导航
3.3.13 离线数据集成通用配置
最近更新时间:2022.09.07 11:41:27首次发布时间:2022.09.05 11:25:31
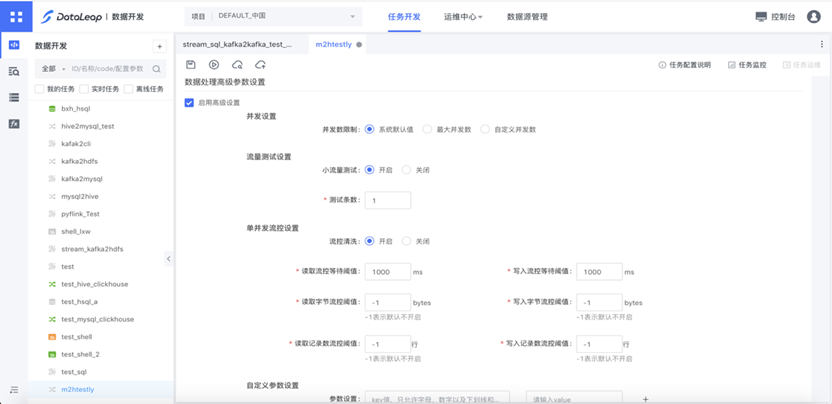
数据处理高级参数设置
- 并发设置
系统默认值指执行引擎会根据任务的类型、文件的个数、文件的大小、连接节点的个数智能推断任务执行的并发。如果不确定如何设置并发,可使用默认值。 - 最大并发数
指任务在各个执行阶段控制的最大并发数,并发数是由系统自动计算,当计算的并发大于最大并发数时,会将并发限制到最大并发数的值。用户可自定义1~20000的任意一个整数 。
需要注意的是,JDBC、Kafka会单独将默认的最大并发限制为5,此时写入阶段的并发数上限为全局并发数限制和局部并发数限制的较小值。如需突破限制,精细地控制每个阶段的并发,可以在自定义并发数里配置读入并发和写入并发。 - 小流量测试
当初次提交作业想验证数据正确性时,可开启小流量测试。测试条数在1~10000之间,当每个并发运行到该条数时,任务会自行关闭。 - 单并发流控设置
流量控制支持用户自定义每一个并发的读写字节流控阈值,读写记录数流控阈值和读写流控等待阈值,默认关闭。读写字节和读写记录有一项满足要求即启动流控。- 读写流控等待阈值:该阈值决定每次流控检查的时间间隔,当最新记录到来的时刻和上次记录的时刻超过等待阈值时,进行流控检查。读写流控等待阈值默认为1000ms。
- 如果发现流控效果不明显,可以调小此阈值(如10ms)来进行更精细控制。
- 读写字节流控阈值:该阈值决定每次检查时是否激活流量控制。当最新的字节数和上次记录的字节数超过阈值时,启动流控。根据超过的比例进行动态睡眠处理。默认为-1,即不开启。
- 读写记录数流控阈值:该阈值决定每次检查时是否激活流量控制。当最新写的记录数和上次记录的记录数超过阈值时,启动流控。根据超过的比例进行动态睡眠处理。默认为-1,即不开启。
根据测试结果,用户可根据任务所需的qps快速配置读写流控参数,公式如下:
读写记录数流控阈值(每秒)~= 单并发qps * 2
注意:如果需要进行多并发的精确流控,需要在任务自定义参数中加入job.common.slots_per_tm : 1,将每个Worker中的线程数设置为1。
- 自定义参数
自定义参数支持用户更好地定制自己任务的运行方式,目前已支持参数如下:- job.common.flink_tm_slot_memory:Flink TM单个slot的内存,单位为MB,默认大小为4096。配置示例:job.common.flink_tm_slot_memory=8192
- job.common.flink_yarn_priority:只在开启了优先级提交的yarn队列生效,可控制flink作业提交到yarn队列的优先级,范围1~9,数字越大,优先级越高,默认为1。配置示例:job.common.flink_yarn_priority=1。