日志服务支持通过 DaemonSet 方式采集 Kubernetes 集群的容器标准输出,本文档演示控制台创建采集配置的相关操作步骤。
背景信息
在容器中安装日志服务提供的采集插件 LogCollector 之后,LogCollector 会根据容器中的 Label 和环境变量确定待采集的容器,持续采集指定容器内产生的标准输出,并将标准输出和容器名等容器相关的元数据信息一起上传至服务端。LogCollector 还支持断点续联,checkpoint 文件中会定期留存采集相关的位点信息,即使 LogCollector 停止后重新启动,也会从上一次保存的位点继续采集。
此外,LogCollector 采集容器标准输出时,支持单行、多行等多种采集配置,除各种采集配置默认附加的预留字段之外,日志服务还会对 LogCollector 采集到的容器标准输出添加以下预留字段,并默认为其创建索引。
预留字段 | 说明 |
|---|---|
| 数据源类型,即 stdout 或 stderr。 |
| 镜像名称。 |
| 容器名称。 |
| 容器或 Pod 的 IP 地址。 |
| Pod 名称。 |
| Pod 的唯一标识。 |
| Pod 所属的 Namespace。 |
前提条件
- 已在待采集的容器中安装了 LogCollector。相关操作步骤请参考 Kubernetes 集群安装 LogCollector。
- 已创建了机器组,并在机器组中添加了容器所在的宿主机。 推荐使用机器标识类型的机器组,机器标识可配置为您在安装 LogCollector 时配置的用户自定义标识,即需与您在安装 LogCollector 时,在 ConfigMap 中设置的
${your_labels}的值一致,例如nginx-log。
限制说明
- 采集容器标准输出时:
- Docker 容器引擎仅支持 JSON 类型的日志驱动。
- 如果某些容器匹配了多个采集配置,那么在该容器上仅最新的采集配置生效。
- 采集容器内日志文件时:
- 容器内日志文件的采集路径目前仅支持不挂载、emptyDir 挂载和 hostPath 挂载 3 种方式。
- 采集路径不支持设置为软链接,因为 LogCollector 无法访问容器内日志文件的软链接,请按照容器内日志文件的真实路径配置采集路径。
- 在容器停止之后,LogCollector 会收到该容器的 stop 事件,并随即停止采集该容器的日志。如果 LogCollector 采集该容器的日志有一定延迟,则容器停止之前产生的部分日志可能未被采集。
- LogCollector 支持的容器引擎包括 Docker 和 Containerd。不同类型容器引擎的访问路径限制如下:
- Docker:LogCollector 通过宿主机的
/run/docker.sock访问 Docker 容器引擎,请确保该路径存在且 LogCollector 具备访问权限。 - Containerd:LogCollector 通过宿主机的
/run/containerd/containerd.sock访问 Containerd 容器引擎,请确保该路径存在且 LogCollector 具备访问权限。
- Docker:LogCollector 通过宿主机的
创建 LogCollector 采集配置
步骤一 选择日志空间
- 登录日志服务控制台。
- 在顶部导航栏中,选择日志服务所在的地域。
- 在左侧导航栏中,选择常用功能 > 日志接入。
- 在日志接入页面的LogCollector日志采集页签中,选择日志采集模式。
- 选择日志空间,单击下一步:选择机器组。
选择日志项目和日志主题,采集到的日志数据将被存储到该日志主题中。
步骤二 选择机器组
- 在全部机器组区域中,选择需要被采集日志的机器组。
如果列表中无可用的机器组,您需要先创建机器组。具体操作,请参考创建机器组(机器标识)、创建机器组(IP地址) - 在已选机器组区域中确认机器组无误后,单击下一步:采集规则。
步骤三 配置采集规则
配置基础信息
填写基本规则配置。
配置
说明
规则名称
规则名称即 LogCollector 采集配置的名称。
您也可以单击导入其他采集配置,选择日志Region、日志项目和采集配置,将已创建的采集配置导入到当前配置中,您只需要指定采集规则名称即可。容器日志采集
选择启用。
采集类型
选择K8s 容器标准输出。
采集信息
按需选择采集的内容。支持以下采集方式:
- 仅采集标准输出 - stdout。
