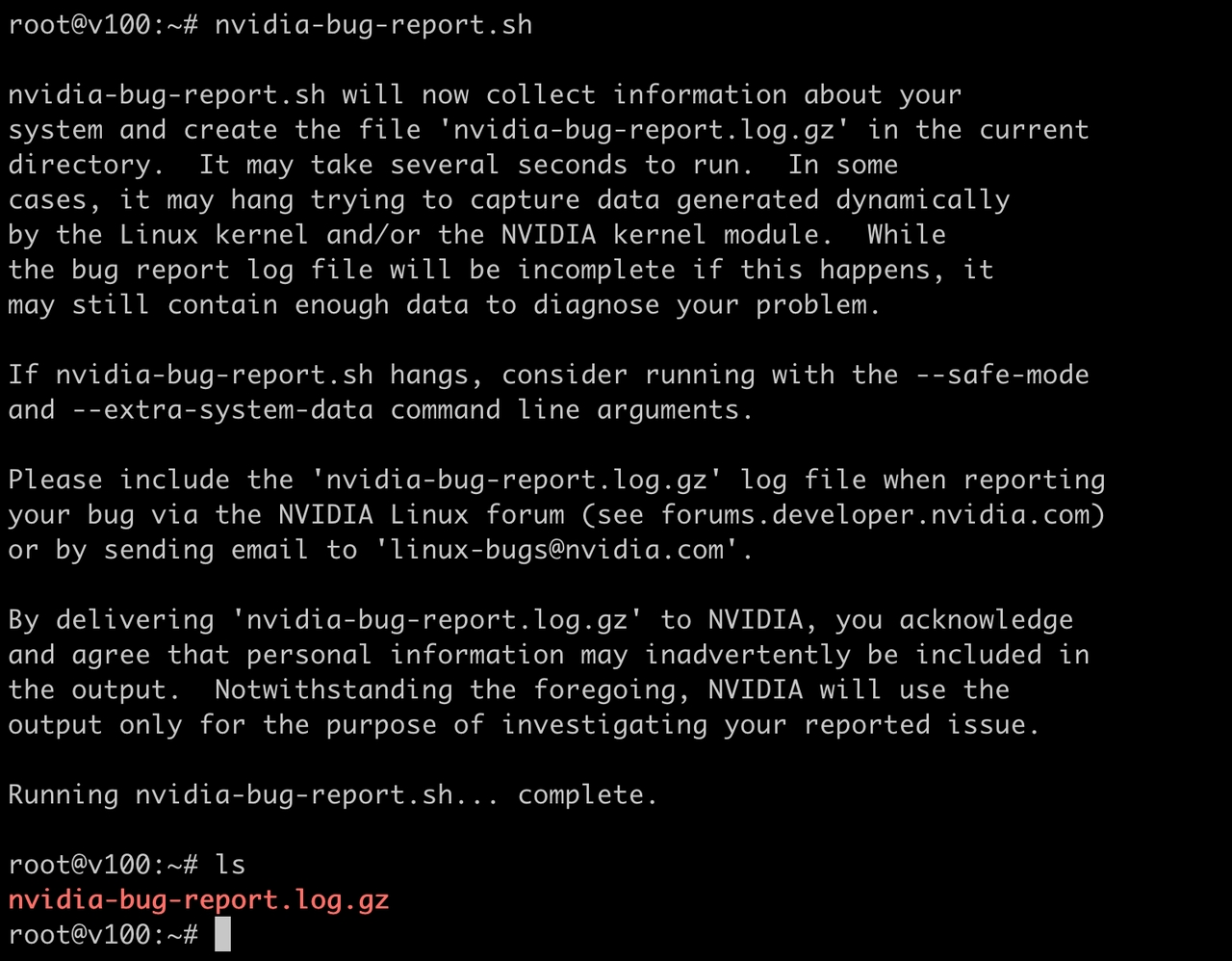
如何判断和处理硬件相关故障?
