导航
3.3.10 Hive-Hbase
最近更新时间:2022.09.05 11:25:31首次发布时间:2022.09.05 11:25:31
使用场景
将Hive数据导入到Hbase中,供离线分析使用。
注意事项
如果未找到Hbase数据源信息,请在数据源管理中配置对应的数据源
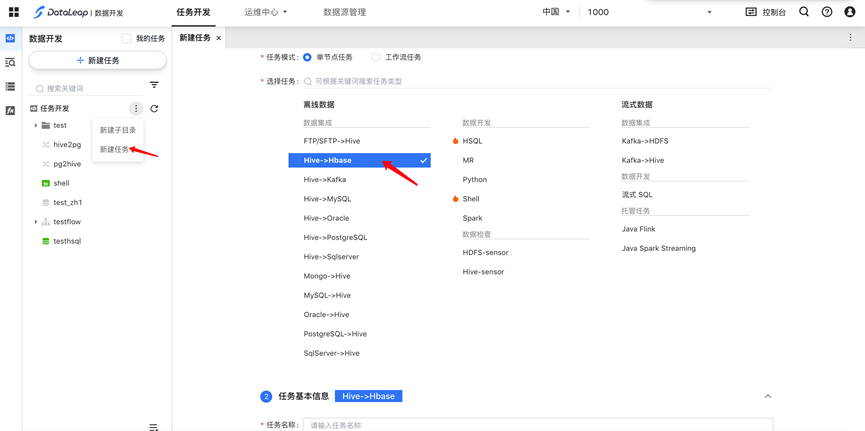
新建任务
- 在任务开发首页,点击“新建任务”
- 在项目下,左侧目录结构中新建任务
任务设置
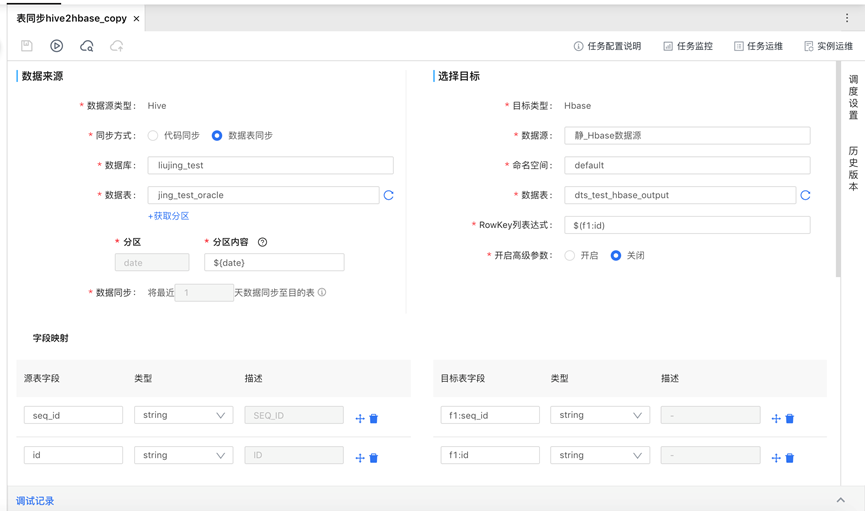
数据源信息
- 同步方式:sql同步或数据表同步
- 数据库:hive所在的数据库
- 数据表:hive目标表
- 分区:分区字段从hive表自动获取
- 天级分区,若日期格式为:yyyyMMdd 如:20181017,则填写:${date}
- 天级分区,若日期格式为:yyyy-MM-dd 如:2018-11-17,则填写:${DATE}
- 数据同步:数据同步天数,使用静态分区同步
- 数据写入方式:区分清除式写入/覆盖式写入
目标信息
- 数据源:Hbase数据源;
- 命名空间:Hbase的命名空间
- 数据表:导入目标表
- Rowkey列表达式:Rowkey列表达式
Hbase 高级参数
| 参数 | 默认值 | 备注 |
|---|---|---|
null_mode | skip | 碰到null值的处理方式: |
| wal_flag | false | 是否开启 write-ahead log功能 |
version_column | 按当前时间戳写入 | 时间戳写入模式: |
| encoding | UTF-8 | 数据编码格式 |
| write_buffer_size | 8MB | 写入缓冲区大小,单位为bytes, 8MB: 8*1024*1024 |
字段信息
字段映射在选好数据来源和目标后,hive信息可自动添加,来源于hive表结构;Hbase需要手动添加,可调整映射顺序。
数据处理高级参数设置
若下游Hbase开启鉴权,需启用高级设置,设置自定义参数
参数设置:job.reader.hadoop_conf | ipc.client.fallback-to-simple-auth-allowed=true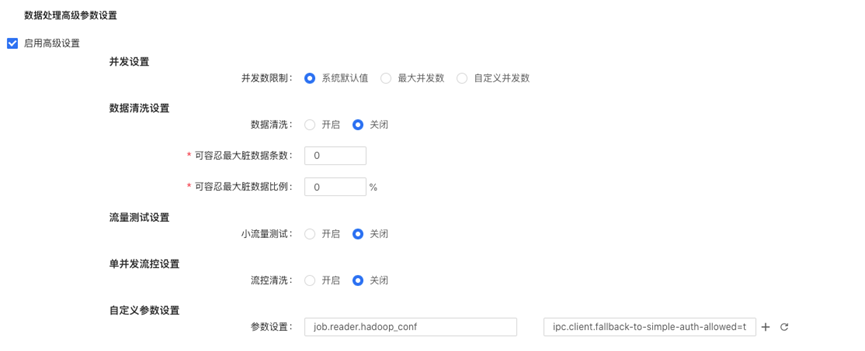
任务调试
点击调试按钮,选择业务日期进行调试,调试结果/日志可在页面查看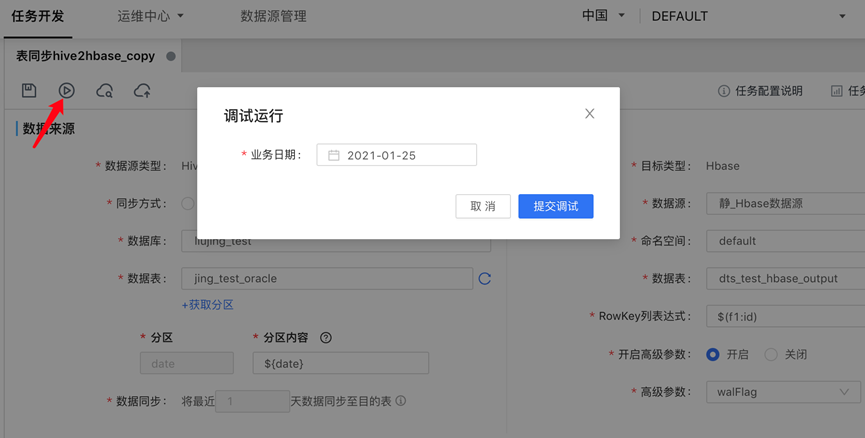
通用设置
调度设置等详见通用设置说明