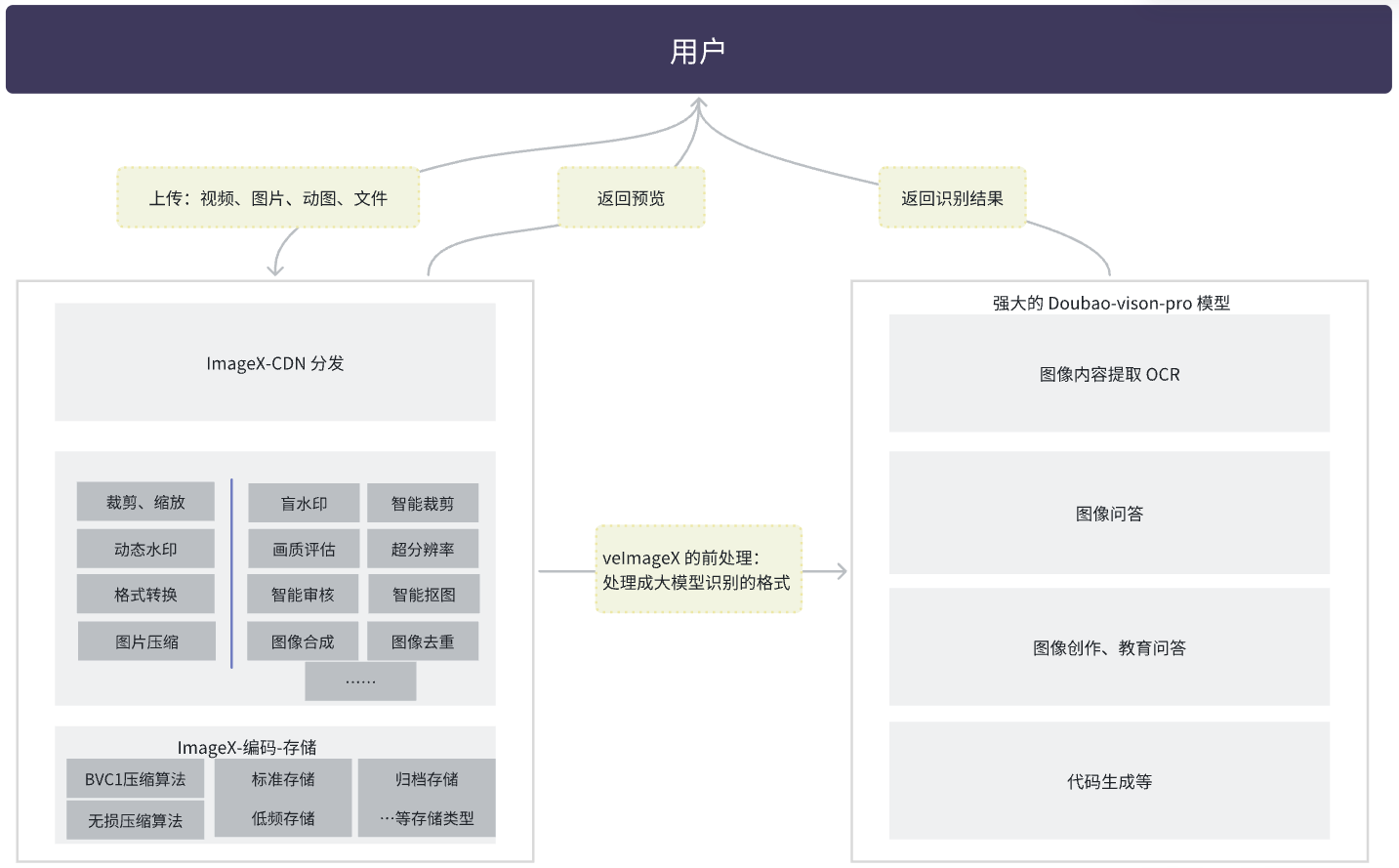
借助豆包视觉理解大模型,您可以使用上传 SDK 将图片、视频上传到 veImageX 的同时,让 AI 对图片内容进行理解和识别。从而实现图像内容提取、图像内容问答、数学题解答等效果。
说明
视觉理解模型仅能理解图片或视频中的视觉信息,如需使用 AI 生成图片,请参考 veImageX-豆包智能生图最佳实践。
视觉理解模型本质上仅能对图片内容进行理解,如果您上传的是视频,那么您需要先在 veImageX 配置视频截帧模板,获取截帧后的静图。接着,再由视觉理解模型对静图内容进行理解。
背景说明
视觉理解大模型是火山方舟推出的可以理解图片内视觉信息,并结合这些信息完成如描述图片等图片相关任务的 AI 模型。
该模型整体具备强大的综合能力,能够应用于图片理解领域中的大部分场景,从基础的图片文字识别,到复杂的数学问题,都具有不错的表现。
| 场景 | 场景细分 | 描述 |
|---|---|---|
图像内容抽取(OCR) | 纯文本图像的文字抽取 | 模型能够实现各类包含文本图片的文字内容抽取,如:密集文本图片、文档截图等,并支持格式化输出文本内容 |
| 日常图像的文字抽取 | 对日常手机拍摄的图片中,包含的文本文字抽取,如:菜单、路标、证件等 | |
| 表格图像的内容抽取 | 模型能够识别图表、表格类型图片的文字、数字等内容读取,并支持格式化输出文本内容 | |
图像问答 | 图片描述 | 描述图片中的内容,包括详细描述、简短描述以及为图像分类 |
| 图像内容提问 | 对图片中包含的内容进行提问 | |
| 图像创作 | 根据图像内容,创作文案、标题等,如:点评、小红书文案、朋友圈文案等 | |
| 教育 | 数学题目解答 | 分析题目、考点说明、解题思路、解题结果 |
| 数学题目批改 | 对数学题目的回答批改, | |
| 代码生成 | 前端页面 | 根据图片引导,绘制前端页面 |
| 图表绘制 | 根据图片引导,绘制图表。 | |
不过,该模型明确不具备【图像生成】能力,在实际使用中可能存在如下几个问题,然后寻求方案解决:
