数据库工作台 DBW 提供一键诊断功能,通过该功能您可以更直观的查看数据库性能情况的全貌,快速确认实例是否存在异常。本文介绍如何管理一键诊断。
前提条件
- 已创建云数据库 PostgreSQL 版实例,且实例状态处于运行中。详细操作,请参见创建实例。
- 如果目标实例已开启安全管控,那么您需为当前账号申请目标实例的运维只读或运维读写权限。详细信息,请参见开启云数据库 PostgreSQL 版实例安全管控和申请云数据库 PostgreSQL 版相关操作权限。
注意事项
在使用一键诊断功能期间,请勿操作变更实例的相关配置,否则会导致无法正常一键诊断功能查看数据库性能情况。
扣分规则
诊断项 规则 计算方式 CPU 使用率
按照 CPU 使用率进行扣分,最大可扣 10 分。
CPU 使用率 < 70% 时,不扣分。
CPU 使用率 >= 70% 时,扣分计算公式为:
min((使用率-70)*40/100, 10)。
内存使用率
按照内存使用率进行扣分,最大可扣 10 分。
内存使用率 < 70% 时,不扣分。
内存使用率 >= 70% 时,扣分计算公式为:
min((使用率-70)*40/100, 10)。
连接数使用率
连接使用率进行扣分,最大可扣 10 分。
连接数使用率 < 70% 时,不扣分。
连接数使用率 >= 70% 时,扣分计算公式为:
min((使用率-70)*40/100, 10)。
慢日志
按照每 24 小时慢日志的数量进行扣分,最大可扣 10 分。
慢日志数量 = 0 时,不扣分。
0 条 < 慢日志数量 < 50 条时,扣 1 分。
慢日志数量 >= 50 条时,扣分计算公式为
int(min(数量/50, 10))。
磁盘使用率
剩余磁盘预计可使用天数进行扣分,最大可扣 15 分。
通过可使用天数计算扣分
可使用天数 >= 15 天,不扣分。
可使用天数 < 15 天时,扣分计算公式为
int(15 - 天数/3 )
通过使用率计算扣分
磁盘使用率 < 70% 时,不扣分。
磁盘使用率 >= 70% 时,扣分计算公式为:
min((使用率-70)*40/100, 10)。
说明
在统计磁盘使用率的最终得分时,按照两种扣分方式中较高的进行扣分。诊断结果风险等级规则
诊断项 无风险 低风险 中风险 高风险 CPU 使用率 cpuUsage < 70% 70% <= cpuUsage < 80% 80% <= cpuUsage < 90% 90% <= cpuUsage 内存使用率 memUsage < 70% 70% <= memUsage < 80% 80% <= memUsage < 90% 90% <= memUsage 连接数使用率 connectionUsage < 70% 70% <= connectionUsage < 80% 80% <= connectionUsage < 90% 90% <= connectionUsage 慢日志 slowlogs = 0 0 <= slowlogs < 100 100 <= slowlogs < 300 300 <= slowlogs 磁盘使用率
15 <= days
diskUsage < 70%
12 <= days < 15
70% <= diskUsage < 80%
7 <= days < 12
