流式计算 Flink 版已经接入云监控服务,您可以在云监控平台配置告警策略,以及时识别资源异常状态并发送告警通知,提升运维效率。本文为您介绍在云监控平台如何配置告警策略,以及流式计算 Flink 版支持配置告警的 Metric 详情。
Metric介绍
下表为您介绍流式计算 Flink 版支持配置告警的监控指标。
维度 | 指标名 | 支持的聚合维度 | 指标含义及计算方式 | 对应开源 Flink 指标(Scope:MetricName) | 使用说明 |
|---|---|---|---|---|---|
作业运行状态 | 作业 failed 或者是 recover 的时间长度 | 最大值 | 已废弃, Failover 时作业从故障到 Running 的时间 | job:downtime | 仅支持 1.11,不推荐使用 |
过去 30s 作业 Failover 次数 | 最大值、最小值、平均值 | 过去 30s 作业 Failover 的次数 | job:fullRestarts | 不推荐使用,由于 Flink Failover 间隔比较长,建议使用后续过去 5/10/15 分钟的 Failover 次数指标 | |
作业失败状态(值为 1 表示失败) | 最大值 | 作业以失败状态结束 | 无 | 此报警只通知一次,并且不支持报警恢复功能 | |
作业 Failover QPS | 最大值 | 作业发生 Failover 的 QPS | job:fullRestarts | 不推荐使用,由于 Flink Failover 间隔比较长,QPS 计算不够直观,建议使用后续过去 5/10/15 分钟的 Failover 次数指标 | |
作业成功结束状态(值为 1 表示成功结束) | 最大值 | 作业以成功状态结束 | 无 | 此报警只通知一次,并且不支持报警恢复功能 | |
作业失败退出后被自动拉起次数 | 最大值 | 作业失败后被自动拉起的次数 | 无 | 仅当开启任务失败重试拉起配置后生效 | |
业务延迟 | 最大值 | Source 处理数据的时间减去数据写入上游存储的时间,当前只支持新的 KafkaSource | operator:currentEmitEventTimeLag | 仅支持 1.16 版本且使用新的 KafkaSource | |
过去 5 分钟内作业 Failover 次数 | 总和 | 过去 5 分钟作业 Failover 次数 | job:fullRestarts | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
过去 10 分钟内作业 Failover 次数 | 总和 | 过去 10 分钟作业 Failover 次数 | job:fullRestarts | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
过去 15 分钟内作业 Failover 次数 | 总和 | 过去 15 分钟作业 Failover 次数 | job:fullRestarts | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
checkpoint | 最近一次 checkpoint 用时 | 最大值、最小值、平均值 | 最近一次 checkpoint 用时 | job:lastCheckpointDuration | 由于Checkpoint 时间过长会触发超时,该报警难以配置阈值,不推荐使用。建议配置合理的 checkpoint 超时时间后配合checkpoint 失败次数配置报警 |
checkPoint 连续失败次数 | 最大值、最小值、平均值 | 连续失败次数,checkpoint 成功后会清零。不计算触发 checkpoint 失败的次数(例如作业处于 Failover 中) | 无 | ||
过去 5 分钟内作业 Checkpoint 失败次数 | 总和 | 过去 5 分钟作业 Failover 次数 | job:numberOfFailedCheckpoints | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
过去 10 分钟内作业 Checkpoint 失败次数 | 总和 | 过去 10 分钟作业 Failover 次数 | job:numberOfFailedCheckpoints | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
过去 15 分钟内作业 Checkpoint 失败次数 | 总和 | 过去 15 分钟作业 Failover 次数 | job:numberOfFailedCheckpoints | 建议配置连续 3/5 个周期都大于阈值才触发报警,防止误报警 | |
Kafka | Max KafkaConsumer Records Lag V11 | 最大值、最小值、平均值 | Kafka 中积压待消费的数据条数,指标值多个 partition 求最大值,该值比较大表明消费能力不足 | 无 | 仅使用 OldKafkaSource 生效,且作业异常时该指标不打点 |
Max KafkaConsumer Records Lag V16 | 最大值、最小值、平均值 | Kafka 中积压待消费的数据条数,指标值多个 partition 求最大值,该值比较大表明消费能力不足 | 无 | 仅使用 NewKafkaSource 生效,且作业异常时该指标不打点 | |
flinkFiveMinsCounter | 过去 5 分钟内作业 Failover 次数 | 总和 | 过去 5 分钟作业 Failover 次数 | job:fullRestarts | 不推荐,该报警指标为重复指标,后续会下线。 |
前提条件
- 您在前往云监控服务侧创建告警策略前,需要先明确资源对象,请提前获取 Flink 任务的 ID。
- 在创建告警策略时,选择邮箱、电话或者短信作为通知方式时,需要提前创建告警联系人和联系组,请参见创建告警联系人和联系组。
创建告警策略
登录云监控控制台。
在左侧导航栏选择告警中心 > 告警策略,然后单击创建告警策略。
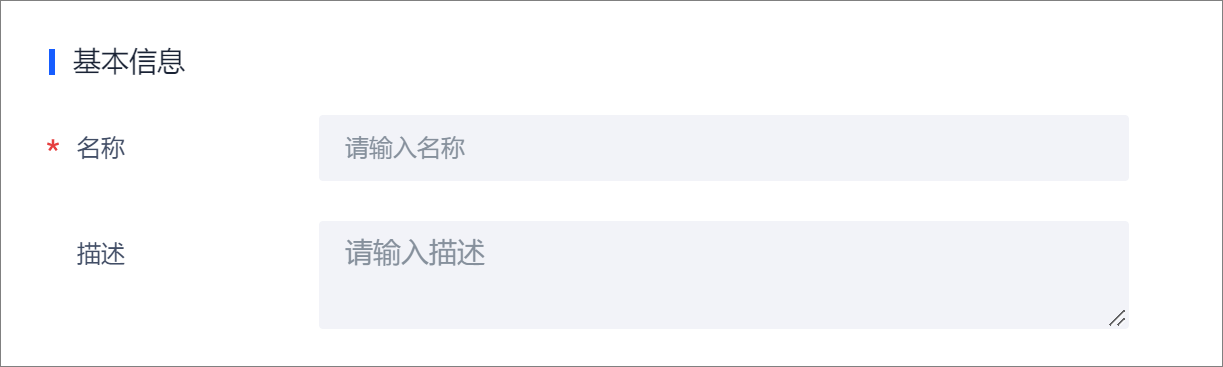
在基本信息区域,设置告警策略名称和描述。
配置
说明
名词
自定义告警策略名称,用于标识告警策略。
要求长度范围在1~128字符,且不得以数字、短横线(-)开头。描述
告警策略的描述。
在告警对象区域,选择资源类型为数据中台 > 流式计算 Flink 版,然后根据实际情况选择地域、维度和资源。
配置
说明
资源类型
选择数据中台 > 流式计算 Flink 版。
地域
根据您资源对象所在地域选择。
维度
创建告警策略的维度,目前支持作业运行状态、checkpoint、Kafka 和 flinkFiveMinsCounter 四个维度。
资源
