流式计算 Flink版
流式计算 Flink版






- 文档首页
 流式计算 Flink版问题排查Task 反压
流式计算 Flink版问题排查Task 反压

本文为您介绍 Flink 出现 Task 反压的常见原因和处理建议。
背景信息
您在查看本文内容前,建议先查看背景信息中的内容。
什么是反压?
首先通过经典的“生产者-消费者模型”来理解反压。
在该模型中,有生产者、消费者,以及一个固定大小的队列,生产者负责生产数据并写入到队列中,消费者从队列中获取数据。当消费者的消费能力小于生产者的生产能力时,队列中的数据就会开始堆积,直至堆积满,此时生产者将被阻塞且无法继续生产数据。生产者还可能是其他队列的消费者,堆积现象还会继续往上层传递,直到源头,这就是反压现象。
Flink Job 部署在不同 TaskManager 时,从 TaskA 流转到 TaskB 的过程也有可能出现反压现象。
Flink内部通信模型
场景模拟:一个 Flink Job 包含 TaskA 和 TaskB,且并发度为 4,即 TaskA.1~4 和 TaskB.1~4。将这个 Flink Job 部署到 2 个 taskmanager 中,每个 taskmanager 分配 2 个 slots。由于 Flink 支持不同类型的 Task 可以放到同⼀个 slot 中,则整个分配方式如下:
B.1 | B.2 | B.3 | B.4 | |
|---|---|---|---|---|
