导航
3.3.3 Hive-Kafka
最近更新时间:2022.09.05 11:25:30首次发布时间:2022.09.05 11:25:30
使用场景
将Hive数据同步至Kakfa,实现Hive数据源与Kafka之间的数据传输。
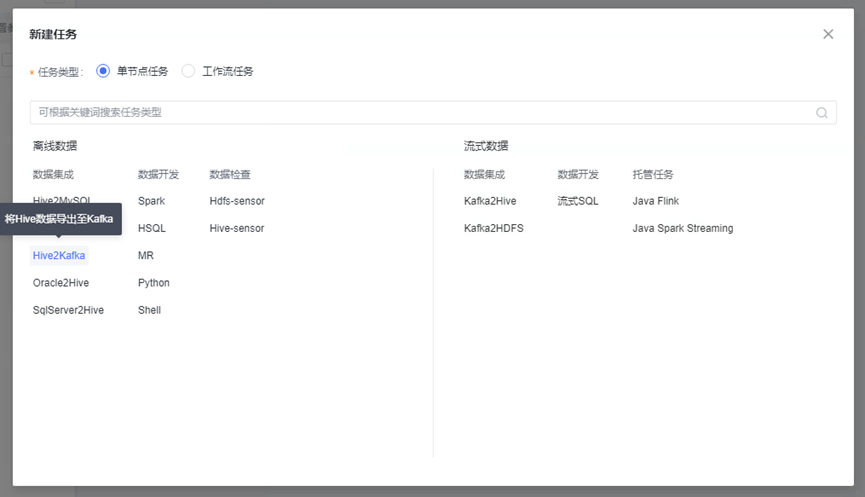
新建任务
- 在任务开发首页,点击“新建任务”
- 在项目下,左侧目录结构中,右键新建任务
任务配置
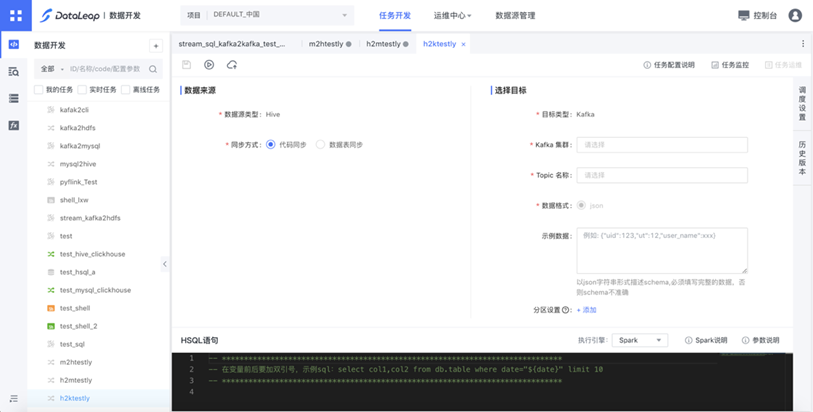
hive2kafka提供两种同步模式,代码同步和数据表同步,通过两种模式,都可以将hive数据导入到kafka中。
代码同步:将通过sql获取的hive数据,同步至kafka。
数据表同步: 将选中的hive表数据,以JSON形式同步至kafka中。
- value为null的字段不会存于kafka中。
- hive是array和map类型的,kafka类型选择string,该字段数据会以json形式来存储。
常见问题
- Hive2Kafka是否支持回溯?
支持正常回溯,但是历史已经写入的数据不会删除。 - Hive2Kafka流控设置
目前支持设置 records/s 和 bytes/s。
注意:
- 设置的速率都是针对单个并行实例的,如果需要控制全局速率,那么可以通过设置reader和writer的并行度,和单个并行度的速率来达到控制全局速率的目的。
- 设置bytes/s时,系统内部统计的流量和真实写入kafka的流量有偏差。