实时数据接入,是指支持通过对接实时数据源,将实时数据接入系统中。
注意
SaaS支持对接火山Kafka;私有化支持对接火山Kafka、开源火山Kafka和Pulsar
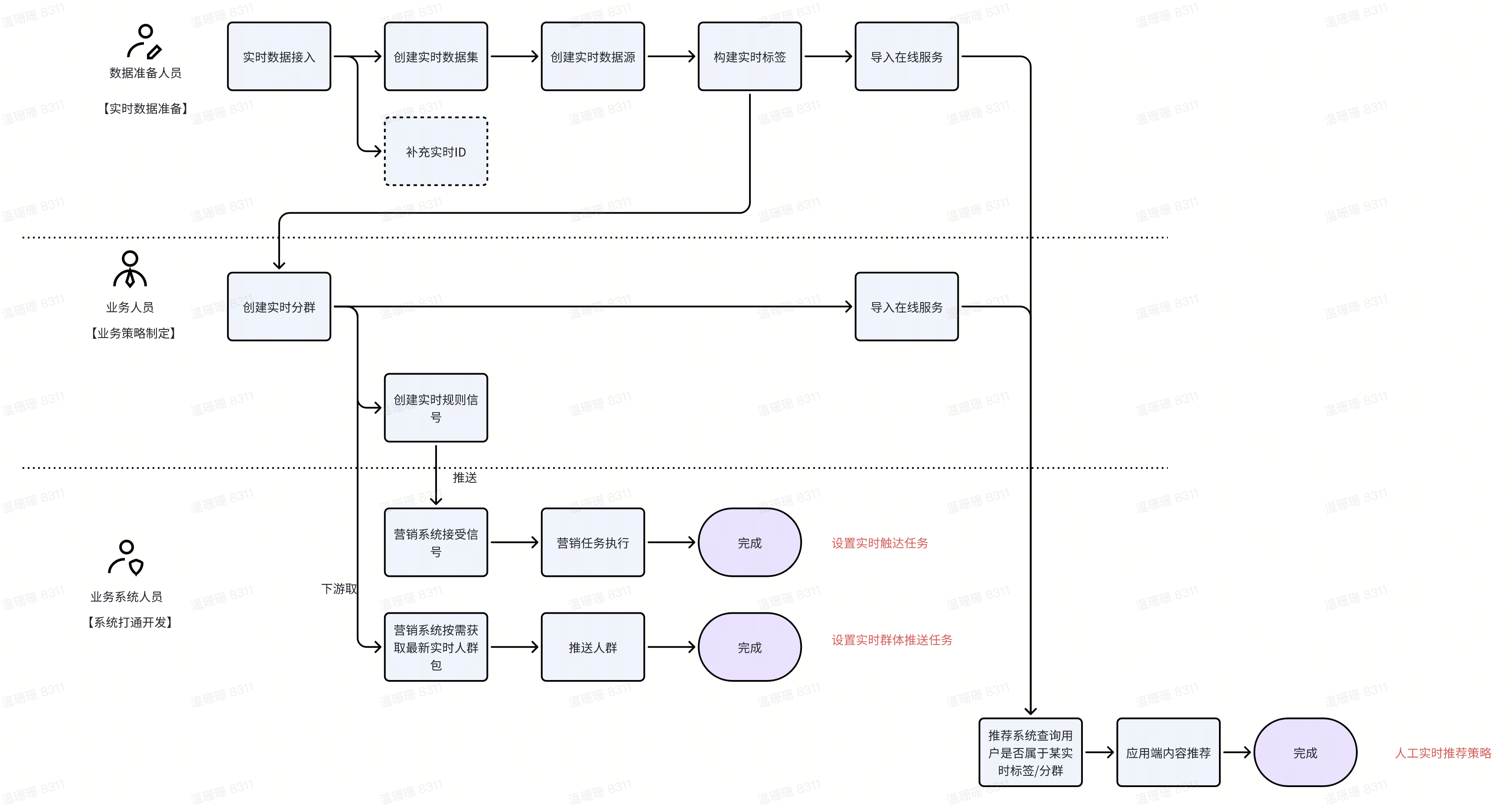
2.1 新建Kafka数据连接
点击 数据融合 > 数据连接 。
在数据连接目录左上角,点击 新建数据连接 按钮,在跳转的页面选择 Kafka 。
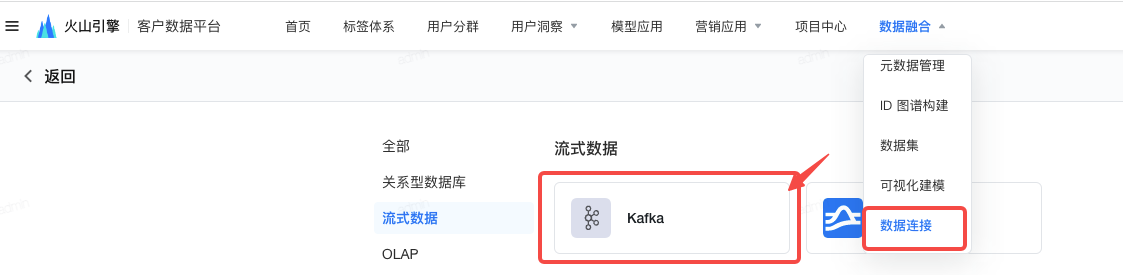
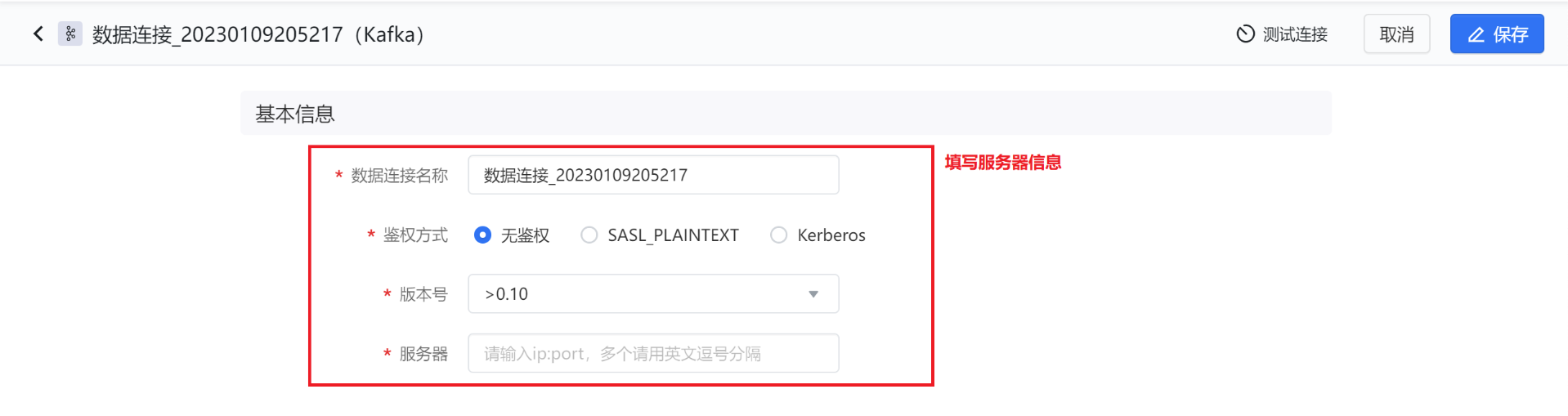