A.1 | local | remote | ||
A.2 | ||||
A.3 | remote | local | ||
A.4 | ||||
TaskManager1 分配 A1、A2、B1、B2;TaskManager2 分配 A3、A4、B3、B4。位于相同 Taskmanager 内部的 Task 靠local传输,位于不同的 TaskManager 之间的 Task 靠remote传输。
TaskManager内部数据流转流程
两个 TaskManager 之间的 TCP Channel 是共享的,例如 A1 -> B3/B4 和 A2-> B3/B4 使用的是同一个 TCP Channel。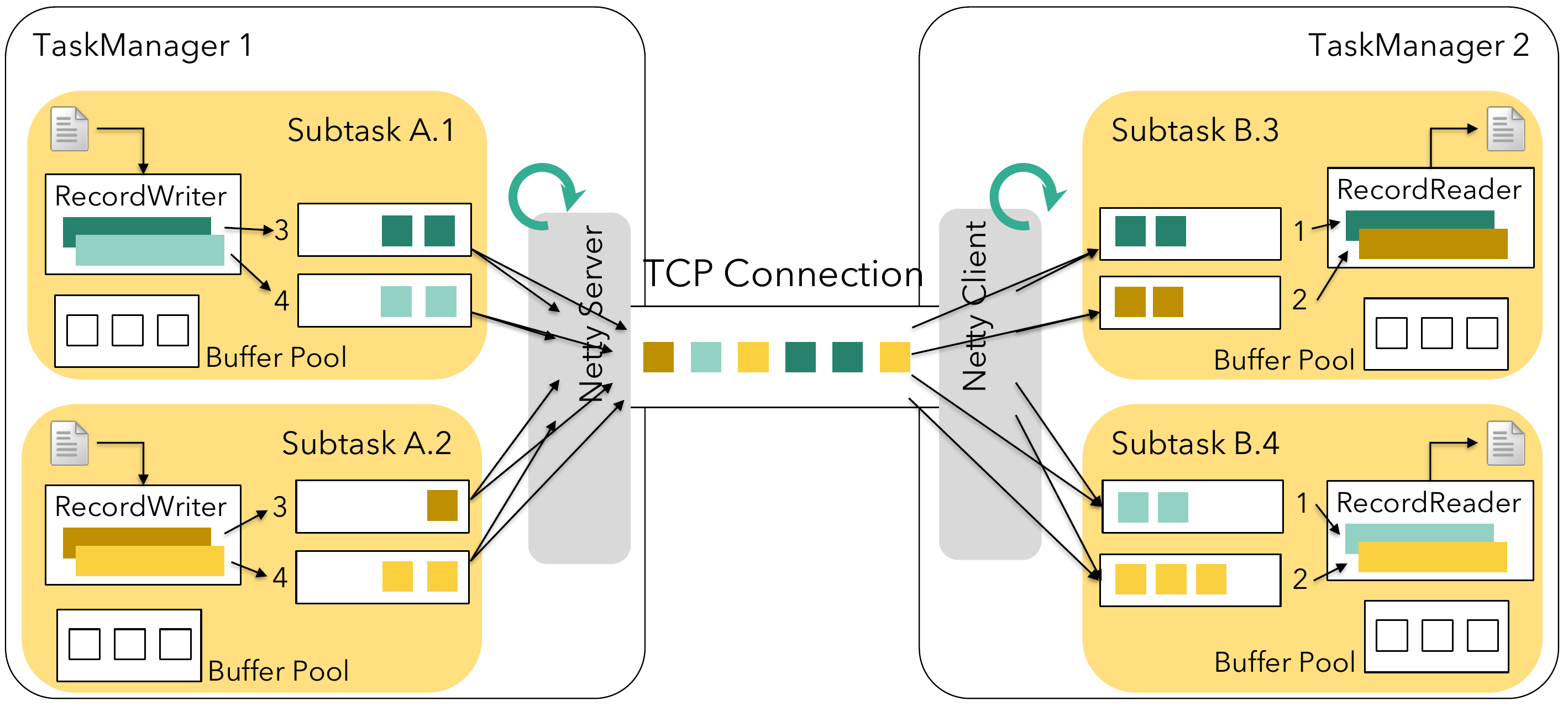
从上图中可以得出,生产者 TaskA 将数据发送到 TaskB,需要经历 2 个步骤:
- TaskA 将产生的数据通过 RecordWriter 序列化写到一个 Output Queue Buffer 中。Output Queue Buffer 是有固定长度的,当写满后,将阻塞写。
- 经过底层网络传输,将 TaskManager1 中的 Output Queue Buffer 中的数据传递到 TaskManagger2 中的 Input Queue Buffer 中,然后再由 RecordReader 从 Input Queue Buffer 读取数据进行反序列化,再由 TaskB 处理。Input Queue Buffer 也是有固定长度的,当写满后,无法继续接收从底层网络传输过来的数据。
