大部分模型除了支持用户查看说明信息之外,也允许用户体验模型的推理效果,比如与大语言模型进行日常对话。
平台提供两种体验入口,您可以按照自己的需求进行选择。
入口一:在模型详情页左上角单击「立即体验」即可进入对应的能力体验页面。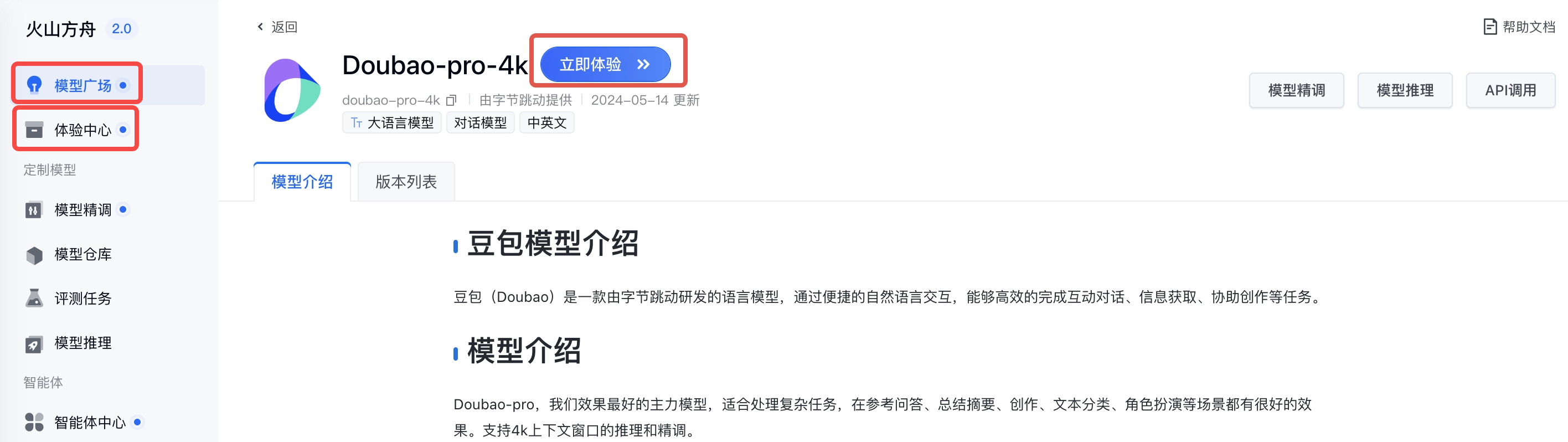
入口二:在火山方舟左侧菜单栏,点击「体验中心」,即可开启模型体验。
进入体验中心页面后,首次进入会推荐常见场景下的优质模型,您可以点击不同场景,直接开启大语言模型的对话体验。