GPU云服务器
GPU云服务器






- 文档首页
 GPU云服务器容器共享mGPU用户指南通过Docker云上安装并使用mGPU服务
GPU云服务器容器共享mGPU用户指南通过Docker云上安装并使用mGPU服务

本文主要介绍在GPU云服务器中搭建Docker使用 mGPU 功能,实现容器共享 GPU 的方法。
前提条件
本方法仅限在火山引擎公有云环境中使用,安装mGPU服务前,请您完成以下准备工作:
- GPU多容器共享技术mGPU仅对已通过企业实名认证的用户开放,暂不支持个人实名认证用户使用。请确认您已完成账号注册和企业实名认证。
- 请联系客户经理获取mGPU安装包。
- 确保GPU实例满足以下要求:
- 您已购买GPU计算型实例。
- GPU实例操作系统为velinux1.0,内核版本为5.4.x。
- GPU实例已安装470.129.06的NVIDIA驱动,您可以参考安装GPU驱动。
步骤一:安装nvidia-docker
- 远程连接云服务器并登录,具体操作请参考登录Linux实例小节。
- 请参考NVIDIA官方指导完成nvidia-docker(19.3以上版本)和nvidia-container-toolkit(1.10.0-1及以下版本)安装。
- 执行以下命令,安装nvidia-container-toolkit。
apt install -y nvidia-container-toolkit=1.10.0-1
步骤二:安装mGPU服务
- 下载并查看安装包文件,确认版本信息。
- 将安装包上传到GPU实例的可执行目录下。
- 执行以下命令安装mGPU,请将
mgpu-installer-x.xx.xx-xxx-xxx-xxx.run替换为您实际获取的安装包文件名称。bash mgpu-installer-x.xx.xx-xxx-xxx-xxx.run
回显如下,表示安装成功。
- 执行以下命令,查看日志确认安装结果。
cat /var/log/mgpu/mgpud.log
回显如下,表示安装成功。2022-11-15T20:16:14.393+0800 INFO mGPU Daemon version: 0.07.32
步骤三:运行mGPU服务
本文以ecs.g1tl.4xlarge为例,为您演示当2个容器共用1号GPU显卡,且使用TensorFlow 19.10版本时的配置方式。
背景信息
影响mGPU服务的环境变量如下表所示,您需要在创建容器时指定环境变量的值,使容器可以通过mGPU服务获得算力。运行mGPU服务前,请您首先了解下表信息。
| 环境变量 | 取值类型 | 说明 | 示例 |
|---|---|---|---|
| NVIDIA_VISIBLE_DEVICES | String | NVIDIA容器运行时标准环境变量。 | 请根据NVIDIA官方要求准备。 |
MGPU_COMPUTE_POLICY | u64 | mGPU服务提供的算力Qos策略,取值:
| 若希望容器在第1张GPU卡上使用Native burst share策略,配置 |
| MGPU_COMPUTE_WEIGHT | String | 容器配置的GPU卡算力权重,取值范围:(0,100] 。 | 若希望容器在第1张GPU卡上使用20%的权重,则配置MGPU_COMPUTE_WEIGHT=0:20。 |
MGPU_VMEM_LIMIT | String | 容器配置的GPU卡限制显存,单位MiB。 | 若希望容器在第2张卡张限制最多使用4096MiB的显存,则配置 |
执行以下命令,启动mGPU服务。
systemctl start mgpud执行以下命令创建容器a和容器b,并设置容器内可见显存。
docker run --name gpu_a --gpus '"device=1"' -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v /mnt:/mnt -e MGPU_COMPUTE_WEIGHT=1:50 -e MGPU_COMPUTE_POLICY=1:0 -e MGPU_COMPUTE_TIMESLICE=1:200 -e MGPU_VMEM_LIMIT=1:16384 nvidia/cuda:11.4.0-base-ubuntu20.04docker run --name gpu_b --gpus '"device=1"' -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v /mnt:/mnt -e MGPU_COMPUTE_WEIGHT=1:30 -e MGPU_COMPUTE_POLICY=1:0 -e MGPU_COMPUTE_TIMESLICE=1:200 -e MGPU_VMEM_LIMIT=1:4096 nvidia/cuda:11.4.0-base-ubuntu20.04说明
本示例中,通过设置环境变量
MGPU_VMEM_LIMIT指定容器内可见的显存,执行完成后创建了2个容器:- gpu_a:分配8 GiB显存,50%算力。
- gpu_b:分配4 GiB显存,30%算力。
执行以下命令,通过mgpu-cli工具查看显存、算力等信息,更多介绍请参见监控mGPU相关指标。
mgpu-cli device info -a //-a表示查看容器a的信息
回显如下,可查看GPU显卡的剩余显存和算力。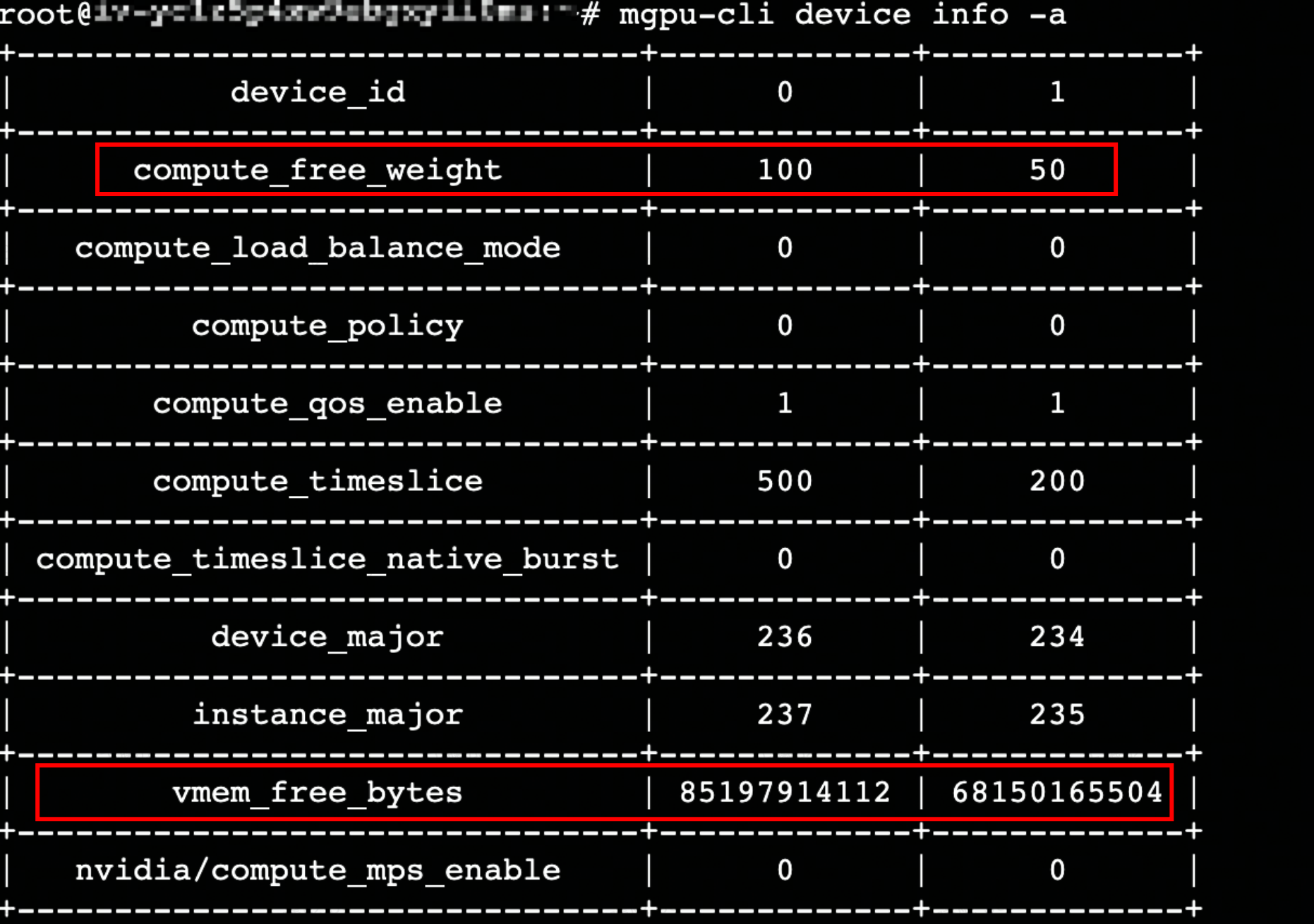
附录
升级mGPU服务
您可以按需升级mGPU服务,以获得更高版本的能力支持。
- 执行以下命令,关闭所有运行中的容器。
docker stop (docker ps -a | awk '{ print $1}' | tail -n +2) - 执行以下命令,安装新的mGPU服务,请将
mgpu-installer-x.xx.xx-xxx-xxx-xxx.run替换为您实际获取的安装包文件名称。bash mgpu-installer-x.xx.xx-xxx-xxx-xxx.run
卸载mGPU服务
- 执行以下命令,停止所有运行容器。
docker stop (docker ps -a | awk '{ print $1}' | tail -n +2) - 执行以下命令,卸载mGPU。
bash /usr/local/mgpu/mgpu-uninstall
监控mGPU相关指标
mGPU安装时已为您同时安装了mgpu-cli工具,便于您直接在终端查看mgpu相关指标,包括device、container、instance。
执行mgpu-cli -h命令,获取mgpu-cli使用帮助。
回显如下,表示您可以使用mgpu-cli container info -a获取容器a的container相关指标。
Manage and config mgpu devices and instances from the command line. Usage: mgpu-cli [command] Available Commands: completion Generate the autocompletion script for the specified shell container Container manage commands device Device manage commands help Help about any command instance Container manage commands version Show version
Device 指标说明
指标名称 指标含义 compute_free_weight 设备未分配的算力百分比 compute_load_balance_mode 容器使用该设备时的负载均衡模式 compute_policy 设备的算力调度策略 compute_qos_enable 基于该设备的创建的实例是否使能算力QoS(适用于Native Burst策略) compute_timeslice 算力时间片百分比 device_major /dev/mgpuX主设备号 instance_major /dev/mgpuXinstY、/dev/mgpuXctl-$(container_id)主设备号 vmem_free_bytes 该设备剩余的显存容量(单位: byte) nvidia/compute_mps_enable 容器内是否使能mps服务(适用于Native Burst策略) Container/Instance 指标说明
指标名称 指标含义 instance_id 实例ID container_id 容器ID device_id 实例对应的设备ID instance_id 实例ID compute_qos_enable 是否使能算力QoS compute_weight 该实例分配的算力百分比 minor /dev/mgpuXinstY的次设备号 tasks 正在使用该设备的进程PID vmem_info 显存信息:空闲、PID、已使用 vmem_limit 申请的容器显存限制 vmem_qos_enable 是否使能显存qos