Flink 反压机制
假设 Subtask B.4 处理能力下降,低于 Subtask A.2 写入的 QPS 时,将出现以下现象:
- 首先 Subtask B.4 的 Input Queue Buffer 将会写满,然后向上传递反压,网络传输通道也发生堵塞。
- 继续向上传递反压,Subtask A.2 的 Output Queue Buffer 也被写满,然后继续反压到 Subtask A.2 的数据处理 QPS。
- 继续向上传递反压,直至数据源。如果是 KafkaSource,则不能继续消费 Kafka 的数据,从而产生 Lagsize。
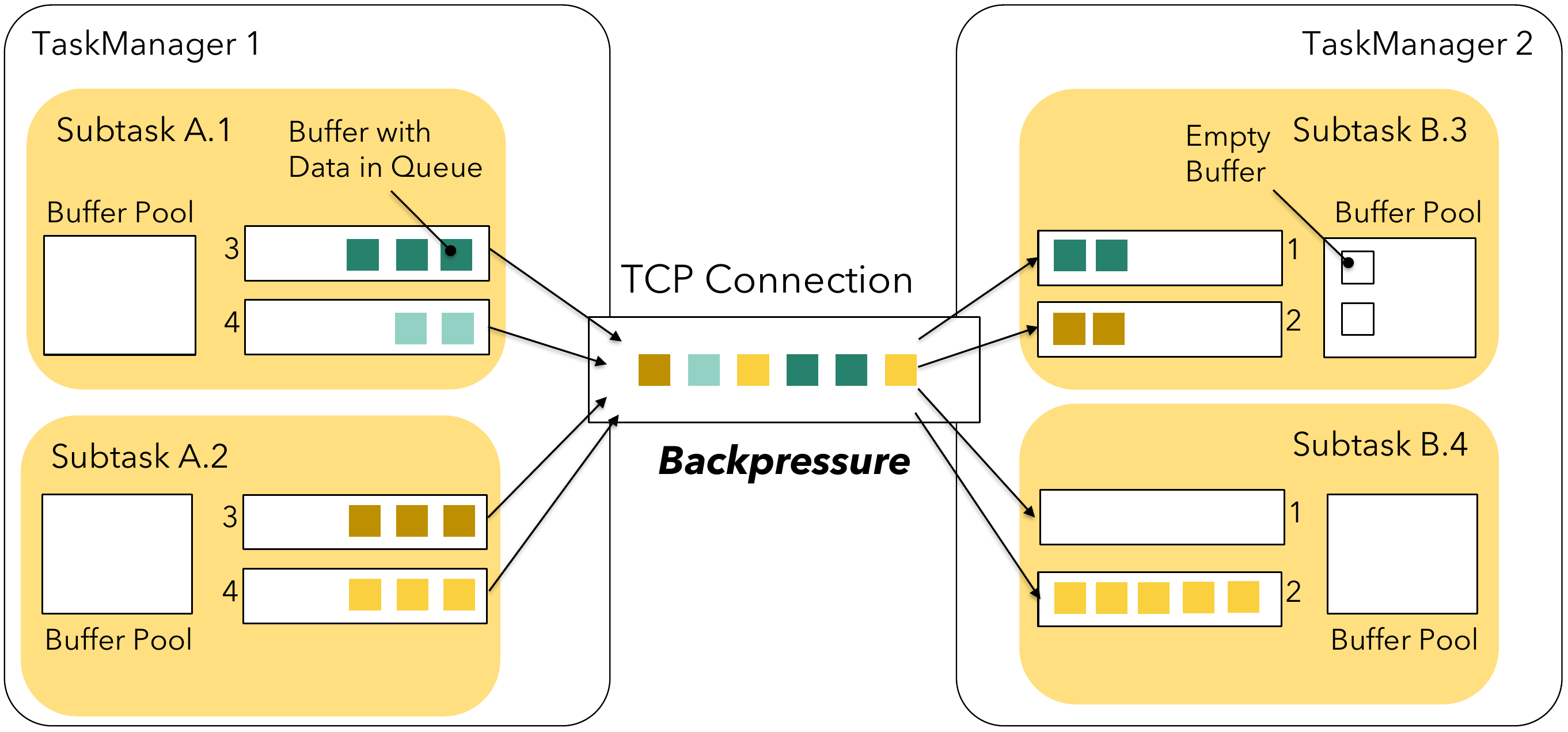
这种反压机制有一个缺点,就是当产生数据倾斜时,Subtask A.2 往 Subtask B.4 产生数据量较大时,由于反压,会影响到 Subtask A.1 的生产能力。如果您想深入了解 Flink 反压机制,请参见Flink's Network Stack。
常见反压原因
介绍出现反压的常见原因。
原因一:资源不足
Container CPU 不足,导致计算能力不足,出现反压。
您可以观察 Container CPU 和 Application CPU 的使用情况。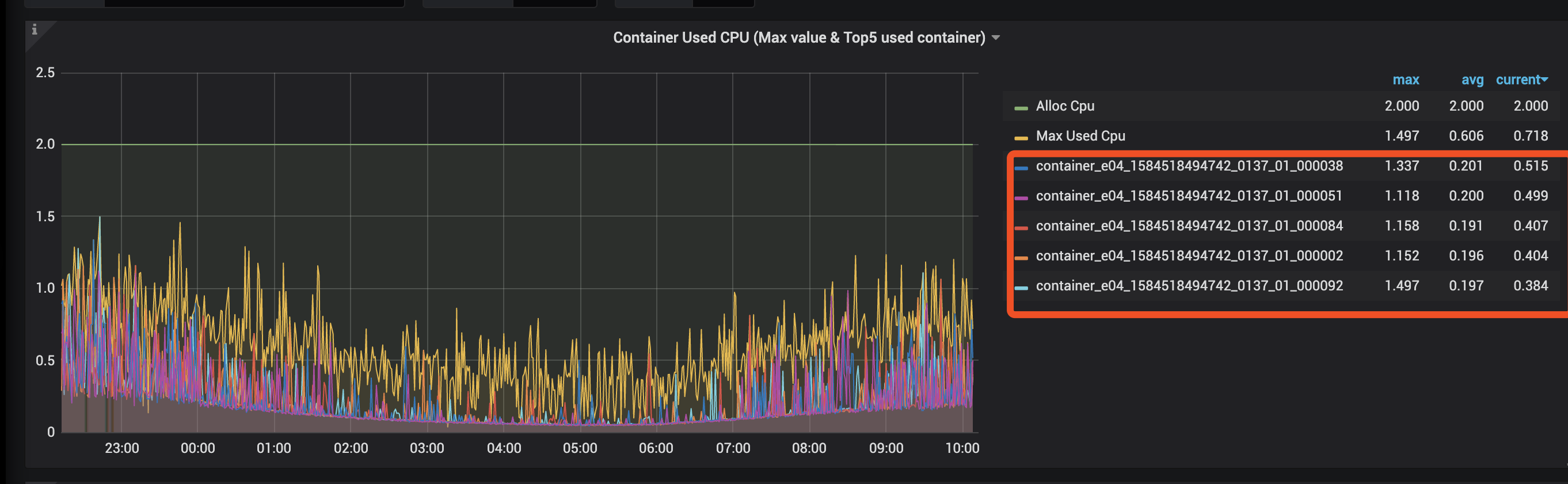
