导航
可视化数据集成
最近更新时间:2025.04.10 16:40:54首次发布时间:2025.04.10 16:40:54
说明
此功能为SaaS旗舰版功能,且默认关闭,如需使用需联系火山引擎技术支持人员进行开通。
一、概述
在企业进行数据采集时使用过其他厂商的埋点系统,不希望重复建设埋点体系,希望DataTester能够提供数据集成的方案,对历史数据资产直接复用。为了支持数据集成的需求, DataTester采用可视化数据集成的方式支持Kafka消息订阅,通过创建并执行数据集成任务,将其他厂的UBA数据上报至火山DataTester数据服务。
- 创建数据集成任务
- 通过输入Kafka服务器、topic等信息,进行数据源的连接
- 将连接后的数据源内的元数据进行解析,支持客户通过数据映射配置进行字段映射
- 支持客户对任务配置时间/周期等进行配置
- 支持客户对任务设置任务告警
- 任务运维
- 在任务列表通过任务开关对任务进行启动/停止
- 通过任务日志可以查看数据任务的执行结果
- 任务明细&邮件可以查看单次告警明细
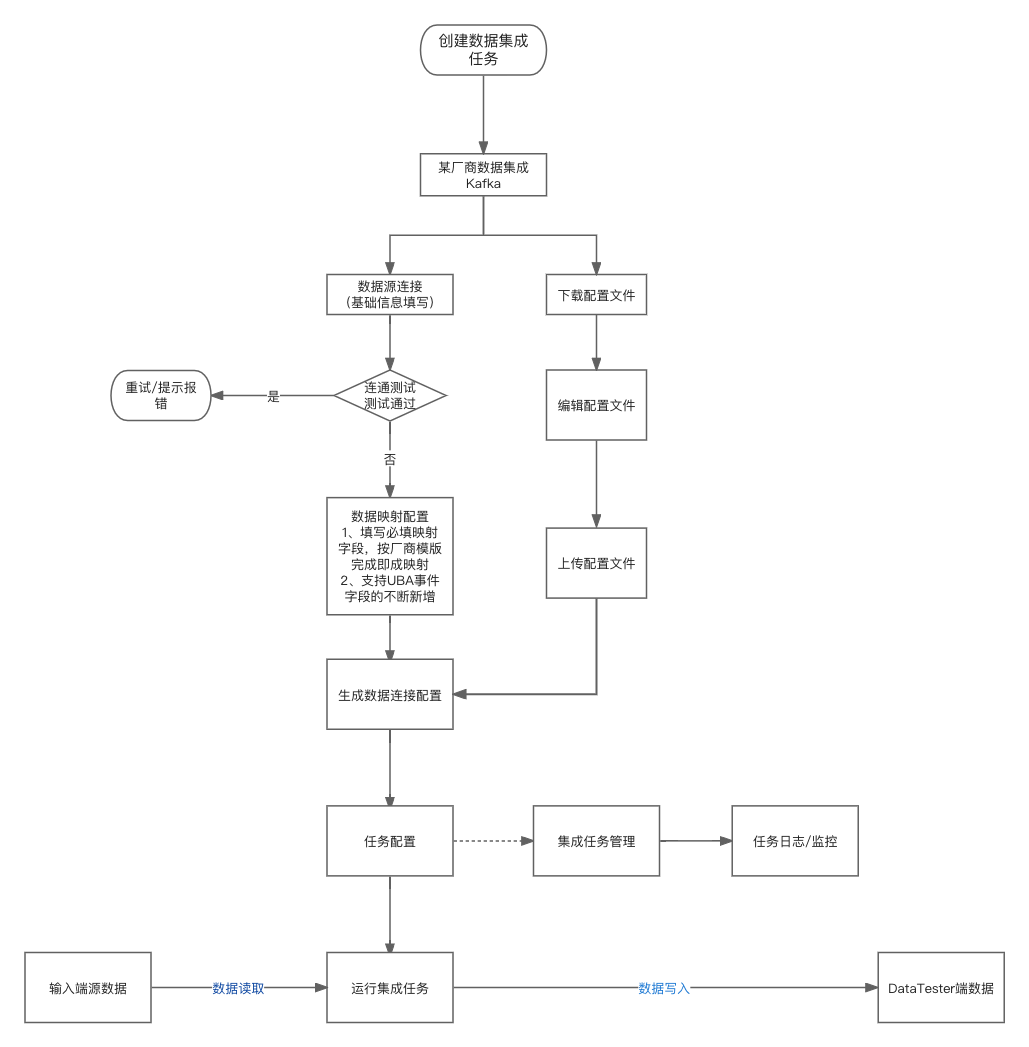
二、数据集成流程示例
- 流程示例:某厂商Kafka-UBA数据接入DataTester
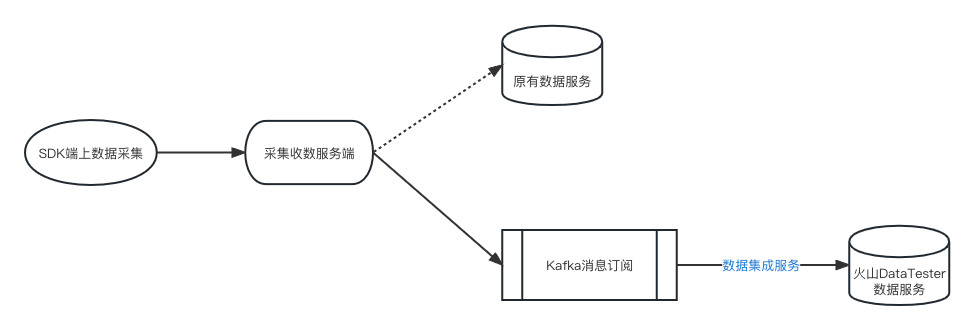
