数据库传输服务 DTS 支持全增一体功能,该功能可以帮助您在进行数据迁移和同步时,将全量数据和增量数据混合去重后并发迁移或同步至目标端,从而提高数据的传输速率,降低数据回退的可能性。本文介绍全增一体的优势、流程图、性能对比等信息。
流程图
数据迁移
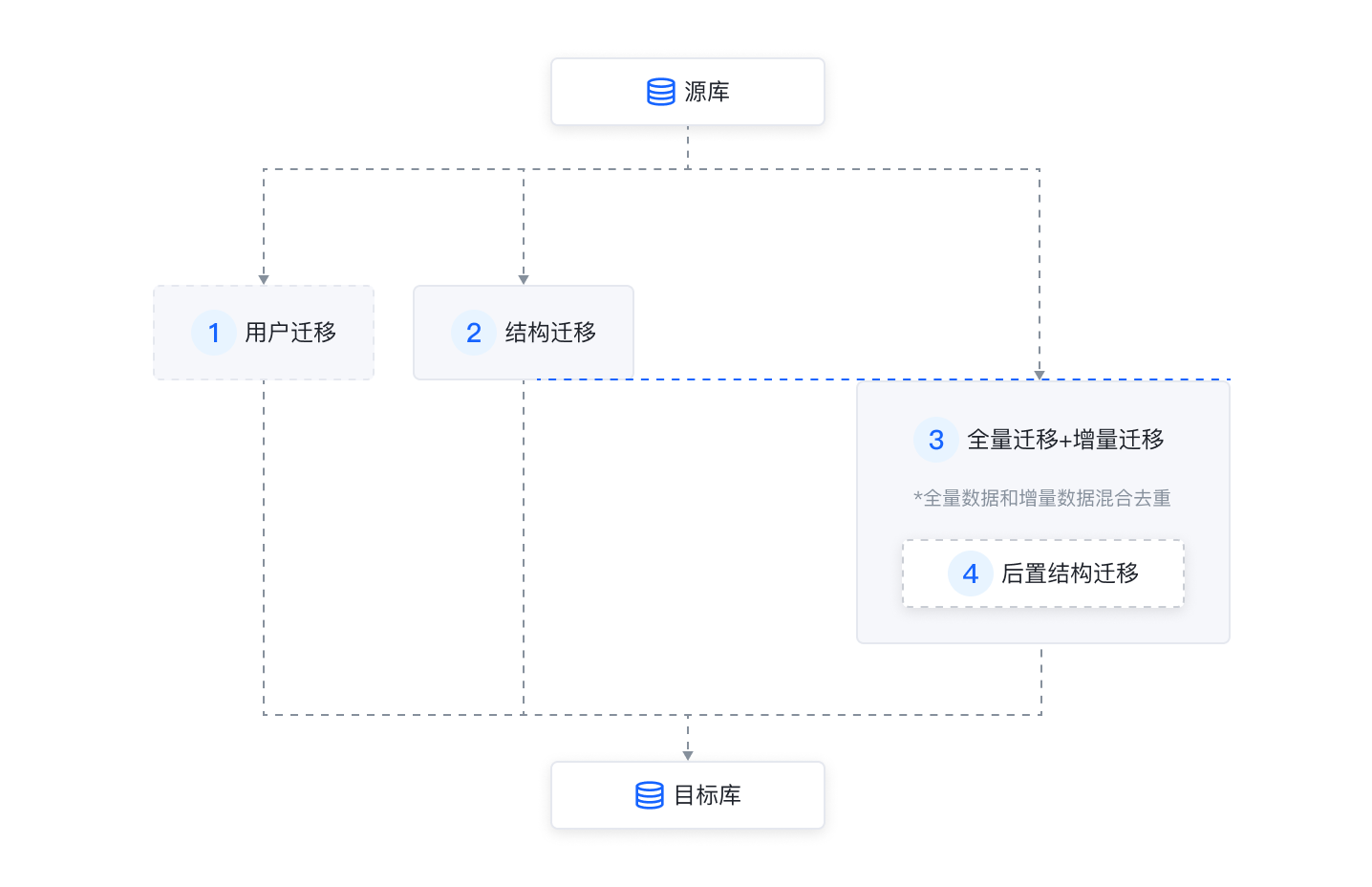
结构迁移:读取源库表结构定义语法,重新组装成目标库的语法格式。
全量迁移 + 增量迁移:全量读取源表内容的同时进行目标库增量日志解析和回放,读取增量数据,DTS 将全量和增量的混合数据去重后同时写入到目标端。
后置结构迁移:为保证数据迁移的性能和迁移任务的稳定性,部分数据库迁移对象会在全量和增量迁移结束后进行创建。需要进行后置结构迁移的对象是 MySQL:TRIGGER、EVENT。
数据同步
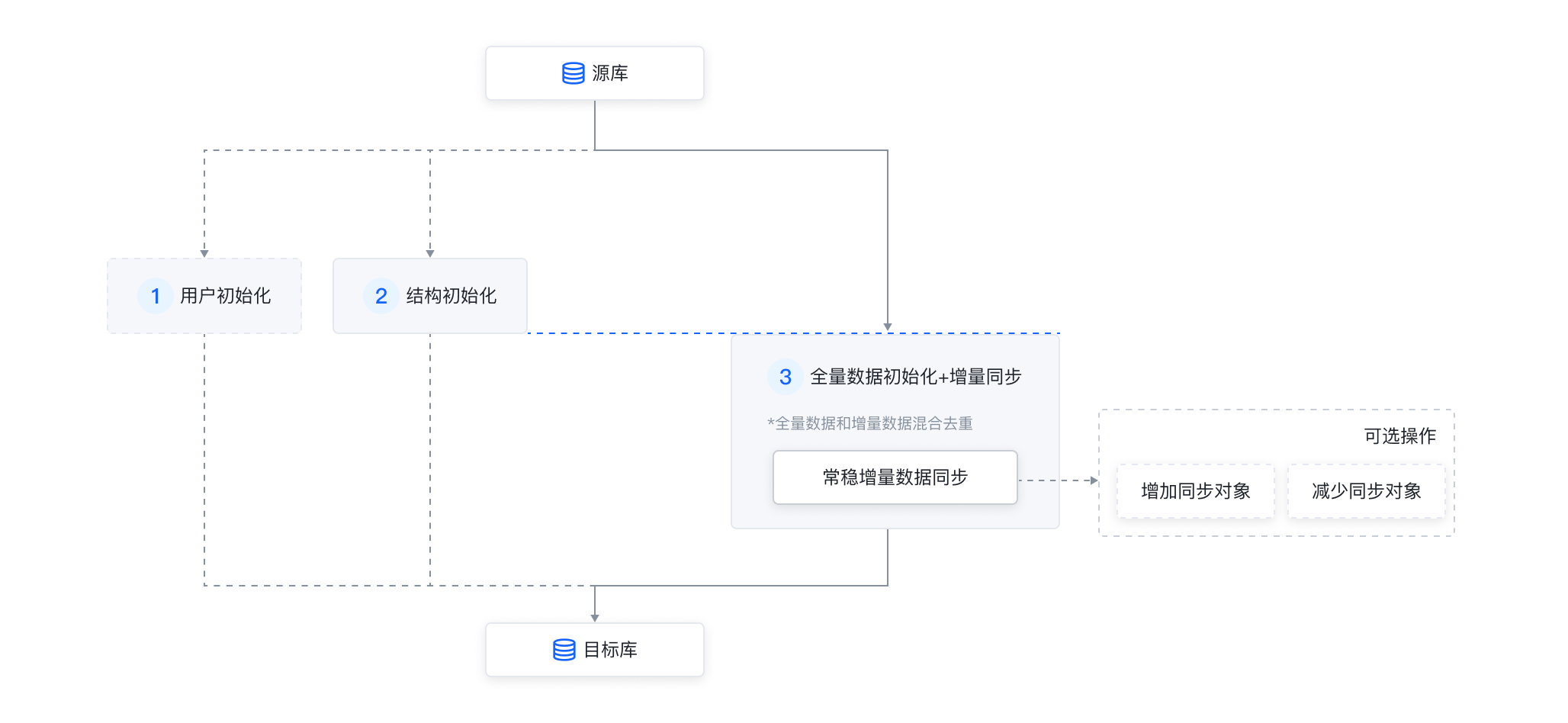
结构初始化:读取源库表结构定义语法,重新组装成目标库的语法格式。
全量初始化 + 增量同步:全量读取源表内容的同时进行目标库增量日志解析和回放,读取增量数据,将全量和增量的混合数据去重后同时写入到目标端。
优势
更具灵活性:能够在同一任务中,更加灵活地对不同表的同步类型、数据过滤范围以及冲突策略进行配置。
摆脱数据依赖:支持对更大的表进行迁移或同步,在迁移或同步过程中不再依赖 Kafka,不必担心全量时间过长造成数据延迟的问题。
