导航
录音文件识别极速版
最近更新时间:2024.03.11 12:44:26首次发布时间:2023.03.08 14:13:52
1. 流程简介
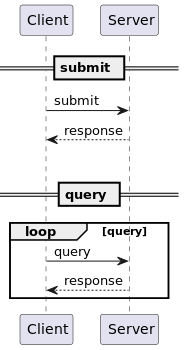
录音文件识别极速版服务的处理流程分为提交任务和查询结果两个阶段
- 任务提交:提交音频链接,并获取服务端分配的任务 ID
- 结果查询:通过任务 ID 查询转写结果
服务也支持回调通知方式。客户端在提交任务时注册回调地址,服务端转写完成后请求回调地址通知结果,不需要客户端主动查询。
2. 鉴权
设置鉴权内容,请参考鉴权方法。
3. 提交任务
3.1 域名
火山地址:https://openspeech.bytedance.com/api/v1/auc/submit
3.2 请求
请求方式:HTTP POST。
请求和应答,均采用在 HTTP BODY 里面传输 JSON 格式字串的方式。
Header 需要加入内容类型标识:
Content-Type: application/json
3.2.1 请求字段
字段 | 说明 | 层级 | 格式 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| app | 应用相关配置 Application related configuration | 1 | dict | ✓ | |
| appid | 应用标识 Application id | 2 | string | ✓ | |
| token | 应用令牌 Application token | 2 | string | ✓ | 控制访问权限。 |
| cluster | AUC服务集群 Business cluster | 2 | string | ✓ | 指定需要访问的集群。在控制台创建应用并开通录音文件识别极速版服务后,显示的 Cluster ID 字段。 |
| user | 用户相关配置 User related configuration | 1 | dict | ✓ | |
| uid | 用户标识 User id | 2 | string | ✓ | 用于区分同一appid下,不同用户的请求,建议采用 IMEI 或 MAC。 |
| audio | 音频相关配置 Audio related configuration | 1 | dict | ✓ | |
| url | 音频地址 Audio URL | 2 | string | ✓ | 需提供可下载的音频文件地址。 |
| format | 音频容器格式 Audio format | 2 | string | ✓ | raw / wav / ogg / mp3 / mp4,默认以文件名后缀作为格式。 |
| codec | 音频编码格式 Audio codec format | 2 | string | raw / opus,默认为 raw(pcm)。 | |
| rate | 音频采样率 Audio sample rate | 2 | int | 默认为 16000。 | |
| bits | 音频采样点位数 Audio bits per sample | 2 | int | 默认为 16。 | |
| channel | 音频声道数 Audio channels | 2 | int | 1(mono) / 2(stereo),默认为1。 | |
| request | 请求相关配置 Request related configuration | 1 | dict | ||
| callback | 回调地址 call back url | 2 | string | 业务方的 http 回调地址,识别结束后服务会用给 POST 方法请求回调地址,body 内容与业务方调用查询接口时服务端返回的格式相同。 | |
| boosting_table_name | 自学习平台上设置的热词词表名称 | 2 | string | 热词功能和设置方法可以参考文档 | |
| additions | 额外参数 | 1 | dict | 额外参数控制字段,dict 类型,里面的 key和value 均为 string 类型。 | |
| language | 语言 | 2 | string | 默认为中文,所有语种见 支持语种 | |
| use_itn | 数字归一化 | 2 | string | 是否开启数字归一化。"True" 表示开启, "False" 表示关闭。 默认开启。 | |
| use_punc | 标点 | 2 | string | 是否添加标点。"True" 表示开启, "False" 表示关闭。 默认开启。 | |
| use_ddc | 顺滑 | 2 | string | 是否开启顺滑。"True" 表示开启,"False" 表示关闭。目前只有中文、英文、日语支持顺滑 默认关闭 | |
| with_speaker_info | 返回说话人信息 | 2 | string | "True" 表示返回说话人信息, "False"表示不返回。 默认不返回。 | |
| enable_query | 使用回调时是否允许主动查询 | 2 | string | 如果 submit 提交任务时使用回调功能,默认不能调用 query 接口查询结果。设置这个参数允许主动查询 "True": 使用回调时允许主动查询; "False": 使用回调时不允许主动查询。默认 "False" | |
| channel_split | 多声道音频是否区分声道 | 2 | string | 如果设为"True",则会在返回结果中使用channel_id标记,1为左声道,2为右声道。默认 "False" |
3.2.2 支持语种
| 序号 | 语言 | language code |
|---|---|---|
| 1 | 中文普通话(简体) | zh-CN |
| 粤语 | cant | |
| 四川话 | sc | |
| 上海话 | zh_shanghai | |
| 2 | 英文 | en-US |
| 3 | 日语 | ja-JP |