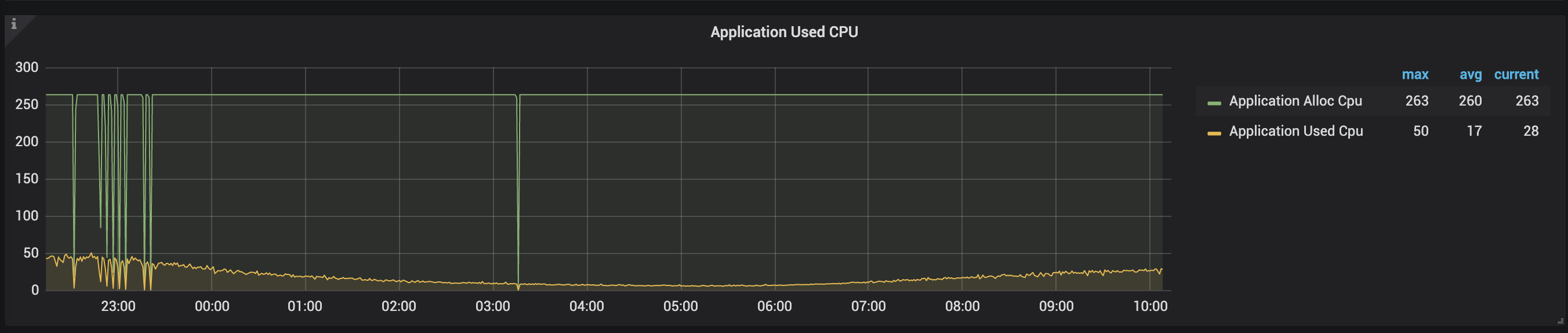
由于 cgroup 策略给单个 Container 预留了 20% 的 Buffer,所以可以按照 100% 来区分高负载和低负载。
是否资源不足 | Container CPU < 100% * tm_cores | Container CPU > 100% * tm_cores |
|---|---|---|
Application CPU < 80% * total_cores | 否 | 负载不均 |
Application CPU > 80% * total_cores | NA(不会出现) | 是 |
当资源不足时,可以选择缩小单 tm_slots,增加 tm_num 个数。 如果出现负载不均,请参照负载不均的排查思路。
原因二:负载不均
当出现负载不均时,需要分析两个原因:
- 是否数据倾斜;
- 是否 Task 调度不均衡。
判断是否数据倾斜
可以查看 Flink Metric 中的各个 Operater QPS 的 Max 和 AVG 值。如果两值差别很大,则代表数据倾斜。
如下图所示,该 Bolt QPS 的 max 和 avg 差距约 9 倍,则说明产生了数据倾斜。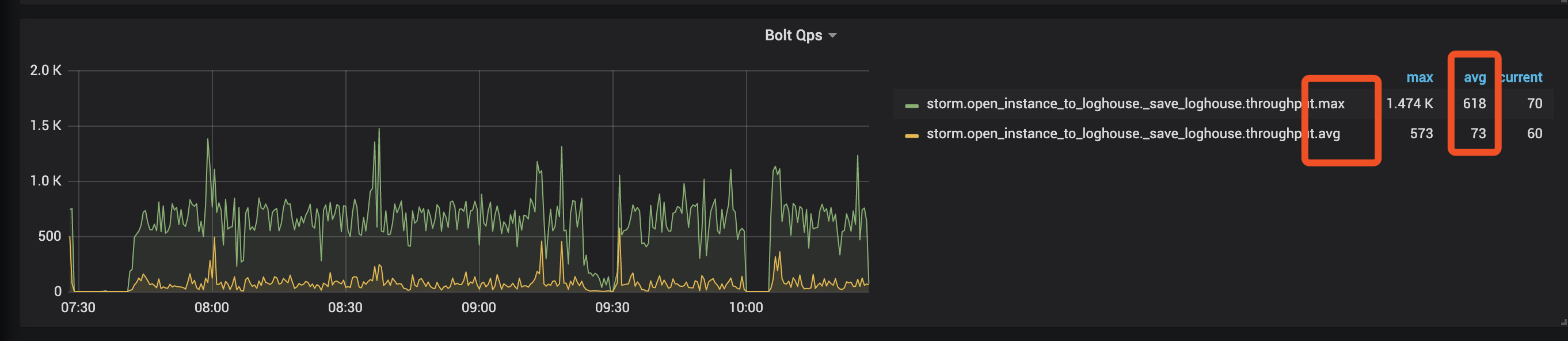
Task是否调度不均衡
如果 Task 并发度与 Container 并发度不能成正比,则代表不同 Container 分配的 Task 个数不同。
