本文档介绍如何通过WebSocket协议实时访问语音识别服务 (ASR),主要包含鉴权相关、协议详情、常见问题和使用Demo四部分。
ASR 服务使用的域名是 wss://openspeech.bytedance.com/api/v2/asr。
设置鉴权内容,请参考鉴权方法。
交互流程
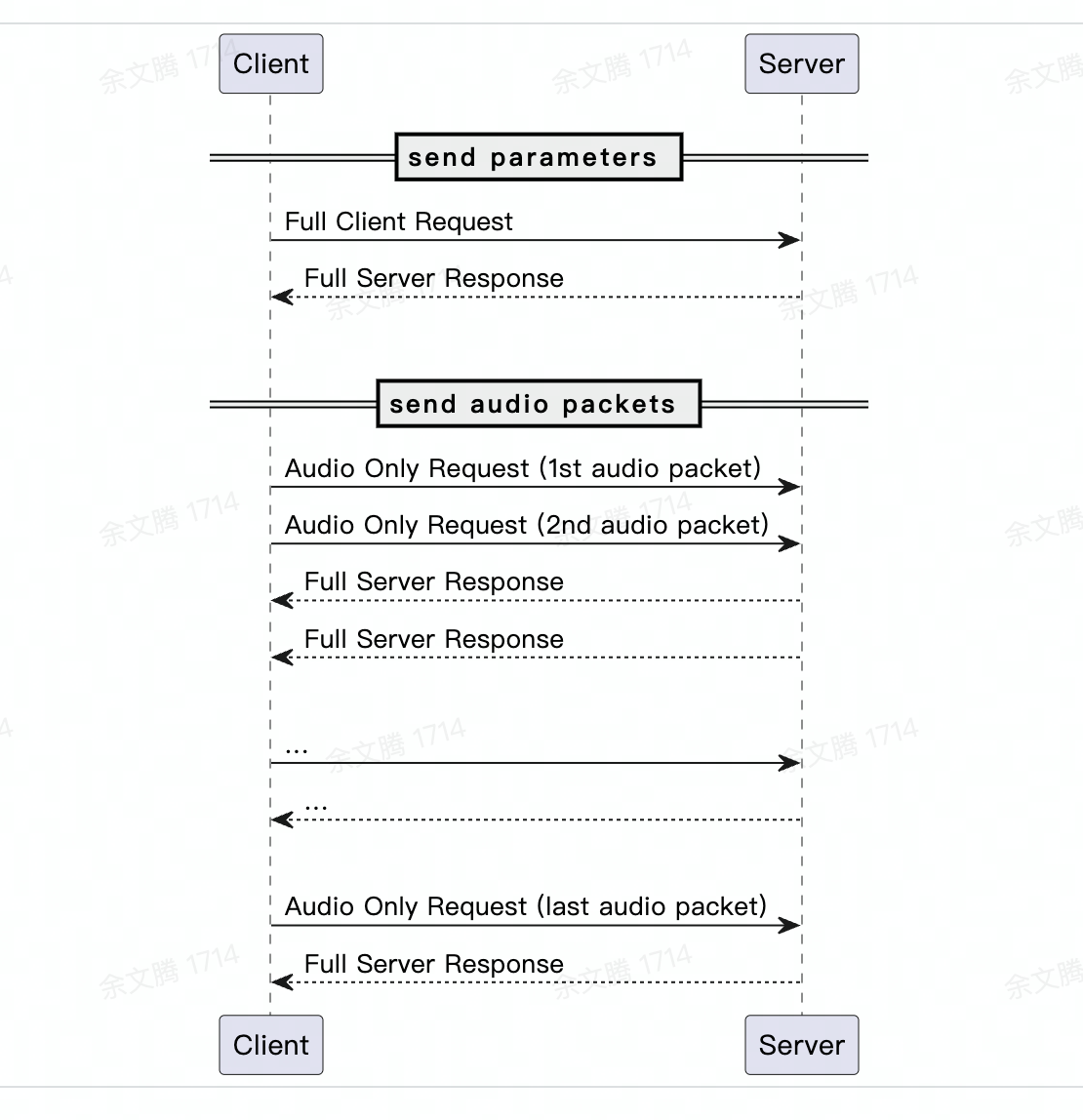
3.1. WebSocket 二进制协议
WebSocket 使用二进制协议传输数据。协议的组成由至少 4 个字节的可变 header、payload size 和 payload 三部分组成,其中 header 描述消息类型、序列化方式以及压缩格式等信息,payload size 是 payload 的长度,payload 是具体负载内容,依据消息类型不同 payload 内容不同。
需注意:协议中整数类型的字段都使用大端表示。
3.1.1. header 数据格式
| Byte \ Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | Protocol version | Header size | ||||||
| 1 | Message type | Message type specific flags | ||||||
| 2 | Message serialization method | Message compression | ||||||
| 3 | Reserved | |||||||
| 4 | [Optional header extensions] | |||||||
| 5 | [Payload, depending on the Message Type] | |||||||
| 6 | ... | |||||||
3.1.2. header 字段描述
字段 (size in bits) | 说明 | 值 |
|---|---|---|
Protocol version (4) | 将来可能会决定使用不同的协议版本,因此此字段是为了使客户端和服务器在版本上达成共识。 | 0b0001 - version 1 (目前只有该版本) |
Header (4) | Header 大小。实际 header 大小(以字节为单位)是 header size value x 4 。 | 0b0001 - header size = 4 (1 x 4) |
Message type (4) | 消息类型。 | 0b0001 - 端上发送包含请求参数的 full client request0b0010 - 端上发送包含音频数据的 audio only request 0b1001 - 服务端下发包含识别结果的 full server response 0b1111 - 服务端处理错误时下发的消息类型(如无效的消息格式,不支持的序列化方法等) |
Message type specific flags (4) | Message type 的补充信息。 | 0b0000 - full client request 或包含非最后一包音频数据的 audio only request 中设置 b0010 - 包含最后一包音频数据的 audio only request 中设置 |
Message serialization method (4) | full client request 的 payload 序列化方法; 服务器将使用与客户端相同的序列化方法。 | 0b0000 - 无序列化 0b0001 - JSON 格式 |
Message Compression (4) | 定义 payload 的压缩方法; 服务端将使用客户端的压缩方法。 | 0b0000 - no compression0b0001 - Gzip 压缩 |
Reserved (8) | 保留以供将来使用,还用作填充(使整个标头总计4个字节)。 |
3.2. 请求流程
3.2.1. 建立连接
根据 WebSocket 协议本身的机制,client 会发送 HTTP GET 请求和 server 建立连接做协议升级。
需要在其中根据身份认证协议加入鉴权签名头。设置方法请参考鉴权方法。
3.2.2. 发送 full client request
WebSocket 建立连接后,发送的第一个请求是 full client request。格式是:
| 31 ... 24 | 23 ... 16 | 15 ... 8 | 7 ... 0 |
| Header | |||
| Payload size (4B, unsigned int32) | |||
| Payload | |||
- Header:
3.1.1描述的 4 字节头。 - Payload size: 是按 Header 中指定压缩方式压缩 payload 后的长度,使用大端表示。
- Payload: 包含音频的元数据以及 server 所需的相关参数,一般是 JSON 格式。具体的参数字段见下表:
字段 | 说明 | 层级 | 格式 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| app | 应用相关配置 | 1 | dict | ✓ | |
| appid | 应用标识 | 2 | string | ✓ | |
| token | 应用令牌 | 2 | string | ✓ | 控制访问权限。 |
| cluster | 业务集群 | 2 | string | ✓ | 根据场景,选择需要访问的集群。在控制台创建应用并开通流式语音识别服务后,显示的 Cluster ID 字段。 |
| user | 用户相关配置 | 1 | dict | ✓ | |
| uid | 用户标识 | 2 | string | ✓ | 建议采用 IMEI 或 MAC。 |
| device | 设备名称 | 2 | string | ||
| platform | 操作系统及API版本号 | 2 | string | iOS/Android/Linux|version,通过“|”分隔。 | |
| network | 用户网络 | 2 | string | 2G / 3G / 4G / WiFi 。 | |
| nation | 国家 | 2 | string | ||
| province | 省份 | 2 | string | ||
| city | 城市 | 2 | string | ||
| audio | 音频相关配置 | 1 | dict | ✓ | |
| format | 音频容器格式 | 2 | string | ✓ | raw / wav / mp3 / ogg |
| codec | 音频编码格式 | 2 | string | raw / opus,默认为 raw(pcm) 。 | |
| rate | 音频采样率 | 2 | int | 默认为 16000。 | |
| bits | 音频采样点位数 | 2 | int | 默认为 16。 | |
| channel | 音频声道数 | 2 | int | 1(mono) / 2(stereo),默认为1。 | |
| request | 请求相关配置 | 1 | dict | ✓ | |
| reqid | 请求标识 | 2 | string | ✓ | 每个请求唯一标识,建议使用 UUID。 |
| sequence | 请求序号 | 2 | int | ✓ | 对于同一个请求的多个包序号,从 1 递增,最后一包取相反数。如 1,2,3 -4。 |
| nbest | 识别结果候选数目 | 2 | int | 默认为 1。 | |
| confidence | 识别结果置信度下限 | 2 | int | 默认为 0,保留字段。 | |
| workflow | 自定义工作流 | 2 | string | 默认值:audio_in,resample,partition,vad,fe,decode。 | |
| show_utterances | 输出语音停顿、分句、分词信息 | 2 | bool | ||
| result_type | 返回结果类型 | 2 | string | 默认每次返回所有分句结果。 如果想每次只返回当前分句结果,则设置 show_utterances=true 和 result_type=single;如果当前分句结果是中间结果则返回的 definite=false,如果是分句最终结果则返回的 definite=true 。 | |
| boosting_table_name | 自学习平台上设置的热词词表名称 | 2 | string | 热词功能和设置方法可以参考文档 | |
| correct_table_name | 自学习平台上设置的替换词词表名称 | 2 | string | 替换词功能和设置方法可以参考文档 |
参数示例:
{ "app": { "appid": "", "token": "", "cluster": "" }, "user": { "uid": "388808088185088" }, "audio": { "format": "wav", "rate": 16000, "bits": 16, "channel": 1, "language": "zh-CN" }, "request": { "reqid": "a3273f8ee3db11e7bf2ff3223ff33638", "workflow": "audio_in,resample,partition,vad,fe,decode", "sequence": 1, "nbest": 1, "show_utterances": true } }
3.2.3. 发送 audio only request
Client 发送 full client request 后,再发送包含音频数据的 audio-only client request。音频应采用 full client request 中指定的格式(音频格式、编解码器、采样率、声道)。格式如下:
| 31 ... 24 | 23 ... 16 | 15 ... 8 | 7 ... 0 |
| Header | |||
