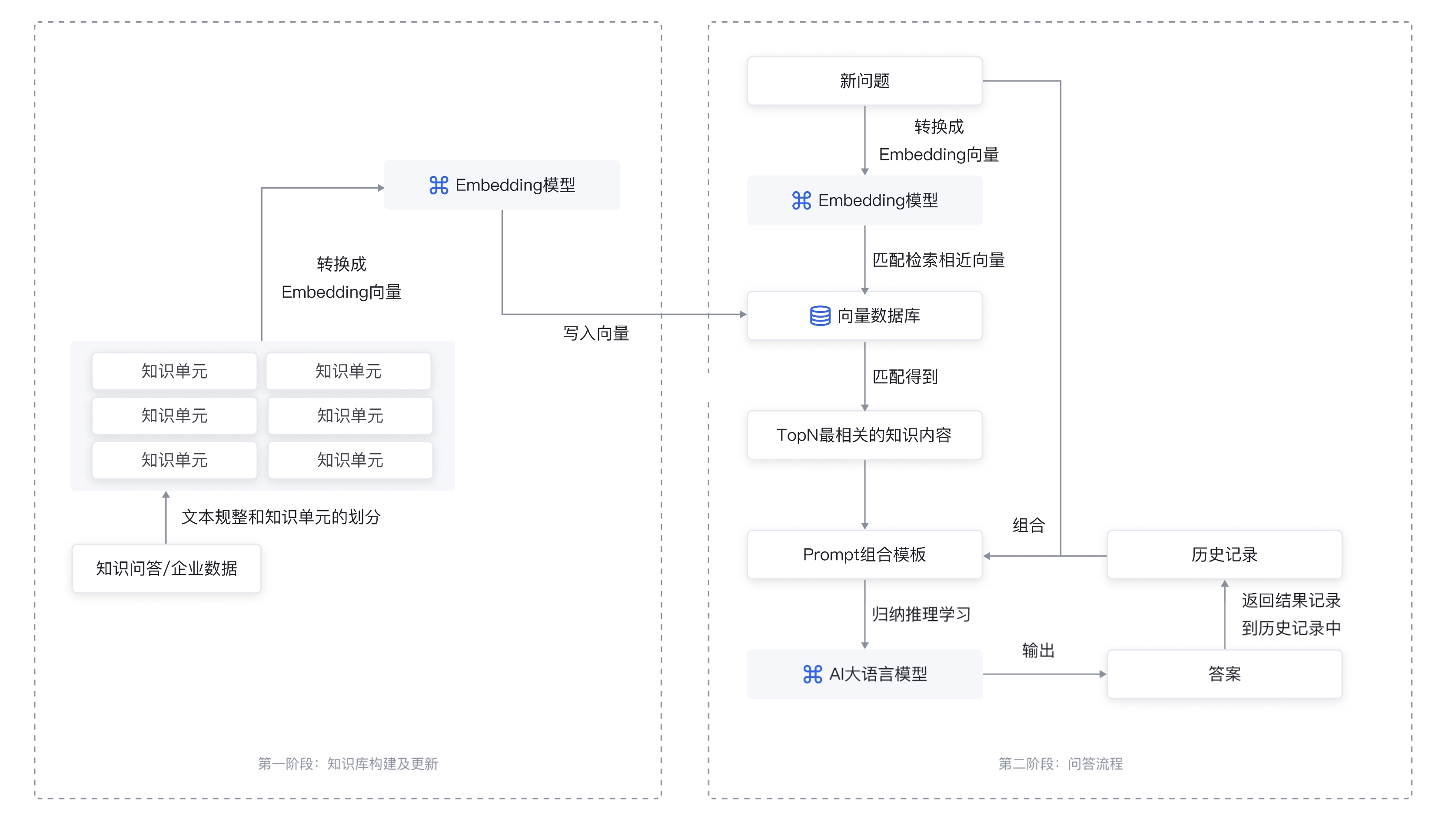
Prompt Engineering 的工作流程大致可以分为两个阶段:企业内部向量化知识库构建 + 问答阶段。
企业内部向量化知识库构建
将企业知识库的所有文档,分割成内容大小适当的片段,然后通过 Embeddings 转换算法,例如 OpenAI 的模型 API,将其转换成 Embeddings 数据,存储于云数据库 PostgreSQL 版向量数据库中,详细流程如下图所示:
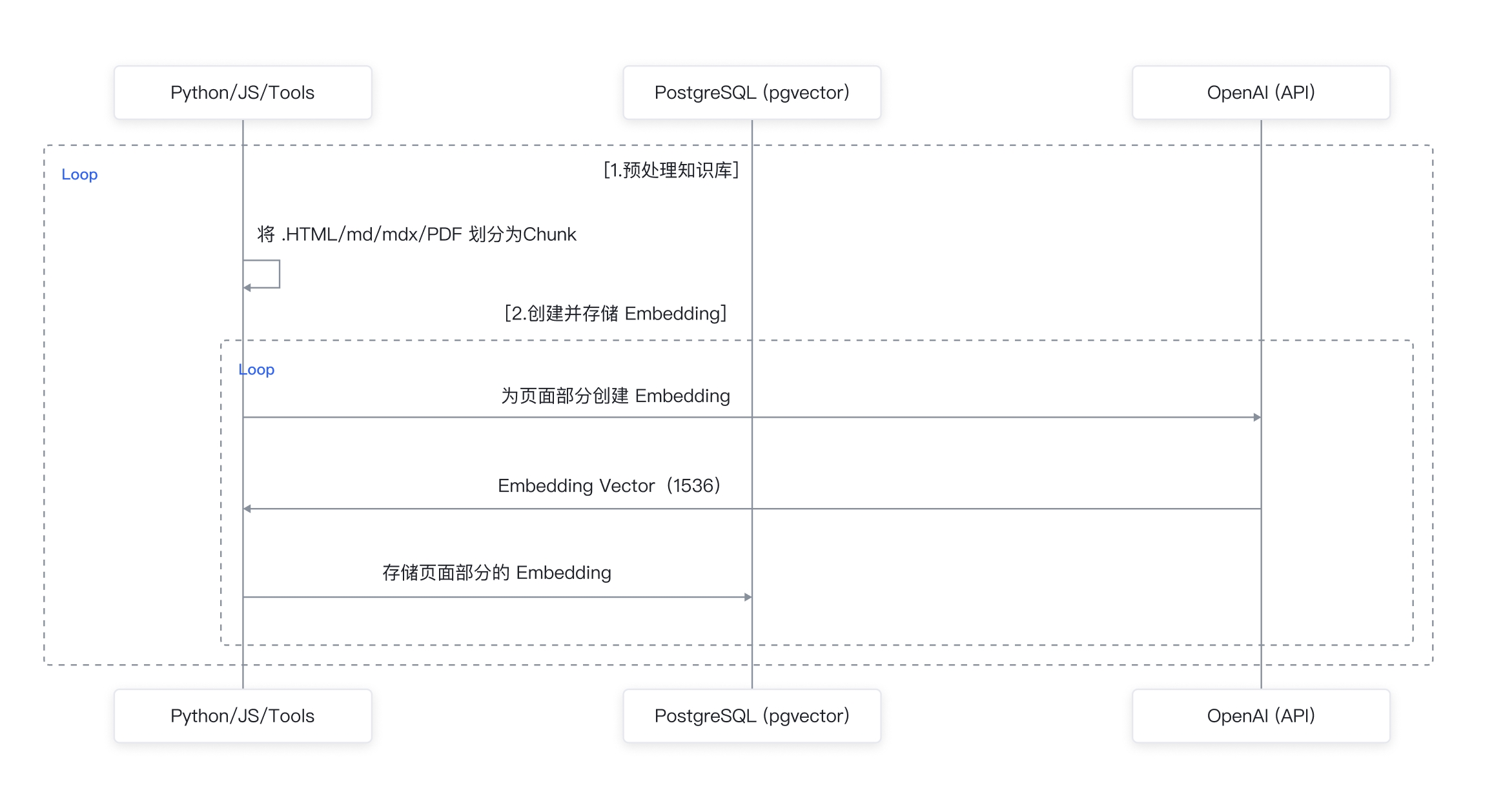
问答阶段
首先问答系统接收用户的提问,同样转换为 Embedding 数据,通过与向量化的问题进行相似性检索,获取最相关的 TOP N 的知识单元。并通过 Prompt 模板,将问题、最相关的 TOP N 知识单元、历史聊天记录,拼装成新的提问问题。大语言模型理解优化过的提问问题,返回相关结果。系统最终将结果返回给提问者。流程如下图所示:
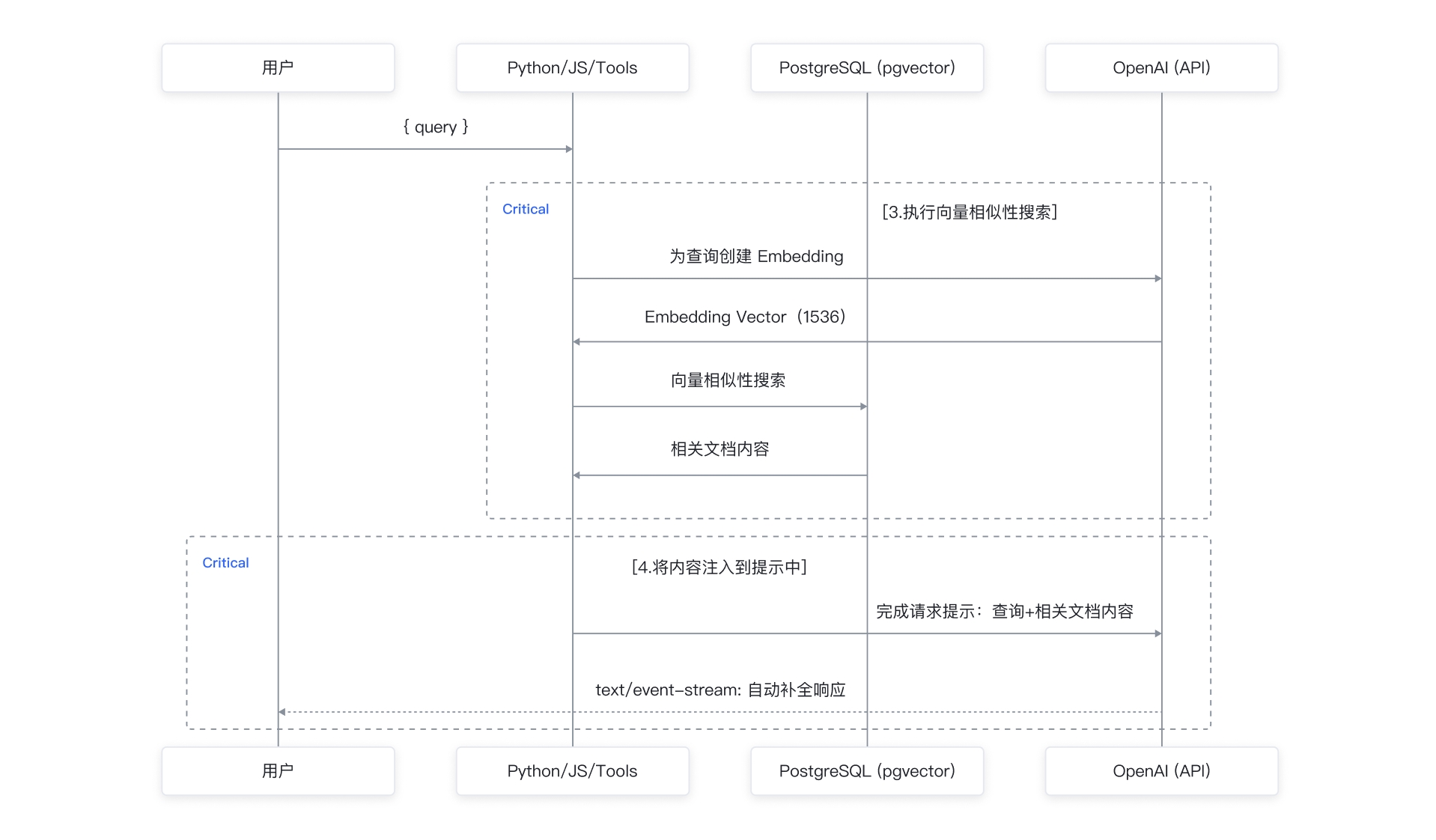
云数据库 PostgreSQL 版作为向量数据库的优势
借助云数据库 PostgreSQL 版提供的 pg_vector 插件,可以构建用于向量高效存储、检索的向量数据库。相较于其他向量数据库,基于云数据库 PostgreSQL 版构建的向量数据库具有如下优势:
使用便捷易上手:无需专业 AI 专家介入,无需构建其他大规模复杂分布式集群,只需要一个数据库实例,便可构建专用向量数据库。使用接口兼容现有 SQL 语法,不需要定制化调度框架、终端。
性价比高:可使用已有数据库实例,不需要额外购买其他庞大的集群资源。
数据实时更新可用:向量数据可以在毫秒级实现新增、更新,并且依然具备事务属性,无需担心数据的错乱。
支持高并发,扩展容易:在向量化场景可支持数千 TPS;在性能出现瓶颈时,可以通过一键扩展只读节点,轻松实现整体吞吐的瞬间提升。
支持向量维度高:pg_vector 还具备支持向量维度高的特点。最多可支持 16000 维向量,能够满足绝大部分向量化存储、使用场景。
前置条件
