导航
客户数据平台
搜索目录或文档标题搜索目录或文档标题
快速入门
用户指南
数据集成与整合
数据连接
常见数据源接入
本地文件
Web连接器
流式数据
OLAP
关系型数据库
列式数据库
文档数据库
火山引擎矩阵
可视化建模
构建标签体系
用户洞察与分析
项目与权限管理
下游营销应用
CDP x 广告平台
CDP x 火山营销套件
CDP x 云短信
开放能力
资产输出
OpenAPI
标签体系
用户分群
分析洞察
IDMapping
数据档案
在线服务
资产输出
权限服务
OpenAPI(旧)
最佳实践
业务看板最佳实践
群体画像最佳实践
多维特征分析最佳实践
生命周期分析最佳实践
私域效果分析最佳实践
- 文档首页 /客户数据平台/用户指南/数据集成与整合/可视化建模/数据处理/数据输入
数据输入
最近更新时间:2024.03.28 11:23:42首次发布时间:2024.03.28 11:23:42
我的收藏
有用
有用
无用
无用
文档反馈
1.功能概述
数据输入,是用户开始进行可视化建模的任务处理的开端,需要选择一定的数据连接,实现从数据源中获取数据输入,进而可以选择数据清洗算子或者其他处理方式。
2.操作步骤
2.1 数据输入处理
以MySQL数据连接的数据输入为例,将输入数据集推动到画布中,点击该输入算子。可以看到数据源信息,并且设置抽取的方式,进行非分区字段筛选,目前已经支持“且”与“或”的筛选逻辑,用户可以基于数据源进一步自由过滤数据。此外还可以设置抽取参数,设置预览的数据量等。