GPU实例相比普通云服务器实例,增加了较多的外设,包括GPU、RDMA网络直通网卡、本地盘等。因此,除普通云服务器可能发生的常见问题外,还有如GPU、直通网卡以及PCIe链路上发生的亚健康或故障。针对GPU实例的常见故障和处理建议具体如图1所示。
图1 常见故障及处理建议
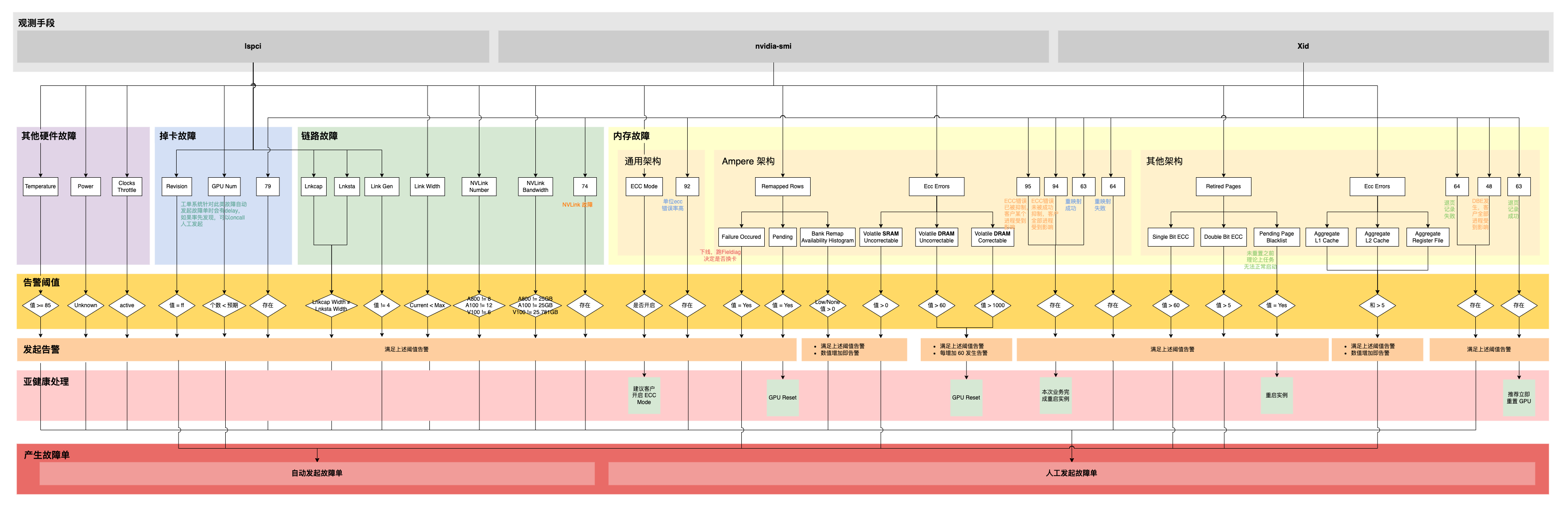
图2 故障处理流程
GPU亚健康或故障处理流程如图2所示,以下重点介绍亚健康现象的处理流程。
除亚健康外的其它故障现象,您可以通过工单系统直接发起故障单或等待系统自动监控到异常情况从而自动发起故障单进行处理。
- 当发生“监控异常事件通知”、“业务中断实例异常”情况时,需要分析是否为亚健康现象(参考图1)。
- 查看亚健康现象是否恢复。
- 未恢复,发起Oncall或提交工单处理。
- 已恢复,处理完毕。
常见问题列表
| 故障类型(见图1) | 相关文档 |
|---|---|
| 掉卡故障 | 如何查看GPU是否掉卡? |
| 链路故障 | 如何查看带宽/链路是否正常? |
| 内存故障 | 如何判断GPU实例是否为Ampere架构? |
| 如何查看Remapped Rows相关指标(仅Ampere架构)? | |
| 如何查看Retired Pages相关指标(除Ampere外的其它架构)? | |
| - | 如何查看Xid信息? |
| - | 如何收集NVIDIA日志? |
如何查看GPU是否掉卡?