- 填写所需的基本信息,并进行 测试连接 。
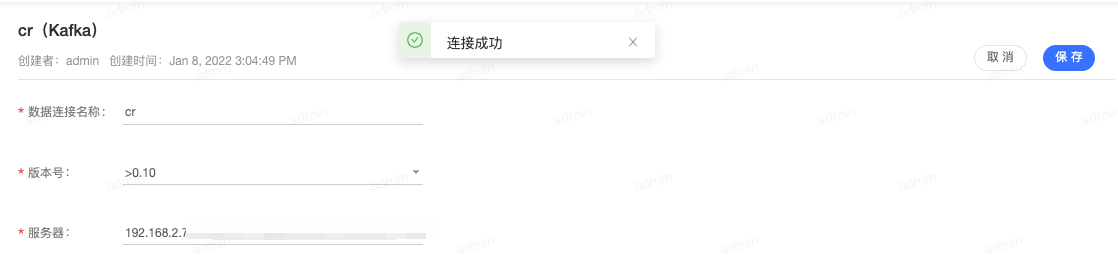
- 连接成功后点击 保存 即可。
2.2 新建实时数据集
说明
在新建实时数据集前,请先明确后续需要使用实时明细表还是实时行为表,两者对数据格式的要求略有不同。
实时明细表
对于实时明细数据源,目前仅需要提供id字段、时间分区字段(建议再提供一个时间戳字段)。例如:
// 在该json中,uid为id字段,p_date为时间分区字段,其余均为业务字段。 {"uid":"abcd123456", "p_date":"2023-03-16", "timestamp":1678937019232, "cost":22.0, "item":"apple", "vip":"yes"}
实时行为表
对于实时行为数据源,需要提供id字段、事件字段、时间戳字段、分区字段、事件属性字段(若有)。例如:
// 在该json中,uid为id字段,p_date为时间分区字段,timestamp为时间戳字段,event为事件字段,string_map为事件属性。 // 该json代表用户abcd123456发生了一个openApp事件,appName为tiktok {"uid":"abcd123456", "p_date":"2023-03-16", "timestamp":1678937019232, "event": "openApp", "string_map":{"appName":"tiktok"}}
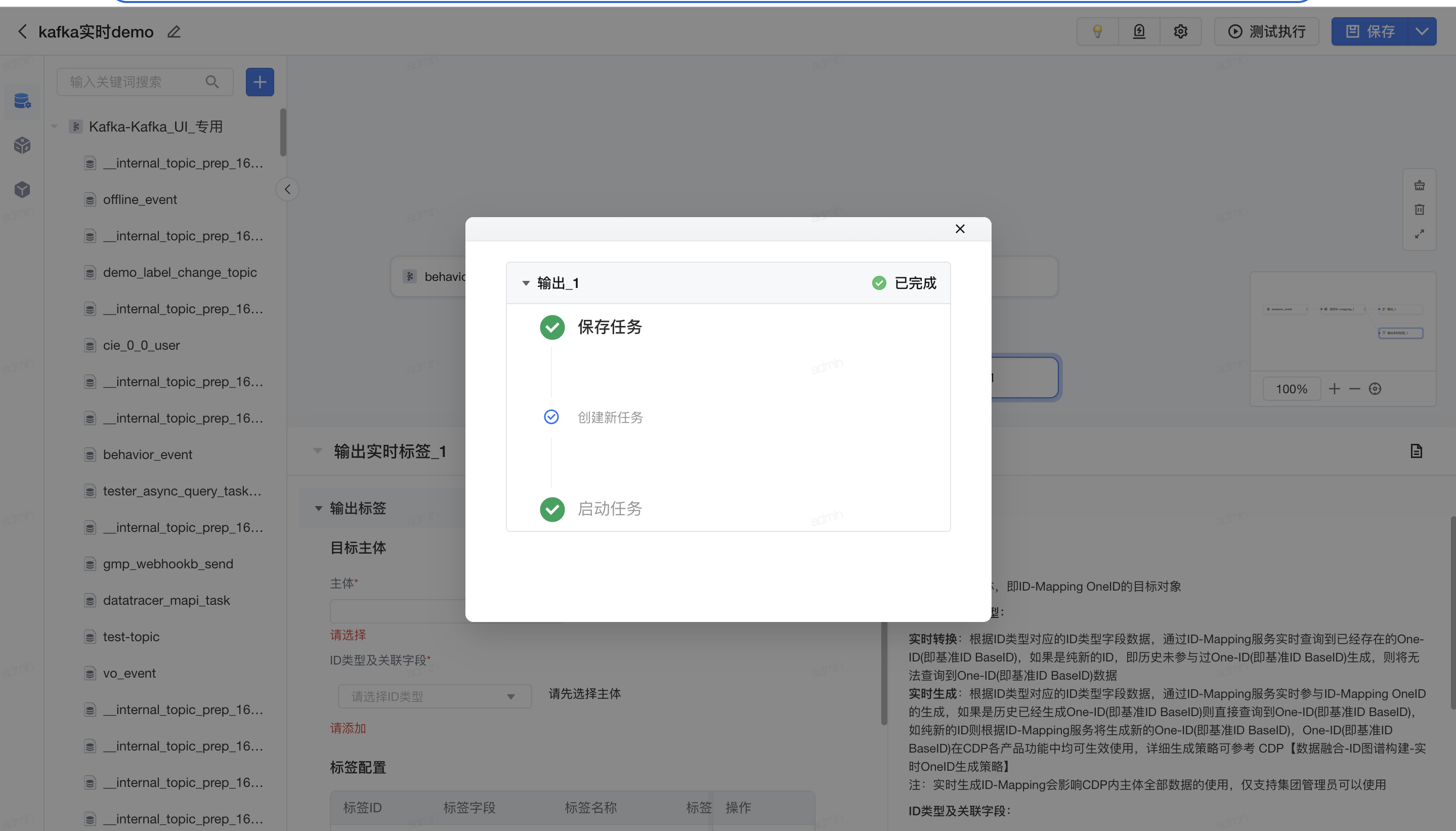
- 点击 数据融合>可视化建模, 创建新任务,选择实时任务。
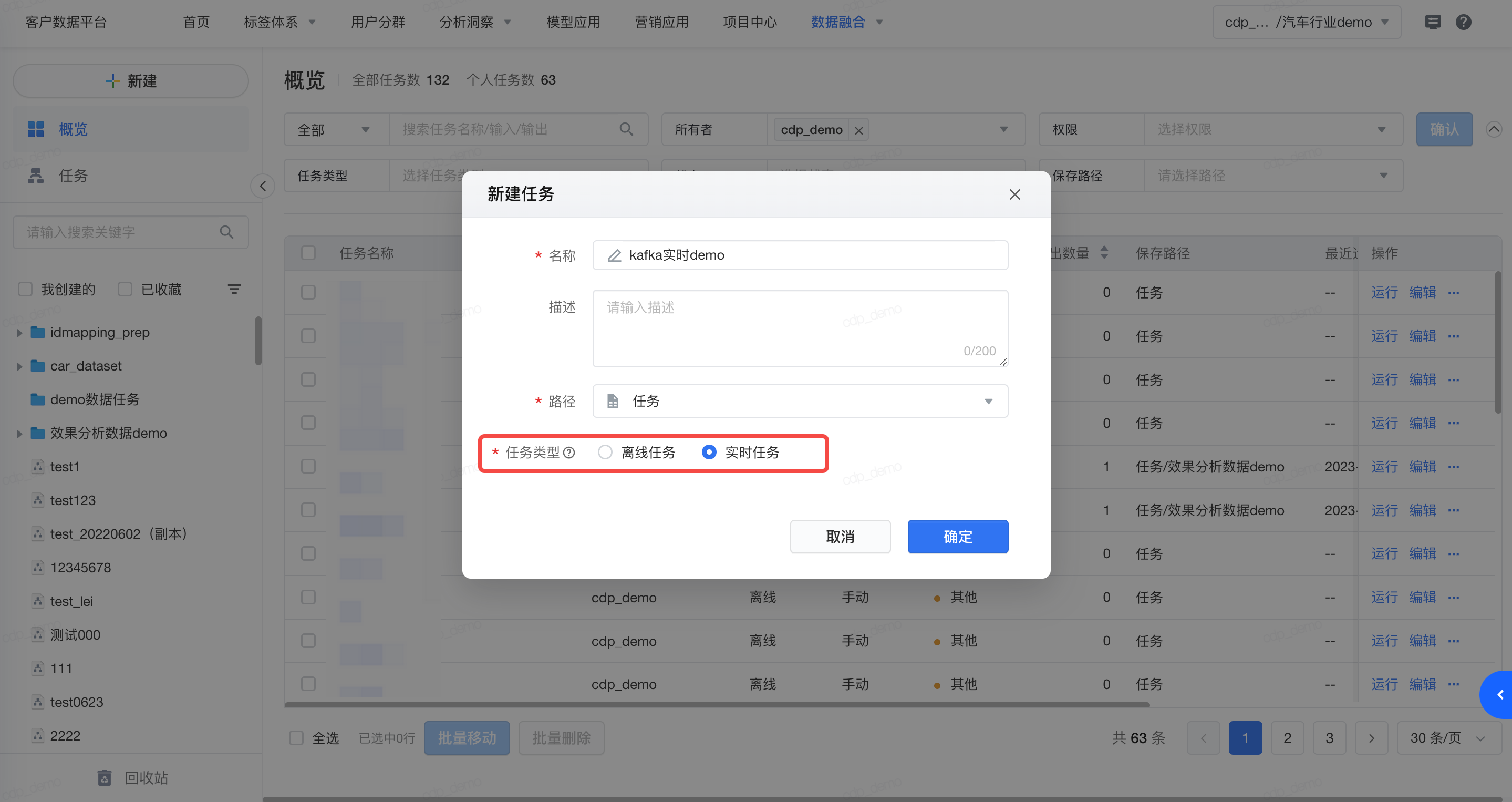
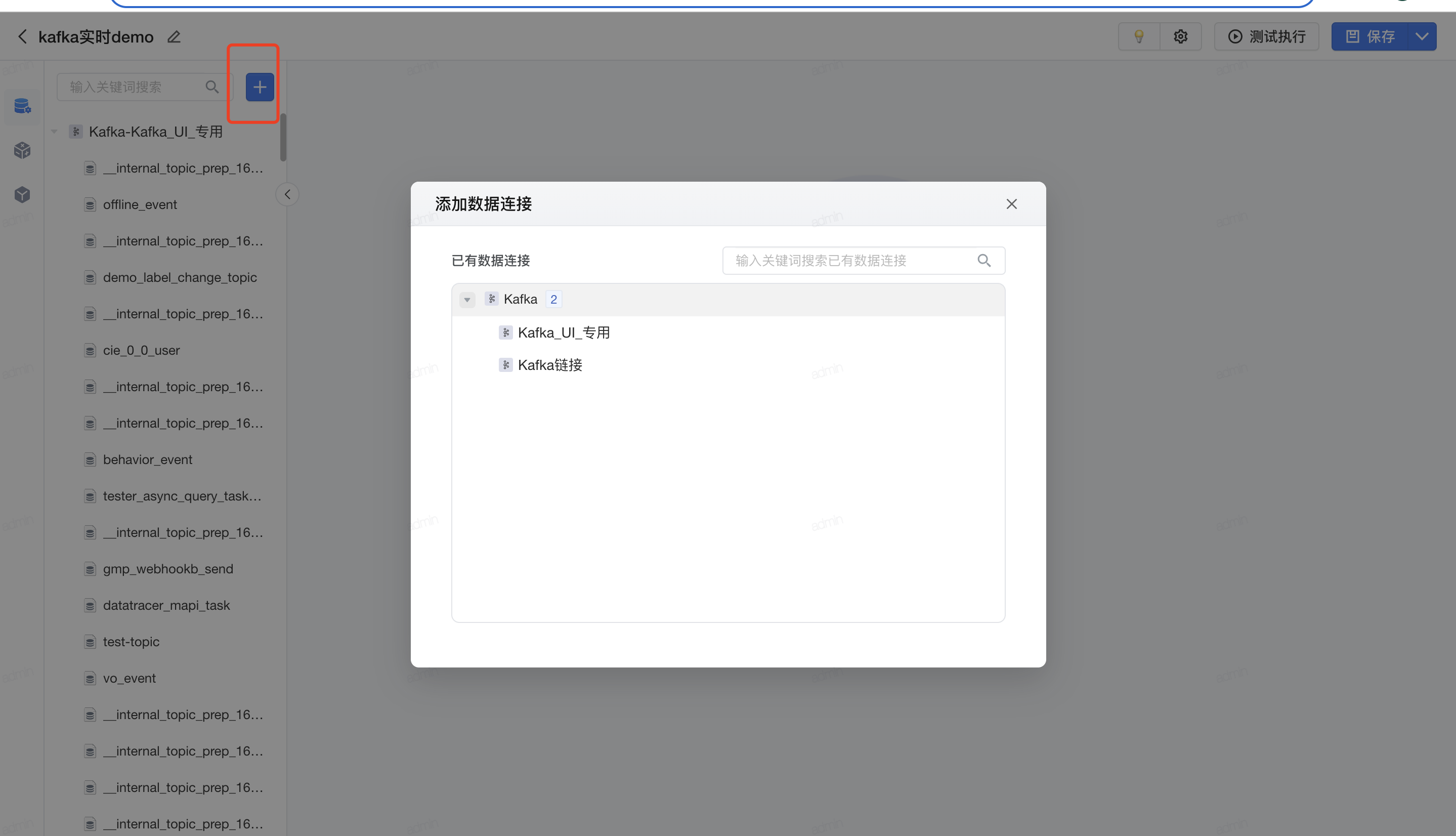