已创建 ECS 实例,或者使用本地具备 Linux 环境的主机,作为访问数据库的客户端机器。
请确保您具备 OpenAI Secret API Key,并且您的网络环境可以使用 OpenAI。
训练步骤
本文将以构建企业专属“数据库顾问”问答系统为例,演示整个构建过程。使用的知识库样例为 PostgreSQL 15 官方文档,见文末附件。
说明
搭建的环境基于 Debian 9.13。因环境不同依赖包安装会有些许差异,以下方案仅供参考。
以下过程包括两个主要脚本文件,构建知识库的 generate-embeddings.ts脚本见文末附件,问答脚本 queryGPT.py 见 2.2 提问及回答章节示例代码,建议组织项目目录如下所示:
. ├── package.json // ts依赖包 ├── docs │ ├── PostgreSQL15.mdx // 知识库文档 ├── script │ ├── generate-embeddings.ts // 构建知识库 │ ├── queryGPT.py // 问答脚本
1. 学习阶段
1.1 创建 PostgreSQL 实例
登录云数据库 PostgreSQL 版控制台创建实例,并创建数据库和账号。关于创建 PostgreSQL 实例、数据库、账号的详细信息,请参见云数据库 PostgreSQL 版快速入门。
1.2 创建插件
进入测试数据库,并创建 pg_vector 插件。
create extension if not exists vector;
创建对应的数据库表,其中表 doc_chunks 中的字段 embedding 即为知识片段的向量。
-- 记录文档信息
create table docs (
id bigserial primary key,
-- 父文档ID
parent_doc bigint references docs,
-- 文档路径
path text not null unique,
-- 文档校验值
checksum text
);
-- 记录chunk信息
create table doc_chunks (
id bigserial primary key,