- GC压力
在 Flink Dashboard 上,默认有 YGC、FGC 两个指标,请根据需要查看相关指标。一般只需要关注 FULL GC 指标。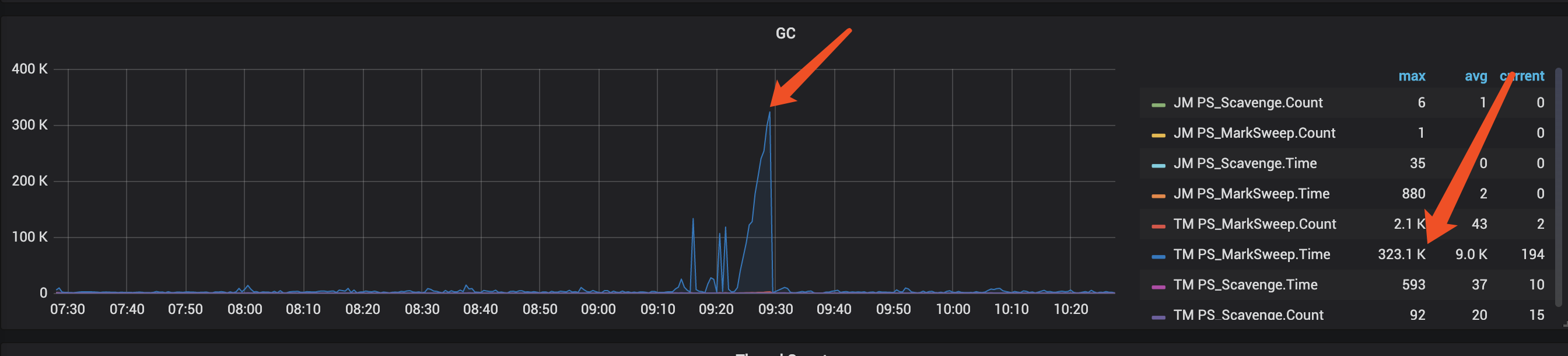
- Task Latency较高
出现某些 Task 执行时间较长,如果 Task 之间有 IO 操作,需要检查 IO Latency 是否过于高。您可以在 Flink Dashboard 查看 Latency,记录了每个 Task 的执行时间。
如下图所示, map latency 是 10s。遇到这种情况,可以优化 task 处理能力,也可以增加并发。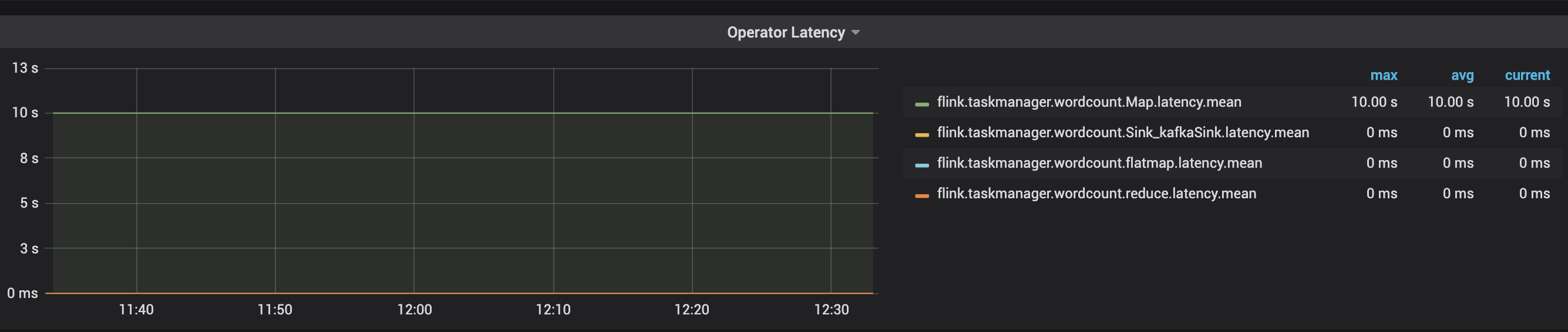
- 系统资源
遇到单机整体负载较高(常见于 Bigbang 队列和共享 Share 队列),该情况一般会产生局部 Partition 延迟。
遇到单机网络异常,一般会导致 Network Stack 变慢,导致延迟。
此类问题,自主排查难度大,请提交 Oncall 。 - 单线程瓶颈
Flink Java/SQL 任务一般情况下单 Task 是由单线程执行,单线程跑满也只能跑 1 个 CPU。
您可以观察单 Container 分配 Task 个数,以及该 Container CPU 使用情况,如果 Container CPU 使用情况达到该 Container 分配 Task 个数的 Cores,则会出现单线程瓶颈。