三、与客户平台交互方式说明
四、功能介绍
4.1 创建集成任务
DataTester提供两种方式进行数据集成,分别为可视化配置和自定义上传配置,两种方式带来的效果一致,二选一即可
4.1.1 可视化配置数据集成
1.基本信息
- 新建数据集成任务,需要定义数据集成任务的基本信息
- 选择需要同步的数据源类型:UBA数据、用户属性,并配置任务名称和任务描述。
2.数据源连接
- 新建数据集成任务时,需输入“提供数据源”的三方/客户的消费者组名称、kafka服务器地址、kafka Topic名称,进行数据源的连接测试
- 点击连接测试会尝试连接topic并读取最新一条数据填充示例
3. 元数据映射
数据源字段映射至Tester系统字段
4.任务配置
- 支持客户对任务配置时间/周期等进行配置
4.1.2自定义配置数据集成
1.自定义配置集成任务
- 选择自定义配置集成任务
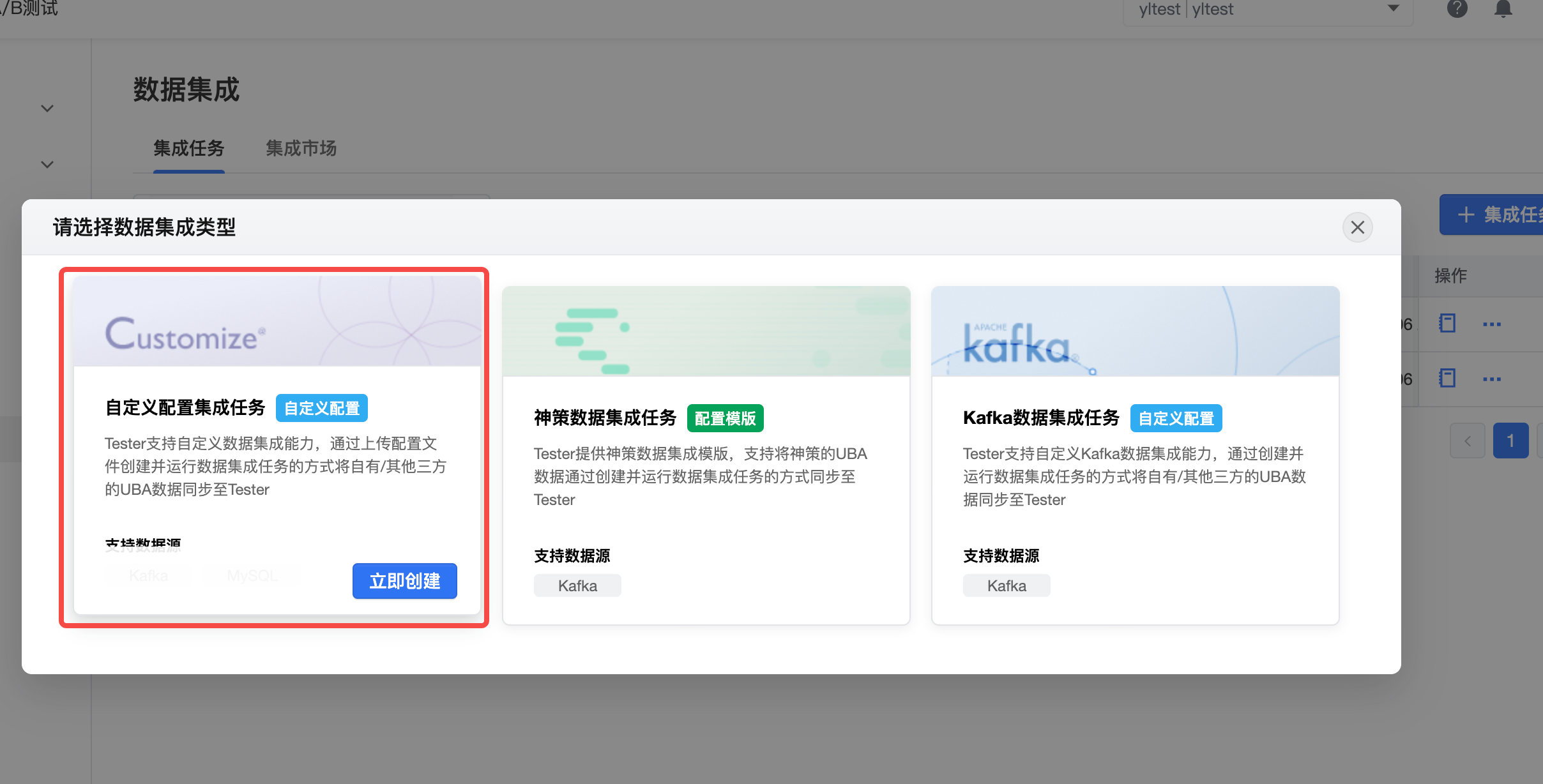
2.创建集成任务
- 上传配置
3.配置文件
具体文件格式可以联系火山技术支持人员
4.任务配置
4.2 任务运维
4.2.1 任务列表
- 任务列表
- 任务明细
4.3 数据应用
通过数据集成的同步的用户行为数据,可以在Datatester后台【数据管理】页面进行查看,并可使用该部分事件创建事件指标,示例如下: