导航
基于Spark的词频统计
最近更新时间:2022.05.11 14:36:28首次发布时间:2022.05.11 14:36:28
实验介绍
本次实验练习介绍了如何在虚拟机内进行批示计算Spark的词频统计类型的数据处理。在开始实验前需要先进行如下的准备工作:
- 下载并配置完成虚拟机。
- 在虚拟机内已完成Hadoop环境的搭建。
关于实验
预计部署时间:90分钟
级别:初级
相关产品:批式计算Spark
受众:通用
操作步骤
步骤一:安装并配置批示计算Spark
1.执行以下命令完成Spark的下载及安装
wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz sudo tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C //解压Spark安装包到根目录下
解压完成后出现如图所示回显: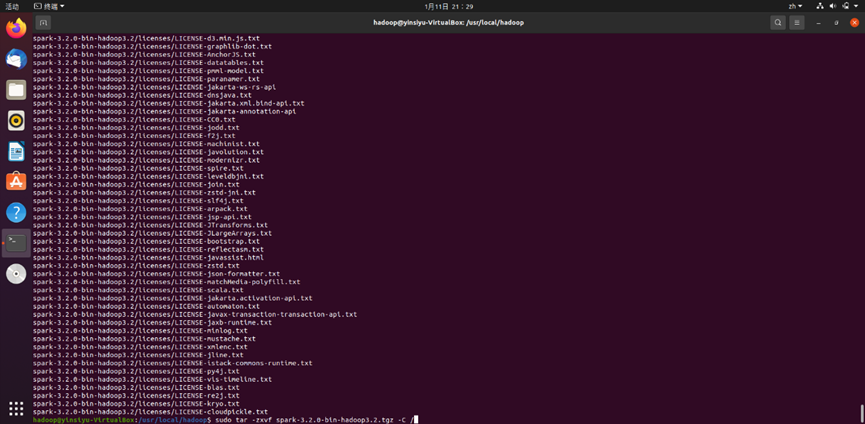
2.进行Spark环境的配置
- 执行sudo vim /etc/profile命令,在文件末尾插入以下内容:
JAVA_HOME = /usr/lib/jvm/jdk_1.8.0_301 //该路径为个人虚拟机内jdk的路径 SPARK_HOME = /usr/local/hadoop/spark-3.2.0-bin-hadoop3.2 //该路径同样为个人虚拟机内hadoop的安装路径 PATH = $PATH:$HOME/bin:$JAVA_HOME/bin:$SPARK_HOME/bin export JAVA_HOME export SPARK_HOME export PATH
- 执行cd /spark-3.2.0-bin-hadoop3.2/conf进入conf目录下,再依次执行以下命令:
sudo cp spark-env.sh.template spark-env.sh sudo vim spark-env.sh
在配置文件末尾根据路径添加如下内容:
export JAVA_HOME = '/usr/lib/jvm/jdk_1.8.0_301' //该路径为个人虚拟机内jdk的路径 export SPARK_HOME = /usr/local/hadoop/spark-3.2.0-bin-hadoop3.2 exoprt HADOOP_HOME = '/home/hadoop' export HADOOP_CONF_DIR =/home/hadoop/etc/hadoop export SPARK_MASTER_IP = 127.0.0.1 export SPARK_MASTER_POST = 7077 export SPARK_MASTER_WEBUI_PORT = 8099 export SPARK_WORKER_CORES = 3 exoprt SPARK_WORKER_INSTANCES = 1 export SPARK_WORKER_MEMORY = 5G export SPARK_EXECUTOR_CORES = 1 export SPARK_WORKER_WEBUI_PORT = 8081 export SPARK_EXECUTOR_MEMORY = 1G export LD_LIBRARY_PATH = ${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
- 依次执行sudo cp workers.template worker和vim worker查看workers配置文件内容。有如下所示图显:
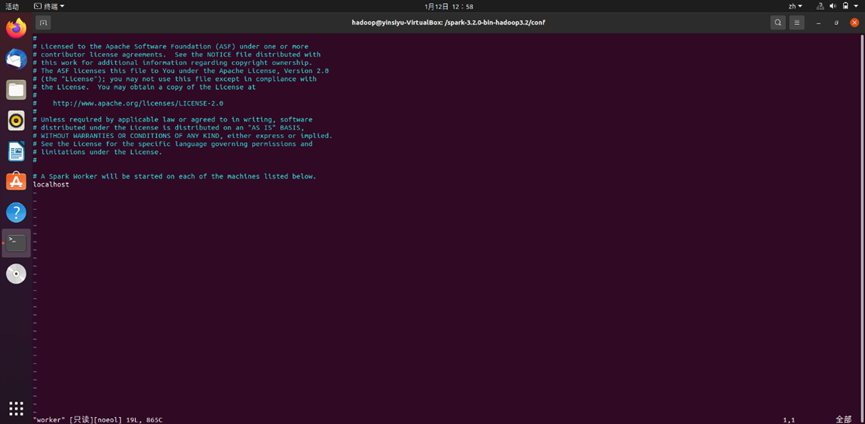
默认是“localhost”,如果不是,请更改为此。
3.验证及启动
在命令行输入jps,出现如下所示图显:

开启Spark环境,正常情况下有如下显示,证明安装及配置成功:
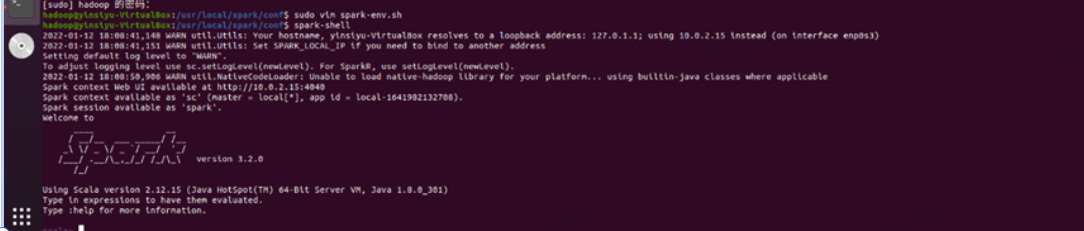
步骤二:安装配置Scala交互环境
执行以下命令完成Scala交互环境的下载安装
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz sudo tar -zxvf scala-2.11.8.tgz -C /usr/local/hadoop //解压scala安装包
解压成功后有如下回显: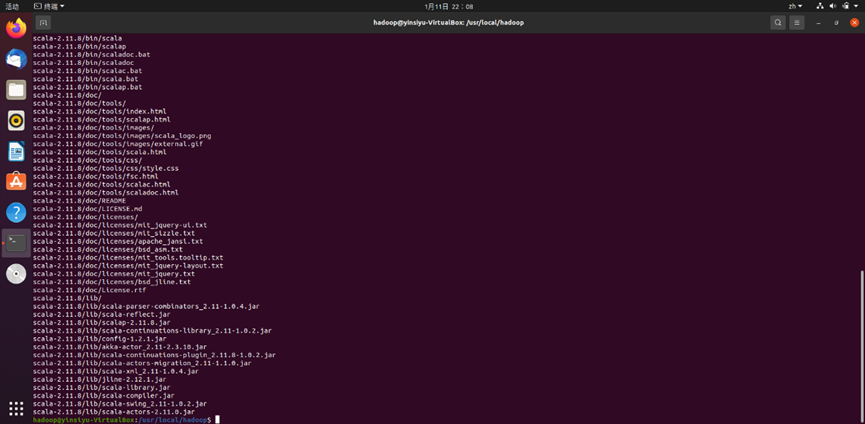
- 执行
sudo vim /etc/profile命令,在配置文件末尾添加如图所示内容:
JAVA_HOME = /usr/lib/jvm/jdk_1.8.0_301 //该路径为个人虚拟机内jdk的路径 SPARK_HOME = /usr/local/hadoop/spark-3.2.0-bin-hadoop3.2 //该路径同样为个人虚拟机内hadoop的安装路径 SCALA_HOME = /usr/local/hadoop/scala-2.11.8 PATH = $PATH:$HOME/bin:$JAVA_HOME/bin:$SPARK_HOME/bin:$SCALA_HOME/bin export JAVA_HOME export SPARK_HOME export SCALA_HOME export PATH
执行source /etc/profile命令,输入scala -version,出现如下所示回显表明scala搭建成功:
步骤三:下载安装sbt用于scala应用程序打包
1.依次执行以下命令,下载sbt:
sudo mkdir /uru/local/sbt //创建sbt目录 wget https://github.com/sbt/sbt/releases/download/v1.3.8/sbt-1.3.8.tgz sudo tat -zxvf ./sbt-1.3.8.tgz -C /usr/local //解压 sudo chown -R hadoop /usr/local/sbt cp ./bin/sbt-lanuch.jar ./
2.下载完成后,进行配置,用于启动sbt
- 执行
vim /usr/local/sbt/sbt,在sbt安装目录下新建一个shell脚本文件,输入以下内容:
#!/bin/bash SBT_OPTS = "-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar 'dirname $0'/sbt-launch.jar "$@"
- 执行
chmod u+x /usr/local/sbt/sbt命令,为该shell脚本增加可执行权限。完成后,执行sbt -version查看sbt版本信息,出现如下所示回显表明安装成功: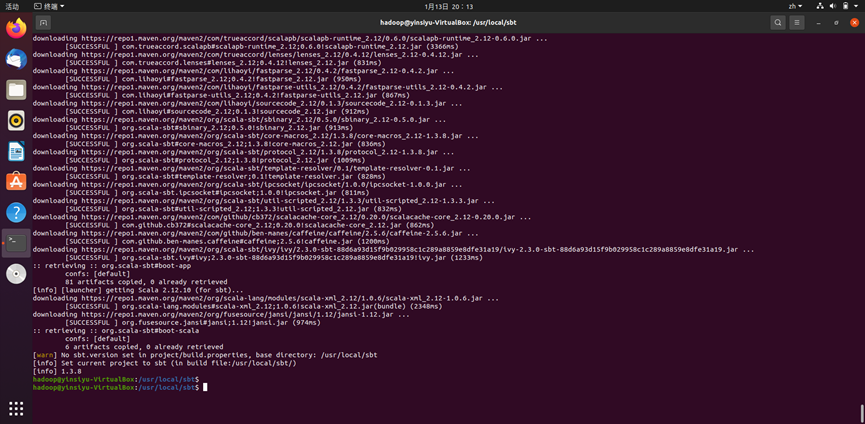
步骤四:进行简单词频统计示例
1.编写scala应用程序来实现词频统计
- 在
/usr/local/spark/mycode/wordcount/src/main/scal下执行vim test.scala命令,输入如下代码示例:
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object WordCount { def main(args: Array[String]) { val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt" val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") val sc = new SparkContext(conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
- 同时执行
vim word.txt命令,创建测试文件(其余大数据可通过其他方式进行)。 - 使用sbt对程序进行打包操作,执行
vim simple.sbt,输入如下所示内容:
name := "Simple Project" version := "1.0" scala Version := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
为保证编译打包顺利完成,执行
find .查看整个应用程序的文件结构,如下图所示:
执行
/usr/local/sbt/sbt package命令开始打jar包,出现如下图所示回显,表明正常,可以开始运行程序: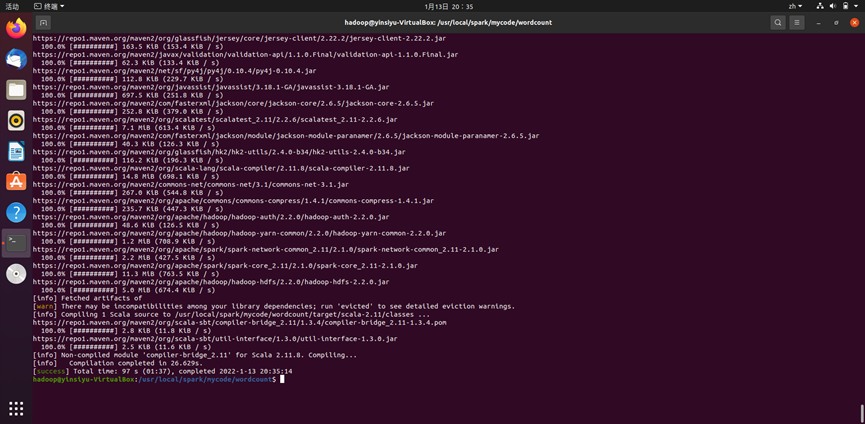
执行如下命令,通过spark-submit运行scala程序:
/usr/local/spark/bin/spark-submit–class "WordCount" /usr/local/spark/mycode/wordcount/target/scala-2.11.8/simple-project_2.11-1.0.jar
出现如下回显,表示执行成功: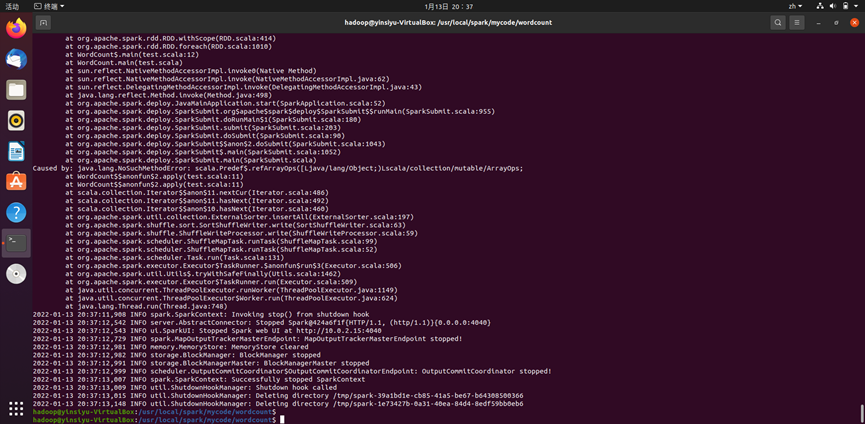
2.通过scala交互模式进行词频统计
在完成准备工作的前提下,执行spark -shell命令,进入scala交互环境,依次执行下列命令:
val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt") val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a + b) wordCount.collect()
可得到结果如下图所示: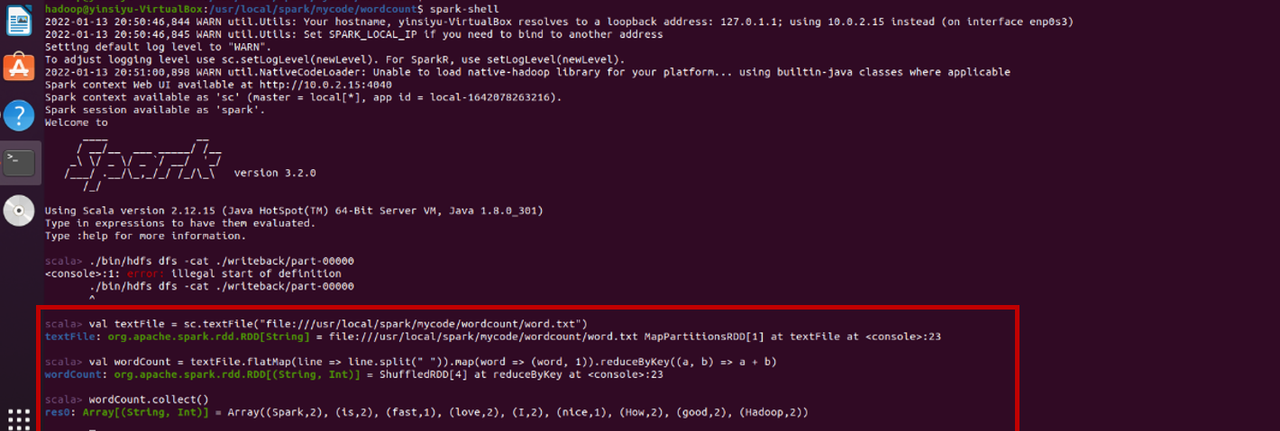
如果您有其他问题,欢迎您联系火山引擎技术支持服务。