唯一键(Unique表):主要用于确保表中某一列或多列数据的唯一性,当为一列或多列设置唯一键时,插入或更新数据时会检查这些列的值是否已经存在,从而保证数据按照唯一键去重。
可视化建模输出节点,可以通过将指定的字段(列)设置为唯一键(Unique Key),实现数据写入时按照唯一键进行去重,在保证唯一过程中,可以设置去重的取值逻辑(如遇重复时,保留最新的结果或保留最原始的结果),按照需求保留想要的唯一结果值。
注意
该功能非默认开启功能,如需要使用请在部署时打开。
场景1:用户有一张全量订单表,希望查询订单创建日期下最新订单状态的订单数据,对于历史过程数据没有需求。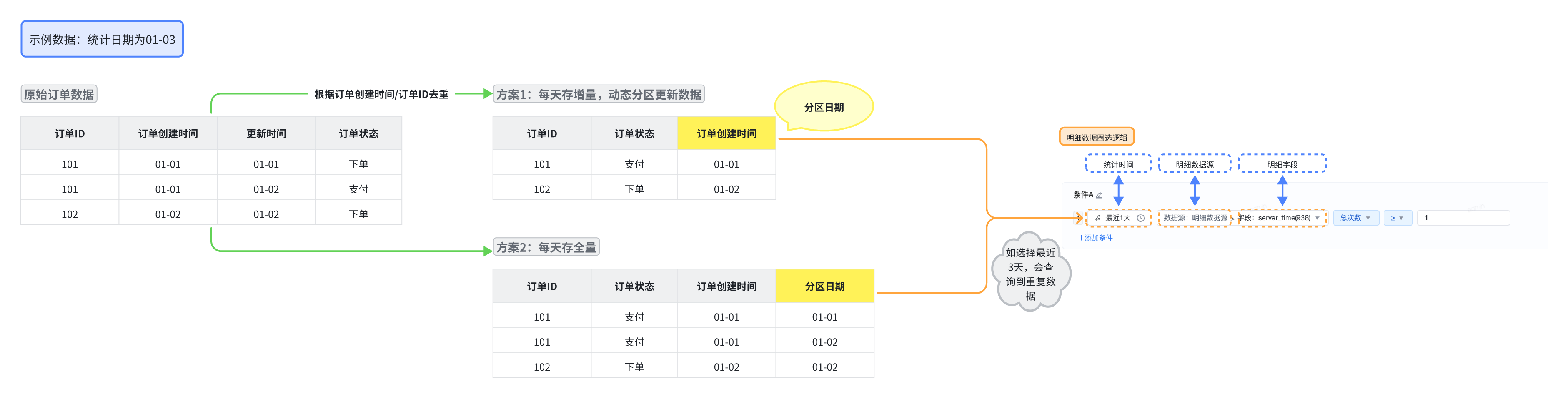
实现逻辑如下:
方案1: 每天清洗全量数据进行去重,然后将订单创建时间作为分区,设置动态分区更新
优势:只需要存在一份数据,资源消耗相对较少
劣势:动态分区是覆盖写入,存储上存在性能限制
方案2: 每天清洗全量数据进行去重,然后每天分区存储全量数据,查询时查最近一个分区
优势:操作相对简单,去重逻辑相对好实现
劣势:
1. 存储成本增加,如需配置尽可能设置生命周期在较短范围内
2. 分区无具体业务含义,下游查询时如按照分区日期查询可能查到重复数据,需约定按照全量逻辑查询,且每次查询要查询全量数据,查询性能较差(即分区限制最新分区,然后按照订单创建时间进行统计)
说明