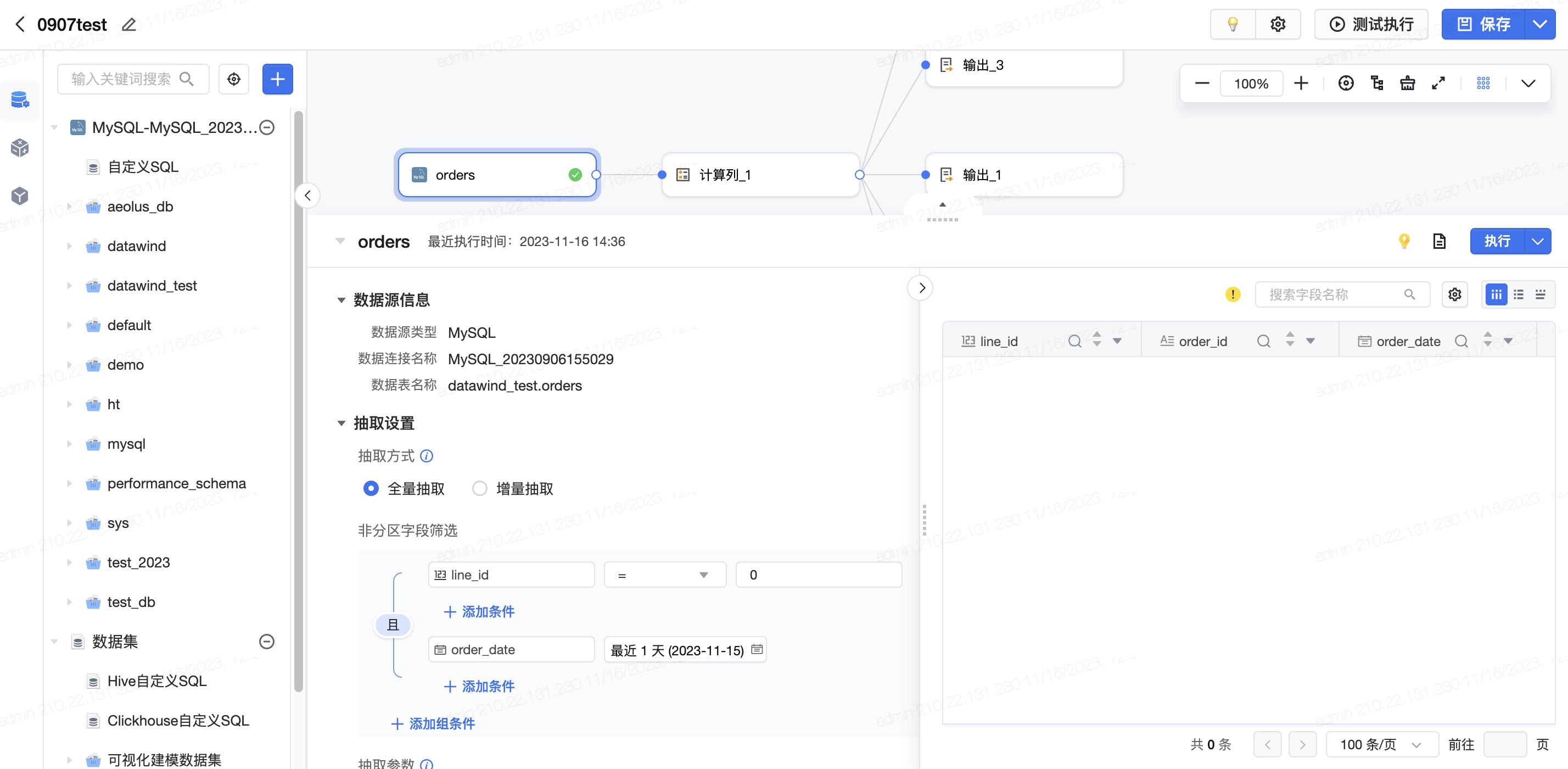
完成以上基本的数据输入处理后,用户可以进一步选择数据清洗或者特征工程等算子,实现多样的数据加工与处理。
2.2 自定义SQL
可视化建模支持对大部分离线存储的数据输入做自定义SQL,实现基本的数据加工。在任务创建的数据连接环节,如果用户选择了数据集,那么在左侧画布中会显示:自定义SQL(离线任务可显示)、可视化建模数据集、智能数据洞察数据集、客户数据平台数据集(如同时购买并部署该产品)。其中自定义SQL简介如下:
- Hive/ClickHouse自定义SQL:
Hive:可视化建模输出并且数据存储为Hive类型数据集,可以写SQL,满足Hive语法即可