也可以点击「选择更多模型」,挑选心仪的模型进行体验。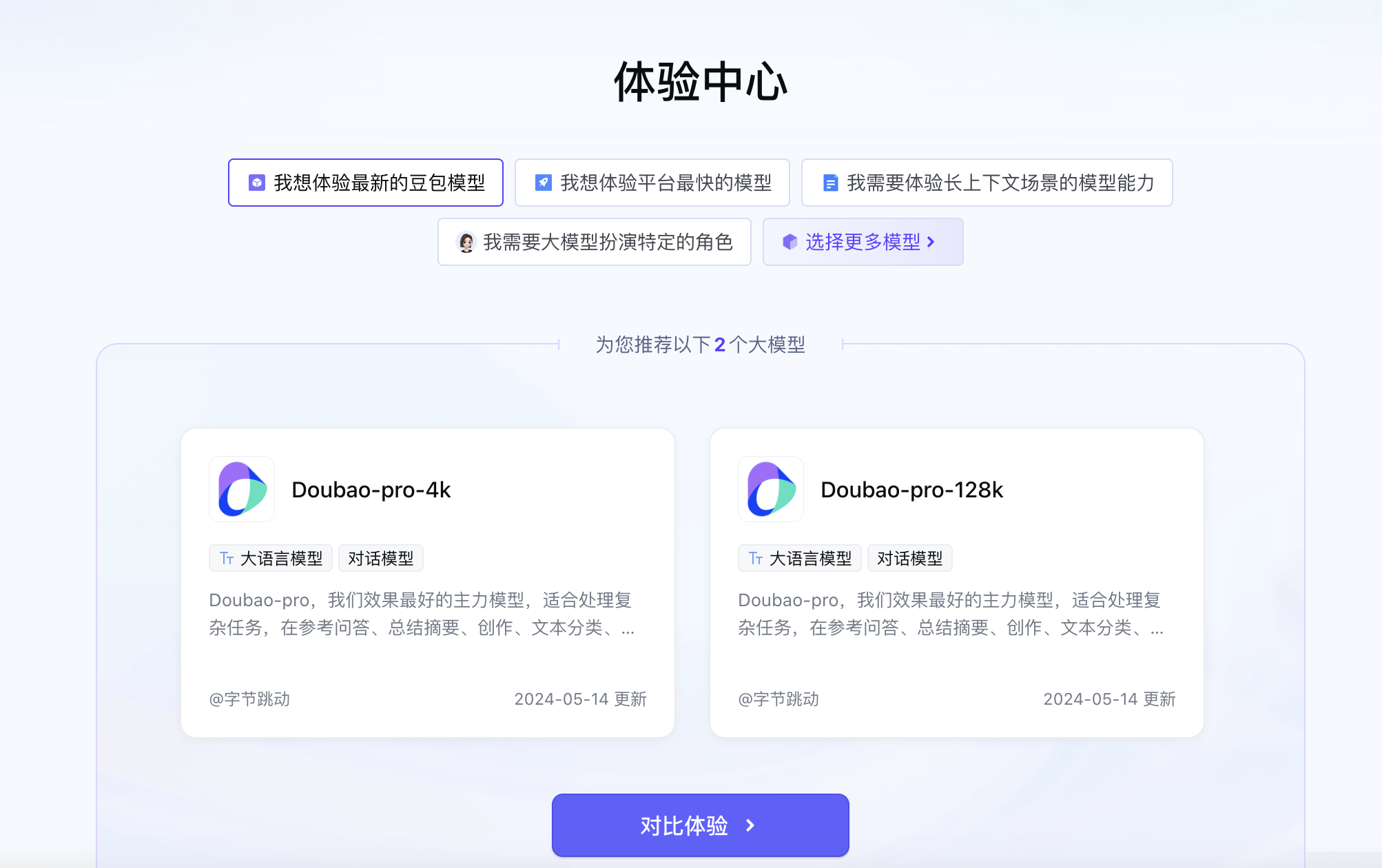
完成一次完整对话的操作步骤
完成一次对话,只需三步,具体如下:
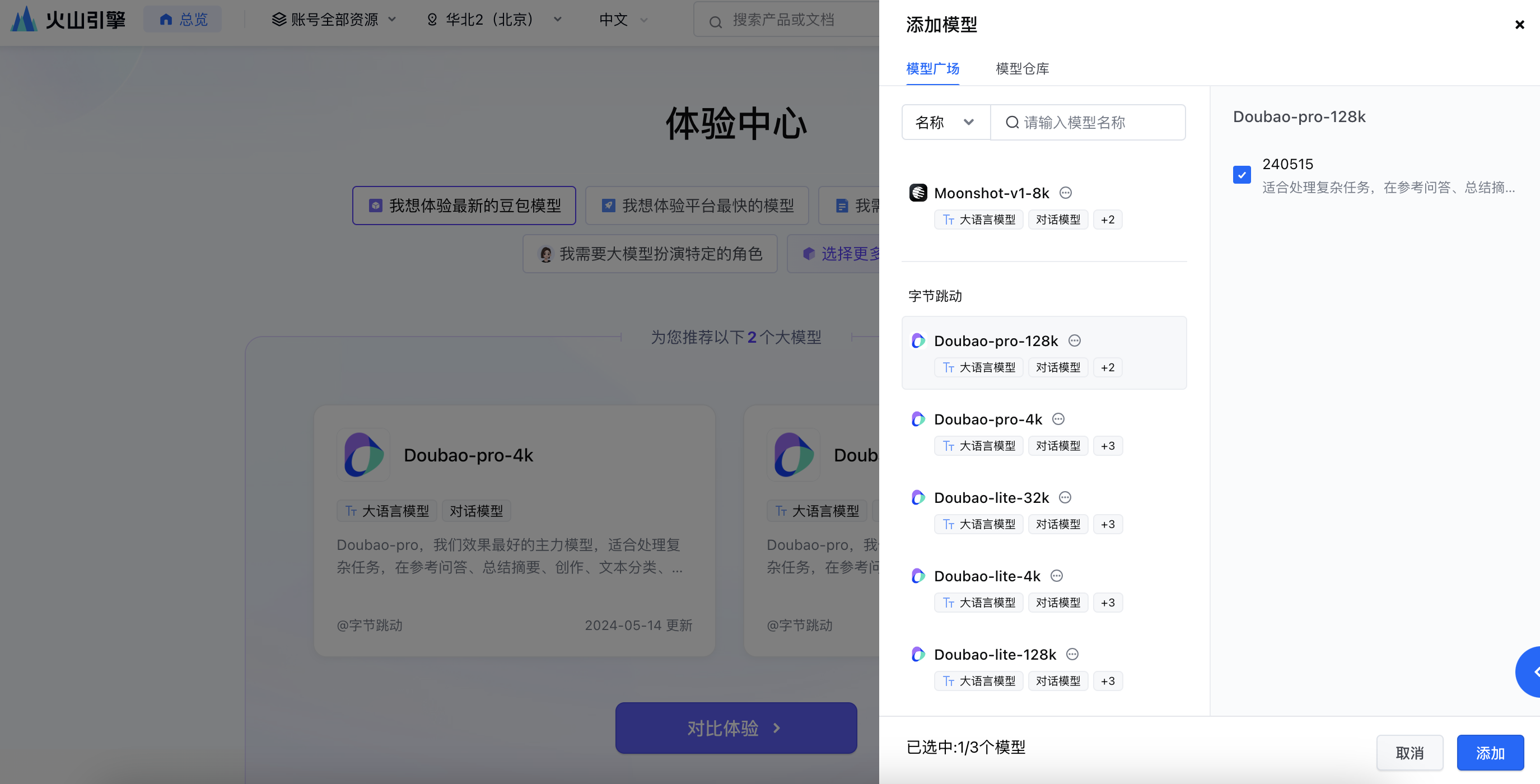
步骤一:首次进入,需先选择模型。点击预置的场景直接开启「对比体验」,或「选择更多模型」,在弹出的窗口中,选择您要体验的模型和版本,点击「添加」。
若您已添加模型,可跳过此步骤,直接体验感兴趣的模型。