综上概述: 方案2相对更灵活,但是VeCDP产品下游圈选组件适配比较复杂,且查询性能无法保证。
场景2:在场景1的基础上,用户希望存储订单每个状态首次变更的时间,即按照订单状态+订单更新时间分区排序取最早的值,但是表里面会记录订单变化的日志
实现逻辑:
方案1:参照场景1的逻辑无法实现,没办法按照多级分区排序取值
方案2:利用窗口函数排序取值,每天存储全量数据
概述: 该场景只能选择方案2,但存在下游查询适配的风险
说明
针对以上场景,如用户希望上述两个场景输出的结果数据作为明细数据,场景1-方案1可以支持配置,但是受限性能和分区限制;方案2则存在查询异常,因为明细数据档案要求数据结构为增量数据,标签或分群圈选组件筛选时统计日期等同于分区日期,用户使用时如选择非最近1天,最终结果可能数据异常。
基于增量更新且保证主键唯一的逻辑场景,又可以支持下游快速查询,支持唯一键(Unique表)配置能力,可实现:
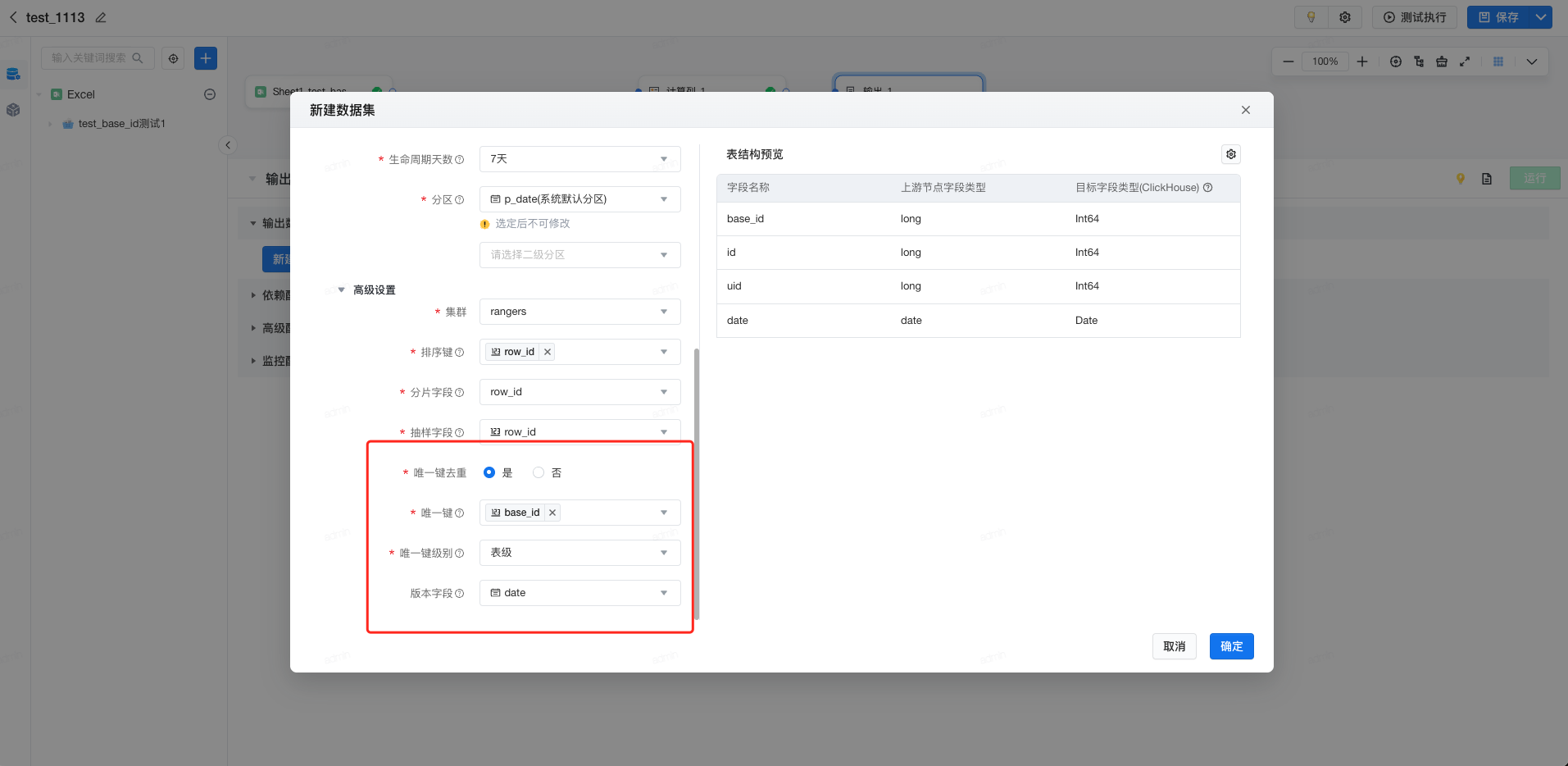
设置唯一键,并且可设置多个字段,如存在多个字段,则多个字段的组合结果进行去重唯一
设置唯一键级别,支持全表唯一和分区级别唯一
设置版本字段,支持按照某个字段进行排序取值,仅支持Date/DateTime类型字段
设置版本排序,根据版本字段进行正序取值
注意:唯一键的逻辑是在分片(Sharding)基础上实现的,即相同节点内数据去重唯一