- 仅采集标准错误 - stderr。
- 同时采集标准输出 - stdout和标准错误 - stderr。
(可选)启用通用容器采集规则。
通用容器采集规则通过容器的通用信息指定待采集的内容,也可以同时排除不采集的内容。说明
未启用通用容器采集规则和K8s 采集规则时,表示采集范围为全部容器。同时配置两种采集规则时,两种规则的逻辑关系为与,即必须同时满足两种规则才能成功采集。
配置
说明
容器名称
待采集的容器名称。若未指定容器名称,表示采集机器组中全部容器。
支持正则匹配,例如设置容器名称为^(container-test)$,表示采集所有名称为container-test的容器。说明
正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。容器Label
启用白名单
容器 Label 白名单通过容器 Label 指定待采集的容器,不启用白名单时指定采集全部容器。
启用容器 Label 的白名单时,需要填写键值对。其中 Key 必选,Value 可选。- Value 为空:采集所有在容器 Label 中包含 Key 的容器。
- Value 不为空:只采集在容器 Label 中包含 Key 并且其值匹配 Value 的容器。 Value 支持正则匹配。例如设置 Key 为 app,设置 Value 为
^(test1|test2)$,表示只采集在容器 Label 中包含 app:test1、app:test2 的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即容器 Label 只要符合任一 Key-Value 对就会被列为采集范围。
- 启用容器 Label 白名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。 - 采集火山引擎弹性容器实例(VCI)时,容器 Label 白名单配置不会生效。
启用黑名单
容器 Label 黑名单用于指定不采集的容器范围,不启用黑名单时表示采集全部容器。
如果启用容器 Label 黑名单,则 Key 必选,Value 可选。- Value 为空,表示不采集所有在容器 Label 中包含 Key 的容器。
- Value 不为空,表示采集时只排除匹配键值对的容器,即只排除在容器 Label 中包含 Key、并且其值匹配 Value 的容器。 Value 支持正则匹配,例如设置 Key 为 app,设置 Value 为
^(test1|test2)$,表示不采集在容器 Label 中包含 app:test1、app:test2 的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即容器 Label 只要符合任一键值对,就会被排除出采集范围。
- 启用容器 Label 黑名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。 - 采集火山引擎弹性容器实例(VCI)时,容器 Label 黑名单配置不会生效。
容器环境变量
启用白名单
容器环境变量白名单通过容器环境变量指定待采集的容器,不启用白名单时表示指定采集全部容器。
启用容器环境变量的白名单时,需要填写键值对。其中 Key 必选,Value 可选。- Value 为空:采集所有在容器环境变量中包含 Key 的容器。
- Value 不为空:只采集在容器环境变量中包含 Key 并且其值匹配 Value 的容器。 Value 支持正则匹配。例如设置 Key 为 module,设置 Value 为
^(tcp|udp)$,表示只采集在容器环境变量中包含 module:tcp、module:udp的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即容器环境变量只要符合任一 Key-Value 对就会被列为采集范围。
- 启用容器环境变量白名单时,Key 不能重复。
启用黑名单
容器环境变量黑名单用于指定不采集的容器范围,不启用黑名单时表示采集全部容器。
如果启用容器环境变量黑名单,则 Key 必选,Value 可选。- Value 为空,表示不采集所有在容器环境变量中包含 Key 的容器。
- Value 不为空,表示采集时只排除匹配键值对的容器,即只排除在容器环境变量中包含 Key、并且其值匹配 Value 的容器。 Value 支持正则匹配,例如设置 Key 为 module,设置 Value 为