方式一
登录实例。
执行如下命令,若回显结尾为(rev ff),表明GPU识别异常。
lspci | grep -i nvidia# lspci | grep -i nvidia 31:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) 65:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) 98:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) e3:00.0 3D controller: NVIDIA Corporation Device 2236 (rev ff)执行如下命令查看GPU卡数量,如下图,查询的是4卡规格,丢失1张。
nvidia-smi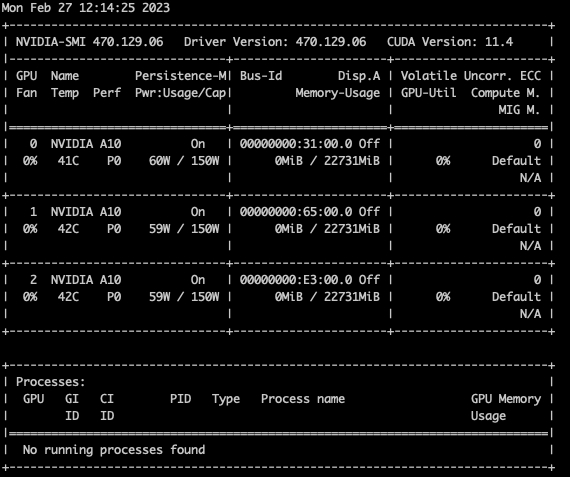
方式二
- 登录实例。
- 执行如下命令查看系统日志。
cat /var/log/kern.log | grep -i xid
回显如下,表明GPU卡丢失。
如何查看带宽/链路是否正常?
方式一:Lspci带宽检测
- 登录实例。
- 执行如下命令。
lspci -vvd 10de: | grep -i "Lnkcap:\|Lnksta:"
回显如下,其中Lnkcap为额定带宽,Lnksta为当前带宽,两者一致则表明带宽/链路未发生异常。# lspci -vvd 10de: | grep -i Lnkcap: LnkCap: Port #0, Speed 8GT/s, Width x16, ASPM not supported LnkCap: Port #4, Speed 8GT/s, Width x16, ASPM not supported LnkCap: Port #16, Speed 8GT/s, Width x16, ASPM not supported LnkCap: Port #20, Speed 8GT/s, Width x16, ASPM not supported # lspci -vvd 10de: | grep -i Lnksta: LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok) LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok) LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok) LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
