火山方舟
火山方舟






- 文档首页
 火山方舟实践教程RAG(检索增强)解决方案
火山方舟实践教程RAG(检索增强)解决方案

一、检索增强生成(Retrieval Augmented Generation,简称 RAG)是一种先进的自然语言处理技术,旨在进一步提升大语言模型的输出质量和可靠性。该技术通过整合信息检索功能,将用户查询与向量数据库进行精准匹配,从而为用户提供了更加准确和可信的答案,有效减轻了大型模型在生成回答时可能出现的“幻觉”现象。
二、以下是一些RAG常见的场景:
需要大量背景知识的任务:当生成的文本需要依赖大量的背景知识或数据时,RAG可以通过检索相关信息来辅助生成过程。
复杂查询的回答:对于需要从大量数据中提取特定信息的复杂查询,RAG可以检索最相关的文档,并生成准确的回答。
实时信息检索:在需要根据最新数据快速生成回答的场景中,RAG可以结合实时检索的信息和生成模型来提供最新的回答。
多轮对话系统:在聊天机器人或虚拟助手中,RAG可以帮助系统根据对话历史和上下文检索相关信息,并生成合适的回复。
长形式内容生成:当需要生成长篇内容,如文章、报告或故事时,RAG可以从大量数据中检索相关信息来辅助内容的生成。
事实核查和数据验证:RAG可以用于生成准确无误的信息,通过检索可靠的数据源来支持生成的内容。
个性化内容生成:在需要根据用户的历史行为或偏好生成个性化内容时,RAG可以检索用户相关的信息,以生成更符合用户需求的内容。
跨语言翻译和生成:RAG可以用于生成特定语言的文本,通过检索和利用跨语言的数据来提高翻译的准确性和自然性。
教育和培训:在自动生成教育材料或提供个性化学习建议时,RAG可以检索相关的教育资源并生成定制化的内容。