^(tcp|udp)$,表示不采集在容器环境变量中包含 module:tcp、module:udp的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即容器环境变量只要符合任一键值对,就会被排除出采集范围。
- 启用容器环境变量黑名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。
容器环境变量日志标签
是否将环境变量作为日志标签,添加到原始日志数据中。开启后,日志服务将在日志中新增容器环境变量相关字段,设置多个键值对时,表示添加多个字段。
例如设置 Key 为 source,设置 Value 为 data_source,假设容器包含环境变量source=DC,那么将在日志中新增字段__tag__data_source__: DC。(可选)启用K8s 采集规则。
K8s 采集规则用通过 Kubernetes 容器的信息指定待采集的内容,也可以同时排除不采集的内容。说明
未启用通用容器采集规则和K8s 采集规则时,表示采集范围为全部容器。同时配置两种采集规则时,两种规则的逻辑关系为与,即必须同时满足两种规则才能成功采集。
配置
说明
Namespace名称
待采集的 Kubernetes Namespace 名称,不指定 Namespace 名称时表示采集全部容器。
Namespace 名称支持正则匹配。例如设置 Namespace 名称为^(tcp|udp)$,表示采集tcp命名空间、udp命名空间下面的所有容器。工作负载类型
通过工作负载的类型指定采集的容器,仅支持选择一种类型。未指定类型时,表示采集全部类型的容器。
支持的工作负载类型如下:- Deployment:无状态负载
- StatefulSet:有状态负载
- DaemonSet:守护进程
- Job:任务
- CronJob:定时任务
工作负载名称
通过工作负载的名称指定待采集的容器。未指定工作负载名称时,表示采集全部容器。
工作负载名称支持正则匹配。例如设置工作负载名称为^(http.*)$,表示采集以 http 开头的工作负载下面的所有容器。Pod Label
启用白名单
Pod Label 白名单用于指定待采集的容器。未开启 Pod Label 白名单时,表示采集全部容器。
如果需要设置 Pod Label 白名单,则 Key 必填:- Value 为空,表示采集所有在 Pod Label 中包含 Key 的容器。
- Value 不为空,表示只采集在 Pod Label 中包含 Key 并且其值匹配 Value 的容器,支持正则匹配。 Value 支持正则匹配,例如设置 Key 为 module,设置 Value 为
^(tcp|udp)$,表示只采集在 Pod Label 中包含 module:tcp、module:udp的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即 Pod Label 只要符合任一键值对,就会被列为采集范围。
- 启用 Pod Label 白名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。
启用黑名单
通过 Pod Label 黑名单指定不采集的容器,不启用表示采集全部容器。
如果需要设置 Pod Label 黑名单,则 Key 必填,Value 选填。- Value 为空,表示采集时排除所有在 Pod Label 中包含 Key 的容器。
- Value 不为空,表示采集时只排除在 Pod Label 中包含 Key 并且其值匹配 Value 的容器。 Value 支持正则匹配,例如设置 Key 为 module,设置 Value 为
^(tcp|udp)$,表示不采集在 Pod Label 中包含 module:tcp、module:udp的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即 Pod Label 只要符合任一键值对,就会被排除出采集范围。
- 启用 Pod Label 黑名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以http开头的字符。
Pod Annotation
启动白名单
Pod Annotation 白名单用于指定待采集的容器。
