导航
3.3.4 SqlSever-Hive
最近更新时间:2022.09.05 11:25:30首次发布时间:2022.09.05 11:25:30
使用场景
将SqlSever数据导入到Hive表中,如将业务系统生产的SqlSever数据同步到Hive表,供离线分析使用。
注意事项
如果未找到SqlSever数据源信息,请在数据源管理中配置对应的SqlSever数据源
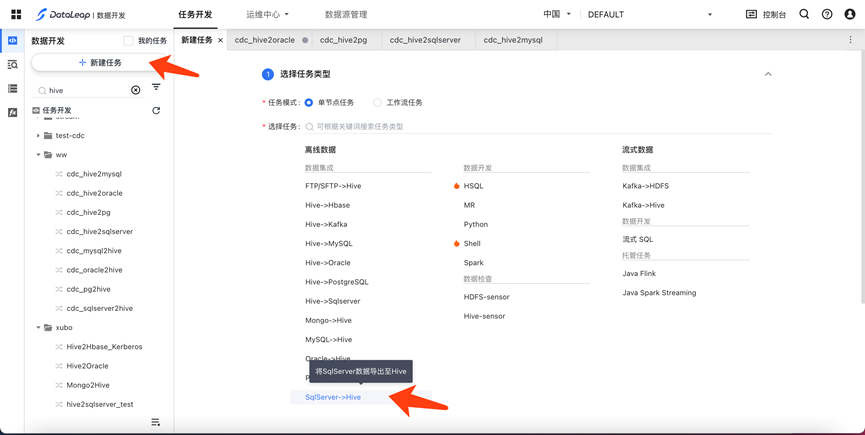
新建任务
- 在任务开发首页,点击“新建任务”
- 在项目下,左侧目录结构中,右键新建任务
任务设置
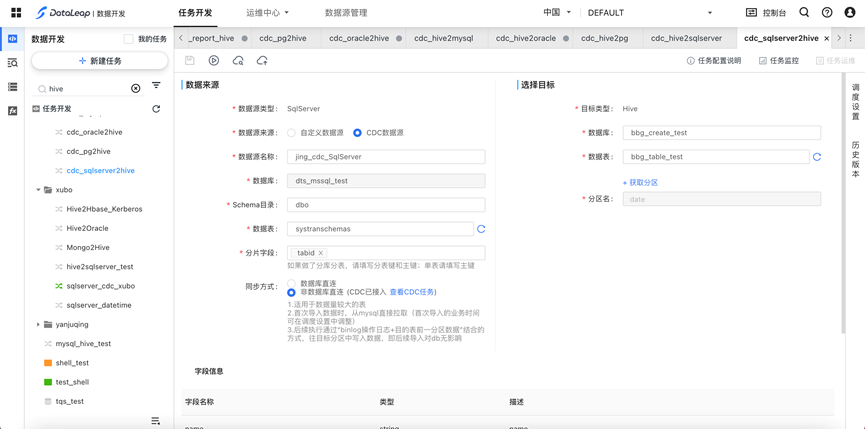
数据源信息
- 数据源来源:分为自定义数据源和CDC数据源,CDC数据源可选非直连模式
- 数据源名称:数据源管理中注册的数据源
- 数据库:数据源所属的仓库名;
- Schema目录:sqlsever的schema目录
- 数据表:数据源所属的表名;
- 分片字段:如果做了分表,推荐使用“分表键+主键”;如果无分表,推荐使用“主键”
目标信息
- 数据库:hive所在的数据库
- 数据表:hive目标表
- 分区名:分区字段从hive表自动获取
字段映射
字段映射在选好数据来源和目标后,可通过“自动添加”功能填充,也可手动添加和编辑,“自动添加”通过数据源的表结构获取。字段填充后,按需调左右映射。
同步方式
数据库直连:
- 适用于小表模式(表数据量在百万行以下)
- 适用于对在线业务访问latency不敏感(每次导入直接从mysql拉取数据)
- 任务频率为小时级时, 如有批量重跑或实例耗时超过1小时的情况, 对Mysql从库可能有较大压力,请谨慎评估相关操作对DB的负载影响
非数据库直连:
- 适用于数据量较大的表
- 首次导入数据时,从数据库直接拉取(首次导入的业务时间可在调度设置中调整,首次导入业务时间的实例会拉取db全量数据)
- 后续执行通过“binlog操作日志+目的表前一分区数据”结合的方式,往目标分区中写入数据,即后续导入对db无影响
- 非数据库直连新增或修改hive字段后的处理方法:新增或修改hive字段后需要重跑一次全量。重跑全量可以通过修改调度设置-调度属性-首次导入的业务时间,然后将任务上线重跑首次导入的业务时间到今天的实例。
- 需要注意,如果更新了唯一索引字段,且需要重新全量dump,请至少等1天以后,否则有可能出现数据增多。
- 增量同步需要先接入CDC任务,详见CDC任务说明