步骤二:选中感兴趣的模型,进行对话,如果您不知道如何开启与大模型的对话,平台大部分模型提供「快速提问」功能,直接点击问题Prompt,即可完成提问。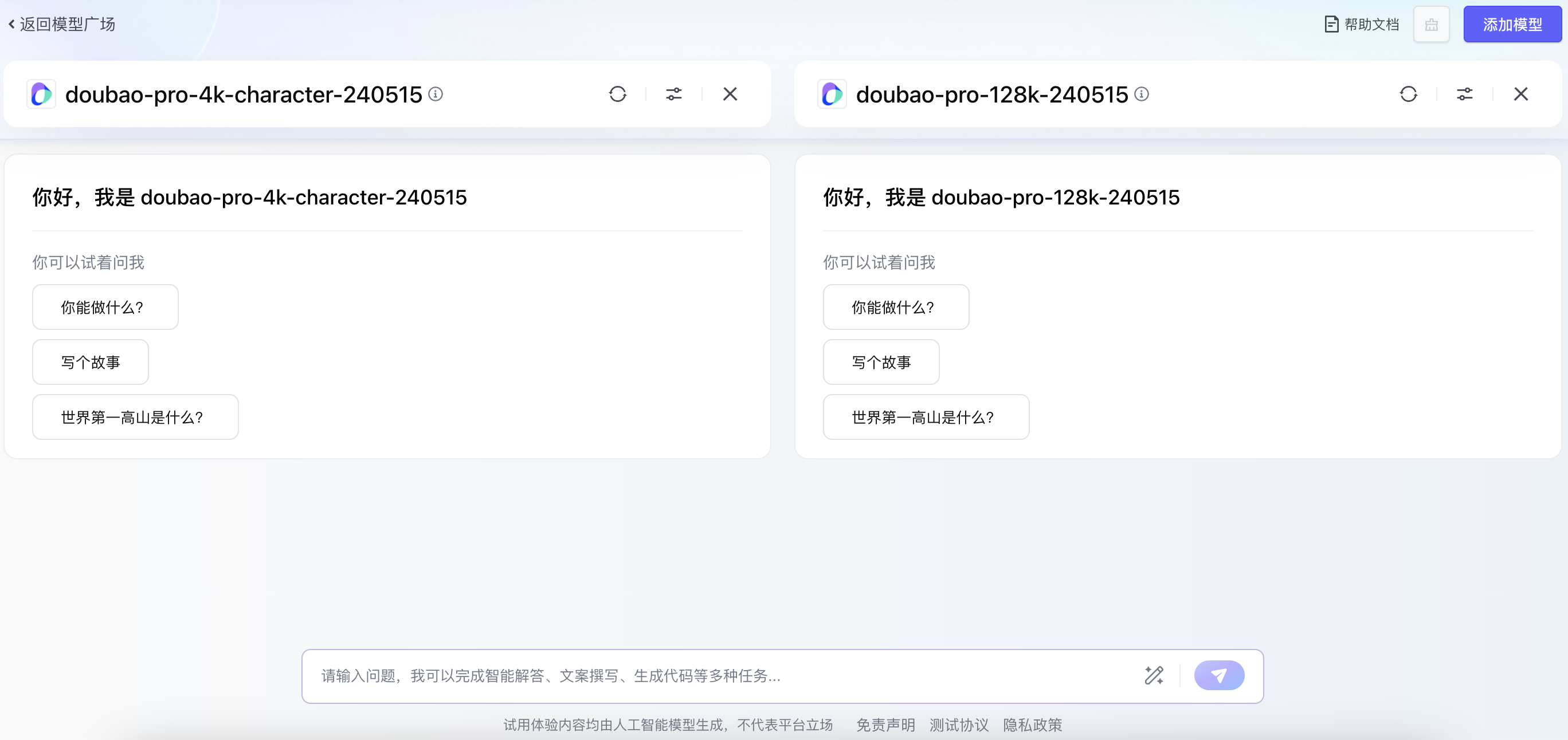
步骤三:对于模型生成的回答,您可以给予好评或差评的反馈。如果您对模型的回答不满意,还可以点击刷新重新生成答案。您还可以点击复制,复制模型生成的内容。
此外,对话底部还展示了此轮回答的首token延迟、平均每秒消耗token数、总耗时时间、调用token数的信息,您可以比较模型的性能。
您可以点击「清除上下文」,结束此轮对话,并清空上下文关系,下方对话将不受上方内容影响。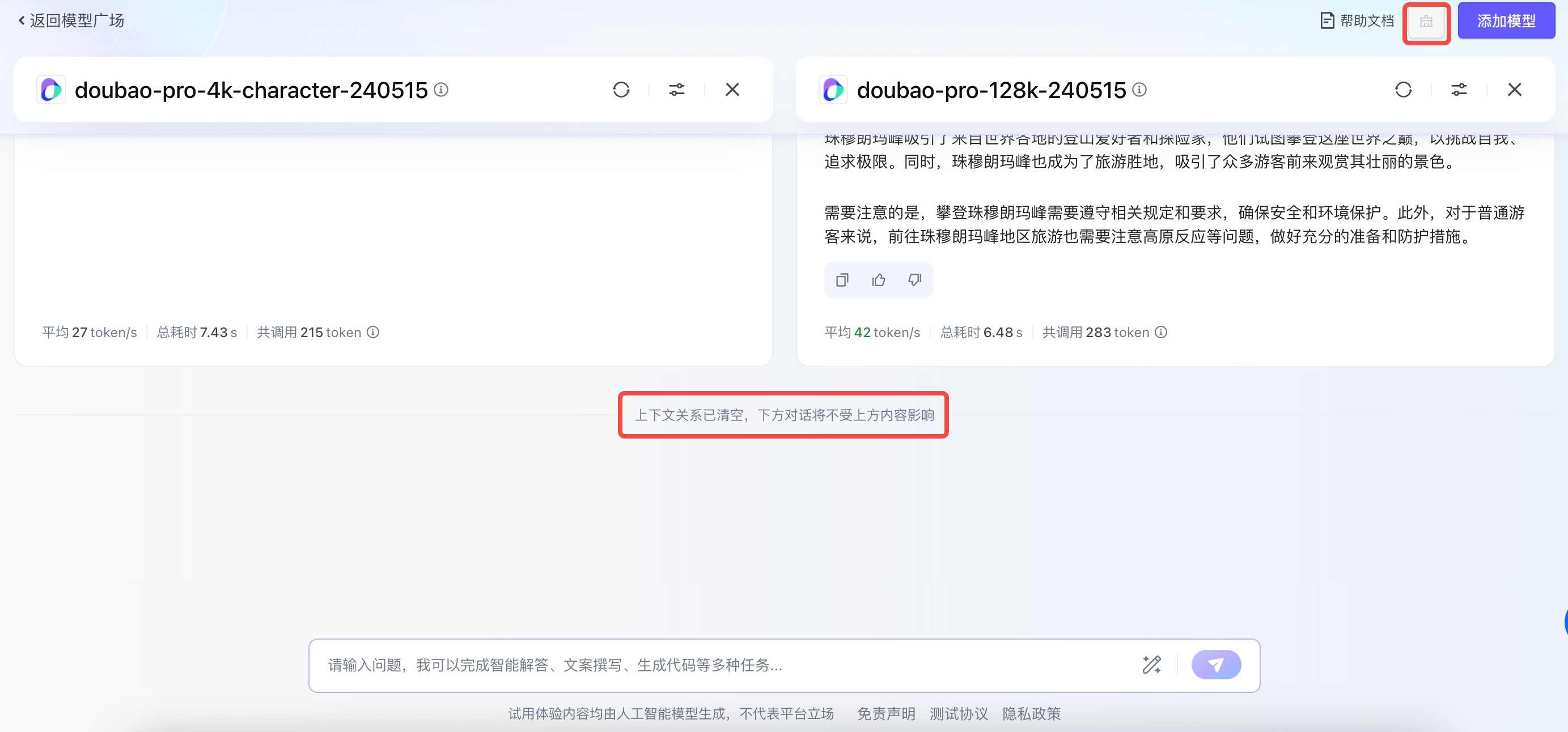
- 当您想换个话题与大模型进行交流时,可点击页面左侧的「+」,开启新一轮的对话。

- 对于已有话题可以进行标题的重命名、删除操作。

- 支持在列表中随意切换模型和话题。

平台向用户展示了模型的若干可调参数,不同的参数设置会影响模型生成的回答,您可以根据自己的需求进行设置。点击模型下方的「高级设置」,可以调整模型的参数。
每个参数名后面紧跟着“?”,将鼠标悬浮在上面,即可展示该参数的详细说明,帮助您理解该参数。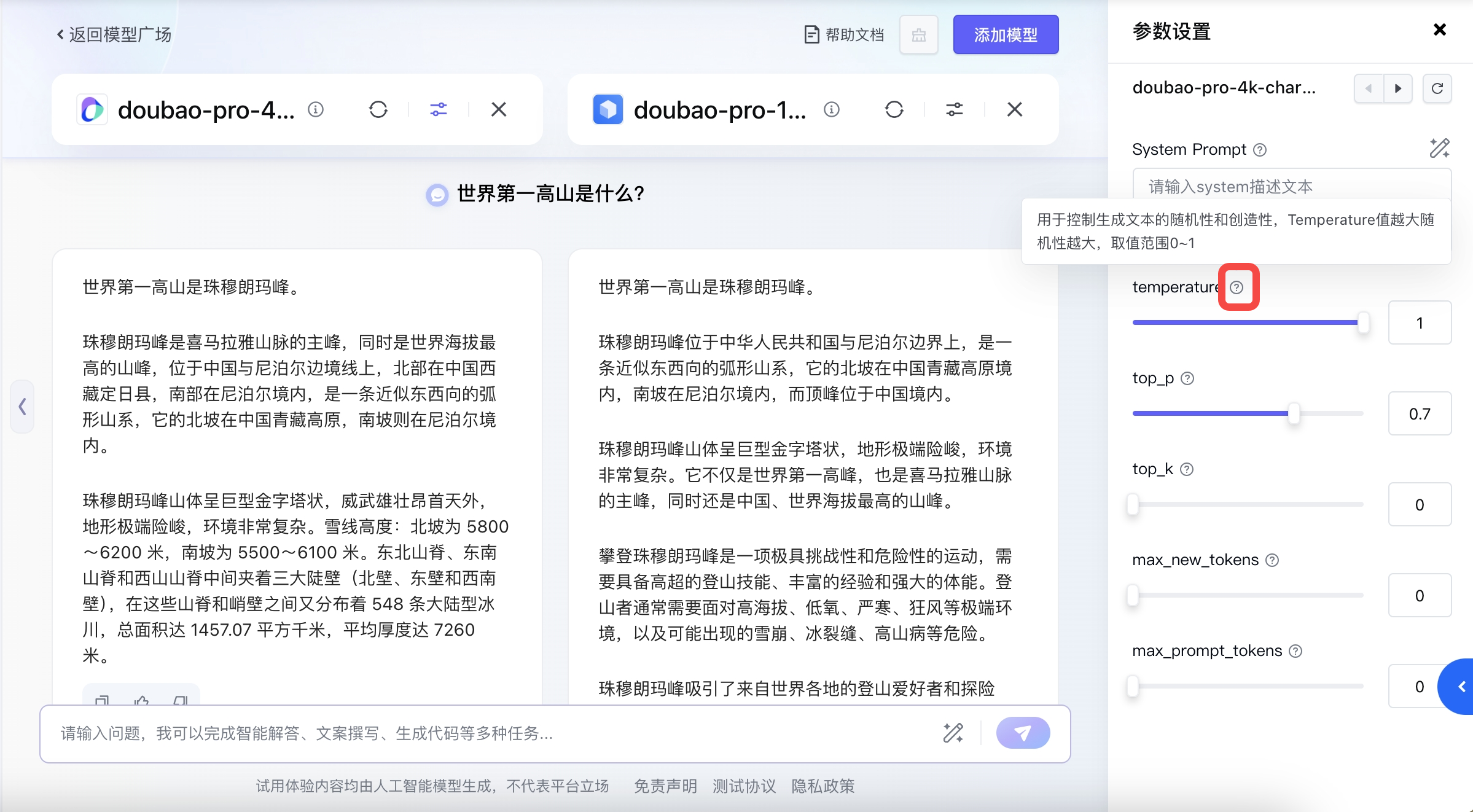
不同的模型支持的参数不同,下表列出了所有的参数:
参数名 | 参数说明 |
|---|---|
MaxNewTokens | 输出文本的最大tokens限制。
|
Temperature | 用于控制生成文本的随机性和创造性,Temperature值越大随机性越大,取值范围0~1,默认值为0.9。
|
TopP | 用于控制输出tokens的多样性,TopP值越大输出的tokens类型越丰富,取值范围0~1,默认值为0.95。
详细解释:TopP可以设置tokens候选列表的大小, 将可能性之和刚好超过设定值P的top tokens列入候选名单,然后从候选名单中随机采样,生成一个token。 |
TopK | 用于控制输出tokens的多样性,TopK值越大输出的tokens类型越丰富,取值范围>0,默认值为X。
详细解释:TopK可以设置保留概率最高的前K个tokens,从中随机抽取一个token作为最终输出,这种方法可以限制输出序列的长度,并仍然保持样本的一定多样性。 |