DataLeap私有化V2.1.2
DataLeap私有化V2.1.2






- 文档首页
 DataLeap私有化V2.1.23 数据开发3.2 流开发3.2.1 SQL任务
DataLeap私有化V2.1.23 数据开发3.2 流开发3.2.1 SQL任务

通过标准化的 flink sql 语言,在线开发、测试、运维流式任务,不依赖jar包,方便更新和维护。
适用场景
- 对流式数据通过sql的方式做聚合加工,产出实时指标。
- 对结构比较清晰的数据做清洗过滤的流式ETL需求。
- 构建流式数据仓库。
数据源的使用
通过DDL语句实现对数据源的使用,目前提供以下几类语法:
- create table:用于定义表结构,包含有定义源表(source)、结果表(sink)
- create view:用于定义中间结果视图
- create function:用于自定义udf的声明
- insert into XXX select:用于表示真正需要执行的sql语句,并将执行结果insert到对应的结果表中
新建任务
功能入口:
- 在任务开发首页,点击“新建节点”;
- 在项目下,左侧目录结构中,右键新建任务;
- 任务编辑页面,点击“新建”。
新建任务类型选择“流式sql任务“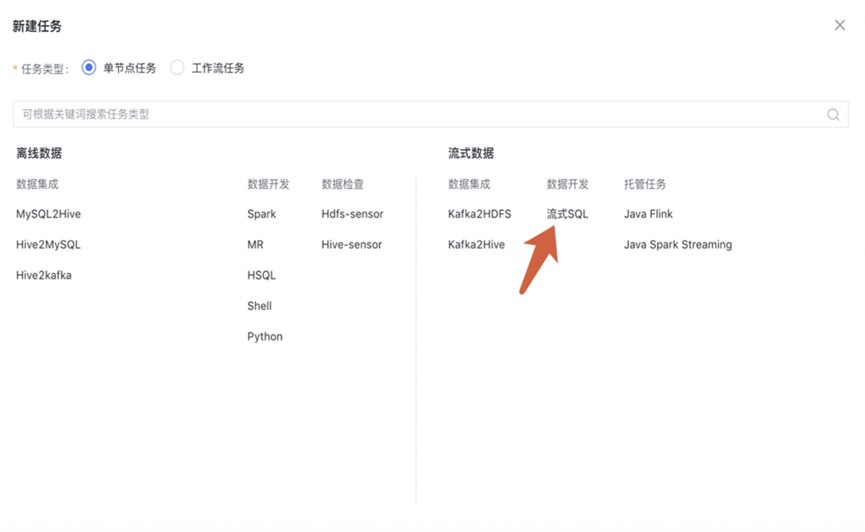
SQL 编辑
通过DDL语法声明使用数据源,Flink SQL 加工数据,DataLeap 版本的DDL语法与开源版有少量不同,具体看下方的说明与DDL参数表格。
一个完整的任务示例:
1. -- 1.创建 kafka source table 2. create table click_data( 3. user_id bigint, 4. article_id bigint, 5. click_time timestamp, 6. watermark for click_time as withoffset(click_time, 3000) 7. ) with ( 8. 'connector.type' = 'kafka', 9. 'connector.version' = '0.10', 10. 'connector.topic' = 'test_topic', 11. 'connector.cluster' = 'test_cluster', 12. 'connector.group.id' = 'flink_1.9_sql_test', 13. 'update-mode' = 'append', 14. 'format.type' = 'json', 15. ); 16. 17. -- 2.创建 Mysql sink table 18. create table article_pv( 19. article_id bigint, 20. PV bigint, 21. s_time timestamp 22. ) with ( 23. 'connector.type' = 'jdbc', 24. 'connector.table' = 'test_table', 25. 'connector.dbname' = 'testdb', 26. 'connector.url' = 'mysql.testdb_write', 27. 'connector.username' = 'sink.test', 28. 'connector.password' = 'abcabc', 29. 'connector.write.flush.max-rows' = '5' 30. ); 31. -- 3. 计算逻辑 32. insert into article_pv 33. select article_id, count(*) as PV, TUMBLE_START(click_time, INTERVAL '1' HOUR) as s_time 34. from click_data 35. group by article_id, TUMBLE(click_time, INTERVAL '1' HOUR)
PB 格式定义
使用PB格式的数据源,需要在当前任务上传PB类的定义文件,或手工输入PB类,json格式无需设置。
一次只支持一个PB类的定义,例:
1. syntax = "proto2"; 2. package abase_test; 3. message AbaseTest { 4. required int64 first_id = 1; 5. required int64 latest_id = 2; 6. }
说明
- 如果kafka topic是binlog数据,在flink sql source中指定下'format.type' = 'pb_binlog'即可,数据类型选择'json'方式
- 如果Kafka topic是自定义pb数据
- 在flink sql source中指定下'format.pb-class' = '{package的路径}.{java_outer_classname的类名}${入口message名称}'.
- 譬如,
a) `'format.pb-class' = 'parser.proto.ProtoParser$Instance'`
数据源格式选择"pb","Pb类定义"中开头设置 package 和 option java_outer_classname,"入口message名称" 指定入口message名称
举例:
"Pb类定义"开头:
package parser.proto;
option java_outer_classname = "ProtoParser";
"入口message名称":Instance
任务调试
流式任务支持在线调试,通过2种方式获取测试数据:
1. 在当前任务消费的 topic 中抽取最近100条数据
2. 手工上传json格式的文件
测试过程中,SQL 在独立环境运行,所有的输出直接写到本地浏览器,不会对线上生产的数据存储系统造成影响。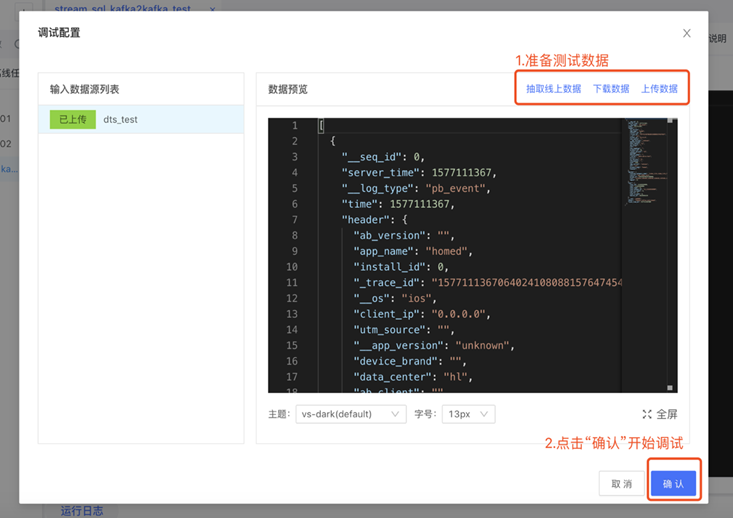
参数设置
基础信息:任务名称、描述、责任人、队列等基础信息按需填写。
资源设置
获取推荐配置:根据任务的历史24小时运行情况,给出推荐配置
Flink 运行参数:Flink 相关的动态参数和执行参数,具体设置详见 Flink 官方文档
用户自定义参数:kv格式,按需设置。
提交上线
任务测试通过后,先“保存”任务生成一个草稿版本。然后点击“提交上线”,即按最新的版本启动一个 Flink 实例,后续的运行情况可在“任务运维”中查看。
运维列表的“重启”功能以线上配置为准,不应用最新版本草稿。
历史版本
每次上线会生成一个版本,在“历史版本”功能中可以查看、对比和回滚,回滚的效果是恢复至草稿,需要重新点击上线。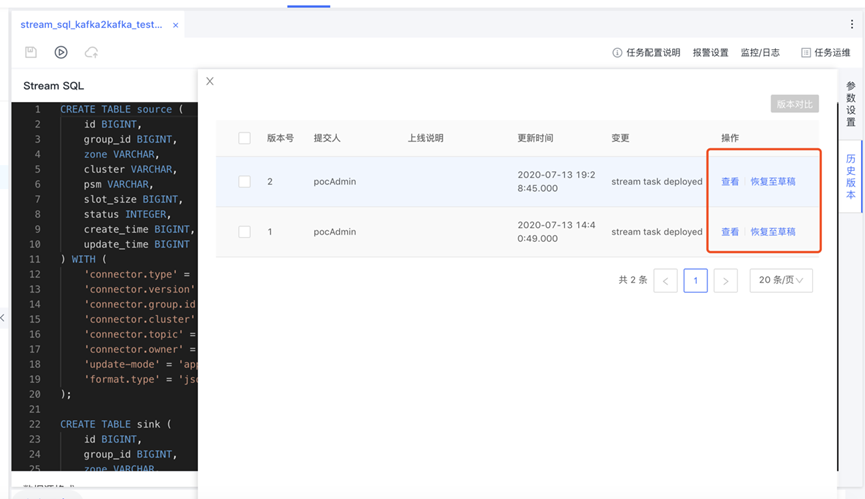
DDL参数设置
DataLeap的流式SQL在DDL部分与开源版本有少量不同,具体参考以下内容。
Kafka DDL 参数
| name | meaning | required | default | consumer/producer |
|---|---|---|---|---|
| connector.type | connector 的类型,必须是 kafka | YES | - | consumer & producer |
| connector.version | kafka 版本,当前支持 '0.10' | YES | - | consumer & producer |
| connector.cluster | kafka 集群名 | YES | - | consumer & producer |
| connector.topic | kafka topic | YES | - | consumer & producer |
| connector.group.id | consumer group id | YES | - | consumer |
| update-mode | 更新模式, 'append'/'upsert' | YES | - | consumer 就填 'append' 就行; producer 如果是查询的结果是可以更新的就用 upsert, 如果是查询的结果是不可更新的就用 append. |
| connector.owner | 作业 owner | NO | - | consumer & producer |
| connector.startup-mode | earliest-offset/latest-offset/group-offsets/specific-timestamp,详细解释如下 | NO | group-offsets | consumer |
| connector.specific-timestamp | 当指定connector.startup-mode为specific-timestamp的时候,需要指定一个ms单位的时间戳,从该时间戳开始消费 | NO | 0 | consumer |
| connector.reset-to-earliest-for-new-partition | 该参数表示在任务启动时,如果用的是group-offsets配置,对于那些还没有offset的partition如何处理,详情可以参考:kafka partition扩容 | NO | true | consumer |
| connector.kafka.properties.{param} | {param} 是任意 kafka 参数, 如 connector.kafka.properties.ignore.dc.check = true | NO | - | consumer & producer |
| connector.log-failures-only | 写入 kafka 失败时是否只打一条日志,task 不退出 | NO | false | producer |
| connector.rate-limiting-num | 读取 kafka 限速,是整个 source table 所有并发的流速之和, 配合 connector.rate-limiting-unit 使用。 | NO | -1,默认不限速 | consumer |
| connector.rate-limiting-unit | 读取 kafka 限速的单位,配合 connector.rate-limiting-num 使用,可选单位:'BYTE', 'RECORD' 分别对应 byte 和 消息条数 | NO | 'BYTE' | consumer |
Mysql DDL 参数
| name | meaning | required | 取值范围 | default |
|---|---|---|---|---|
| connector.type | connector type | YES | jdbc | - |
| connector.dbname | 数据库名 | YES | - | - |
| connector.table | 数据库表名 | YES | - | - |
| connector.init-sql | 新建 db 连接时预执行的语句。 如需要写入表情符号时,设置 'connector.init-sql' = 'SET NAMES utf8mb4' | NO | - | - |
| connector.write.flush.max-rows | 积攒多少条数据一批次写入 | NO | 0~ | 5000 |
| connector.write.flush.interval | 积攒多久时间的数据一批次写入, 单位 ms, 默认是 0 的话,就是没有定期输出,而不是每来一条就输出。 | NO | 0~ | 0 |
| connector.write.max-retries | 写入数据库失败的情况下,最多尝试多少次 | NO | 0~ | 3 |
Kafka json Format
使用 json format 需在 create table 语句中通过'format.type'='json' 指定。
注意事项:
json类型根据用户在create table中声明的column name和column type做解析。SQL任务目前仅做部分自动适配,例如声明为int类型,但实际json里面是int的string表示,SQL也能自动识别并转换回int。但是如果例如声明为int但实际为long或者声明为int但实际是带有字母的string等,SQL无法直接转换,会报错。
json类型支持嵌套json。例如嵌套json "{"a": "a", "b": {"c": 1, "d": "s"}}", 声明嵌套结构时,需要声明为b Row<c int, d varchar> 即可表明字段c、d是嵌套于字段b中。json也支持array形式。
1. 如果是简单的array,例如"a": [1,2,3,4],则可声明为a Array
2. 如果是嵌套json的array,例如"a": [{"b": 3}, {"b": 6}],则可声明为a Array<Row>, 即表明a是一个object类型array,a的结构中,有一个类型为int的b列。获取的方式如 select a[1].b 会返回3.