确定设置告警策略的资源(作业)范围,支持以下两种设置方式:
- 全部:表示对当前账号下所有作业设置告警策略。注意,全部指针对当前作业生效,后续新建作业需要手动配置。
- 部分:需手动选择一个或多个作业,表示仅对所选作业设置告警策略。
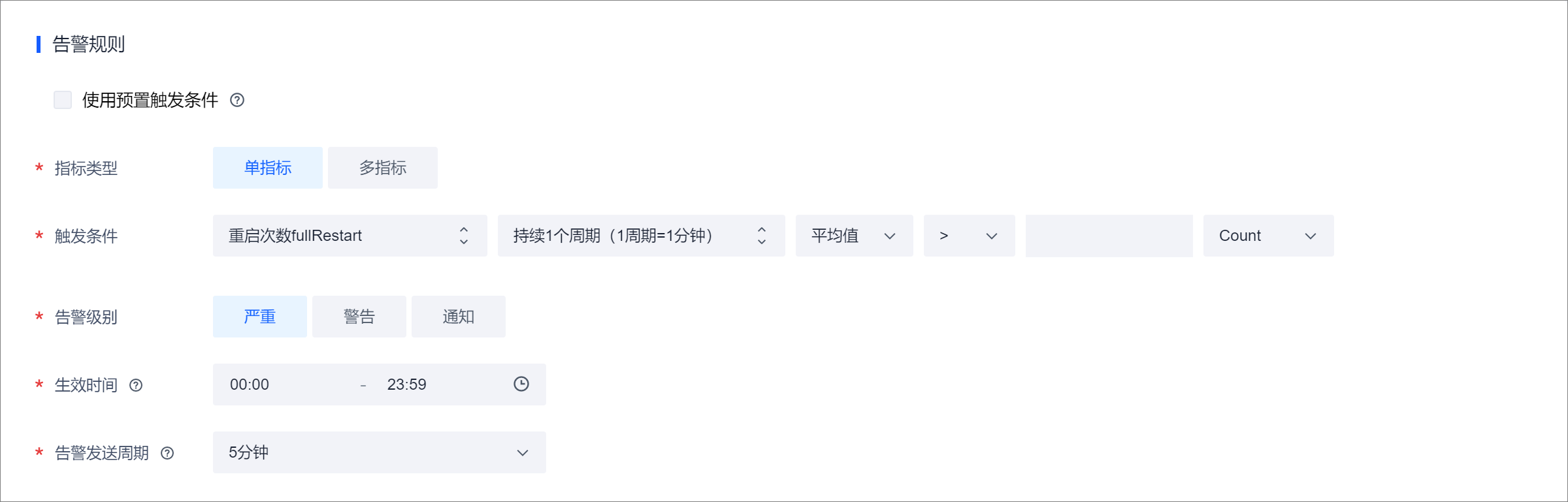
在告警规则区域,选择指标类型,设置告警规则触发条件,告警级别、策略生效时间、告警发送周期等。
配置
说明
使用预置触发条件
按照告警维度预先配置的触发条件,便于您快速填写告警策略。但 Flink 的维维度均没有预置触发条件,无需关注该参数。
指标类型
支持选择单指标或多指标。如果您需要监控资源的多个指标,可直接配置多指标类型。
触发条件
设置告警的监控指标、持续周期、统计类型、比较关系以及阈值。当被监控的资源指标达到触发条件时,系统会推送告警通知。
触发报警的计算方法是连续 N 个周期获取当前周期指标的统计值,如果都满足报警阈值,则触发报警。
以《过去 5 分钟作业 Failover 次数为例》,如果配置连续 3 个周期(1周期=1分钟),总和,>=5。 则会在每分钟计算过去 5 分钟 Failover 次数的和,如果连续 3 分钟计算的值都 >=5 ,则触发报警。告警级别
用于标识告警的严重程度。支持设置严重、警告、通知。
生效时间
告警策略的生效时间。告警策略只在生效时间内监控资源的数据是否达到触发条件。
告警发送周期
触发告警策略后,如果被监控的资源仍然持续触发告警,则系统会周期性发送告警通知。
告警恢复通知
指标不满足触发条件后是否发送告警恢复通知。当前 Flink 支持的指标不支持告警恢复,不要开启
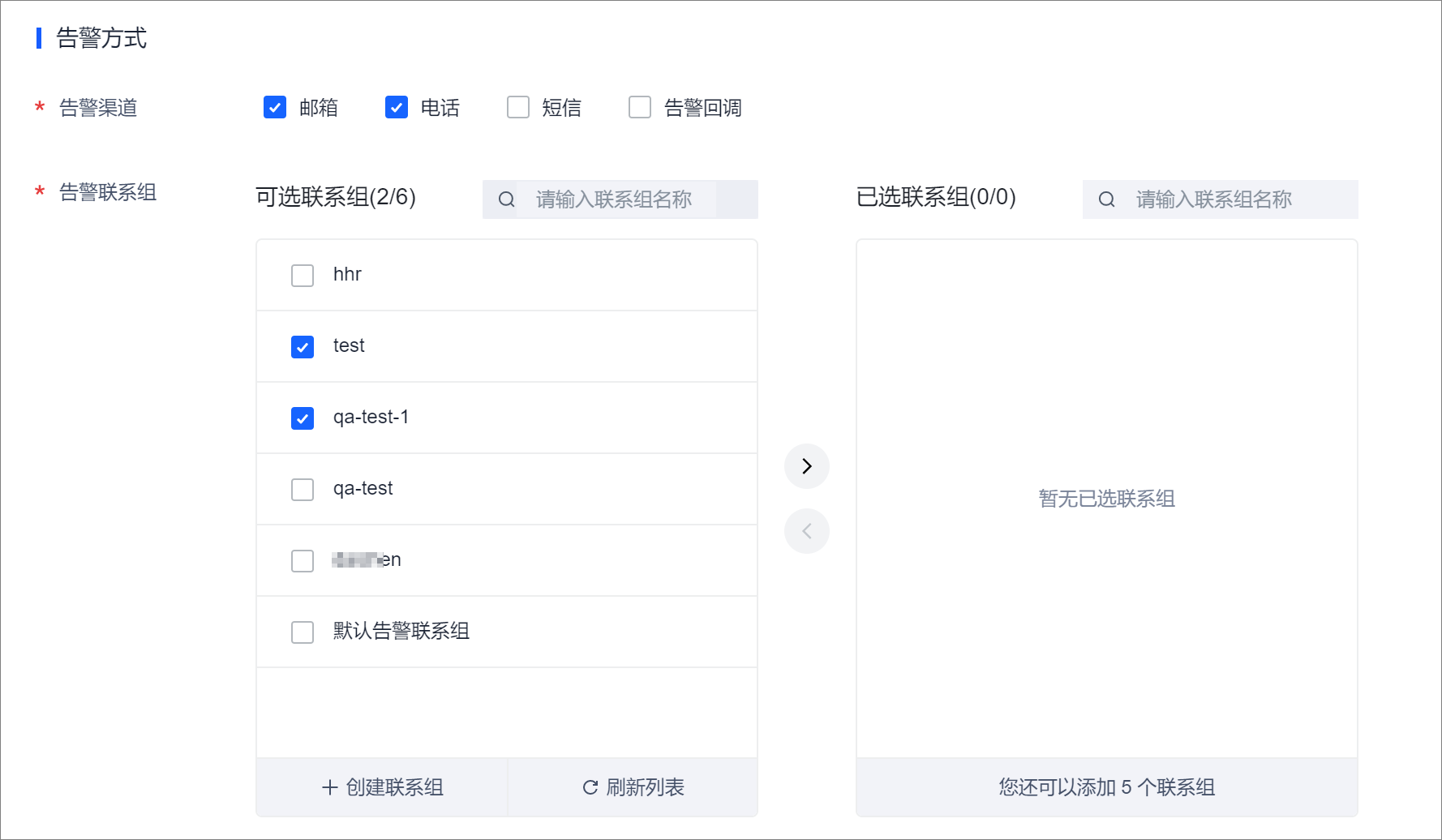
在告警方式区域,选择告警通知方式和告警通知组。
配置
说明
告警渠道
选择一个或多个渠道。支持邮箱、电话、短信以及告警回调。
告警联系组
当告警渠道选择邮箱、电话或者短信中的一个或多个渠道时,您必须设置一个或多个联系组作为告警通知的接收方。
告警回调
当选择告警回调时,页面将展示告警回调文本框,您必须指定可用的 URL。
后续如果触发告警,则系统会把告警的详细信息通过 POST 请求发送至该 URL,便于您进行深入的数据分析。告警策略配置完成后,单击页面右下角的确定。
告警策略创建成功后,即自动启动。