如果需要设置 Pod Annotation 白名单,则 Key 必填,Value 选填。- Value 为空,表示 Pod Annotation 中包含 Key 的 Pod 下的容器都匹配。
- Value 不为空,表示 Pod Annotation 中包含 Key 并且其值匹配 Value 的 Pod 下的容器才匹配。
Value 默认为字符串匹配,即只有 Value 和 Pod Annotation 的值完全相同才会匹配。如果该值以^开头并且以$结尾,则为正则匹配。例如设置 Key 为 app,设置 Value 为^(test1|test2)$,表示匹配 Pod Annotation 中包含app:test1、app:test2的 Pod 下的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即 Pod Annotation 只要符合任一键值对,就会被列为采集范围。
- 启用 Pod Annotation 白名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以 http 开头的字符。
启动黑名单
Pod Annotation 黑名单用于指定不采集的容器。
如果需要设置 Pod Annotation 黑名单,那么 Key 必填,Value 选填。- Value 为空,表示 Pod Annotation 中包含 Key 的 Pod 下的容器都被排除。
- Value 不为空,表示 Pod Annotation 中包含 Key 并且其值匹配 Value 的 Pod 下的容器才被排除。
Value 默认为字符串匹配,即只有 Value 和 Pod Annotation 的值完全相同才会匹配。如果该值以^开头并且以$结尾,则为正则匹配。例如设置 Key 为 app,设置 Value 为^(test1|test2)$,表示匹配 Pod Annotation 中包含app:test1、app:test2的Pod 下的容器。
说明
- 多个 Key-Value 对之间的逻辑关系为逻辑或,即 Pod Annotation 只要符合任一键值对,就会被排除出采集范围。
- 启用 Pod Annotation 黑名单时,Key 不能重复。
- 正则模糊匹配时,必须添加
.*。例如^(http.*)$,表示匹配以 http 开头的字符。
Pod 名称匹配规则
Pod 名称匹配规则用于指定待采集的容器。可选,不指定此项时,表示采集全部容器。
支持正则匹配,例如设置为^(http.*)$,表示采集以 http 开头的 Pod 下面的所有容器。启用全部 K8s Label 日志标签
是否将全部的 Kubernetes Label 作为日志标签,添加到原始日志数据中。开启后,日志服务将在日志中新增 Kubernetes Pod Label 全部字段。例如假设 Pod 包含 Label source=DC 和 destination=CS,那么将在日志中新增字段 tag__source: DC 和 tag__destination: CS。
K8s Label 日志标签
是否将 Kubernetes Label 作为日志标签,添加到原始日志数据中。开启后,日志服务将在日志中新增 Kubernetes Pod Label 相关字段。设置多个键值对时,表示添加多个字段。
例如设置 Key 为 source,设置 Value 为 data_source,假设 Pod 包含 Labelsource=DC,那么将在日志中新增字段__tag__data_source__: DC。K8s Annotation 日志标签
是否将 Kubernetes Annotation 作作为日志标签,添加到原始日志数据中。开启后,日志服务将在日志中新增 Kubernetes Pod Annotation 相关字段。设置多个键值对时,表示添加多个字段。
例如设置 Key 为 sink,设置 Value 为 data_sink,假设 Pod 包含 Annotationsink=ck,那么将在日志中新增字段__tag__data_sink__: ck。
配置日志格式
设置采集策略。
采集策略表示 LogCollector 采集增量日志还是全量日志。默认为增量日志。配置
说明
全量
LogCollector 从每个文件的起始位置开始采集日志,此时 LogCollector 会采集历史日志数据。
增量