- 添加数据连接,选择前序已创建的实时数据连接、选择接入的kafka topic。
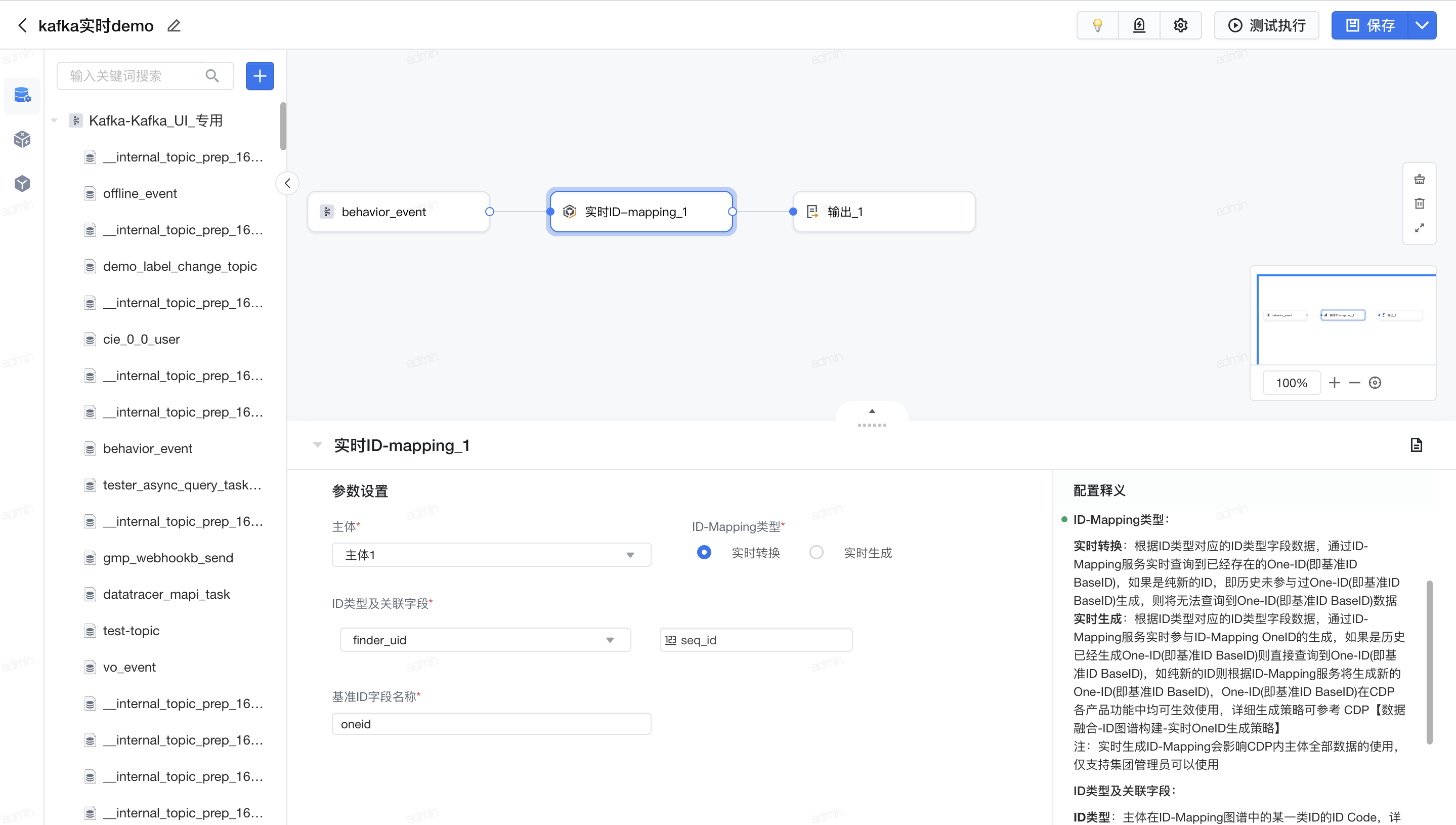
- 添加IDM算子生成OneID
确认是否无法和匹配历史已有ID新增or删除实时转换:根据ID类型对应的ID类型字段数据,通过ID-Mapping服务实时查询到已经存在的One-ID(即基准ID BaseID),如果是纯新的ID,即历史未参与过One-ID(即基准ID BaseID)生成,则将无法查询到One-ID(即基准ID BaseID)数据