出现单线程瓶颈时,您可以增加并发数。
Flink监控反压
如何判断是否是由于反压导致任务产生 Lagsize?您可以在 Flink WebUI 上手动触发反压机制,查看反压状态;也可以查看 Flink Job 中间的 Task 的 InputQueueUsage 和 OutputQueueUsage 比例来判断。
此处假设 Job 分为两个 Task,使用 key 相连接,为了模拟反压效果,可以在 Map Operator 加上 Sleep 10s 逻辑。
GAG 图如下所示:
Flink WebUI
您可以在 Flink Web 中,针对任何一个 Task 做反压检测。反压检测需要在手动触发,触发后 TaskManager 使用 Thread.getStackTrace 来抽样检测 Task Thread 是否处于等待 NetworkBuffer 中。
根据抽样比例,来判断反压状态,反压状态分为 OK、LOW 和 HIGH 三种状态。Ratio 表示抽样 n 次,处于等待 NetworkBuffer 次数的比例。
- OK:
ratio ≤ 0.10 - LOW:
0.10 < Ratio ≤ 0.5 - HIGH:
0.5 < Ratio ≤ 1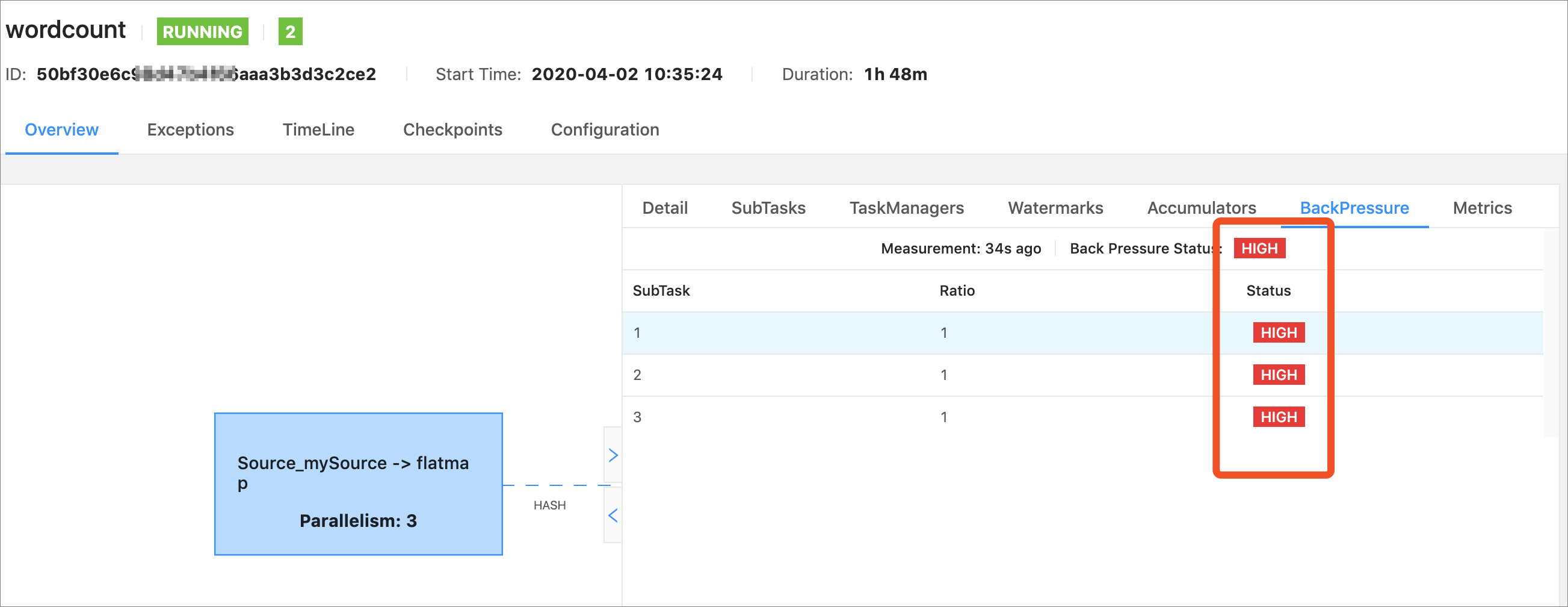