LogCollector 采集日志时,只采集文件内新增的内容。监控范围内的日志文件写入新的日志时,触发 LogCollector 日志采集行为。
- 对于首次采集的日志文件,LogCollector 会根据您指定的增量阈值,自动确认采集的位置。
- 如果新文件大小不超过您所指定的增量阈值,从新文件的起始位置开始首次采集。
- 如果新文件大小超过您所指定的增量阈值,从新文件的末尾减去增量阈值后的位置开始首次采集,即仅采集增量日志。
- 对于非首次采集的日志文件,LogCollector 会根据 Checkpoint 确定采集位置,继续采集。
- 对于首次采集的日志文件,LogCollector 会根据您指定的增量阈值,自动确认采集的位置。
指定采集模式。
采集模式决定了 LogCollector 解析日志文件的模式,您可以根据实际业务场景选择对应的采集模式,并配置指定模式下的日志解析规则。详细说明请参考各个采集模式文档中的步骤 6. 指定采集模式部分。设置时间字段。
采集时间点:将采集日志时 LogCollector 所在服务器的系统时间作为日志时间戳。
自定义时间:提取原始日志中自带的时间作为日志时间戳。相关配置如下:
配置
说明
时间键名称
时间字段的名称。
时间正则
如果您只解析时间字段中的部分内容,可使用正则表达式进行提取。
时间精度
勾选启用纳秒时间精度后,支持提取纳秒精度的时间。详细说明,请参考启用 LogCollector 高精度时间。
时间转换格式
根据提取到的时间内容,设置时间转换格式。例如时间为
01/March/2024 20:15:02,则可配置时间转换格式为%d/%b/%Y:%H:%M:%S。详细的格式说明请参考时间格式。说明
- 如果时间转换格式填写错误导致无法正确解析时间,将以采集时间为准。
- 默认情况下,日志时间支持精确到毫秒,即配置时间转换格式时,支持配置到毫秒。如果时间转换格式中未指定毫秒级的解析方式,则毫秒部分会自动填充为 0。
- 在采集配置中勾选启用纳秒时间精度后,日志转换格式支持到纳秒级别。
- 如果您需要在日志时间中添加时区且原始日志时间包含时区,那么您可以在时间转换格式中添加时区格式(%z)以提取时区。另外,您也可以在时间转换格式中添加固定时区格式(+08:00),然后选择合适的时区属性。
例如时间为2024-03-03 15:00:00 +08:00,您可以设置时间转换格式为%Y-%m-%d %H:%M:%S %z,或者设置时间转换格式为%Y-%m-%d %H:%M:%S +08:00且选择对应的时区属性。
时区属性
设置时区。
- 机器时区:使用 LogCollector 所在服务器的系统时区。
- 自定义时区:包括 UTC 和 GMT。如果要支持夏令时或冬令时,请选择 UTC;否则,请选择 GMT。
时间字段样例
输入原始日志中的时间内容,单击立即验证,日志服务将验证您所配置的时间转换格式是否正确。
选择是否忽略未更新的文件。
开启后,当日志文件更新时间不在您所指定的时间范围内时,LogCollector 会忽略该文件,不进行采集。
配置插件
启用插件配置。
通过 LogCollector 采集文本日志时,如果业务日志结构复杂、格式不固定,无法通过 JSON 模式等常规的日志采集模式进行解析时,可以通过 LogCollector 插件进行采集后处理。详细说明请参考插件概述。
高级设置
(可选)启用高级设置。
请根据您的需求选择高级配置。如果没有特殊需求,建议保持默认配置。配置
说明
过滤器
是否开启日志字段过滤规则。默认为关闭状态。开启后,通过正则表达式配置过滤规则,完全匹配正则表达式的日志才会被采集上报,帮助您筛选出有价值的日志数据。
例如,设置 Key 为response_code,过滤规则为400|500,表示只采集response_code为 400 或 500 类型的日志。上传解析失败日志
是否上传解析失败的日志,默认为关闭状态。
- 开启:所有解析失败的日志,均以指定字段作为键名称(Key),原始日志内容作为值(Value)上传到日志服务。其中键名称可以通过失败日志键名称指定,默认为
LogParseFailed。 - 关闭:解析失败的日志不上传到日志服务。

上传hostname字段
是否上传 hostname 字段,默认为关闭状态。
- 开启:在原始日志中增加一个字段,用于记录日志源的 hostname。字段名可以通过 hostname键名称指定,默认为
hostname。 - 关闭:不添加
hostname字段。