实时生成:根据ID类型对应的ID类型字段数据,通过ID-Mapping服务实时参与ID-Mapping OneID的生成,如果是历史已经生成One-ID(即基准ID BaseID)则直接查询到One-ID(即基准ID BaseID),如纯新的ID则根据ID-Mapping服务将生成新的One-ID(即基准ID BaseID),One-ID(即基准ID BaseID)在CDP各产品功能中均可生效使用,详细生成策略可参考 CDP【数据融合-ID图谱构建-实时OneID生成策略】
- 输出实时数据集
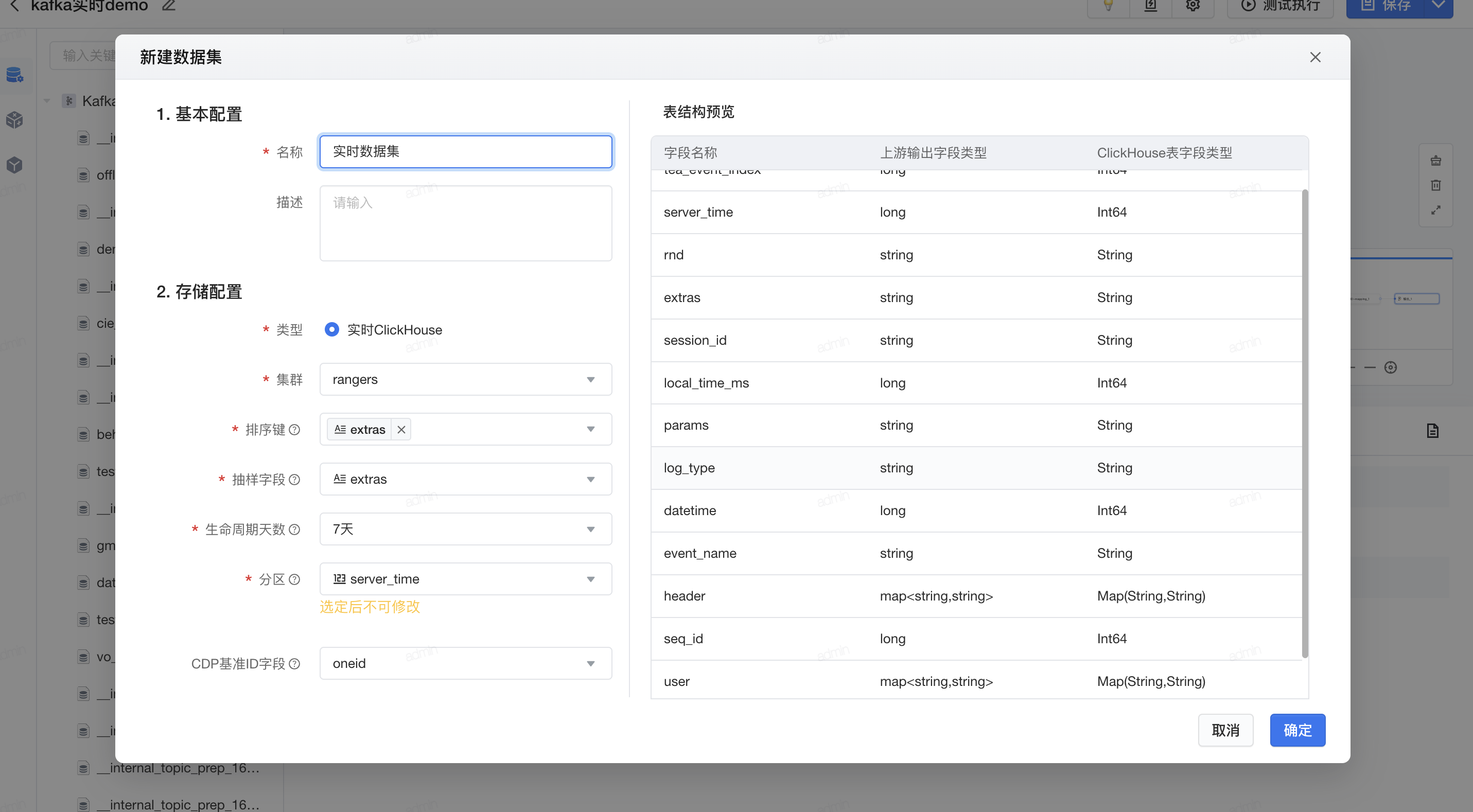