| Payload size (4B, unsigned int32) | |||
| Payload | |||
Payload 是使用指定压缩方法,压缩音频数据后的内容。可以多次发送 audio only request 请求,例如在流式语音识别中如果每次发送 100ms 的音频数据,那么 audio only request 中的 Payload 就是 100ms 的音频数据。
3.2.4 full server response
Client 发送的 full client request 和 audio only request,服务端都会返回 full server response。格式如下:
| 31 ... 24 | 23 ... 16 | 15 ... 8 | 7 ... 0 |
| Header | |||
| Payload size (4B, unsigned int32) | |||
| Payload | |||
Payload 内容是包含识别结果的 JSON 格式,字段说明如下:
字段 | 说明 | 层级 | 格式 | 是否必填 | 备注 |
|---|---|---|---|---|---|
| reqid | 请求标识 | 1 | string | ✓ | 请求中的 reqid。 |
| code | 请求状态号 | 1 | int | ✓ | 详情请参考错误码 。 |
| message | 请求状态信息 | 1 | string | ✓ | |
| sequence | 对应请求包序号 | 1 | int | 对于同一个请求的多个包序号,从 1 递增,最后一包取相反数,例如第五包为最后一包,则该包 sequence 为 -5。 | |
| result | 识别结果 | 1 | list | 仅当识别成功时填写 | |
| text | 整个音频的识别结果文本 | 2 | string | 仅当识别成功时填写。 | |
| confidence | 识别结果文本置信度 | 2 | int | 仅当识别成功时填写。 | |
| utterances | 识别结果语音分句信息 | 2 | list | 仅当识别成功且开启show_utterances时填写。 | |
| text | utterance级的文本内容 | 3 | string | 仅当识别成功且开启show_utterances时填写。 | |
| start_time | 起始时间(毫秒) | 3 | int | 仅当识别成功且开启show_utterances时填写。 | |
| end_time | 结束时间(毫秒) | 3 | int | 仅当识别成功且开启show_utterances时填写。 |
{ "reqid": "0ce870af-c0f0-4208-aae7-bd7cdf063567", "code": 1000, "message": "Success", "sequence": -1, "result": [ { "text": "这是字节跳动, 今日头条母公司。", "utterances": [ { "definite": true, "end_time": 1705, "start_time": 0, "text": "这是字节跳动,", "words": [ { "blank_duration": 0, "end_time": 860, "start_time": 740, "text": "这" }, { "blank_duration": 0, "end_time": 1020, "start_time": 860, "text": "是" }, { "blank_duration": 0, "end_time": 1200, "start_time": 1020, "text": "字" }, { "blank_duration": 0, "end_time": 1400, "start_time": 1200, "text": "节" }, { "blank_duration": 0, "end_time": 1560, "start_time": 1400, "text": "跳" }, { "blank_duration": 0, "end_time": 1640, "start_time": 1560, "text": "动" } ] }, { "definite": true, "end_time": 3696, "start_time": 2110, "text": "今日头条母公司。", "words": [ { "blank_duration": 0, "end_time": 3070, "start_time": 2910, "text": "今" }, { "blank_duration": 0, "end_time": 3230, "start_time": 3070, "text": "日" }, { "blank_duration": 0, "end_time": 3390, "start_time": 3230, "text": "头" }, { "blank_duration": 