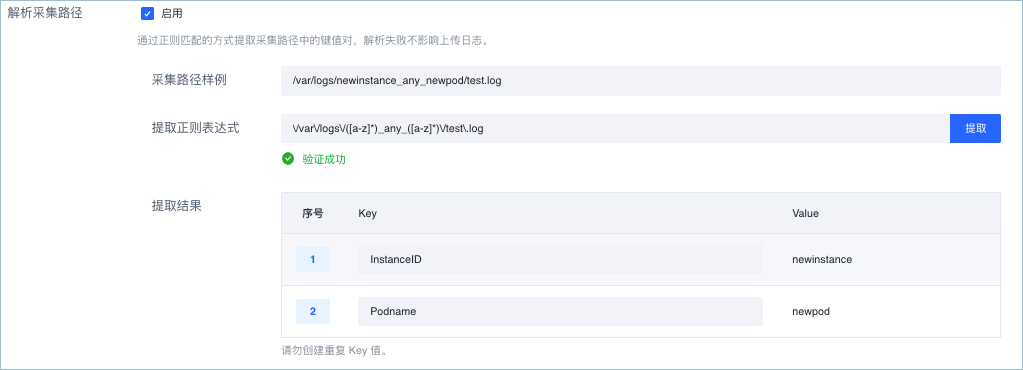
解析采集路径
通过正则表达式提取采集路径中的字段,并将其作为元数据添加到日志数据中。此功能默认为关闭状态。
开启此功能后,您需要设置采集路径样例、提取正则表达式和提取结果。- 采集路径样例:实际场景的采集路径样例。
- 采集路径样例必须是一个绝对路径。
- 路径样例中不能包含通配符
*、?、**。
- 提取正则表达式:用于提取路径字段的正则表达式。必须和采集路径样例匹配,否则无法成功提取。
- 提取结果:提取结果中展示日志服务根据正则表达式将路径样例解析并提取到的每个字段值(Value)。您需要为每个字段指定字段名称(Key)。
- 最多配置 100 个字段名。
- 字段名不可为空,且不可重复。
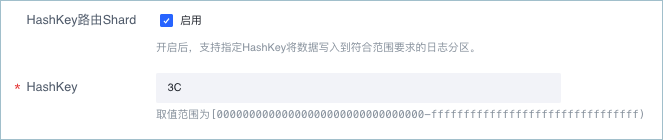
HashKey路由Shard
指定 HashKey 将数据写入到符合范围要求的日志分区。此功能默认为关闭状态。
- 开启此功能,表示使用 HashKey 路由 Shard 模式采集数据,将数据有序写入到指定 Shard 中。适用于数据写入和消费对有序性要求较高的场景。 此时需要设置 HashKey,日志服务会将数据写入到包含该 Key 值的 Shard 中。HashKey 的取值范围为 [00000000000000000000000000000000-ffffffffffffffffffffffffffffffff)。
- 关闭此功能,表示使用负载均衡模式采集数据,自动根据负载均衡原则将数据包写入当前可用的任一 Shard 中。该模式适用于写入和消费行为与 Shard 无关的场景,例如不保序。
上传原始日志
是否将原始日志作为一个字段上传到日志服务,默认为关闭状态。
- 开启:原始的日志数据将被封装在指定字段中,和解析后的日志数据一起上传到日志服务中。字段名可以通过原始日志键名称指定,默认值为
raw,实际对应的日志字段为__raw__。 - 关闭:不添加原始日志字段。
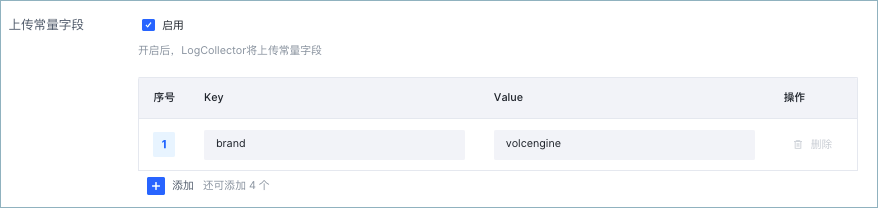
上传常量字段
开启后,LogCollector 会将指定字段的 Key 和 Value 封装到每一条日志中。常量字段需遵循以下限制:
- 支持上传最多 5 个常量字段。
- 字段名(Key)不可重复,不可为空。长度限制为 1~128 字符,包括英文字母、数字、和特殊字符(
-_./),且不能以下划线开头。 - 字段值(Value)不可为空,长度最大为 512 KiB。
上传机器组 Label
是否将机器组的 Label 信息上传到日志服务,默认为关闭状态。
- 开启:LogCollector 会将机器组的 Label 信息上传到指定字段中。您可以在机器组Label键名称中指定字段名称,默认值为
host_group_label。 - 关闭:不上传机器组 Label 信息。
允许文件多次采集
默认情况下,一个日志文件只能匹配一个采集配置,被采集到一个日志主题中。完成该配置后,可实现一个日志文件同时匹配多个采集配置。具体配置说明,请参考文件日志或标准输出同时被采集多份。
扩展配置
LogCollector 扩展配置,JSON 对象格式。目前支持的参数包括 CloseInactive、CloseRemoved、CloseRenamed、CloseEOF 和 CloseTimeout。详细的参数说明请参考CreateRule中的数据结构Advanced。
例如填写以下配置,表示日志文件持续 10 秒没有新日志写入、日志文件被移除或重命名、LogCollector 读取至文件末尾、日志文件监控时长超过 30 分钟后,释放文件句柄。
- 开启:所有解析失败的日志,均以指定字段作为键名称(Key),原始日志内容作为值(Value)上传到日志服务。其中键名称可以通过失败日志键名称指定,默认为
确认采集配置,并单击下一步。
步骤四 检查索引配置
- 检查索引配置。
根据页面提示,按需设置或更新索引,您也可以单击导入已有索引配置,导入其他日志主题的索引。- 若此日志主题未设置索引,可以参考配置索引进行设置。
- 若此日志主题已设置索引,可以根据采集规则中解析的日志字段判断是否需要更新索引。
- 单击完成:检查索引配置。
后续步骤
创建采集配置之后,LogCollector 会根据指定规则开始监听日志文件并采集日志。日志服务会将日志数据保存在指定的日志主题中,您可以在日志主题中执行检索分析操作。