ClickHouse:可视化建模输出并且数据存储为Clickhouse数据集,可以写SQL,满足ClickHouse语法即可
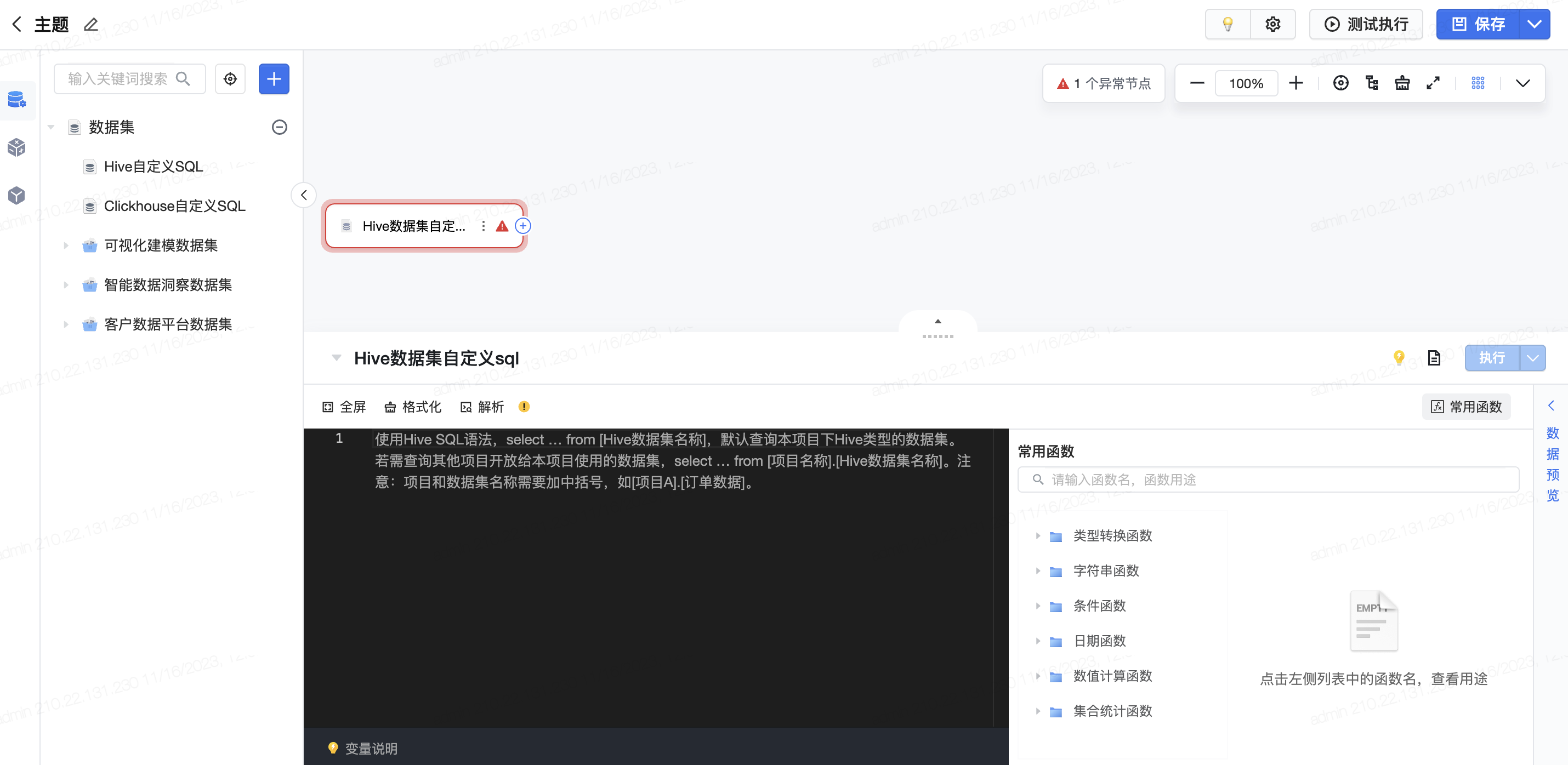
可视化建模中自定义SQL的配置界面,用户可以进行重命名、添加描述、复制与删除等操作。通常作为首个算子节点时,不支持“执行该节点”、“执行到此处”等。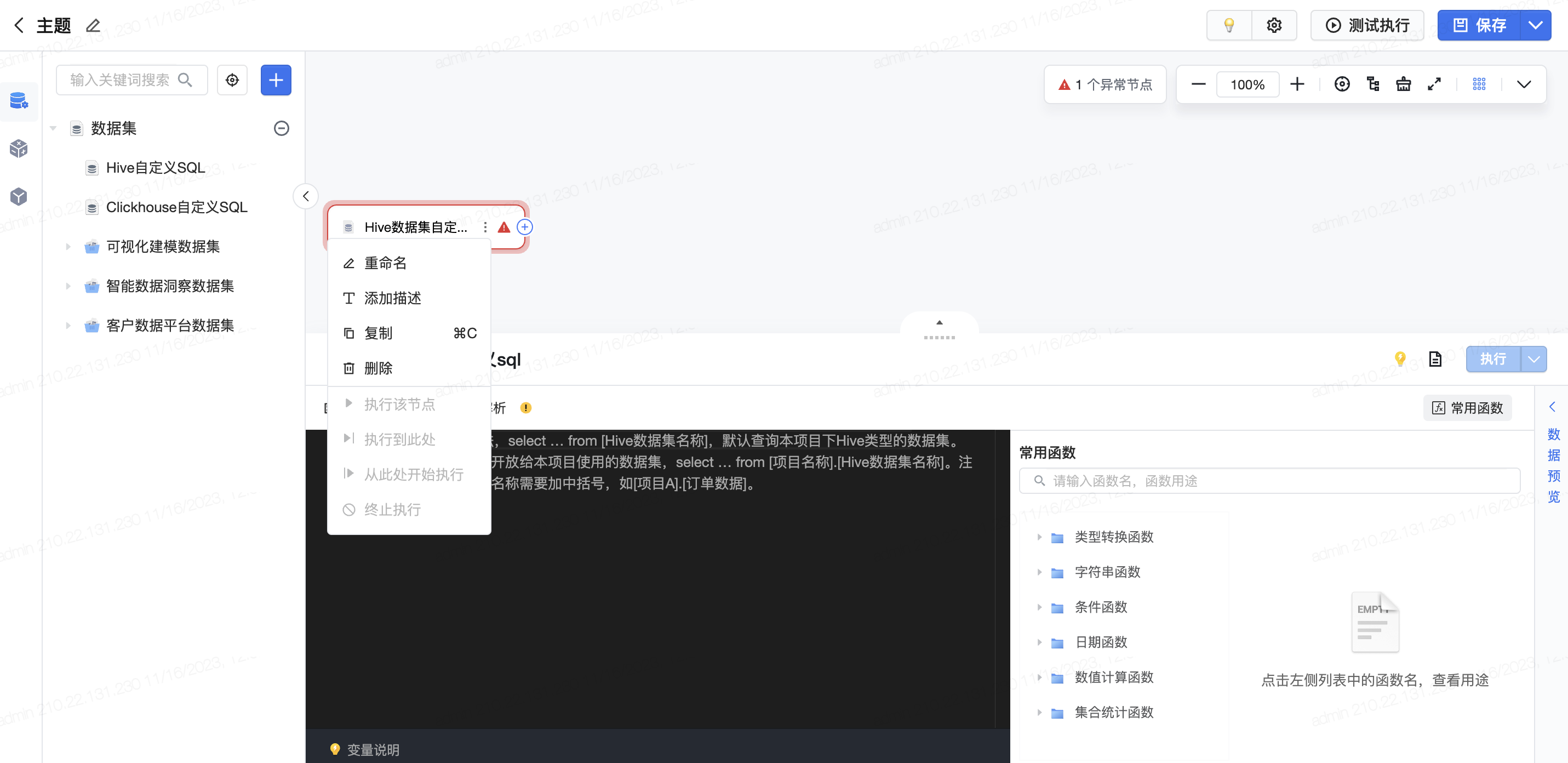
在编辑区域中,为您准备了常见函数库,包括函数用途说明、命令格式、示例等。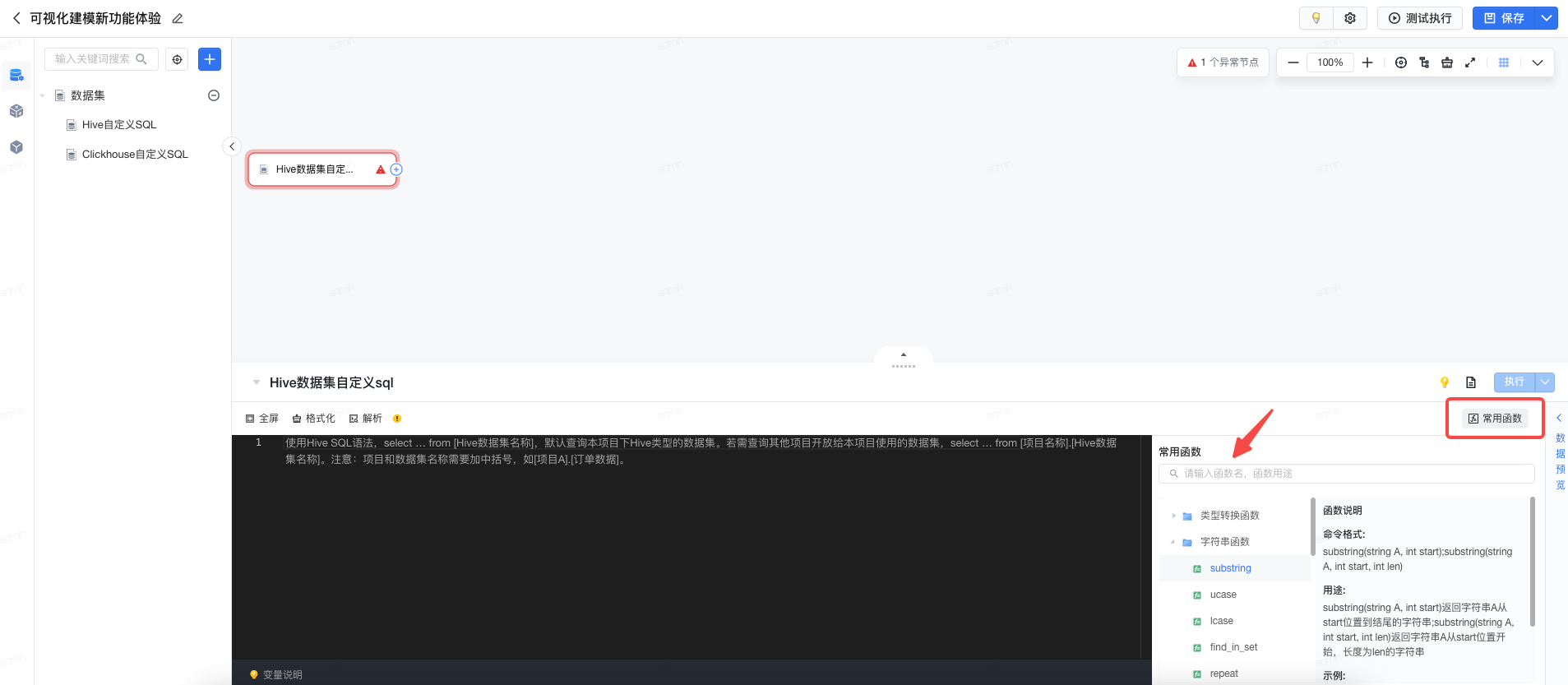
如果已经编辑完成,用户可点击预览进行查看。