提升效率:显著提高数据的新鲜度,极大程度地降低了数据回退的可能性。在迁移或同步任务启动时,增量数据便开始全部写入目的端,全量和增量同步进行。
节省时间:减少大库场景割接所需时间,省去全量数据迁移或同步完成后追增量数据的环节。
简化流程:在变更数据迁移或同步任务对象时,缩短任务的等待时间,由于全量和增量数据变更同步并发,发起变更后,只需完成结构变更就能开展下一轮的数据变更。
性能对比
在增量迁移或增量同步阶段,DTS 的开发人员对使用了全增一体和未使用全增一体的同步任务进行传输相同数据的性能进行了对比,结果表明使用全增一体进行数据传输的效率更高,具体数据如下表所示。
火山引擎云数据库 MySQL 版实例的规格和数据库传输服务 DTS 数据同步任务的规格如下所示
火山引擎云数据库 MySQL 版实例的规格如下:
兼容版本: MySQL 5.7
节点规格:8 核 16GB(rds.mysql.d1.n.8c16g)
存储空间:500GB。
数据库传输服务 DTS 同步任务:
链路规格:Compact
同步拓扑:单向同步
源库和目标库的实例接入方式:火山引擎版 MySQL
同步类型:结构初始化 + 全量初始化 + 增量同步
冲突策略:冲突覆盖
| 数据类型 | 源端 | 目标端 | 未开启全增一体 | 开启全增一体 |
|---|---|---|---|---|
单行 250b | 华北2(北京) | 华北2(北京) |
|
|
华北2(北京) | 华南1(广州) |
|
| |
单行 500b | 华北2(北京) | 华北2(北京) |