80% <= diskUsage < 90%
0 <= days < 7
90% <= diskUsage
查看一键诊断
说明
一键诊断将从慢日志、实时会话等维度帮助您全面诊断 PostgreSQL 实例的运行问题。同时,会给您提出建议性的解决方案,帮助您快速排查数据库故障。
登录 DBW 控制台。
在顶部菜单栏,选择项目和地域。
在左侧导航栏,选择运维管理 > 观测诊断,单击一键诊断。
在页面右上角切换实例类型为云数据库 PostgreSQL 版。
在页面左上角,切换目标实例。
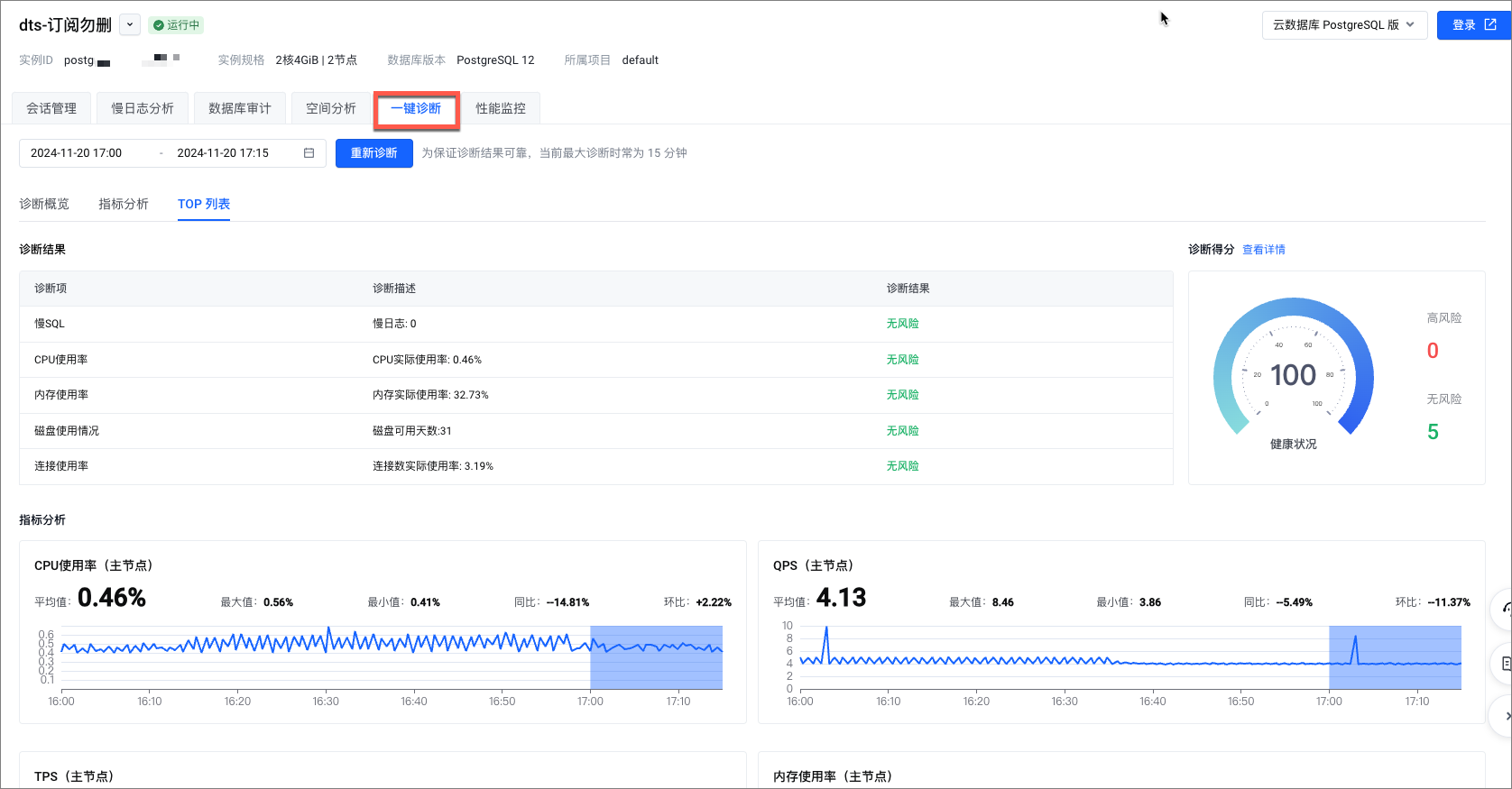
在一键诊断页签,您可以查看到实例内的以下信息。
说明
- 默认展示最近十五分钟的诊断信息,您也可以按需查看指定时间内的诊断结果,时间跨度不可超过 15 分钟。
- 如果指标分析中出现标红的状态,则说明实例存在风险,建议排查一下您的数据库实例,并采取相应措施,保证系统能够稳定高效地运行。
参数 说明 诊断概览 在诊断概览页签,您可以查看实例的诊断结果和诊断得分,具体如下所示: 诊断结果
在诊断结果区域您可以查看当前实例内的诊断项包括慢 SQL、CPU 使用率、内存使用率、磁盘使用率和连接使用率的诊断结果、开始时间。同时,您也可以单击各诊断项操作列的查看详情,查看各诊断项的具体信息,具体信息如下所示:
慢 SQL:在诊断结果详情:慢 SQL 对话框,可以查看慢 SQL 的指标描述、TOP 10 慢 SQL 列表和性能监控具体信息如下所示。
指标描述:该区域展示当前实例内慢 SQL 的数量。
TOP 10 慢 SQL 列表:在该区域展示前 10 个慢 SQL。单击查看全部,跳转至慢日志分析页签,可查看更多慢日志。详细信息,请参见慢日志分析管理。
性能监控:该区域展示当前实例内的慢 SQL 数量和 CPU 使用率。
CPU 使用率:在诊断结果详情:CPU 使用率对话框,可以查看 CPU 使用率的指标描述和性能监控,具体信息如下所示。
指标描述:该区域展示当前实例内 CPU 的使用率。
性能监控:该区域展示当前实例内的 CPU 使用率、QPS 和 TPS。
内存使用率:在诊断结果详情:内存使用率对话框,可以查看内存使用率的指标描述和性能监控,具体信息如下所示。
指标描述:该区域展示当前实例内内存的使用率。
性能监控:该区域展示当前实例内的内存使用率和 innodbBufferPool 使用率。
磁盘使用率:在诊断结果详情:磁盘使用率对话框,可以查看磁盘使用率的指标描述、TOP 10 表空间和性能监控,具体信息如下所示。
指标描述:该区域展示当前实例内磁盘的使用率。
TOP 10 表空间:该区域展示当前实例的前 10 个表空间。单击查看全部,查看当前实例的空间使用情况。具体信息,请参见空间分析管理。
性能监控:该区域展示当前实例内的磁盘使用率和 Binlog 大小。
连接使用率:在诊断结果详情:连接使用率对话框,可以查看指标描述和会话信息。具体如下所示。
指标描述:展示当前实例连接数的使用率。
会话信息:该区域展示当前实例内的连接数使用率和连接数。您可以单击查看活跃会话,查看更多会话信息和实时会话信息。详细信息,请参见会话管理。
说明
将鼠标悬浮在各个诊断项上,可查看各个诊断项的风险定义。关于风险规则,请参见注意事项。