企业知识管理:在企业环境中,RAG可以帮助员工快速找到所需的信息,通过检索企业内部的知识库并生成有用的回答。
法律咨询:RAG可以用于提供法律咨询,通过检索相关的法律条文和案例来生成法律建议
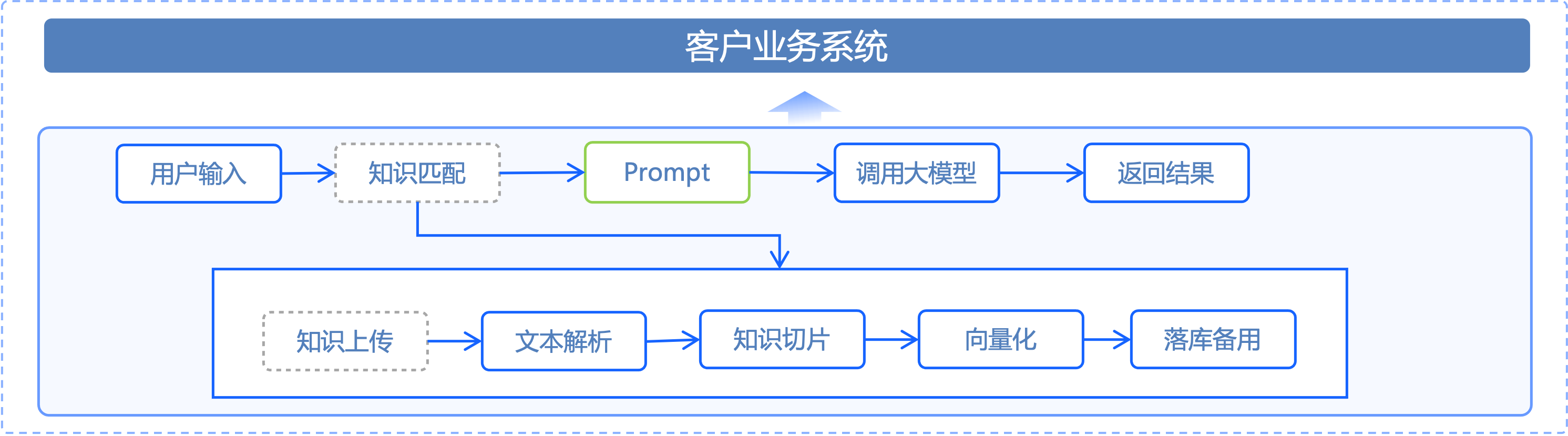
三、下图显示了RAG与LLM配合的流程图: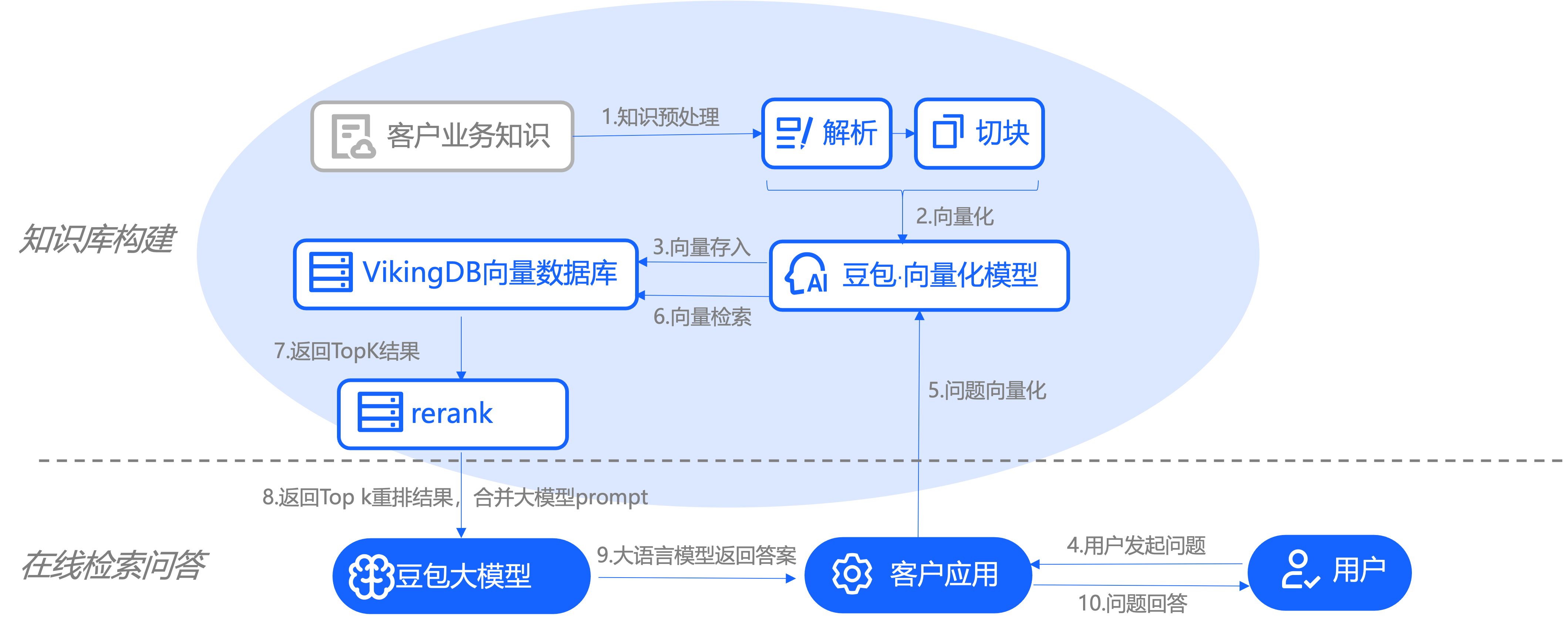
三、我们的优势:
- 提供毫秒级百亿规模的高性能检索,秒级流式知识库索引更新
- 内嵌豆包向量化模型,是由字节跳动自主研发的语义向量化模型,是LLM知识库解决方案的配套工具,支持中、英双语
- 支持向量数据实时写入、实时更新,支持实时索引、自动索引
- 存算分离架构,单数据多场景,节约计算资源,提高在线稳定性,保证高可用性
四、推荐产品:
- 向量数据库(Viking DB): https://console.volcengine.com/vikingdb
- 豆包大模型可根据实际业务场景选择:
Doubao 系列:https://console.volcengine.com/ark/region:ark+cn-beijing/model?projectName=undefined&vendor=Bytedance&view=LIST_VIEW
五、典型案例介绍:
某保险客户为提高客服人效和对话体验,将原有人工客服升级为AI客服。在项目中,多轮对话记忆、问题分散且泛的问题在传统客服功能中难以实现,对话体验不够自然真实,RAG、角色设定等能力,大大提升了客服的用户体验,帮助坐席承接了约30%的咨询问题,提效显著。