ByteHouse 企业版
ByteHouse 企业版






- 文档首页
 ByteHouse 企业版用户指南数据导入/导出流式导入
ByteHouse 企业版用户指南数据导入/导出流式导入

ByteHouse 企业版支持通过 Kafka 进行实时数据写入。本文介绍了如何使用 ByteHouse 企业版控制台进行 Kafka 流式导入。
相比通过引擎插入(INSERT)数据,ByteHouse 企业版控制台的 Kafka 流式导入功能具有以下特点:
- 支持 at-least-once 语义,可自动切换主备写入,稳定高可用。
- 数据根据 Kafka 分区(Partition)自动均衡导入到 ByteHouse 分片(Shard),无需配置分片键。
- 默认数据消费 8 秒后可见。兼顾了消费性能和实时性。
更多实现原理请参考 HaKafka 引擎文档。
- 将 Kafka 数据导入到 ByteHouse 前,请确保您使用的 Kafka 账号密码拥有以下数据权限:
- 列出主题(Topics)
- 列出消费者组(Consumer group)
- 消费消息(Consume message)
- 创建消费者以及消费者组(Consumers & Consumer groups)
- 获取 Kafka 数据源代理列表 IP 地址、用户名、密码。如果您需要通过私网访问火山引擎消息队列 Kafka 版,还需获取 Kafka 数据源所在的 VPC ID。
- 在 ByteHouse 中根据源表结构创建好目标库和表,详情请参考新建数据库/表。
- 将数据从 Kafka 数据源导入至 ByteHouse 时,如果您使用公网访问,将会产生相关费用。建议您在使用前详细了解您使用服务的计费规则。
- 推荐使用私网访问火山引擎消息队列 Kafka 版或者火山引擎云原生消息引擎 BMQ 服务。使用时需确保您使用的服务与 ByteHouse 实例处于相同地域,以保障数据传输效率并避免跨地域访问产生额外费用。
如果您使用的是火山引擎云原生消息引擎 BMQ,需在 BMQ 控制台完成以下配置操作:
- 通过私网访问 BMQ 时,需在 BMQ 中添加接入点。BMQ 的默认接入点与 ByteHouse 间的网络不通,需新建接入点,操作详情请参考添加私网接入点。如果您有特殊网络需求,请提交工单或联系 ByteHouse 团队处理。
- 在 BMQ 中创建 Consumer Group 并记录该名称,用于新建导入任务时填写对应的参数。BMQ 平台创建 Consumer Group 的操作文档请参考创建 Group。
创建数据源
- 登录 ByteHouse 企业版控制台,单击数据导入,在右上角选择对应集群。
- 单击数据源模块中的“+”,新建数据源,数据源类型选择为 Kafka。
配置数据源
在右侧数据源配置界面,根据界面提示,依次输入以下信息:
参数项
配置说明
源类型
选择 Kafka 数据源类型。
源名称
任务名称,和其他任务不能重名。
Kafka 代理列表
填写对应的 Kafka Broker 地址。填写时,请务必填写您使用的接入点所有 Broker 节点的 IP 地址。如果需要填写多个 Broker 地址,请用逗号(,)进行分割。如
10.100.19.127:9092,10.100.19.128:9092。
如果您使用的是火山引擎 BMQ,请使用在准备工作中添加的接入点,请勿使用默认接入点,否则网络无法联通,详情请参考准备工作。身份验证模式
当前 Kafka 数据源支持四种鉴权模式,包括 NONE 无鉴权、PLAIN、SCRAM-SHA-256、SCRAM-SHA-512,并支持 SSL 加密,您可根据 Kafka 代理列表 IP 地址的端口号勾选,对应关系如下:
- None 无鉴权:端口号为 9092。
