导航
3.1.2 HSQL任务
最近更新时间:2022.09.05 11:25:29首次发布时间:2022.09.05 11:25:29
使用场景
通过SQL语句,从源hive表中获取待加工数据,完成后写入目标hive表,支持Spark执行引擎。
任务配置
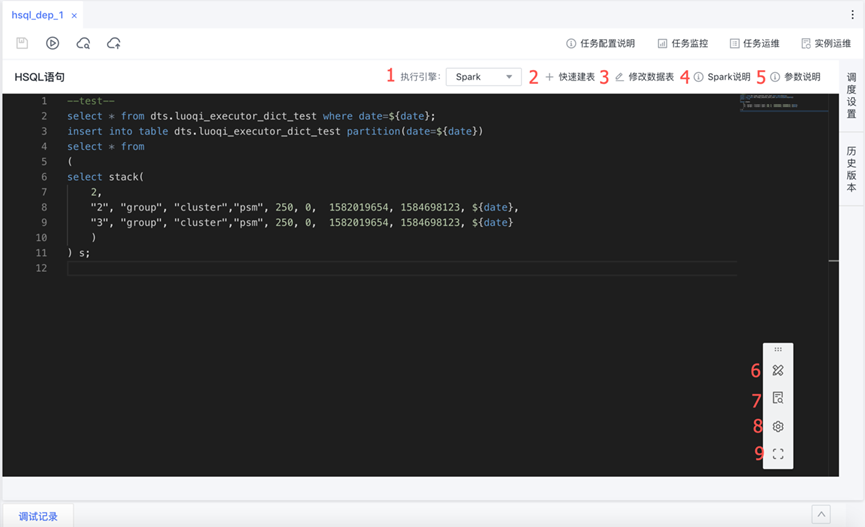
执行引擎:支持spark
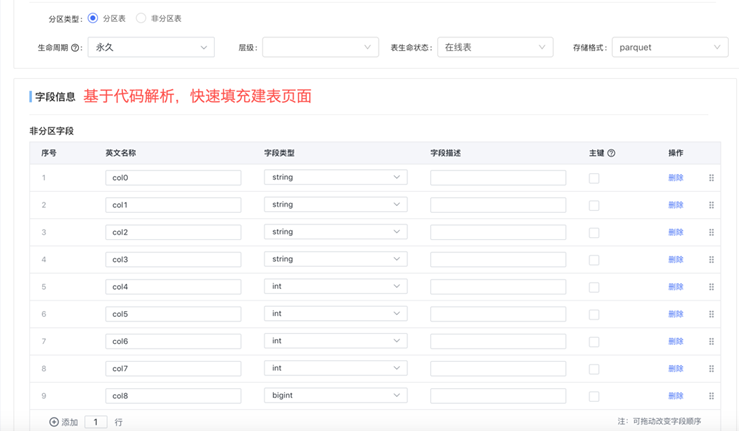
快速建表:若数据需要存入的hive表,且hive表尚未创建,则编写完sql语句后,点击“快速建表”,可基于解析代码快速填充建表页面
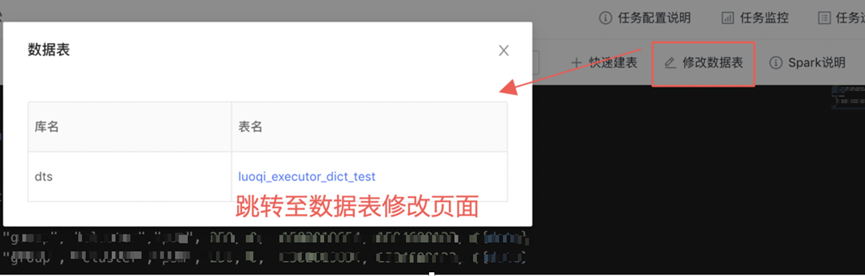
修改数据表:点击后,跳转至数据表编辑页面,进行表信息调整
Spark参数说明:执行引擎选择“spark”,出现spark相关说明
参数说明:系统参数使用说明
格式化:点击后,将SQL进行格式化
解析:编写完sql语句,点击“解析“,可以检验sql语法是否正确
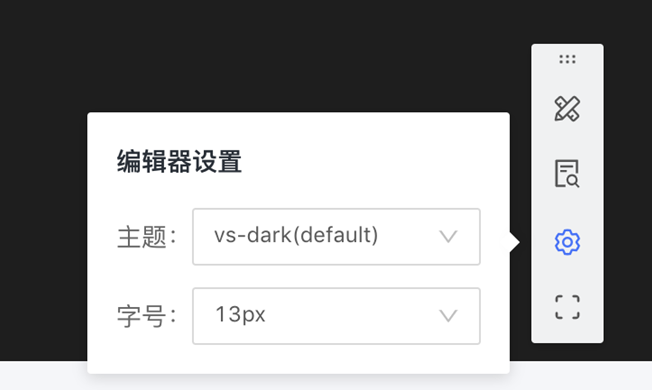
编辑器设置:可根据需要,设置编辑器背景和字号
编辑器全屏:点击后,编辑器全屏,全屏coding区域
智能联想
HSQL任务编辑器支持智能联想及补全能力。编写SQL时自动触发智能联想库名/表名/字段名称,提升SQL编辑效率。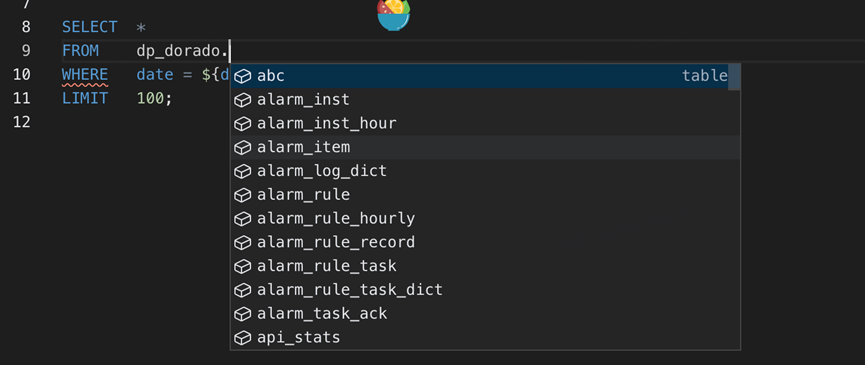
- 编写SQL自动触发库名/表名/字段名称联想
- 联想内容输入Tab触发库名/表名/字段名自动补全
- 鼠标Hover表名/字段名显示详情说明,如字段名称、类型、说明等,同时提供快速入口跳转至数据地图,查看表详情
- 支持快捷操作 键盘cmd+鼠标click表名的方式自动跳转至数据地图表详情页
HSQL 语句示例
//方式1静态分区,场景:根据数据到来的频率,新数据的到来时间确定,分区的值是确定的。 insert overwrite table 目标db.目标表名 partition (date = "${date}") select name, age from 源库名.源表名 where date = "${date-1}" //方式2动态分区,谨慎使用,根据已有数据进行动态分区,分区的值是非确定的。 insert overwrite table 目标db.目标表名 partition (p_date,app) select user_id, date as p_date, app_name as app//分区字段 from 源库名.源表名 where date = "${date-1}