方式二:Nvidia-smi检查
- 登录实例。
- 执行如下命令。
nvidia-smi -q | grep -i -A 2 'Link width'
回显如下,Max和Current的值保持一致,表明带宽/链路未发生异常。# nvidia-smi -q | grep -i -A 2 'Link width' Link Width Max : 16x Current : 16x -- Link Width Max : 16x Current : 16x -- Link Width Max : 16x Current : 16x -- Link Width Max : 16x Current : 16x
如何判断GPU实例是否为Ampere架构?
根据GPU显卡判断架构类型,具体如下表所示。
| 架构类型 | GPU卡 | 实例规格 |
|---|---|---|
Ampere 架构 | A100 | 不同规格挂载的GPU卡不同,具体请参见实例规格清单。 |
| A800 | ||
| A30 | ||
| A10 | ||
| Volt 架构 | V100 | |
| Turing 架构 | T4 |
如何查看Remapped Rows相关指标(仅Ampere架构)?
Remapped Rows是NVIDIA Ampere架构新增的一种硬件机制,用于提高GPU上帧缓冲存储器的可靠性,GPU检测到内存错误时,会尝试重新映射到GPU设备内存行,当一行被重新映射时,NVIDIA驱动程序会将错误的行重新映射到保留行,后续对该行的所有访问都将访问保留行而不是错误行。
您可以通过以下操作查看Remapped Rows相关指标:
- 登录实例。
- 执行如下命令。
nvidia-smi -q -d ECC,ROW_REMAPPER
正常返回如下图所示。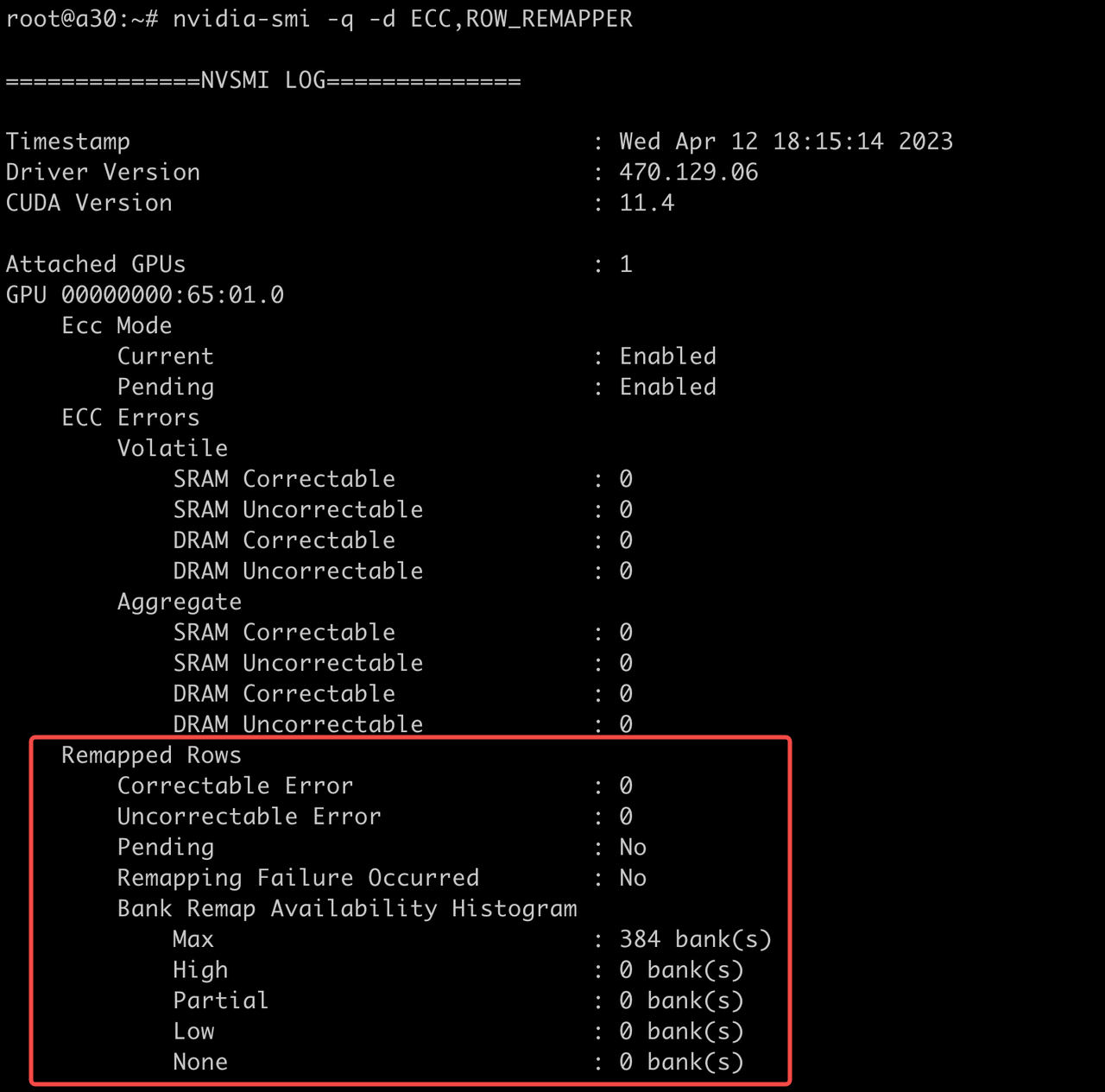
- 如果Pending指标为YES,表示当前发生行重映射,需要重启实例。
- 如果Remapping Failure Occurred指标为YES,表示当前行重映射发生异常,主机需要下线检修。
- 如果Bank Remap Availability Histogram指标的Low/None值 > 0,表示可用的重映射保留行不足,主机需要下线检修。
如何查看Retired Pages相关指标(除Ampere外的其它架构)?