诊断得分 在诊断得分区域您可以查看当前实例的诊断得分,包括健康状况、高风险和无风险的数量。您也可以单击查看详情,在扣分详情对话框查看当前实例内的具体扣分项。 指标分析
在指标分析页签,您可以查看各指标的平均值、最大值、最小值、同比值和环比值。
说明
同比值:和 24 小时前的同一个时间段的比值。
环比值:和上个小时的同一个时间段的比值。
如果指标分析中出现标红的状态,则说明实例存在风险,建议排查一下您的数据库实例,并采取相应措施,保证系统能够稳定高效地运行。
CPU 使用率(主节点)
表示数据库服务器在处理请求时所消耗的 CPU 资源。
您可以通过监控和优化来有效管理和降低 CPU 使用率,提高数据库的整体性能和响应速度。QPS(主节点)
表示数据库在每秒钟内能够处理的查询次数。
您可以通过合理的查询优化、硬件升级、配置调整和使用连接池等方法,可以显著提升系统的 QPS,从而满足更多查询请求,提高数据库的整体性能和服务质量。实时监控和分析 QPS 也能帮助发现和解决性能瓶颈,保证系统的高效运行。TPS(主节点)
表示数据库每秒钟能够处理的事务数量。
您可以通过合理的事务优化、硬件配置提升、调整数据库参数和使用连接池等方法,可以显著提升系统的 TPS,满足更多事务请求,提高数据库整体性能和响应速度。实时监控和分析 TPS,有助于发现性能瓶颈并采取相应措施,保证系统的稳定高效运行。内存使用率(主节点)
表示主节点在处理数据库操作时所消耗的内存资源。
您可以通过合理配置内存参数(如shared_buffers、work_mem)、优化查询、以及定期监控和调整,可以有效提升数据库的性能,确保系统在高负载下的稳定运行。适当的内存使用能够减少磁盘 I/O 次数,提高查询速度,从而提供更好的用户体验。当前打开连接数(主节点)
表示主节点上正在使用的数据库连接的数量。
您可以通过使用连接池优化应用程序连接管理、合理调整数据库配置参数、持续监控系统运行状况和负载分担策略,可以有效管理连接数,确保数据库在高并发环境下保持性能和稳定性。这不仅能提高系统的响应速度,满足业务需求,还能防止资源瓶颈导致的服务中断。慢查询数量(主节点)
表示执行时间超过预期或设定阈值的查询,用于评估数据库的健康状况和整体效率。
您可以通过持续监控和分析慢查询,识别和解决潜在的性能瓶颈,确保系统在高负载环境下依然能够快速响应,提供优质的使用体验。活跃会话数(主节点)
表示当前在主节点上处于活跃状态的客户端连接的数量。
您可以通过使用连接池、优化查询和事务、调整数据库配置、监控和负载分担等策略,有效管理活跃会话数,确保数据库在高并发环境下保持性能和稳定性。合理的活跃会话管理能够提升系统响应能力,提供稳定的使用体验,同时避免资源瓶颈导致的服务中断和性能下降。连接数使用率(主节点)
表示当前数据库所使用的连接数占配置的最大连接数的比例。
您可以通过合理的连接管理、优化应用程序、调整数据库配置、监控和负载分担等策略,有效地控制连接数使用率,确保数据库在高并发环境下保持性能和稳定性。监控连接数使用率,有助于及时识别潜在的资源瓶颈,防止资源耗尽带来的性能问题,并为系统扩展提供参考依据。TOP SQL 列表 在 TOP SQL 列表区域,您可以查看在该实例中的基于 TOP 慢 SQL、TOP 表(基于空间分析) 统计的 TOP SQL 的详细信息,您也可以单击查看全部,查看 SQL 的更多信息。