参数
| name | meaning | required | default | note |
|---|---|---|---|---|
| format.type | format 的类型,必须是 'json' | YES | - | - |
| format.derive-schema | json schema 指定方式之一,即自动按table 的schema 推断。强烈建议用这个 | No | true | 样例: 'format.derive-schema'='true' |
| format.schema | json schema 指定方式之一,指定 type info, 不建议用这个,建议用 format.derive-schema | No | - | 样例: 'format.schema'='ROW<test1 VARCHAR, test2 TIMESTAMP>' |
| format.json-schema | json schema 指定方式之一 不建议用这个,建议用 format.derive-schema | No | - | 样例: 'format.schema'='{'title': 'Person', 'properties': {'firstName': {'type': 'string'}}} |
| format.fail-on-missing-field | 缺少字段的时候是否直接失败 | No | false | - |
| format.default-on-missing-field | 缺少字段的时候是否自动添加默认值 | No | false | - |
| format.skip-dirty | 跳过脏数据 | No | false | - |
| format.skip-interval-ms | 脏数据打印间隔(默认是10s) | No | 10000 | - |
| format.json-parser-feature.{feature} | jackson 的 JsonParser.Feature 相关配置 | No | - | 样例:'format.json-parser-feature.ALLOW_UNQUOTED_CONTROL_CHARS'='true' |
| format.enforce-utf-encoding | 是否强制编码为utf8编码(默认非BMP类型的unicode会以转义的方式来处理 | NO | false | - |
| format.filter-null-values | 是否把null字段不写进json中 | NO | false | - |
| format.bytes-as-json-node | 是否把json中byte字段当成any类型. | NO | false |
Kafka pb format
使用 pb format 需在 create table 语句中通过'format.type'='pb' 指定。参数说明如下:
| name | meaning | required | default | note |
|---|---|---|---|---|
| format.type | format 的类型,必须是 'pb' | YES | - | - |
| format.pb-class | 指定 pb class | YES | - | 样例: 'format.pb-class' = 'parser.proto.ProtoParser$Instance' |
| format.pb-skip-bytes | 解析 pb bytes 的时候忽略前几个bytes,这个是 AML 的特殊需求,普通用户请忽略 | No | 0 | 样例:'format.pb-skip-bytes' = '8' |
| format.pb-sink-with-size-header | true/false. 往外 sink pb bytes 的时候,是否在前面加上 8 字节的 pb bytes size。这个是 AML 的特殊需求,普通用户请忽略 | No | false | 样例:'format.pb-sink-with-size-header' = 'true' |
| format.ignore-parse-errors | 是否忽略解析错误的数据 | NO | false | - |
pb 中类型和 sql 中类型的映射关系:
| types in pb | sql type | note |
|---|---|---|
| repeated | ARRAY | 如: repeated int32 -> ARRAY |
| MAP | MAP | 如:map<string, int32> -> MAP<varchar, int> |
| enum | varchar | - |
| oneof | - | 会将 oneof 字段直接解到上一层,详见文末附录 |
| 其他复杂类型 | Row | - |
| double | double | - |
| float | float | - |
| int32 | int | - |
| uint32 | int | - |
| uint64 | bigint | - |
| sint32 | int | - |
| sint64 | bigint | - |
| fixed32 | int | - |
| fixed64 | bigint | - |
| sfixed32 | int | - |
| sfixed64 | bigint | - |
| bool | boolean | - |
| string | varchar | - |
| bytes | binary | - |