导航
私有化部署
最近更新时间:2022.11.23 16:40:15首次发布时间:2022.10.17 10:23:42
大数据文件存储(CloudFS)支持私有化部署,搭建高可靠,低成本,无限容量的分布式文件系统,并可与火山引擎流式计算 Flink、批式计算 Spark等产品结合部署使用。
功能介绍
大数据文件存储(CloudFS)是面向大数据和机器学习生态的文件存储产品和服务,支持完整的HDFS语义,无需修改代码即可使用高可靠、低成本、高可用的分布式文件系统,在文件存储场景无缝兼容HDFS使用方式,在数据湖场景提供多元格式数据的存储与使用能力。
大数据文件存储(CloudFS)支持私有化部署,与公有云保持同源演进,针对私有化部署的大数据文件存储进行云原生改造,实现线下大数据引擎云原生部署和全生命周期管理,为客户构建新一代大数据存储底座。
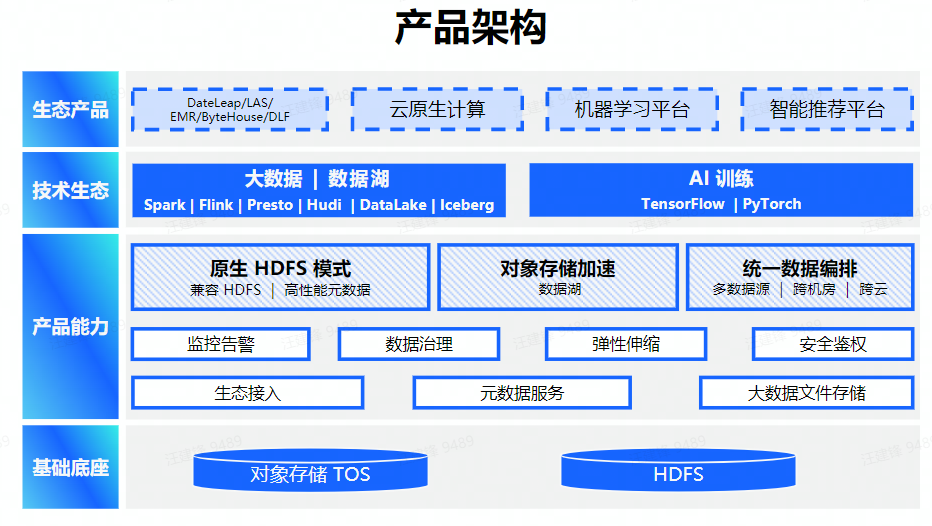
应用场景
金融、制造、医疗等行业进行大数据流、批处理和数据分析,用于报表生成,客户分析等。
客户痛点:存算一体架构资源扩缩难;存储可靠性差;成本高
关键特性:计算&缓存资源动态伸缩、海量的存储空间、稳定可靠的存储服务
金融、制造、医疗等行业大量使用AI服务业务,如:用户分析、智能推荐、病灶检查等
客户痛点:数据量级大,处理、移动困难;数据的IO要求高,TOS 无法满足;小文件数量多;数据格式复杂。
关键特性:数据统一管理、小文件场景优化、为模型训练提供充沛的 I/O 能力。
产品优势
- 高可靠
NameNode深度自研,跨 AZ 数据高可靠,提供高性能,高可靠的元数据服务。 - 低成本
支持存储空间线性扩展,降低成本。 - 高效能
支持大数据处理和机器学习的数据存储需求,提升数据处理效能。 - 高性能
提供高吞吐,高稳定的数据读写能力,读取和写入速度快。