- PLAIN、SCRAM-SHA-256、SCRAM-SHA-512:
- 如果未开启 SSL:端口号为 9093。
- 如果开启 SSL:端口号为 9095。
安全协议
支持选择 SASL_PLAINTEXT、SASL_SSL 协议类型。
用户名、密码
填写有权限访问 Kafka 实例的用户名和密码信息。
数据源信息填写完成后,单击确定按钮,进行数据源连通性测试,连通成功后,即代表数据源创建成功。
新建导入任务
在 Kafka 数据源下,单击新建导入任务,进入新建导入任务配置界面,并完成以下信息配置:
参数
说明
通用信息
任务名称
填写导入任务名称信息,支持数字、字母及下划线,不能以数字开头,最多仅支持 128 字符,且不能和现有任务重名。
描述
输入该导入任务相关描述信息,方便后续维护管理。
选择数据源
源类型
选择 Kafka 数据源类型。
数据源
下拉选择已创建成功的 Kafka 数据源。
若没有符合要求的数据源,您可单击新建数据源按钮,前往新建数据源。Topic
下拉选择 Kafka 数据源中的已有的 Topic 信息。
Group 名称
Kafka Consumer Group 名称。非必填,若不填则系统自动生成 Group 名称。
如果您使用的是火山引擎云原生消息引擎 BMQ,需要手动填写在准备工作环节创建的 Consumer Group 名称,详情请参考准备工作。自动重设 Offset
指初次启动任务时,Kafka 最新生产的数据开始消费的 offset,第二次启动任务时,会从上次消费暂停的 offset 恢复。
格式
消息格式,目前最常用 JSONEachRow。
分隔符
输入消息分隔符,一般使用 '\n'。
消费者个数
消费者个数,每个消费者会创建一个线程。
写入 Block Size
写入的 block_size 大小。
选择目标表
目标数据库
下拉选择数据导入的目标 ByteHouse 数据库。
目标数据表
下拉选择数据导入的目标 ByteHouse 表。
目标 Schema 配置
提取 Schema
此处配置 Kafka 中的信息和 ByteHouse 表信息的映射,建议使用“数据映射”功能,通过 JSON 或 SQL 方式,抽样提取 Kafka 消息进行自动匹配,字段映射新增方式,您可选择覆盖添加和增量添加方式,匹配需要符合以下规则:
- 源列必须和目标列属于同类型,ByteHouse 不支持隐式转化类型。若类型不匹配,可通过“表达式”进行转化,例如源列为
a,Integer 类型,目标列为 String 类型,则需要在表达式中输入toString(a)。常见的类型转换函数可以参考类型转换函数。 - 目标列中不可为空的列必须有源列匹配。可勾选可为空的目标列,对其进行批量删除。
- 源列必须和目标列属于同类型,ByteHouse 不支持隐式转化类型。若类型不匹配,可通过“表达式”进行转化,例如源列为
所有源列和目标列都完成匹配后,单击页面右下角的提交按钮。提交后,就可以在数据导入对应的数据源下看到新的导入任务。任务创建完成后,会直接开始 Kafka 消费任务。
单击导入任务名称,可以看到当前导入任务的执行情况,信息包括:任务执行 ID、开始时间、时长、导入记录数等信息。
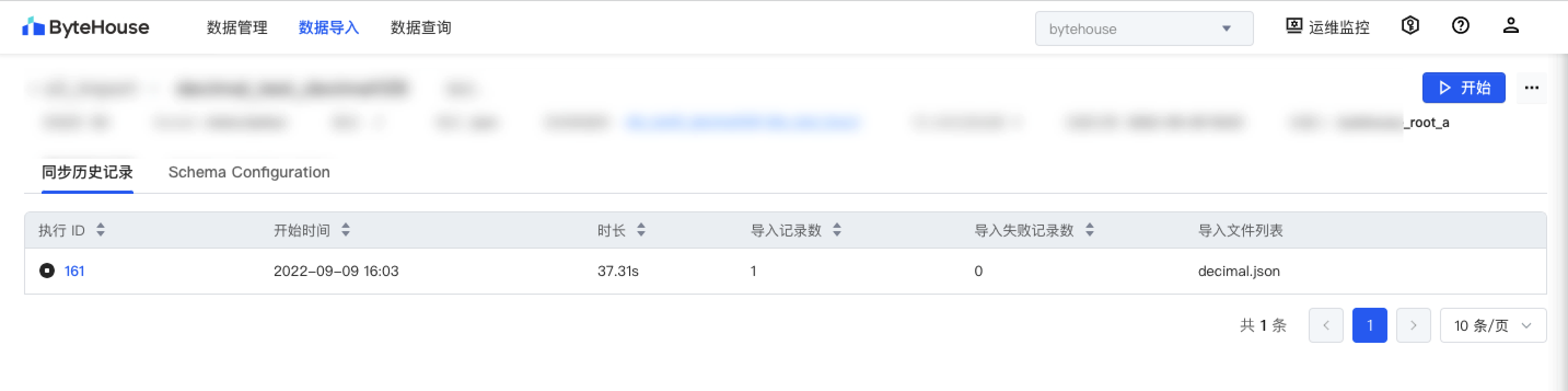
查看执行计划
导入任务创建完成后,您可在执行计划中,看到所有导入任务的具体执行情况。您可单击执行 ID,查看某个任务的执行详情。
在数据导入界面下,单击左侧执行计划按钮,进入到执行计划列表,您可根据以下筛选项,进行执行计划筛选:
- 您可通过输入任务名称或执行计划 ID,来搜索对应的执行计划。
- 您也可通过导入任务状态、时间范围、目标数据表、源类型等信息,下拉选择相应的内容,来快速筛选执行计划。