流式数据 ETL(Extract Transform Load)是数据库传输服务 DTS 提供的数据处理工具,基于领域特定语言(Domain Specific Language,简称 DSL)语法编写 SQL 语句配置数据处理脚本语言,结合 DTS 的高效流数据复制能力,对流式数据进行抽取、转换、加工和装载。本文介绍 ETL 的背景信息和应用场景。
背景信息
DSL 是数据库传输服务 DTS 基于 LISP-1 标准为数据同步场景中数据处理需求设计的脚本语言。DTS 通过 DSL 脚本语言可以对数据中的字符串、日期和数值等进行抽取、转换、加工和加载,用于数据过滤等典型场景。关于 DSL 语法的详细信息,请参见 DSL 语法。
应用场景
数据库传输服务 DTS 结合 ETL 工具用于数据过滤、数据脱敏、记录数据修改时间和数据变更审计等典型场景,具体示例如下所示:
数据过滤
行过滤
例如在某些电商场景中,当需要同步已支付的订单行时,您可以为 DTS 任务配置 ETL 过滤函数,使用 DSL 语法插入额外的转换逻辑,删除未支付的订单。本示例以如下 SQL 语句为例,配置 ETL 过滤函数过滤未支付的订单行:CREATE TABLE orders (id bigint(20) primary key,state tinyint); INSERT INTO orders VALUES (1,0); -- 0 未支付订单 INSERT INTO orders VALUES (2,1); -- 1 已支付订单ETL 过滤函数如下所示:
(defn filter-payed-orders [] (dts/match-table "orders" (if (= 0 (dts/column 'state)) (dts/drop))))字段过滤
例如在某些特殊场景中,当需要对某些字段进行过滤处理时,您可以为 DTS 任务配置 ETL 过滤函数,使用 DSL 语法插入额外的转换逻辑,过滤掉敏感字段。本示例以如下 SQL 语句为例,配置 ETL 函数过滤敏感字段:CREATE TABLE staff (id bigint(20) primary key, name varchar(30), marriage varchar(20)); INSERT INTO staff VALUES (1,"Tom","已婚");ETL 过滤函数如下所示:
(defn drop-marriage-field [] (dts/match-table "staff" (dts/drop-column 'marriage)))
数据脱敏
在数据备份、数据集成等场景中,可能需要对数据进行统计分析,为保证用户隐私数据的安全,您需要为 DTS 任务配置 ETL 过滤函数,使用 DSL 语法插入额外的转换逻辑,对敏感数据进行脱敏。本示例以如下 SQL 语句为例,配置 ETL 函数将身份信息转换成 MD5 值过滤敏感数据:
CREATE TABLE user(id int NOT NULL PRIMARY KEY, id_card varchar(100) NOT NULL, name varchar(100) NOT NULL); INSERT INTO user VALUES(1, '123456789', '张三'); INSERT INTO user VALUES(2, '987654321', '李四');
ETL 过滤函数如下所示:
(defn desensitization [] (dts/match-table "user" (dts/map-column 'id_card str/md5)))
字段变换
转换 JSON 字符串为 JSON 结构体
由于 DTS 支持异构类型的数据间的同步,例如将 MySQL 雇员表中 JSON 字符串的 education 字段同步到 Elasticsearch 中,并以 JSON 结构体呈现。本示例以如下 SQL 语句为例,配置 ETL 函数将 JSON 字符串转换为 JSON 结构体:CREATE TABLE `employee` ( `id` bigint NOT NULL, `name` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `education` json DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci -- 写入数据 insert into employee values(1,"Jack", '[{"name":"dts university","duration":{"from":"2000-01-01","to":"2004-01-01"}}]');ETL 过滤函数如下所示:
(defn transform-education [] (dts/match-table "employee" (dts/map-column 'education json/parse)))说明
education字段经过 ETL 变换后,该字段将会以 JSON 数组的形式写入到 ES 的目标数据库中。- 转换 SET 为字符串
create table mytab (color set('red','blue','green','black'));ETL 过滤函数如下所示:
(defn dts/transform [] (dts/match-table "mytab" (dts/set-column (case (dts/column "color") 0b1 "red" 0b10 "blue" 0b100 "green" 0b1000 "black"))))- 转换 ENUM 为字符串
create table mytab (color enum('red','blue','green','black'));ETL 过滤函数如下所示:
(defn dts/transform [] (dts/match-table "mytab" (dts/set-column (case (dts/column "color") 1 "red" 2 "blue" 3 "green" 4 "black"))))
游戏合服
某游戏应用中各区域服都包含 User 数据,其中采用 UUID 作为业务唯一标识,以确保全局唯一,且各区域服不会存在数据交集。合服后,需舍弃自增主键,使用 user_id 作为唯一标识:
-- 源端表结构 CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(64) NOT NULL, `name` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `userid_idx` (`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 目标端表结构(和源端一致) CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(64) NOT NULL, `name` varchar(64) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `userid_idx` (`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
配置 ETL 合并函数如下所示:
(defn main [] (dts/match-table "user" ;; 丢弃自增列 (dts/drop-column "id") ;; 指定 user_id 做主键 (dts/use-index "user_id")))
示例:两个不同源端信息如下。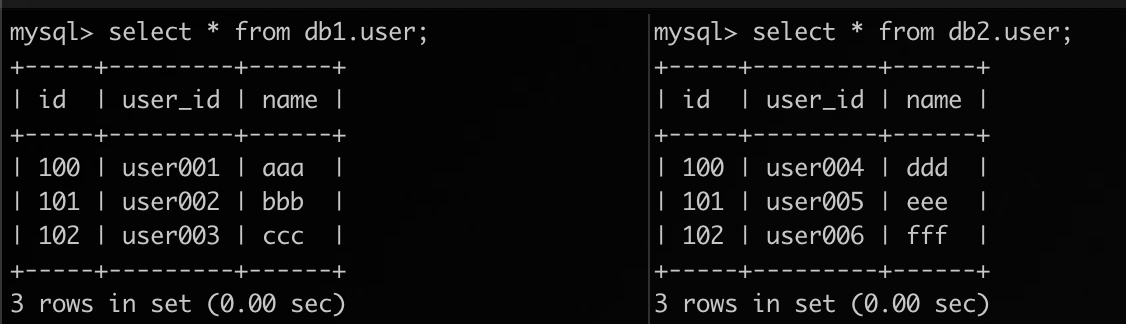
建立两个 DTS 任务,分别从两个源端获取数据合并到一个目的端表(假定目的端自增 ID 从 1 开始):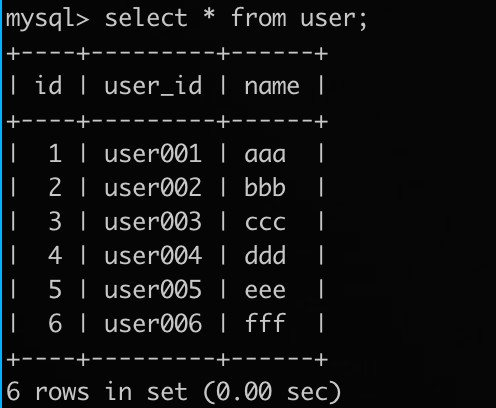
区域业务合库
该场景与游戏合服场景颇为相似但存在细微差别,例如某社交应用平台需将统计到境内和海外的点赞行为结果添加 Region 字段合并到全球汇总表中,并使用 region+user_id 作为唯一标识:
分区表 CN/US:
CREATE TABLE `user_stats` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(64) DEFAULT NULL, `star` bigint, PRIMARY KEY (`id`), UNIQUE KEY `userid_idx` (`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
汇总表:
CREATE TABLE `user_stats` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `region` varchar(32), `user_id` varchar(64) DEFAULT NULL, `star` bigint, PRIMARY KEY (`id`), UNIQUE KEY `region_userid_idx` (`region`,`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
配置 ETL 合并函数:
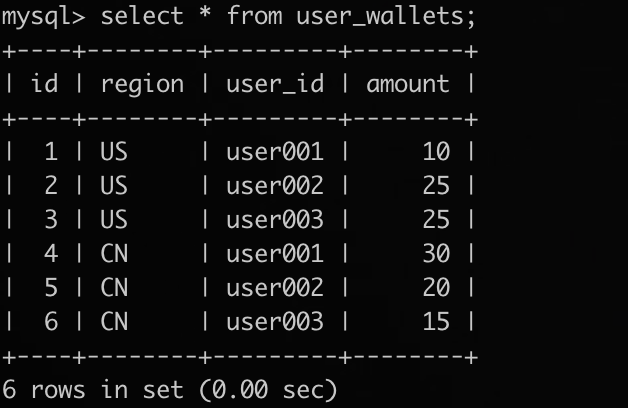
// 例如这是 CN 区 DTS 任务的 ETL 函数 (defn main [] (dts/match-table "user_wallets" ;; 丢弃自增列 (dts/drop-column "id") ;; 设置新列 region 值为 CN (dts/set-column "region" "CN") ;; 指定主键 region+user_id (dts/use-index "region" "user_id"))) // 比如,这是 US 区 DTS 任务的 ETL 函数 (defn main [] (dts/match-table "user_wallets" ;; 丢弃自增列 (dts/drop-column "id") ;; 设置新列 region 值为 US (dts/set-column "region" "US") ;; 指定主键 region+user_id (dts/use-index "region" "user_id")))
示例:国内和国外用户的钱包信息如下。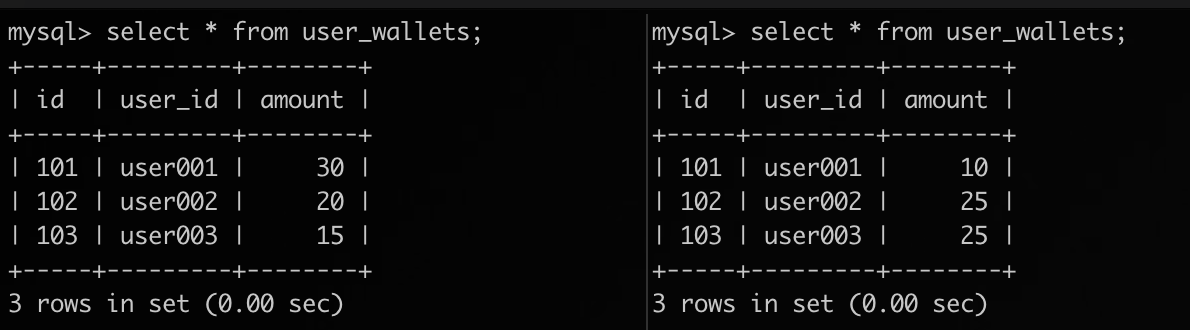
建立两个 DTS 任务,分别从两个源端获取数据合并到一个目的端表(假定目的端自增 ID 从 1 开始):