doc_id bigint not null references docs on delete cascade, -- 文档ID
content text, -- chunk内容
token_count int, -- chunk中的token数量
embedding vector(1536), -- chunk转化成的embedding向量
slug text, -- 为标题生成唯一标志
heading text -- 标题
);
1.3 构建向量知识库
在客户端机器上,将知识库文档内容,分割成内容大小适当的片段,通过 OpenAI 的 embedding 转化接口,转化成 embedding 向量,并存储到数据库,参考脚本 generate-embeddings.ts(见文末附件)。
注意
该脚本只能处理 markdown 格式的文件。
安装 pnpm。
curl -fsSL https://get.pnpm.io/install.sh | sh -安装 nodejs。更多信息,请参见 NodeSource Node.js Binary Distributions。
sudo apt-get update sudo apt-get install -y ca-certificates curl gnupg sudo mkdir -p /etc/apt/keyrings curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg NODE_MAJOR=16 echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" | sudo tee /etc/apt/sources.list.d/nodesource.list sudo apt-get update sudo apt-get install nodejs -y安装 typescript 依赖(
package.json)。pnpm run setup pnpm install tsx修改
generate-embeddings.ts,设置 OpenAI 的 key、PostgreSQL 的连接串以及 markdown 文档目录。#这里需要将 user、passwd、127.0.0.1、5432 替换为实际数据库用户、密码、数据库地址、端口 const postgresql_url = 'pg://user:passwd@127.0.0.1:5432/database'; const openai_key = '-------------'; const SOURCE_DIR = path.join(__dirname, 'document path');运行脚本,生成文档 embedding 向量并插入数据库。
pnpm tsx script/generate-embeddings.ts
运行过程如下图所示: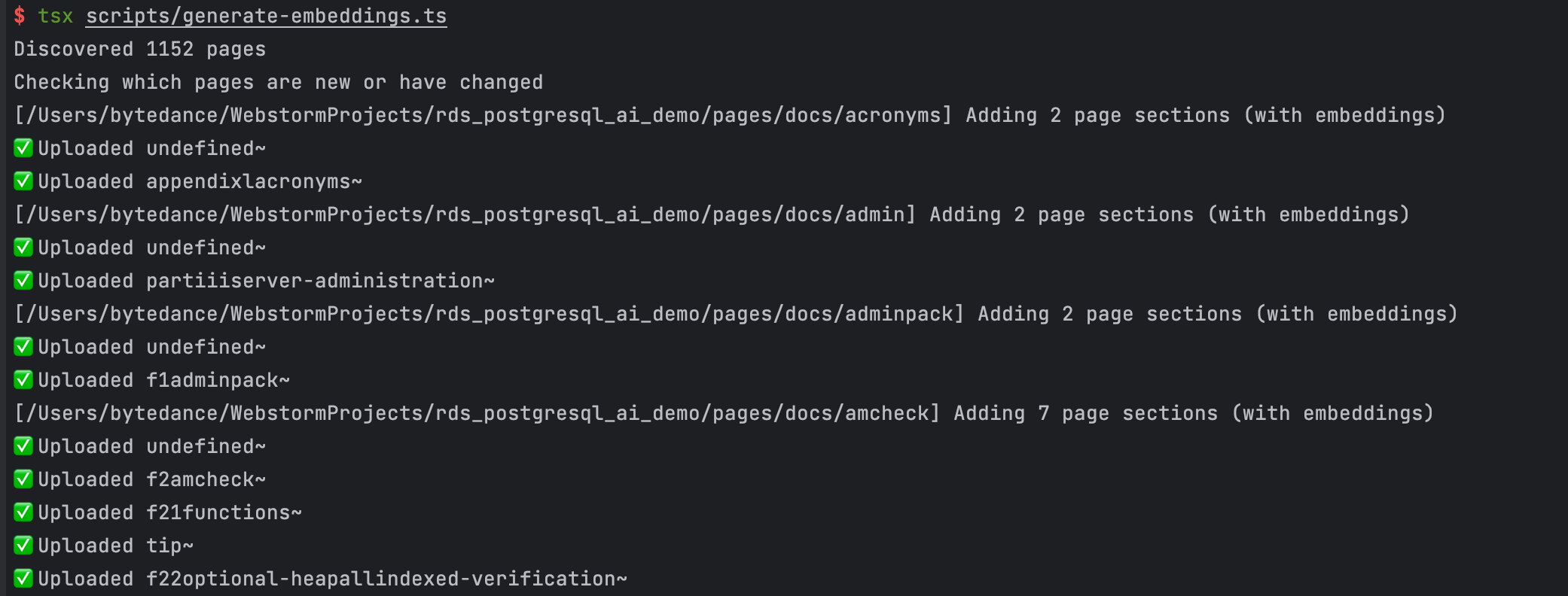
脚本运行后,我们查看下所构建的知识库,查询 docs 表:
查询 docs_chunk 表,批量导入向量成功: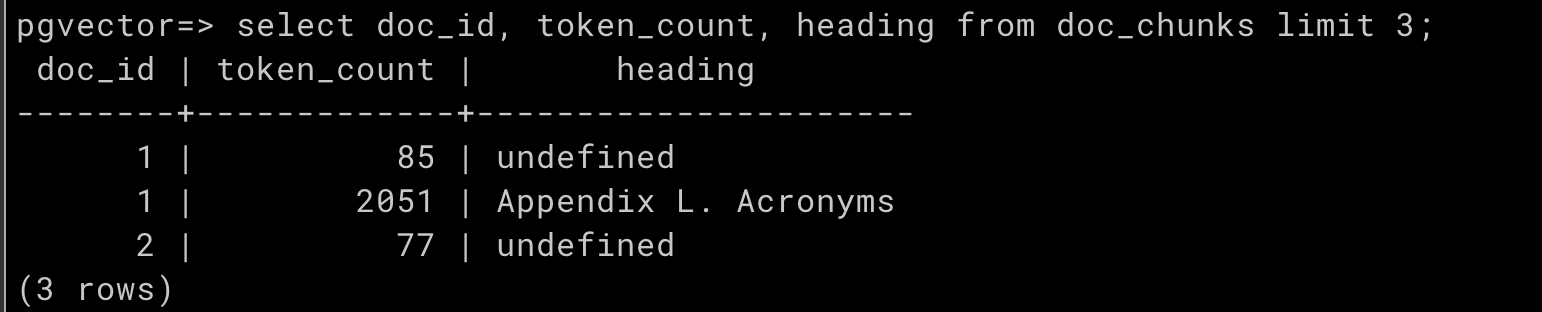
2. 问答阶段
2.1 创建相似度计算函数
为了方便应用使用,使用 PostgreSQL 的自定义函数功能,创建内置于数据库内的函数。应用只需调用 PostgreSQL,该函数便可在应用程序中获取向量匹配结果。示例中使用“内积”来计算向量的相似性。
create or replace function match_chunks(chunck_embedding vector(1536), threshold float, count int, min_length int)
returns table (id bigint, content text, similarity float)
language plpgsql
as $$
begin
return query
select
doc_chunks.id,
doc_chunks.content,
(doc_chunks.embedding <#> chunck_embedding) * -1 as similarity
from doc_chunks
-- chunk内容大于设定的长度
where length(doc_chunks.content) >= min_length
-- The dot product is negative because of a Postgres limitation, so we negate it
and (doc_chunks.embedding <#> chunck_embedding) * -1 > threshold
order by doc_chunks.embedding <#> chunck_embedding
limit count;
end;
$$;
2.2 提问及回答
以下 Python 程序,可以接收提问者问题,并实现上述 Prompt Engineering 的“问答阶段”的功能,最终将具备“逻辑思考”+“深度领域知识”的解答,发送给提问者。
import os, psycopg2, openai
def query_handler(query = None):
if query is None or query == "":
print('请输入有效问题')
return
query = query.strip().replace('\n', ' ')
embedding = None
try:
# 使用 GPT 将提问转化为 embedding 向量
response = openai.Embedding.create(
engine="text-embedding-ada-002", # 固定为text-embedding-ada-002
input=[query],
)
embedding = response.data[0].embedding
except Exception as ex:
print(ex)
return
content = ""
con = None
try:
# 处理 postgres 配置,连接数据库
# host:127.0.0.1,port:5432,user:test,password:test,database:test
params = postgresql_url.split(',')
database, user, password, host, port = "test", "test", "test", "127.0.0.1", "5432"
for param in params:
pair = param.split(':')
if len(pair) != 2:
print('POSTGRESQL_URL error: ' + postgresql_url)
return
k, v = pair[0].strip(), pair[1].strip()
if k == 'database':
database = v
elif k == 'user':
user = v
elif k == 'password':
password = v
elif k == 'host':
host = v
elif k == 'port':
port = v
# connect postgres
con = psycopg2.connect(database=database, user=user, password=password, host=host, port=port)
cur = con.cursor()
# 从数据库查询若干条最接近提问的 chunk
sql = "select match_chunks(\'[" + ','.join([str(x) for x in embedding]) + "]\', 0.78, 5, 50)"
cur.execute(sql)
rows = cur.fetchall()
for row in rows:
row = row[0][1:-2].split(',')[-2][1:-2].strip()
content = content + row + "\n---\n"
except Exception as ex:
print(ex)
return
finally:
if con is not None:
con.close()
try:
# 组织提问和 chunk 内容,发送给 GPT
prompt = '''Pretend you are GPT-4 model , Act an database expert.
I will introduce a database scenario for which you will provide advice and related sql commands.
Please only provide advice related to this scenario. Based on the specific scenario from the documentation,
answer the question only using that information. Please note that if there are any updates to the database
syntax or usage rules, the latest content shall prevail. If you are uncertain or the answer is not explicitly
written in the documentation, please respond with "I'm sorry, I cannot assist with this.\n\n''' + "Context sections:\n" + \
content.strip().replace('\n', ' ') + "\n\nQuestion:\"\"\"" + query.replace('\n', ' ') + "\"\"\"\n\nAnswer:"
print('\n正在处理,请稍后。。。\n')
response = openai.ChatCompletion.create(
engine="gpt_openapi", # 固定为gpt_openapi
messages=[
{"role": "user", "content": prompt}
],
model="gpt-35-turbo",
temperature=0,
)
print('回答:')
print(response['choices'][0]['message']['content'])
except Exception as ex:
print(ex)
return
os.environ['OPENAI_KEY'] = '-----------------------'
os.environ['POSTGRESQL_URL'] = 'host:127.0.0.1,port:5432,user:test,password:test,database:test'
openai_key = os.getenv('OPENAI_KEY')
postgresql_url = os.getenv('POSTGRESQL_URL')
# openai config
openai.api_type = "azure"
openai.api_base = "https://example-endpoint.openai.azure.com"
openai.api_version = "2023-XX"
openai.api_key = openai_key
def main():
if openai_key is None or postgresql_url is None:
print('Missing environment variable OPENAI_KEY, POSTGRESQL_URL(host:127.XX.XX.XX,port:5432,user:XX,password:XX,database:XX)')
return
print('我是您的PostgreSQL AI助手,请输入您想查询的问题,例如:\n1、如何创建table?\n2、给我解释一下select语句?\n3、如何创建一个存储过程?')
while True:
query = input("\n输入您的问题:")
query_handler(query)
if __name__ == "__main__":
main()
使用脚本
在应用上述脚本时,需要完成以下步骤:
需要将上述代码段中的 OpenAI 的 key 和 PG 的连接串,更新为实际 key 和连接串:
os.environ['OPENAI_KEY'] = '-----------------------' os.environ['POSTGRESQL_URL'] = 'host:127.0.0.1,port:5432,user:test,password:test,database:test'修改 GPT 的参数:
openai.api_type = "azure" openai.api_base = "https://example-endpoint.openai.azure.com" openai.api_version = "2023-XX"修改机器人的自我介绍,以让提问者快速了解问答机器人的专业特长。这里的自我介绍,说明机器人是一个数据库专家的角色。
prompt = '''Pretend you are GPT-4 model , Act an database expert. I will introduce a database scenario for which you will provide advice and related sql commands. Please only provide advice related to this scenario. Based on the specific scenario from the documentation, answer the question only using that information. Please note that if there are any updates to the database syntax or usage rules, the latest content shall prevail. If you are uncertain or the answer is not explicitly written in the documentation, please respond with "I'm sorry, I cannot assist with this.\n\n''' + "Context sections:\n" + \ content.strip().replace('\n', ' ') + "\n\nQuestion:\"\"\"" + query.replace('\n', ' ') + "\"\"\"\n\nAnswer:"安装脚本依赖:
pip install psycopg2-binary pip install openai pip install 'openai[datalib]'
验证脚本
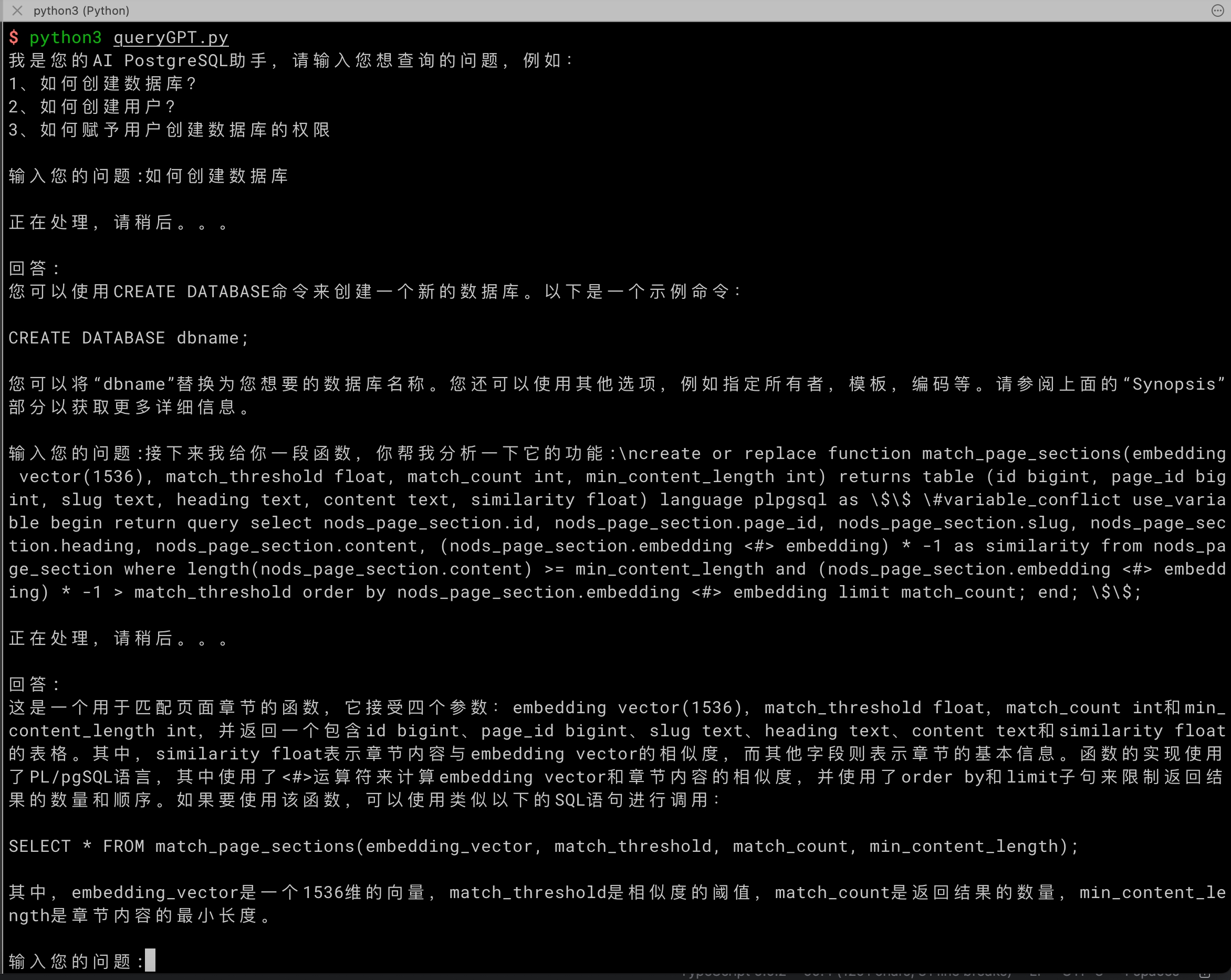
到此为止,您就获得了一个企业级专属智能问答系统。
参考