您可以从 Sink -> Source 逆序依次进行检查,遇到的第一个处于 HIGH 状态的 Task 可能就是触发反压的根本原因(并不绝对),由于该 Task 处于反压状态,它会将该状态一直向上传递,直到 Source。 这种检测方式,本身存在一些缺点:
- 即时触发,不能观察历史情况。
- 并发较多的 Task,需要很长的检测时间。
- 影响任务正常运行状态。
- 无法准确判断反压根源。
Flink Network Metric
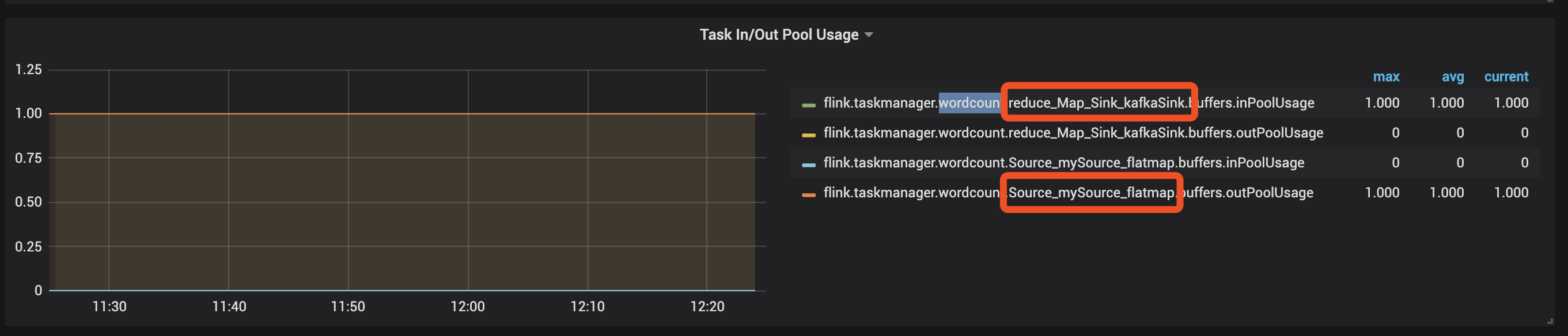
每一个 Flink Job 中间的 Task 都会有一个 InputQueue 和 OutputQueue,您可以通过查看 InputQueueUsage 和 OutputQueueUsage 的比例来判断。
比例情况 | OutputQueueUsage < 1.0 | OutputQueueUsage == 1.0 |
|---|---|---|
InputQueueUsage < 1.0 | 正常 | 处于反压,原因可能是该 Task 下游处理能力不足。如果持续下去,该 Task 将会向上游传递反压。 |
InputQueueUsage == 1.0 | 处于反压,该 Task 可能是反压的源头。如果持续下去,该 Task 会向上游传递反压。 | 处于反压,原因可能是被下游阻塞。 |
当任务处于反压下,您可以从 Sink -> Source 逆序逐步检查,直到找到第一个 InputQueueUsage High,OutputQueueUsage Low 的 Task。