- 分区键需要能被toDate/toDateTime。仅支持使用int类型的时间戳(支持秒/毫秒级),或者'2020-01-01'/'2020-01-01 00:00:00'格式的字符串。 推荐使用int类型时间戳。 如果使用json建表,json中分区键的值也应遵守上面的规则。
分区键设置示例: ①int类型时间戳,字段类型选择Int64。 ②string类型日期'2020-01-01',字段类型选择Date。 ③string类型日期'2020-01-01 00:00:00',字段类型选择DateTime。
嵌套字段提取: 当存在多层嵌套时,可输入json path提取字段。 示例:
{ "body": { "cost": { "city": "Shanghai", "country": "China" } } }
若需要提取字段city,则json.path为body.cost.city
- 新建任务成功
2.3 新建实时数据源
- 点击 数据融合>元数据管理 。
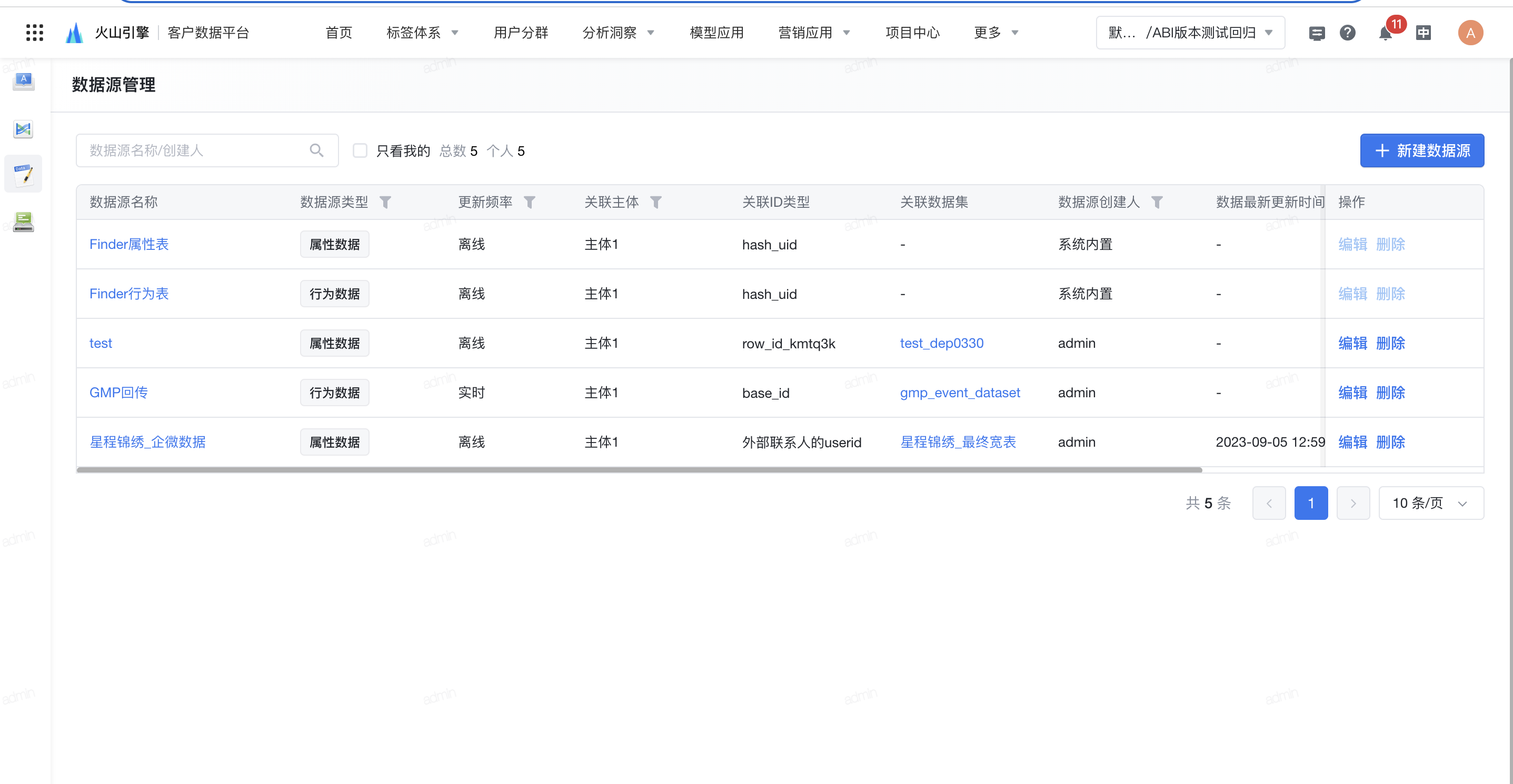
- 新建数据源
选择上述新建数据集, 应用此表 ,进行类型设置。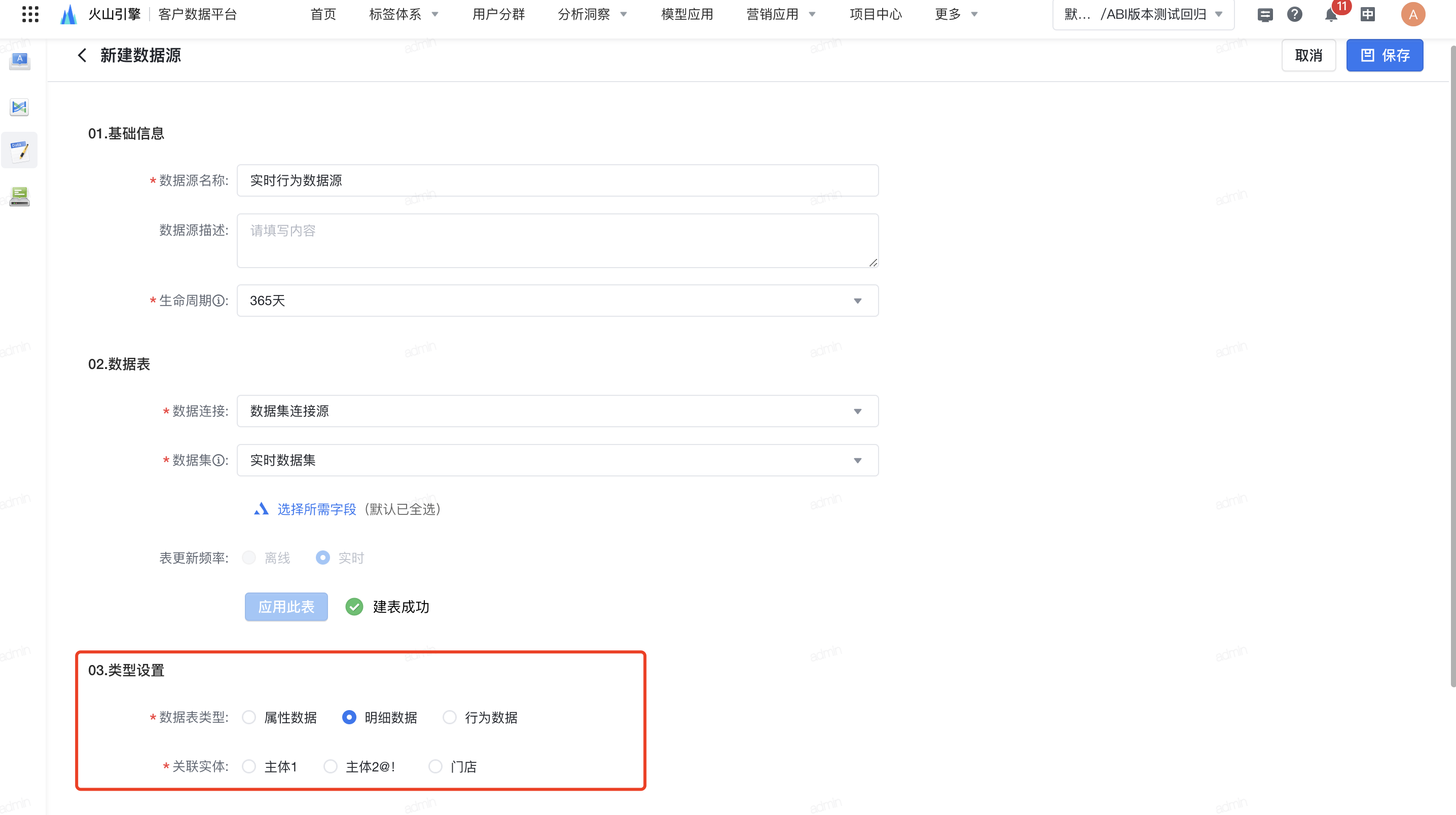
- 完成配置后,点击 保存 即可。