当发生Double Bit ECC错误或多个Single Bit ECC错误时,可能会淘汰GPU设备内存页面。当页面被淘汰时,NVIDIA驱动程序会将其隐藏,这样任何驱动程序或应用程序内存分配都无法访问该页面。
ECC:Error Correcting Code,错误检查和纠正技术。
您可以通过以下操作查看Retired Pages相关指标:
- 登录实例。
- 执行如下命令。
nvidia-smi -q -d ECC,PAGE_RETIREMENT
正常返回如下图所示。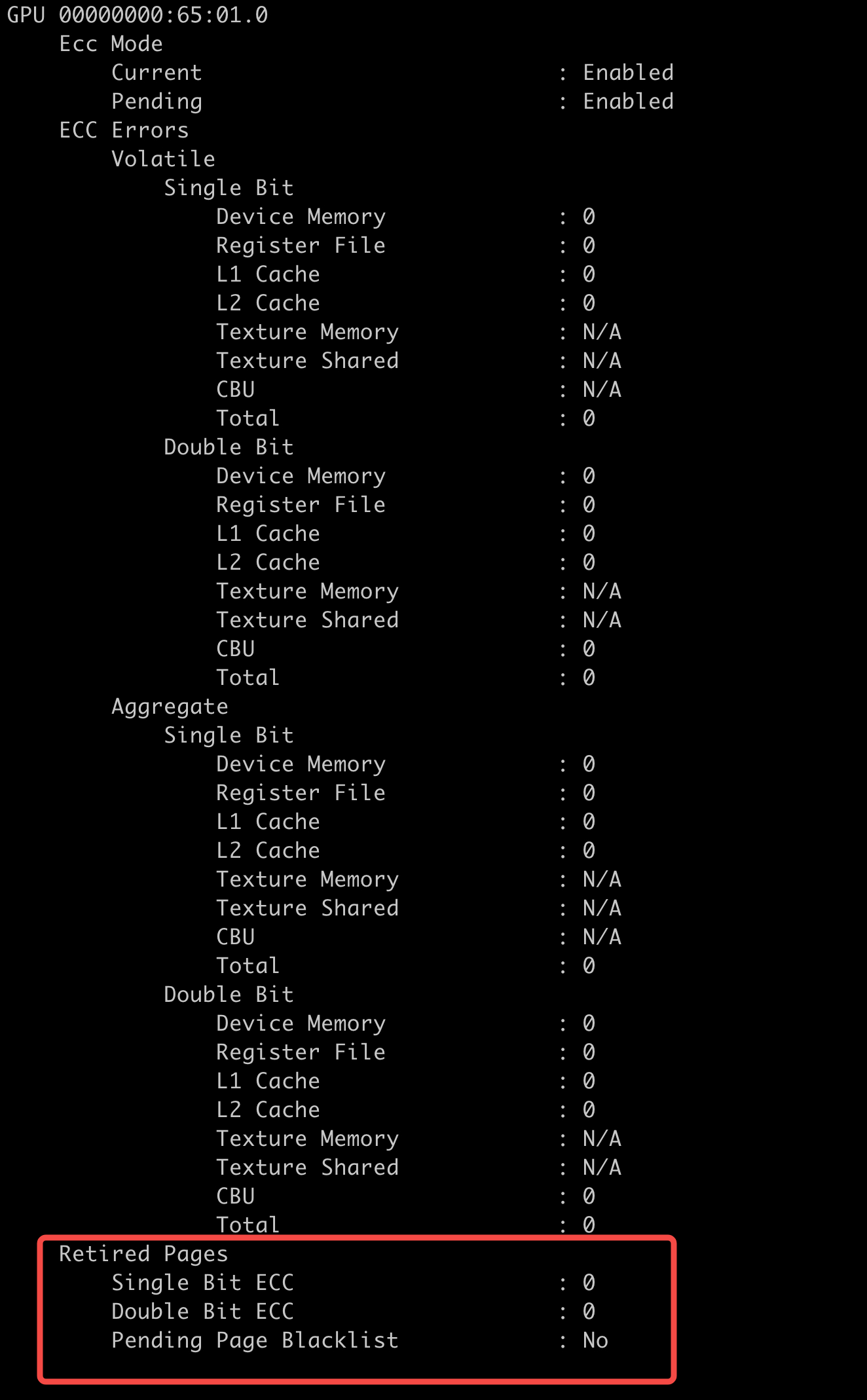
- 如果Pending Page Blacklist指标为YES,需要重启实例。
- Single Bit ECC错误淘汰的内存页数超过60或者Double Bit ECC错误淘汰的内存页数超过5(见图1),需要下线检修物理机。
如何查看Xid信息?
XID是指“X Error ID”,是一种错误代码,用于标识在GPU操作期间发生的错误。XID通常与GPU硬件或驱动程序中的错误相关,例如内存错误、电源问题、温度过高等。
当GPU检测到错误时,它会生成一个XID并记录在系统日志中,管理员可以查看系统日志以查找与XID相关的错误信息,并采取适当的措施来修复问题。
您可以通过以下操作查看Xid信息:
- 登录实例。
- 执行如下命令。
cat /var/log/messages | grep "Xid (PCI"cat /var/log/kern.log | grep "Xid (PCI"
结果如下图所示。