支持传入的图片格式有限。比如用户 iOS 拍的照片可能是 heic 格式等,不容易很好的解决;
传入的文件大小有限制,需要在本地机器做一下压缩才能去做,因此寻求云端现成的方案;
base64 会增大传输的流量;
视频场景下如何支持;
图片缩放后,可以支持更多的处理张数,综合节省成本。
因此,我们考虑解除大模型的封印,通过接入 veImageX 服务来实现对大模型能力限制,增加前置处理,支持更多能力。
组合方案
根据现有的能力,我们可以如下方式来桥接思路。
说明
veImageX 产品当前功能的使用限制详见注意与使用限制。
| 类型 | 输出 | 用户原始素材输入 |
|---|---|---|
输出格式支持 | jpeg、png、webp等 | 视频资源:几乎所有 ffpeg 视频格式,推荐 H.264、H.265。
|
| 基础能力 | 支持存储、分发、图像处理 | - |
| 限制体积输出 | 支持限制体积输出 | 单文件最大支持 4GB。图片文件处理支持 35MB,可扩增。 |
| 分辨率支持 | 支持限制最大分辨率 | 最大 4 亿像素 |
| 上传支持 | 多端 SDK | 支持 Web、Android、iOS、服务端各种 SDK 接入。 |
| 上传数量 | 不限制 | 不限制 |
| 计费模式 | 详见计费说明,其中图像处理计费项提供了 20TB 免费处理量。 | - |
优势说明
| 类型 | 使用豆包视觉理解大模型 | 巧用 veImageX 方案 |
|---|---|---|
提升部分限制 |
|
|
| 压缩方式 | 引入开源组件,自行实现压缩 | 专有图像处理服务 |
| 算力 | 消耗本地算力 | 云端算力,专有芯片 |
| 性能 | - | 相比 Base64 方案,传输数据较小 |
费用成本 | 刊例价
| 刊例价
|
复杂性 | 本地调试,调试稍微方便 | 控制台配置,一次配置,永久生效。 |
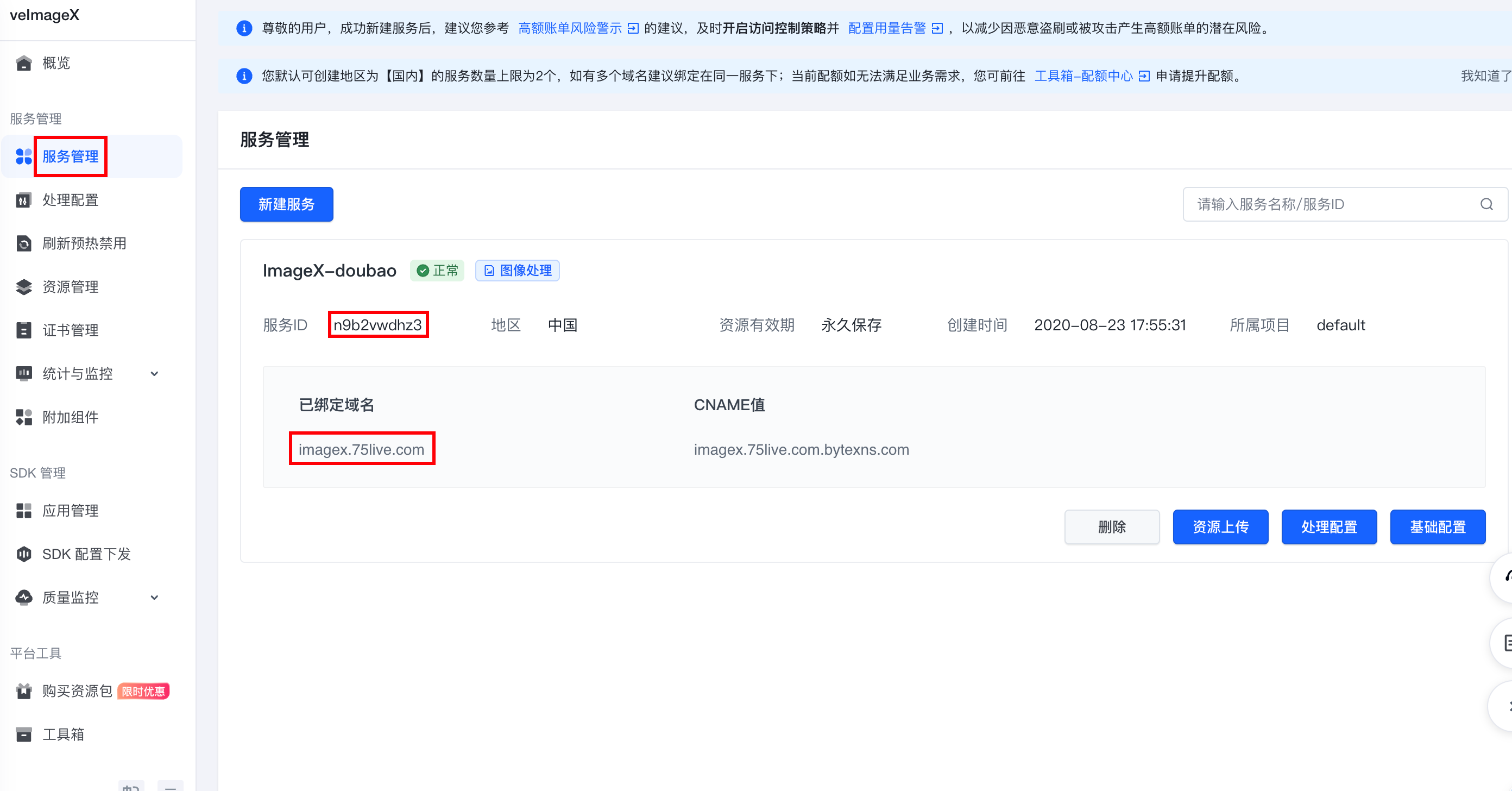
操作准备
| veImageX 侧配置 | 火山方舟侧配置 | ||
|---|---|---|---|
| 服务管理 | 处理配置 | 开通管理 | 在线推理 |
| 根据原始资源类型创建图片处理模板,获取模板配置,如 |
| |
 | 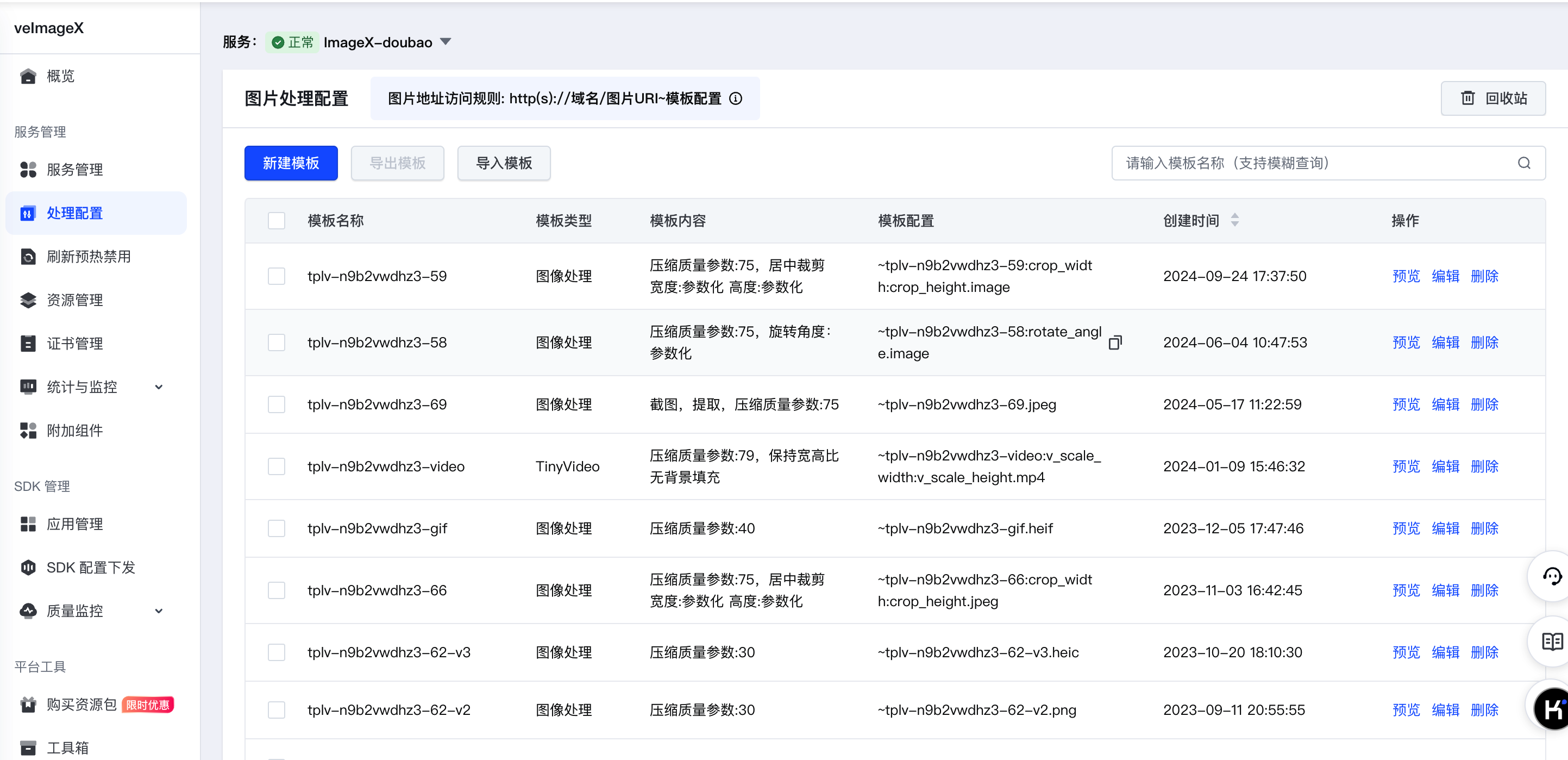 | 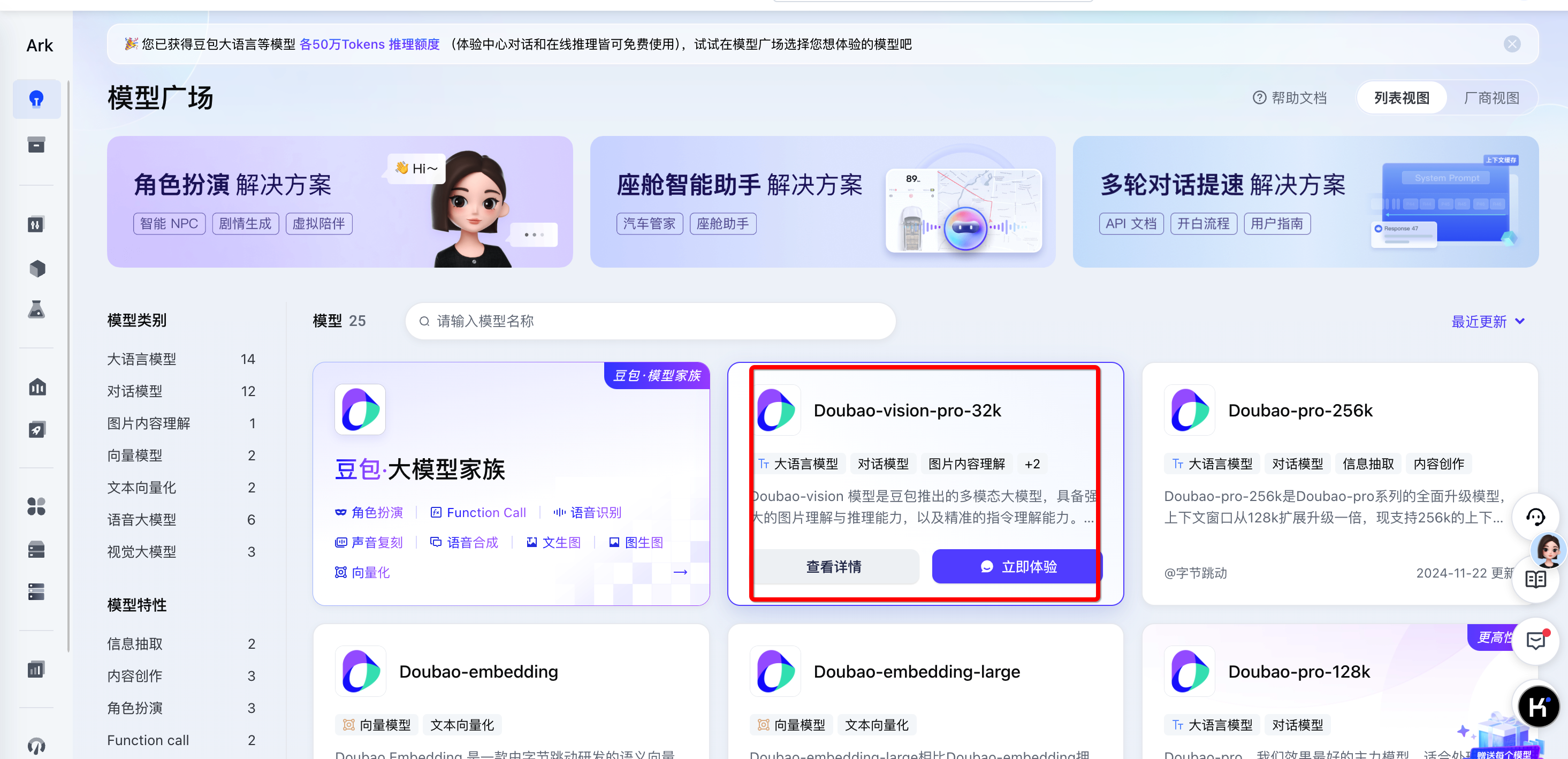 | 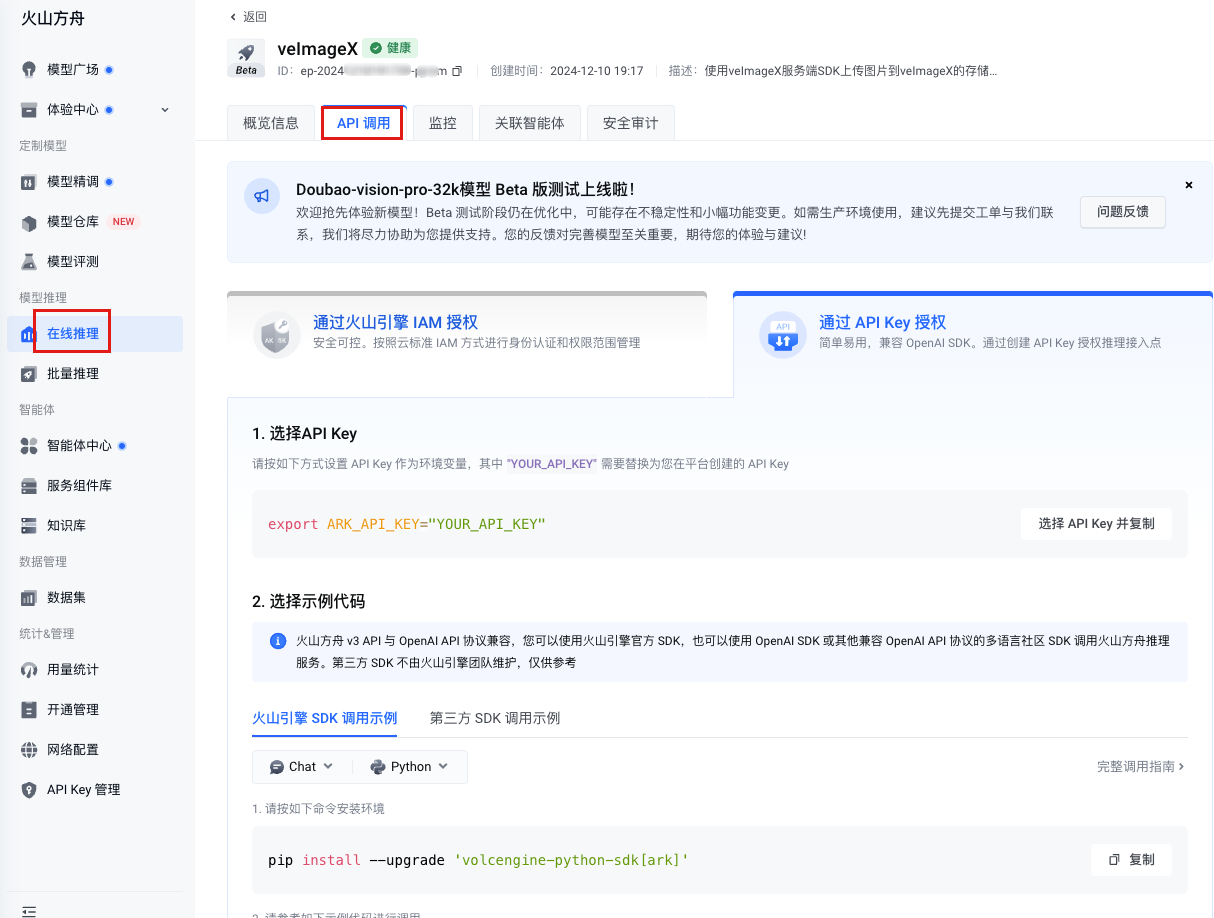 |
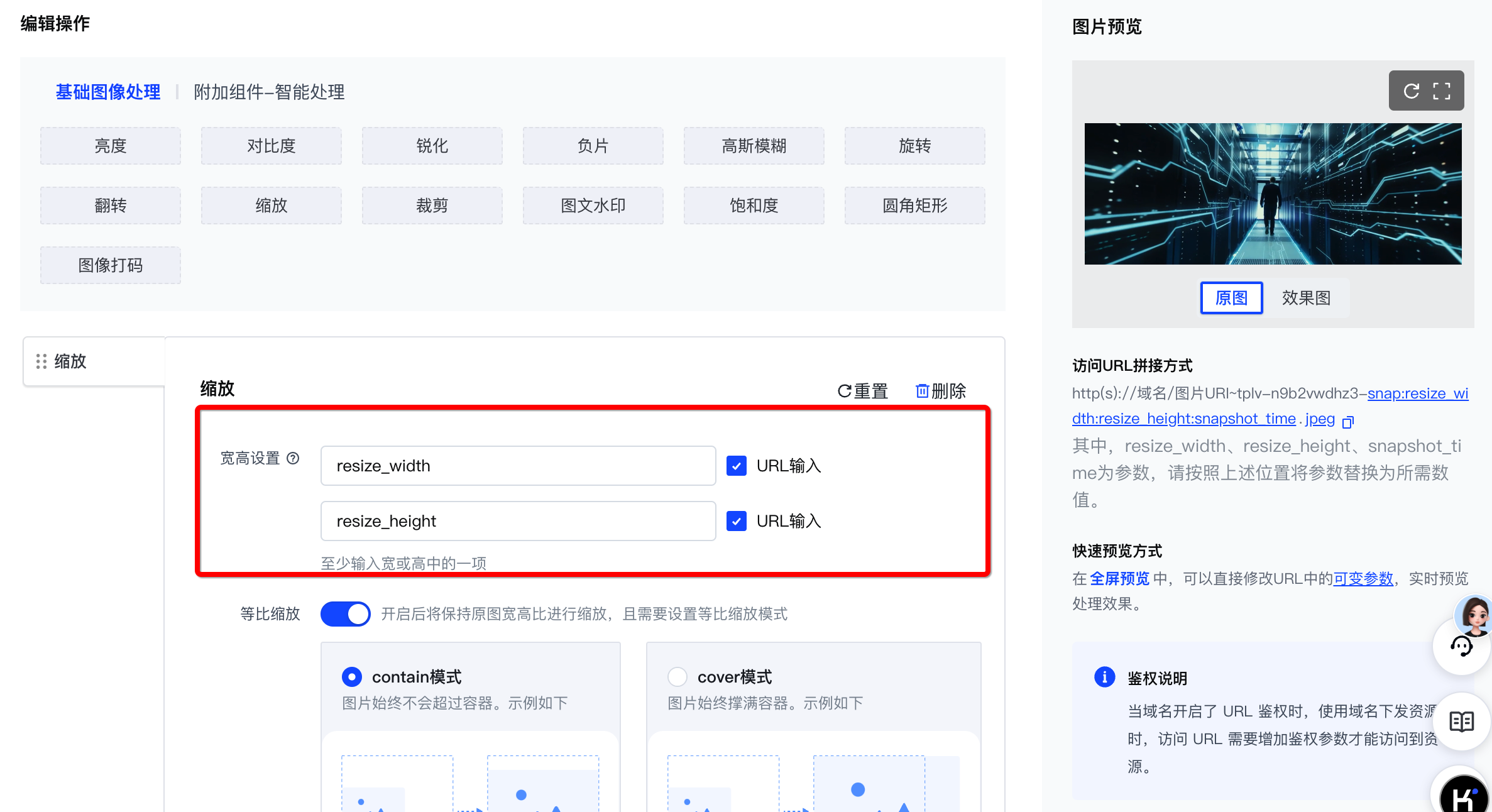
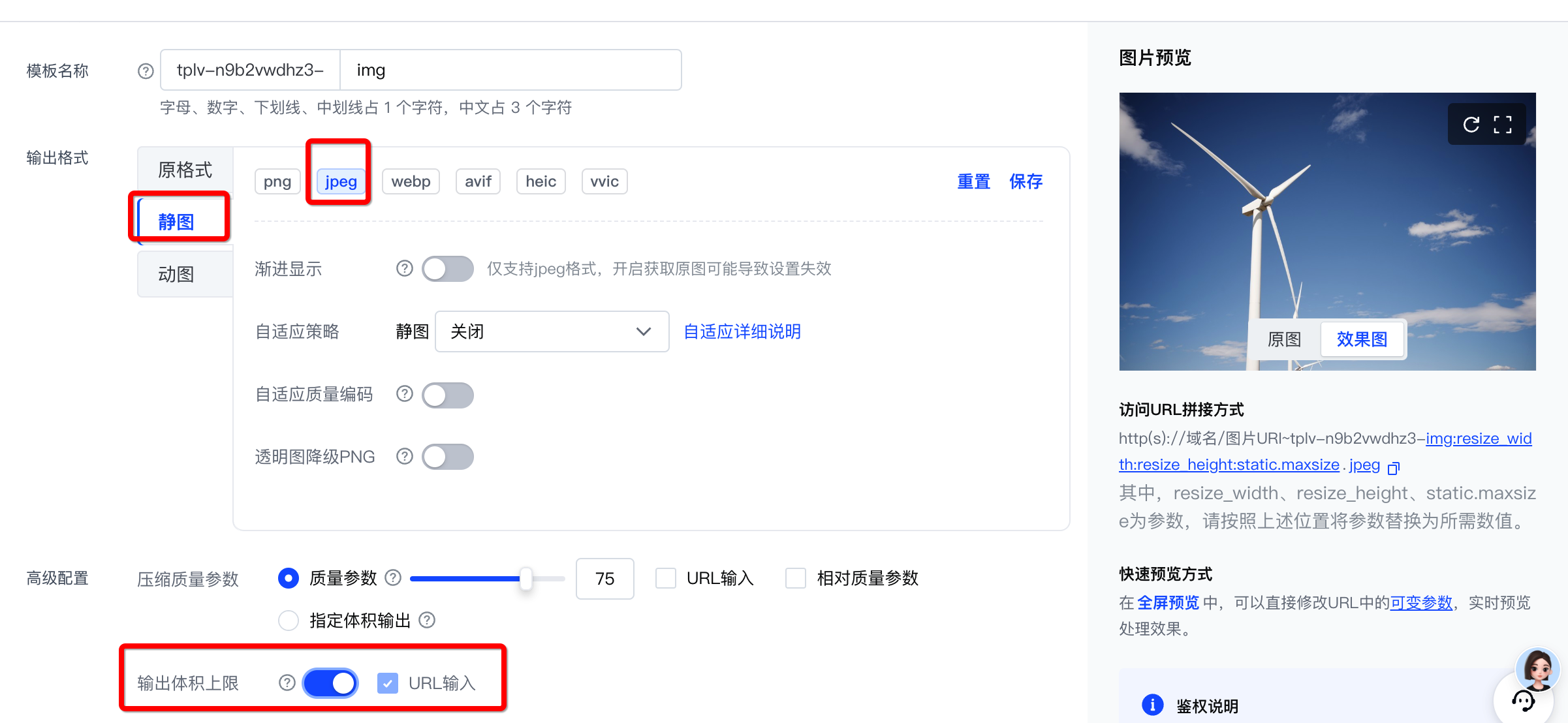
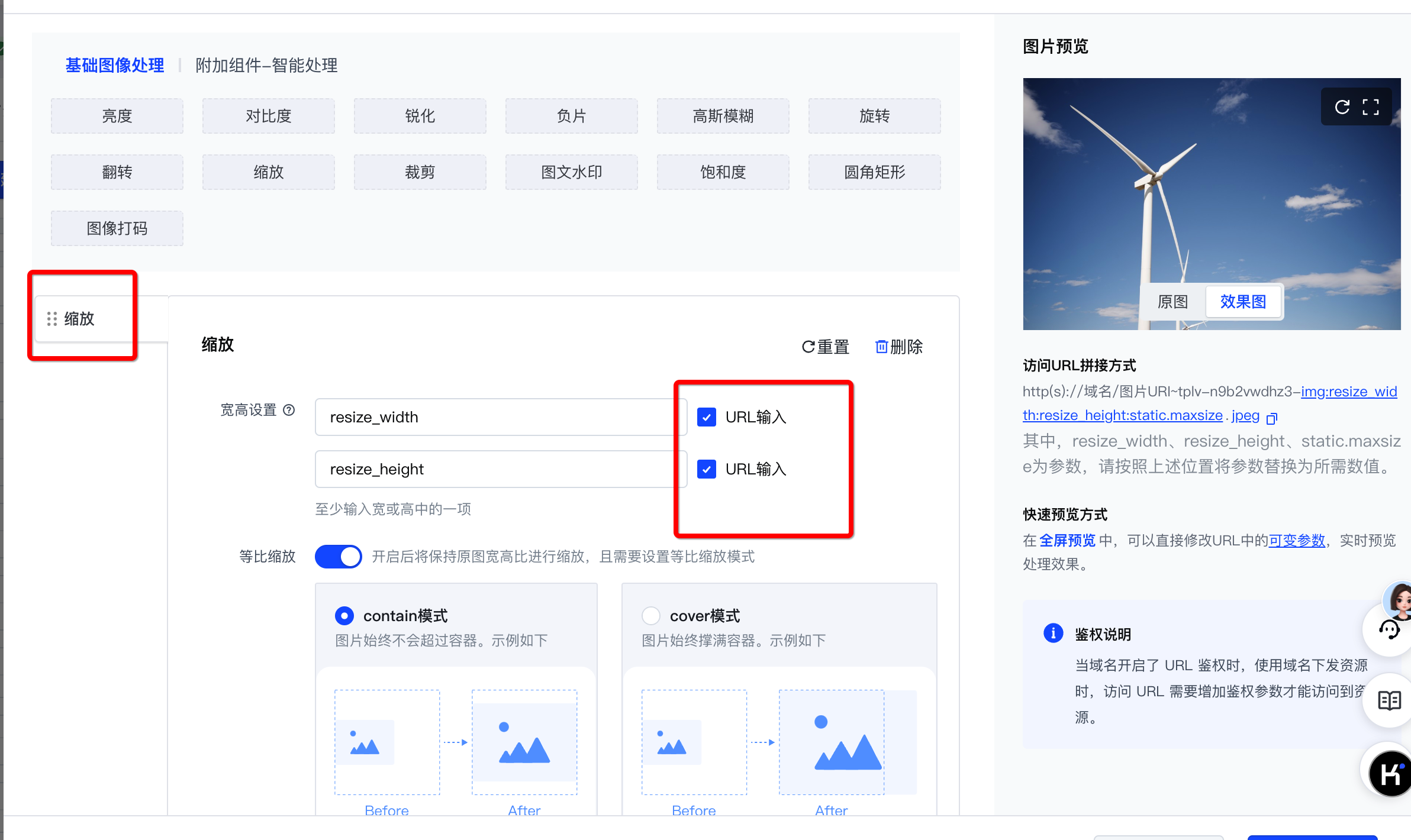
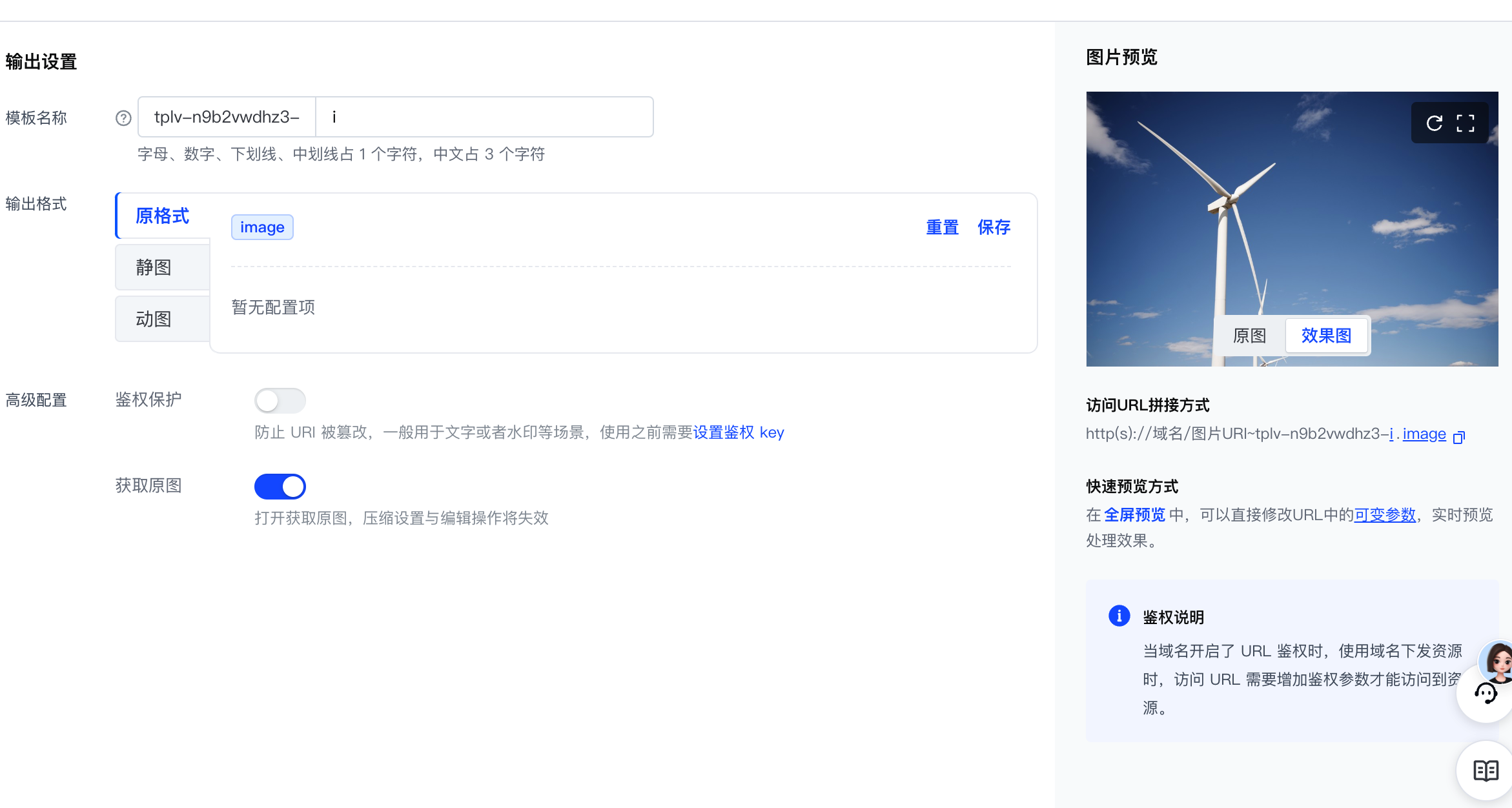
根据您需要处理的资源类型以及输出的图片要求,您需要创建含有对应配置的处理模板。具体如下所示。
| 针对视频/动图类文件 | 针对静图文件 | 针对其他类型源文件 |
|---|---|---|
| 需要输出指定时间戳、动态分辨率、最大体积、固定格式的图像 | 输出指定分辨率、最大体积、指定格式个图片 | 原样输出 |
| 关键能力:截帧/截图、分辨率、格式、压缩 | 关键能力:压缩、分辨率、格式 | |
|
|
|
视频截帧模板
| 图像压缩模板
| 直接使用源地址:
|
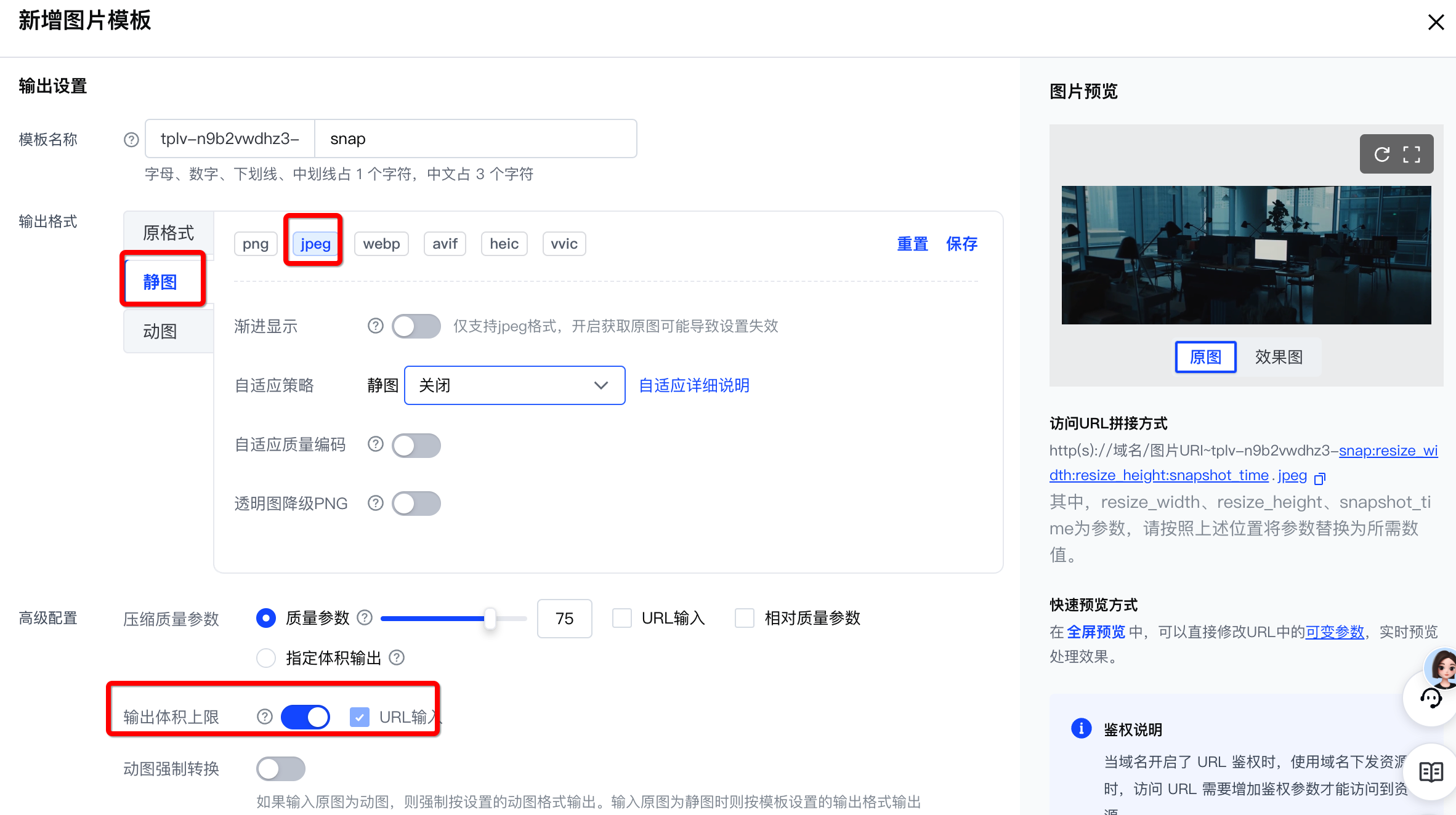
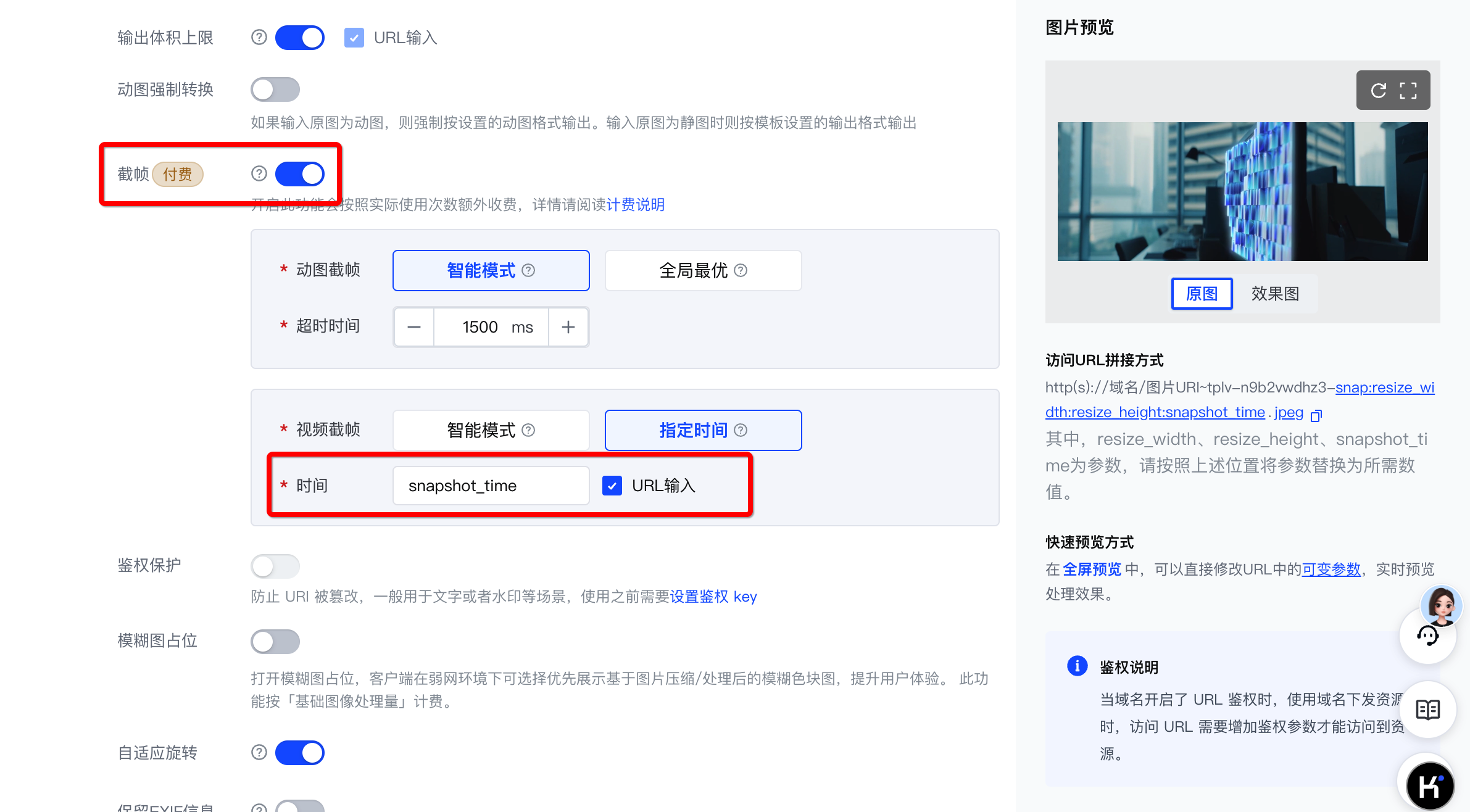
具体使用
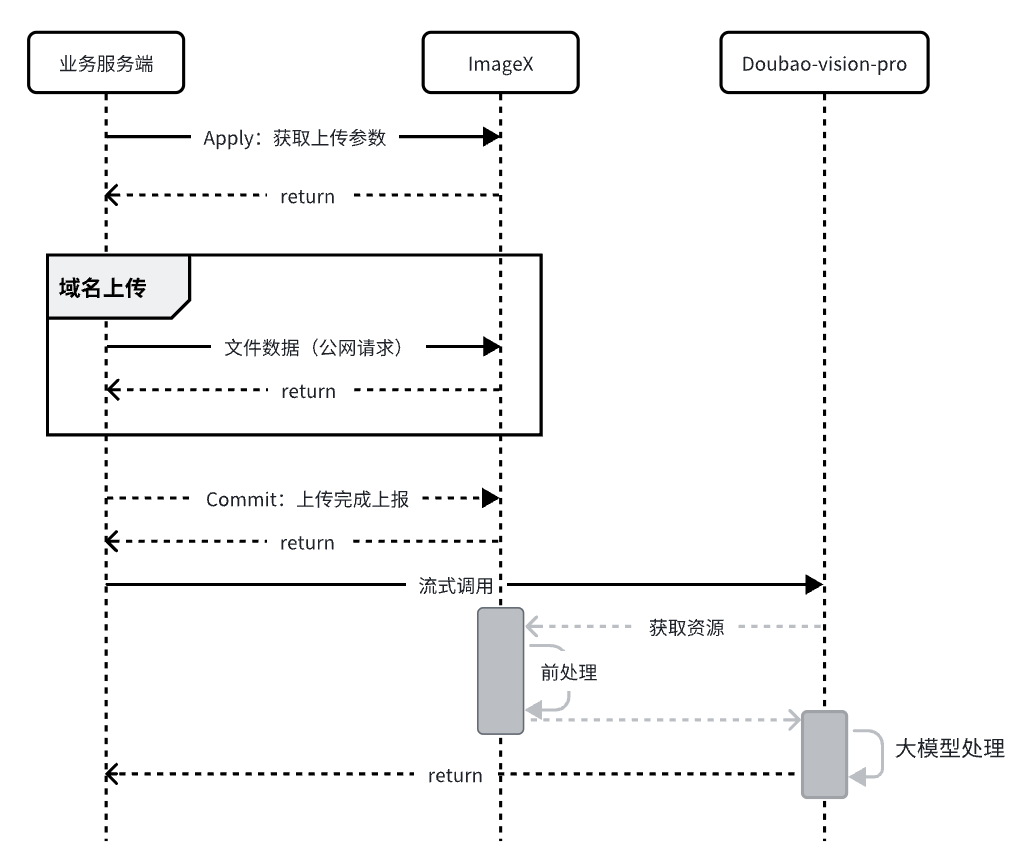
上传图片+前置处理
veImageX 支持上传任何类型的资源,更多上传说明,可参考 veImageX 上传最佳实践。
# coding:utf-8 from __future__ import print_function from volcengine.imagex.v2.imagex_service import ImagexService import os from volcenginesdkarkruntime import Ark #从控制台获取 ak 和 sk IMAGEX_AK = "你的 ak" IMAGEX_SK = "你的 sk" ARK_API_KEY = "你的火山方舟的 ARK_API_KEY" # 替换火山方舟的 ARK_API_KEY,填入 准备操作-在线推理 获取的 ARK_API_KEY ''' 如下是火山引擎 veImageX 上传并拼接 url 的示例,上传前确保使用 pip install --user volcengine 安装 veIamgeX SDK ''' if __name__ == "__main__": imagex_service = ImagexService() domain = "imagex.test.com" # 替换域名,填入 准备操作-服务管理 中获取的域名 Tpl = "tplv-serviceid-1.jpeg" # 替换图片压缩模板,填入 准备操作-处理配置 中获取的模板 imagex_service.set_ak(IMAGEX_AK) imagex_service.set_sk(IMAGEX_SK) params = dict() params["ServiceId"] = "serviceid" # 服务 ID,填入 准备操作-服务管理 中获取的服务 ID params["SkipMeta"] = False params["SkipCommit"] = False params["StoreKeys"] = "dev/aigc/pic/demo1.jpg" # 指定刚上传后图片的存储 uri,可自定义,不填则使用随机生成的字符串 # params['FileExtension'] ='jpeg' file_paths = ["/Users/1.jpg"] # 本地文件的路径,可以支持上传任意类型文件,包括视频、图片等 resp = imagex_service.upload_image(params, file_paths) if resp["Results"][0]["UriStatus"] != 2000: raise Exception("upload failed") image_uri = resp["Results"][0]["Uri"] imagex_url = "https://" + domain + "/" + image_uri + "~" + Tpl # 拼接模板处理后的图片 url,拼接方式为:http://domain/uri+处理模板 print("----- imagex upload and compress success-----") print(imagex_url) ''' 以下为是火山方舟视觉理解大模型的调用示例,调用前请确保使用 pip install --upgrade 'volcengine-python-sdk[ark]' 安装了火山方舟 SDK ''' client = Ark( api_key=ARK_API_KEY, base_url="https://ark.cn-beijing.volces.com/api/v3", ) print("----- streaming request -----") stream = client.chat.completions.create( model="ep-2024**********-****m", # 替换 model,填入 准备操作-在线推理 获取的 model messages=[ { "role": "system", "content": "你是豆包,是由字节跳动开发的 AI 人工智能助手", }, { "role": "user", "content": [ { "type": "text", "text": "请用几个关键词解释一下这张图帮我解释一下这张图", }, {"type": "image_url", "image_url": {"url": imagex_url}}, # 传入 veImageX 拼接的处理后的 url ], }, ], stream=True, ) for chunk in stream: if not chunk.choices: continue print(chunk.choices[0].delta.content, end="") print()
上传视频
请使用 veImageX 的截帧处理,将视频转换为图片后,再使用图像检索模型对图片内容进行理解。
# coding:utf-8 from __future__ import print_function from volcengine.imagex.v2.imagex_service import ImagexService from volcenginesdkarkruntime import Ark # 从控制台获取ak和sk IMAGEX_AK = "你的 ak" IMAGEX_SK = "你的 sk" ARK_API_KEY = "你的火山方舟的 ARK_API_KEY" # 替换火山方舟的 ARK_API_KEY,填入 准备操作-在线推理 获取的 ARK_API_KEY ''' 如下是火山引擎 veImageX 上传并拼接 url 的示例,上传前确保使用 pip install --user volcengine 安装 veIamgeX SDK ''' if __name__ == "__main__": imagex_service = ImagexService() domain = "imagex.test.com" # 替换域名,填入 准备操作-服务管理 中获取的域名 Tpl = "tplv-n9b2vwdhz3-snap-v1:0:0:{}:0.jpeg" # 替换视频截帧模板填入 准备操作-处理配置 中获取的模板。{}是视频截帧的时间点,单位是毫秒 imagex_service.set_ak(IMAGEX_AK) imagex_service.set_sk(IMAGEX_SK) params = dict() params["ServiceId"] = "serviceid" # 服务 ID,填入 准备操作-服务管理 中获取的服务 ID params["SkipMeta"] = False # params["SkipCommit"] = False params["StoreKeys"] = "dev/aigc/pic/demo2.mp4" # 指定刚上传后图片的存储 uri,可自定义,不填则使用随机生成的字符串 # params['FileExtension'] ='jpeg' file_paths = ["/Users/dev/aigc/pic/volcimagex.mp4"] # 本地视频文件的路径,支持上传任意类型文件,包括视频、图片等 resp = imagex_service.upload_image(params, file_paths) if resp["Results"][0]["UriStatus"] != 2000: raise Exception("upload failed") image_uri = resp["Results"][0]["Uri"] imagex_url = "https://" + domain + "/" + image_uri + "~" + Tpl # 拼接模板处理后的图片 url,拼接方式为:http://domain/uri+处理模板 print("----- imagex upload and compress success-----") # 传入时间点,构造 1-10 秒的截帧 URL 列表 imagex_urls = [imagex_url.format(i * 1000) for i in range(1, 11)] # 构建 messages 列表中的 image_url 部分 image_urls_content = [{"type": "image_url", "image_url": {"url": url}} for url in imagex_urls[:10]] ''' 以下为是火山方舟视觉理解大模型的调用示例,调用前请确保使用 pip install --upgrade 'volcengine-python-sdk[ark]' 安装了火山方舟 SDK ''' client = Ark( api_key=ARK_API_KEY, base_url="https://ark.cn-beijing.volces.com/api/v3", ) print("----- streaming request -----") stream = client.chat.completions.create( model="ep-2024**********-****m", # 替换 model,填入 准备操作-在线推理 获取的 model messages=[ { "role": "system", "content": "你是豆包,我会将一个视频每隔1s截图发给你,帮我总结出视频的主要内容,请注意这是一个视频", }, { "role": "user", "content": [ { "type": "text", "text": "请帮我总结视频内容", }, *image_urls_content # 使用星号(*)操作符将列表项展开为单独的元素 ], }, ], stream=True, ) for chunk in stream: if not chunk.choices: continue print(chunk.choices[0].delta.content, end="") print()
App 端和其他端上传和截图原理类似,详细请见上传最佳实践。上传成功后均可以通过 http://domain/uri+模板+签名(可选),拼接有效访问地址,处理成目标结果,返回给用户预览或者送给大模型处理。
常见问题
为什么在本文档中不选用 Base64 方式在视觉理解大模型中上传图片?
主要原因为 Base64 这种上传方式会导致数据量增加,具体说明如下:
Base64 编码是将 3 个 8 位的字节转化为 4 个 6 位的字节,然后在 6 位的前面补两个 0,形成 8 位一个字节的形式 。如果剩下的字符不足 3 个字节,则用 0 填充,输出字符使用 “=” 245。从数学角度来看,每 3 个字节的原始数据经过 Base64 编码后会变为 4 个字节来存储和传输,这就导致了数据量的增加。一般来说 Base64 编码后的数据量会比原始数据增大约 1/3 左右。
由于 Base64 编码后的大型图片数据量增大,那么在网络传输过程中就需要消耗更多的时间和带宽来传输这些数据。例如,一个原本 500KB 的大型图片,经过 Base64 编码后可能会变为 667KB 左右,传输时间自然会延长。