0, "end_time": 3550, "start_time": 3390, "text": "条" }, { "blank_duration": 0, "end_time": 3670, "start_time": 3550, "text": "母" }, { "blank_duration": 0, "end_time": 3696, "start_time": 3670, "text": "公" }, { "blank_duration": 0, "end_time": 3696, "start_time": 3696, "text": "司" } ] } ] } ], "addition": { "duration": "3696", "logid": "20230606120441ECA45EBB4E6A6B036C55" } }
3.2.5. Error message from server
当 server 发现无法解决的二进制/传输协议问题时,将发送 Error message from server 消息(例如,client 以 server 不支持的序列化格式发送消息)。格式如下:
| 31 ... 24 | 23 ... 16 | 15 ... 8 | 7 ... 0 |
| Header | |||
| Error message code (4B, unsigned int32) | |||
| Error message size (4B, unsigned int32) | |||
| Error message (UTF8 string) | |||
- Header:
3.1.1描述的 4 字节头。 - Error message code: 错误码,使用大端表示。
- Error message size: 错误信息长度,使用大端表示。
- Error message: 错误信息。
3.2.6. 示例
3.2.6.1. 示例:客户发送 3 个请求
下面的 message flow 会发送多次消息,每个消息都带有版本、header 大小、保留数据。由于每次消息中这些字段值相同,所以有些消息中这些字段省略了。
Message flow:
client 发送 "Full client request"
- version:
b0001(4 bits) - header size:
b0001(4 bits) - message type:
b0001(Full client request) (4bits) - message type specific flags:
b0000(none) (4bits) - message serialization method:
b0001(JSON) (4 bits) - message compression:
b0001(Gzip) (4bits) - reserved data:
0x00(1 byte) - payload size = Gzip 压缩后的长度
- payload: json 格式的请求字段经过 Gzip 压缩后的数据
- version:
server 响应 "Full server response"
- version:
b0001 - header size:
b0001 - message type:
b1001(Full server response) - message type specific flags:
b0000(none) - message serialization method:
b0001(JSON 和请求相同) - message compression:
b0001(Gzip 和请求相同) - reserved data:
0x00 - payload size = Gzip 压缩后数据的长度
- payload: Gzip 压缩后的响应数据
- version:
client 发送包含第一包音频数据的 "Audio only client request"
- version:
b0001 - header size:
b0001 - message type:
b0010(audio only client request) - message type specific flags:
b0000(payload 不设置 sequence number) - message serialization method:
b0000(none - raw bytes) - message compression:
b0001(Gzip) - reserved data:
0x00 - payload size = Gzip 压缩后的音频长度
- payload: 音频数据经过 Gzip 压缩后的数据
- version:
server 响应 "Full server response"
- message type:
0b1001- Full server response - message specific flags:
0b0000(none) - message serialization:
0b0001(JSON, 和请求相同) - message compression
0b0001(Gzip, 和请求相同) - reserved data:
0x00 - payload size = Gzip 压缩后数据的长度
- payload: Gzip 压缩后的响应数据
- message type:
client 发送包含最后一包音频数据(通过 message type specific flags) 的 "Audio-only client request",
- message type:
b0010(audio only client request) - message type specific flags:
b0010(最后一包音频) - message serialization method:
b0000(none - raw bytes) - message compression:
b0001(Gzip) - reserved data:
0x00 - payload size = Gzip 压缩后的音频长度
- payload: Gzip 压缩后的音频数据
- message type:
server 响应 "Full server response" - 最终回应及处理结果
- message type:
b1001(Full server response) - message type specific flags:
b0000(none) - message serialization method:
b0001(JSON) - message compression:
b0001(Gzip) - reserved data:
0x00 - payload size = Gzip 压缩后的 JSON 长度
- payload: Gzip 压缩后的 JSON 数据
- message type:
3.3. 错误码
| 错误码 | 含义 | 说明 |
|---|---|---|
| 1000 | 成功 | |
| 1001 | 请求参数无效 | 请求参数缺失必需字段 / 字段值无效 / 重复请求。 |
| 1002 | 无访问权限 | token 无效 / 过期 / 无权访问指定服务。 |
| 1003 | 访问超频 | 当前 appid 访问 QPS 超出设定阈值。 |
| 1004 | 访问超额 | 当前 appid 访问次数超出限制。 |
| 1005 | 服务器繁忙 | 服务过载,无法处理当前请求。 |
| 1008 - 1009 | 保留号段 | 待定。 |
| 1010 | 音频过长 | 音频数据时长超出阈值。 |
| 1011 | 音频过大 | 音频数据大小超出阈值。 |
| 1012 | 音频格式无效 | 音频 header 有误 / 无法进行音频解码。 |
| 1013 | 音频静音 | 音频未识别出任何文本结果。 |
| 1014 - 1019 | 保留号段 | 待定。 |
| 1020 | 识别等待超时 | 等待下一包就绪超时。 |
| 1021 | 识别处理超时 | 识别处理过程超时。 |
| 1022 | 识别错误 | 识别过程中发生错误。 |
| 1023 - 1039 | 保留号段 | 待定。 |
| 1099 | 未知错误 | 未归类错误。 |
1. 如何返回全部分句或单个分句的结果
默认每次返回所有分句结果。
如果想每次只返回当前分句结果,则设置 show_utterances=true 和 result_type=single;
如果当前分句结果是中间结果,则返回 utterances 中的 definite=false;
如果是分句最终结果,则返回 utterances 中的definite=true。
2. 如何开启 ITN、顺滑、标点
可通过workflow 参数,控制是否开启 ITN,标点或顺滑。workflow 默认值是 audio_in,resample,partition,vad,fe,decode,只进行识别;
如果要开启 ITN 在 workflow 中增加 "itn", audio_in,resample,partition,vad,fe,decode,itn;
如果要开启顺滑在 workflow 中增加 "nlu_ddc",audio_in,resample,partition,vad,fe,decode,nlu_ddc;
如果要开启标点在 workflow 中增加 "nlu_punctuate", audio_in,resample,partition,vad,fe,decode,nlu_punctuate;
同时开启 itn, 顺滑和标点的 workflow 是 audio_in,resample,partition,vad,fe,decode,itn,nlu_ddc,nlu_punctuate。
Demo 中需要填写 appid、access_token、access_secret、cluster 字段信息,这些信息可以从控制台创建应用开通服务获得。
Python


C++
JAVA
Go