导航
3.1.4 Spark任务
最近更新时间:2022.09.05 11:25:29首次发布时间:2022.09.05 11:25:29
使用场景
spark任务,具体分为Jar spark任务和python spark任务。
Spark 使用说明
- Spark insert overwrite 使用示例
df.write.insertInto("aaa\\\_bbb\\\_doc\\\_html\\\_detail", True) - 用户自定义参数较多时,且存在K-V参数时,可参考如下配置
Spark程序中,如果自定义参数较多, 可直接在"自定义参数"输入框中配置,使用空格分隔,数据开发运行时,会将自定义参数拼接到main class之后,配置输入参数格式需符合spark main class程序解析方式。
如下图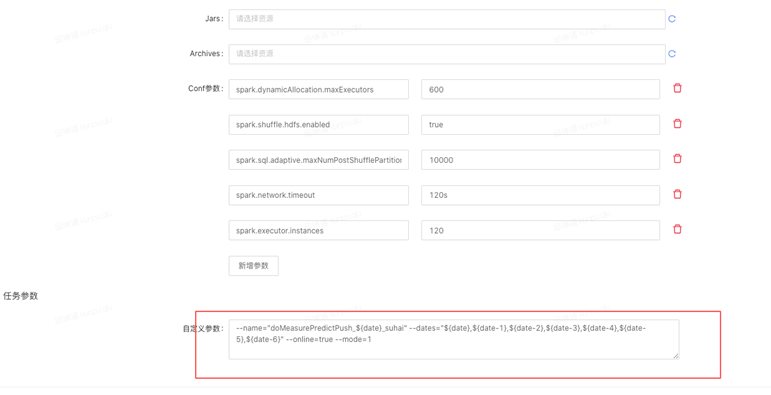
如需使用时间变量,也可以直接在自定义参数中配置${date}/${DATE}等系统变量。 - Spark优化参数
参数列表
| 参数 | 描述 | 默认值 |
|---|---|---|
| spark.executor.instances | 静态资源下:executor数 | 2 |
| spark.executor.cores | 每个executor和CPU数 | 4 |
| spark.dynamicAllocation.enabled | 动态资源开关 | false |
| spark.dynamicAllocation.maxExecutors | 动态资源下:executor的最大个数 | 500 |
| spark.executor.memory | 每个executor的内存大小 | 8g |
| spark.memory.fraction | executor用于计算的内存比例,剩余部分用于存储元数据和运行信息。对于executor内存开的较大的任务,可以适当提高这个值,让更多内存参与计算,但会增加OOM风险 | 0.6 |
spark.executor.memoryOverhead/ | 每个executor的堆外内存大小,堆外内存主要用于数据IO,对于报堆外OOM的任务要适当调大,单位Mb,与之配合要调大executor JVM参数,例如: | 6144 |
| spark.sql.adaptive.enabled | Adaptive execution开关,包含自动调整并行度,解决数据倾斜等优化 | true |
| spark.sql.adaptive.minNumPostShufflePartitions | AE相关,动态最小的并行度 | 1 |
| spark.sql.adaptive.maxNumPostShufflePartitions | AE相关,动态最大的并行度,对于shuffle量大的任务适当增大可以减少每个task的数据量,如1024 | 1000 |
| spark.sql.adaptive.join.enabled | AE相关,开启后能够根据数据量自动判断能否将sortMergeJoin转换成broadcast join | true |
| spark.sql.adaptiveBroadcastJoinThreshold | AE相关,spark.sql.adaptive.join.enabled设置为true后会判断join的数据量是否小于该参数值,如果小于则能将sortMergeJoin转换成broadcast join | spark.sql.autoBroadcastJoinThreshold |
| spark.sql.adaptive.skewedJoin.enabled | AE相关,开启后能够自动处理join时的数据倾斜,对于数据量明显高于中位数的task拆分成多个小task | false |
| spark.sql.adaptive.skewedPartitionFactor | AE相关,数据倾斜判定标准,当同一stage的某个task数据量超过中位数的N倍,将会判定为数据倾斜 | 5 |
| spark.sql.adaptive.skewedPartitionMaxSplits | AE相关,被判定为数据倾斜后最多会被拆分成的份数 | 5 |
| spark.shuffle.accurateBlockThreshold | AE相关,数据倾斜判定基于shuffle数据量统计,如果统计所有的block数据,消耗内存较大,因此设有阈值,当shuffle的单个数据块超过大小和行数阈值时,才会进入统计,这个参数即大小阈值 | 100*1024*1024(100MB) |
| spark.shuffle.accurateBlockRecordThreshold | AE相关,同上,行数阈值,如果设置了上面的数据倾斜处理开关,仍然倾斜,可能是因为这几个参数设得偏大,适当缩小 | 2 * 1024 * 1024 |
| spark.sql.files.maxPartitionBytes | 默认一个task处理的数据大小,如果给的太小会造成最终任务task太多,太大会是输入环节计算较慢 | 1073741824 |
| spark.vcore.boost.ratio | vcore,虚拟核数,设置大于1的数可以使一个核分配多个task,对于简单sql可以提升CPU利用率,对于复杂任务有OOM风险 | 1 |
| spark.shuffle.hdfs.enabled(长任务推荐) | HDFS based Spark Shuffle开关,可以提高任务容错性。遇到org.apache.spark.shuffle.FetchFailedException报错需设置 | false |
set spark.shuffle.io.maxRetries=1; | 一般在开启hdfs shuffle后还可以开启这两个参数,避免不必要的重试和等待 | |
| spark.sql.crossJoin.enabled | 对于会产生笛卡尔积的sql,默认配置是限制不能跑的,在hive里可以配置set hive.mapred.mode=nonstrict跳过限制,相对应的在spark里可以配置set spark.sql.crossJoin.enabled=true起到同样的效果。 | false |
| spark.sql.broadcastTimeout | broadcast joins时,广播数据最长等待时间,网络不稳定时,容易出现超时造成任务失败,可适当增大此参数。 | 300(单位:s) |
| spark.sql.autoBroadcastJoinThreshold | 表能够使用broadcast join的最大阈值 | 10MB |
| spark.network.timeout | 网络连接超时参数 | 120s |
| spark.maxRemoteBlockSizeFetchToMem | reduce端获取的remote block存放到内存的阈值,超过该阈值后数据会写磁盘,当出现数据量比较大的block时,建议调小该参数(比如512MB)。 | Long.MaxValue |
| spark.reducer.maxSizeInFlight | 控制从一个worker拉数据缓存的最大值 | 48m |
| spark.merge.files.enabled | 合并输出文件,如果insert结果的输出文件数很多,希望合并,可以设为true,会多增加一个repartition stage合并文件,repartition的分区数由spark.merge.files.number控制 | false |
| spark.merge.files.number | 控制合并输出文件的输出数量 | 512 |
| spark.speculation | 推测执行开关。如果是原生任务很有可能没开这个参数,会出现个别task拖慢整个任务,可以开启这个参数。 | true |
| spark.speculation.multiplier | 开启推测执行的时间倍数阈值:当某个任务运行时间/中位数时间大于该值,触发推测执行。对于因为推测执行而浪费较多资源的任务可以适当调高这个参数。 | 1.5 |
| spark.speculation.quantile | 同一个stage中的task超过这个参数比例的task完成后,才会开启推测执行。对于因为推测执行而浪费较多资源的任务可以适当调高这个参数。 | 0.75 |
| spark.default.parallelism | Spark Core默认并发度,原生spark程序并发度设置 | 200 |
| spark.sql.shuffle.partitions | Spark SQL默认并发度,AE开启后被spark.sql.adaptive.maxNumPostShufflePartitions取代 | 200 |
| spark.sql.sources.bucketing.enabled | 分桶表相关,当设置为false,会将分桶表当作普通表来处理。做为普通表会忽略分桶特性,部分情况性能会下降。但如果分桶表没有被正确生成(即表定义是分桶表,但数据未按分桶表生成)会报错RuntimeException: Invalid bucket file,避免这个错误,要将这个参数设为false | true |
| spark.sql.partition.rownum.collect.enable | 统计生成固定分区表行数 | false |
| spark.sql.dynamic.partition.rownum.collect.enable | 统计生成动态分区表行数 | false |