针对场景1:可设置订单创建日期为分区,订单ID为唯一键,设置分区粒度唯一
针对场景2:可设置订单创建日期为分区,订单ID+状态为唯一键,设置分区粒度唯一,版本时间为订单更新时间
| 步骤 | 功能入口 | 操作说明 | 操作截图 |
|---|---|---|---|
1 | 可视化建模-新建数据集-高级配置 |
|
|
| 2- 选填 | VeCDP场景联动 | 1. 仅支持VeCDP应用为普通数据集及明细数据配置唯一键,其余类型数据档案会默认配置相应数据结构 | 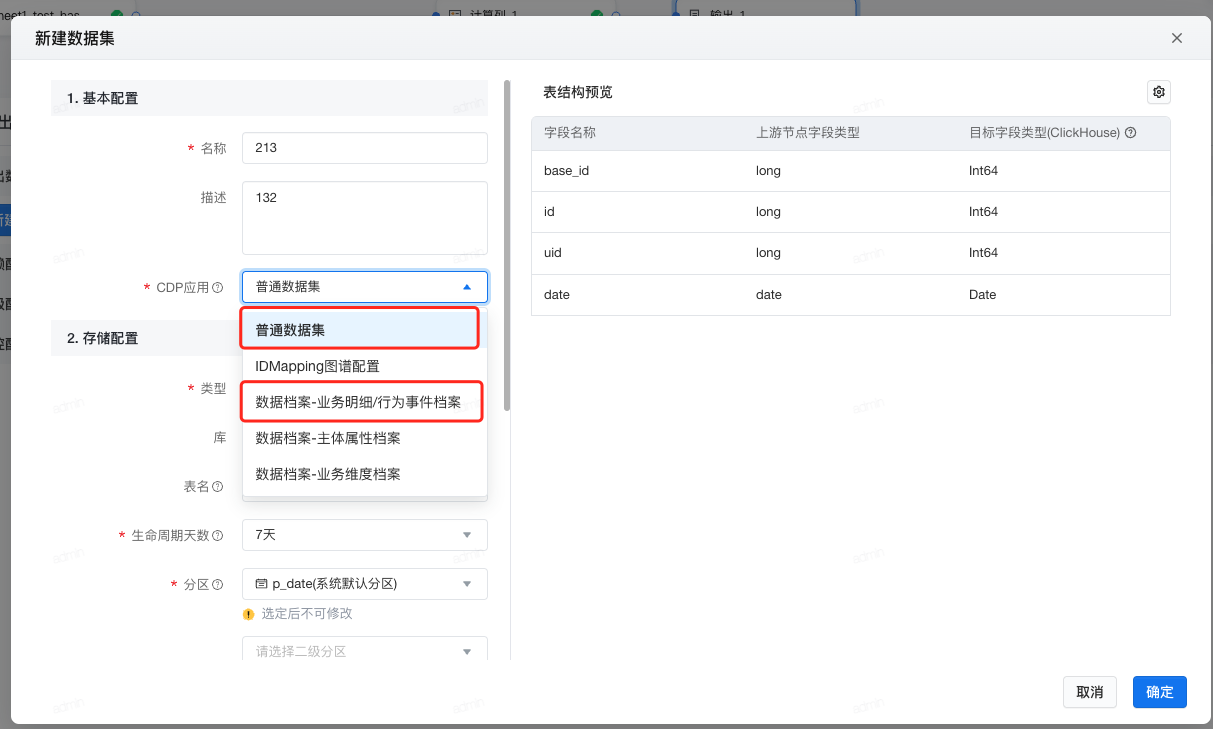 |
注意:唯一键去重功能首次初始化时涉及多分区数据导入,写入数据相对较慢,其次数据更新建议增量更新,避免导入的分区过多。
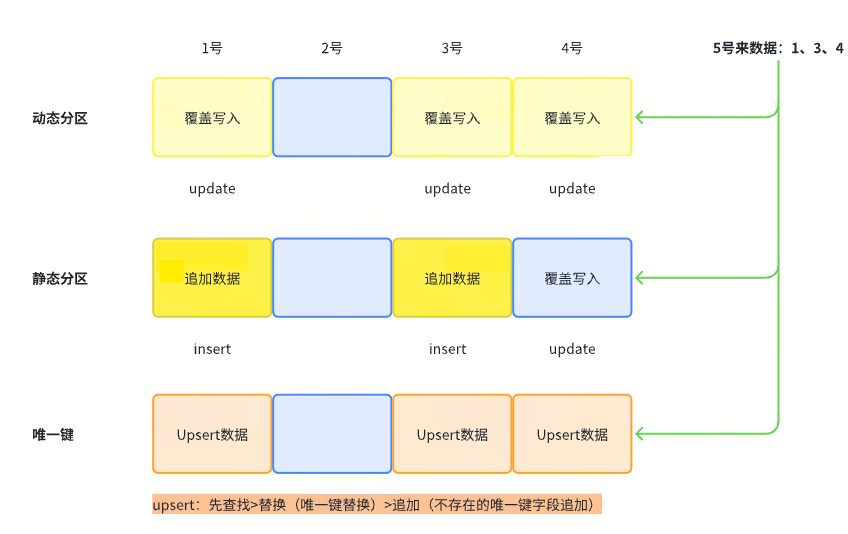
| 功能 | 功能说明 | 差异对比 |
|---|---|---|
静态分区 | 默认的数据写入方式,按照离线更新数据的方式,如果涉及多个分区的数据更新,此时仅会对最近一个分区数据的数据执行先清空分区再写入数据,历史分区只会增量导入数据 |
|
| 动态分区 | 需要在高级配置中打开动态分区开关,涉及到数据更新的分区,都会执行先清空分区再写入数据的更新逻辑 | |
| 唯一键(Unique表) | 根据唯一键字段及版本字段,寻找已有的唯一键字段并判断去重,执行更新操作(Upsert操作) |