| 4 | 韩语 | ko-KR |
| 5 | 法语 | fr-FR |
| 6 | 西班牙语 | es-MX |
| 7 | 葡萄牙语 | pt-BR |
| 8 | 印尼语 | id-ID |
请求示例:
{ "app": { "appid": "", "token": "", "cluster": "" }, "user": { "uid": "388808087185088" }, "audio": { "format": "mp3", "url": "http://xxx.com/obj/sample.mp3" }, "additions": { "use_itn": "False", "with_speaker_info": "True" }, }
3.3 应答
应答格式: JSON
应答字段:
字段 | 说明 | 层级 | 格式 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| resp | 返回内容 | 1 | dict | ✓ | |
| code | 状态码 Request Code | 2 | int | ✓ | 1000 为成功,非 1000 为失败。 |
| message | 状态信息 Request message | 2 | string | ✓ | 失败时标记失败原因。 |
| id | 任务 ID task id | 2 | string | 仅当提交成功时填写。 |
应答示例:
{ "resp": { "code": "1000", "message": "Success", "id": "fc5aa03e-6ae4-46a3-b8cf-1910a44e0d8a" } }
4. 查询结果
4.1 域名
火山地址:https://openspeech.bytedance.com/api/v1/auc/query
4.2 请求
请求方式:HTTP POST
请求和应答均采用在 HTTP BODY 里面传输 JSON 格式字串的方式
Header 需要加入内容类型标识:
Content-Type: application/json
请求示例:
{ "appid": "", "token": "", "cluster": "", "id": "fc5aa03e-6ae4-46a3-b8cf-1910a44e0d8a" }
4.3 应答
应答格式 :JSON。如果离线识别还没识别完,只会返回code和message,全部识别完后才会有识别结果的内容。
应答字段:
字段 | 说明 | 层级 | 格式 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| resp | 返回内容 | 1 | dict | ✓ | |
| id | 请求标识 task id | 2 | string | ✓ | |
| code | 请求状态号 task status code | 2 | int | ✓ | |
| message | 请求状态信息 task proceeing message | 2 | string | ✓ | |
| text | 识别结果文本 asr text | 2 | tring | ||
| utterances | 识别结果语音分句信息 utterances info | 2 | list | 分句列表。 | |
| start_time | 起始时间(毫秒) | 3 | int | 单个分句开始时间。 | |
| end_time | 结束时间(毫秒) | 3 | int | 单个分句结束时间。 | |
| words | 词粒度信息 | 3 | dict | 词列表。 | |
| start_time | 起始时间(毫秒) | 4 | int | 单个词开始时间。 | |
| end_time | 结束时间(毫秒) | 4 | int | 单个词结束时间。 | |
| additions | 额外信息 | 3 | dict | ||
| speaker | 说话人信息 | 4 | string | 说话人结果,使用数字标识。 |
应答示例:
(1)返回文本的形式:
{ "resp": { "id": "fc5aa03e-6ae4-46a3-b8cf-1910a44e0d8a", "code": 1000, "message": "Success", "text": "这是字节跳动, 今日头条母公司", "utterances": [ { "text": "这是字节跳动", "start_time": 1500, "end_time": 3000, "words": [ { "text": "这", "start_time": 1500, "end_time": 1700 }, { "text": "是", "start_time": 1700, "end_time": 2000 }, { "text": "字", "start_time": 2000, "end_time": 2200 }, { "text": "节", "start_time": 2200, "end_time": 2600 }, { "text": "跳", "start_time": 2600, "end_time": 2800 }, { "text": "动", "start_time": 2800, "end_time": 3000 } ], "additions": { "speaker": "1" } }, { "text": "今日头条母公司", "start_time": 4000, "end_time": 6150, "words": [ { "text": "今", "start_time": 4000, "end_time": 4200 }, { "text": "日", "start_time": 4200, "end_time": 4420 }, { "text": "头", "start_time": 4500, "end_time": 4800 }, { "text": "条", "start_time": 4800, "end_time": 5000 }, { "text": "母", "start_time": 5000, "end_time": 5200 }, { "text": "公", "start_time": 5400, "end_time": 5800 }, { "text": "司", "start_time": 5850, "end_time": 6150 } ], "additions": { "speaker": "2" } } ] } }
5. 错误码说明
| 错误码 | 含义 | 说明 |
|---|---|---|
| 1000 | 识别成功 | |
| 1001 | 请求参数无效 | 请求参数缺失必需字段 / 字段值无效 / 重复请求。 |
| 1002 | 无访问权限 | token 无效 / 过期 / 无权访问指定服务。 |
| 1003 | 访问超频 | 当前 appid 访问 QPS 超出设定阈值。 |
| 1004 | 访问超额 | 当前 appid 访问次数超出限制。 |
| 1005 | 服务器繁忙 | 服务过载,无法处理当前请求。 |
| 1006 | 请求中断 | 当前请求已失效 / 发生错误。 |
| 1007 - 1009 | 保留号段 | 待定。 |
| 1010 | 音频过长 | 音频数据时长超出阈值。 |
| 1011 | 音频过大 | 音频数据大小超出阈值(暂定单包不超过2M)。 |
| 1012 | 音频格式无效 | 音频 header 有误 / 无法进行音频解码。 |
| 1013 | 音频静音 | 音频未识别出任何文本结果。 |
| 1014 | 空音频 | 下载的音频为空。 |
| 1015 | 下载失败 | 音频链接下载失败。 |
| 1016-1019 | 保留号段 | 待定。 |
| 1020 | 识别等待超时 | 等待就绪超时。 |
| 1021 | 识别处理超时 | 识别处理过程超时。 |
| 1022 | 识别错误 | 识别过程中发生错误。 |
| 1023 - 1029 | 保留号段 | 待定。 |
| 1030 - 1098 | 保留号段 | 待定。 |
| 1099 | 未知错误 | 未归类错误。 |
| 2000 | 正在处理 | 任务处理中。 |
| 2001 | 排队中 | 任务在等待队里中。 |
6. 接入 demo
Demo 中需要填写 appid、access_token、access_secret、cluster 字段信息,这些信息可以从控制台创建应用开通服务获得。
#coding=utf-8 import requests import json import time import os import uuid s = requests appid = '' token = '' cluster = '' audio_url = '' service_url = 'https://openspeech.bytedance.com/api/v1/auc' headers = {'Authorization': 'Bearer; {}'.format(token)} def submit_task(): request = { "app": { "appid": appid, "token": token, "cluster": cluster }, "user": { "uid": "388808087185088_demo" }, "audio": { "format": "wav", "url": audio_url }, "additions": { 'with_speaker_info': 'False', } } r = s.post(service_url + '/submit', data=json.dumps(request), headers=headers) resp_dic = json.loads(r.text) print(resp_dic) id = resp_dic['resp']['id'] print(id) return id def query_task(task_id): query_dic = {} query_dic['appid'] = appid query_dic['token'] = token query_dic['id'] = task_id query_dic['cluster'] = cluster query_req = json.dumps(query_dic) print(query_req) r = s.post(service_url + '/query', data=query_req, headers=headers) print(r.text) resp_dic = json.loads(r.text) return resp_dic def file_recognize(): task_id = submit_task() start_time = time.time() while True: time.sleep(2) # query result resp_dic = query_task(task_id) if resp_dic['resp']['code'] == 1000: # task finished print("success") exit(0) elif resp_dic['resp']['code'] < 2000: # task failed print("failed") exit(0) now_time = time.time() if now_time - start_time > 300: # wait time exceeds 300s print('wait time exceeds 300s') exit(0) if __name__ == '__main__': file_recognize()
7. 注意事项
- 提交的音频应该小于 512MB,并且时长小于 5 小时
- 半小时内提交的总时长不能超过 500 小时,如果有更大的需求,请联系售前专家
- 转写结果在服务端保存 24 小时,超时后会查询失败