|
|
华北2(北京) | 华南1(广州) |
|
| |
华北2(北京) | 亚太东南(柔佛) |
|
| |
单行 1k | 华北2(北京) | 华北2(北京) |
|
|
华北2(北京) | 华南1(广州) |
|
| |
华北2(北京) | 亚太东南(柔佛) |
|
| |
单行 100k | 华北2(北京) | 华北2(北京) |
|
|
华北2(北京) | 华南1(广州) |
|
| |
华北2(北京) | 亚太东南(柔佛) |
|
| |
单行 500k | 华北2(北京) | 华北2(北京) |
|
|
华北2(北京) | 华南1(广州) |
|
| |
华北2(北京) | 亚太东南(柔佛) |
|
|
使用限制
当前全增一体功能处于邀测阶段,若需使用,请提交工单联系技术支持。
当前仅支持开启 MySQL 到 MySQL 类型的迁移和同步任务的全增一体功能。
当任务开启了全增一体时,由于全量和增量的数据会并发迁移或同步到目标端,所以不支持单独设置全量迁移和全量同步任务的并发数。
当任务开启了全增一体时,由于全量和增量的数据会并发迁移或同步到目标端,所以不支持单独配置增量迁移或增量同步任务的延迟隔离。
已创建的任务不支持变更任务的传输架构,如需进行全增一体,您需要重新创建任务或在原先的任务基础上进行复制。关于如何复制任务,请参见复制迁移任务或复制同步任务。
相关文档
您可以在创建 MySQL 类型的数据迁移和同步任务中开启全增一体功能,相关文档如下所示: