导航
机器学习平台
搜索目录或文档标题搜索目录或文档标题
产品动态
产品计费
快速入门
用户指南
资源组
自定义任务
在线服务
AI加速引擎
最佳实践
LLM
- 文档首页 /机器学习平台/用户指南/工作流/运行工作流
运行工作流
最近更新时间:2023.07.07 14:56:11首次发布时间:2023.07.07 14:56:11
我的收藏
有用
有用
无用
无用
文档反馈
平台支持通过控制台(Web页面)和SDK运行工作流,此处介绍如何通过控制台运行工作流,使用SDK运行工作流请查看工作流SDK使用文档
- 在工作流详情页,点击页面右上角的【运行】,填写工作流的运行名称、工作流的运行参数,即可提交运行
- 可在【运行记录】,查看当前工作流的所有运行记录
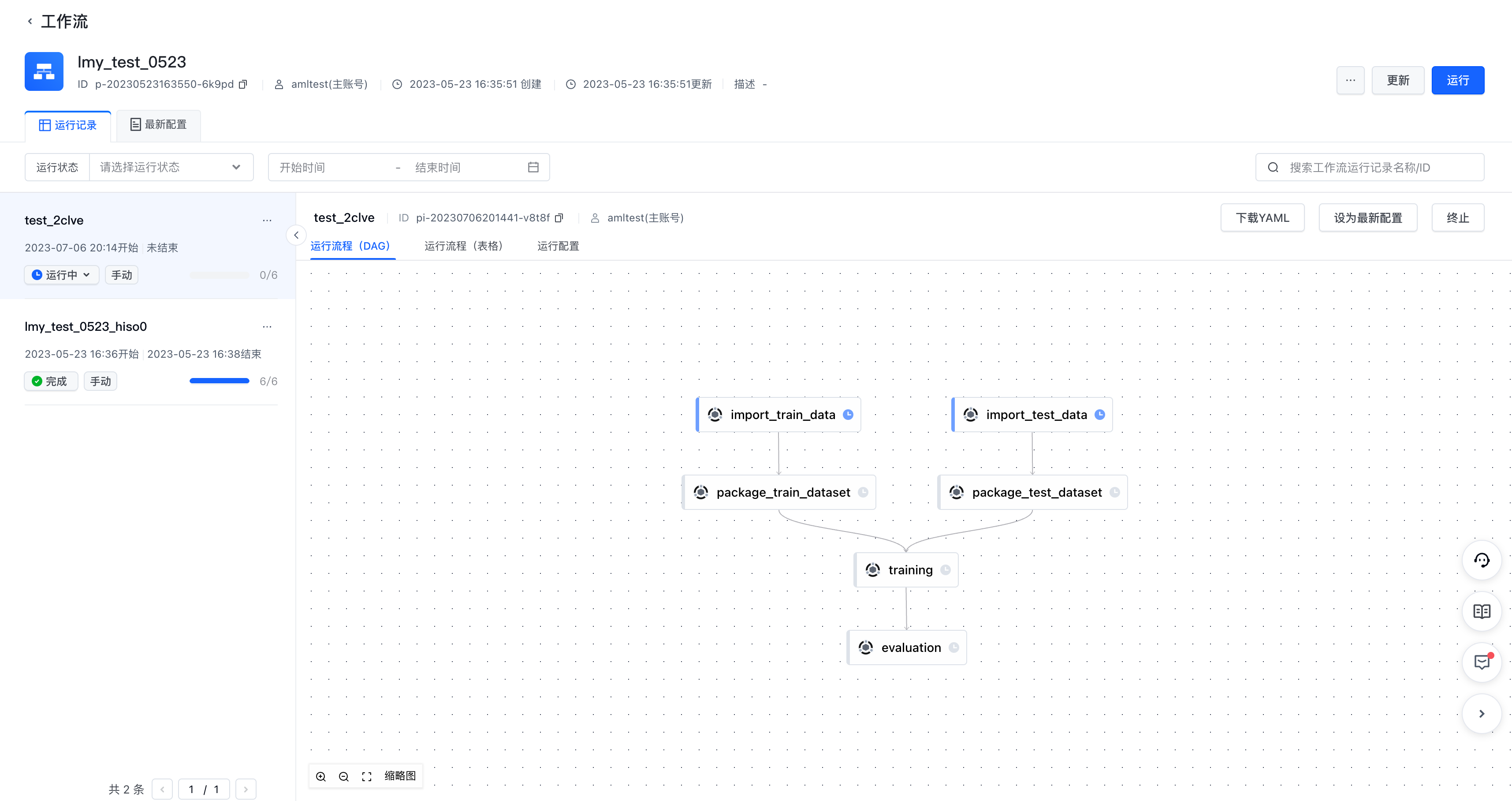
- 左侧列表中,展示工作流整体运行状态
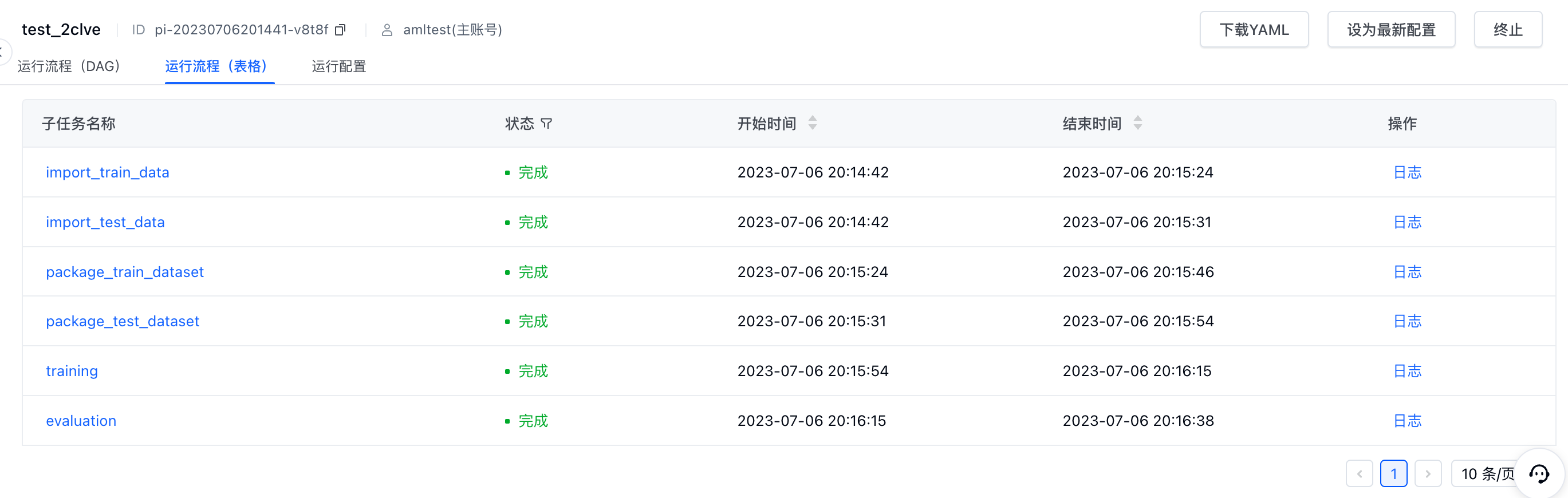
- 右侧可查看工作流各节点运行状态,支持切换至表格形式查看
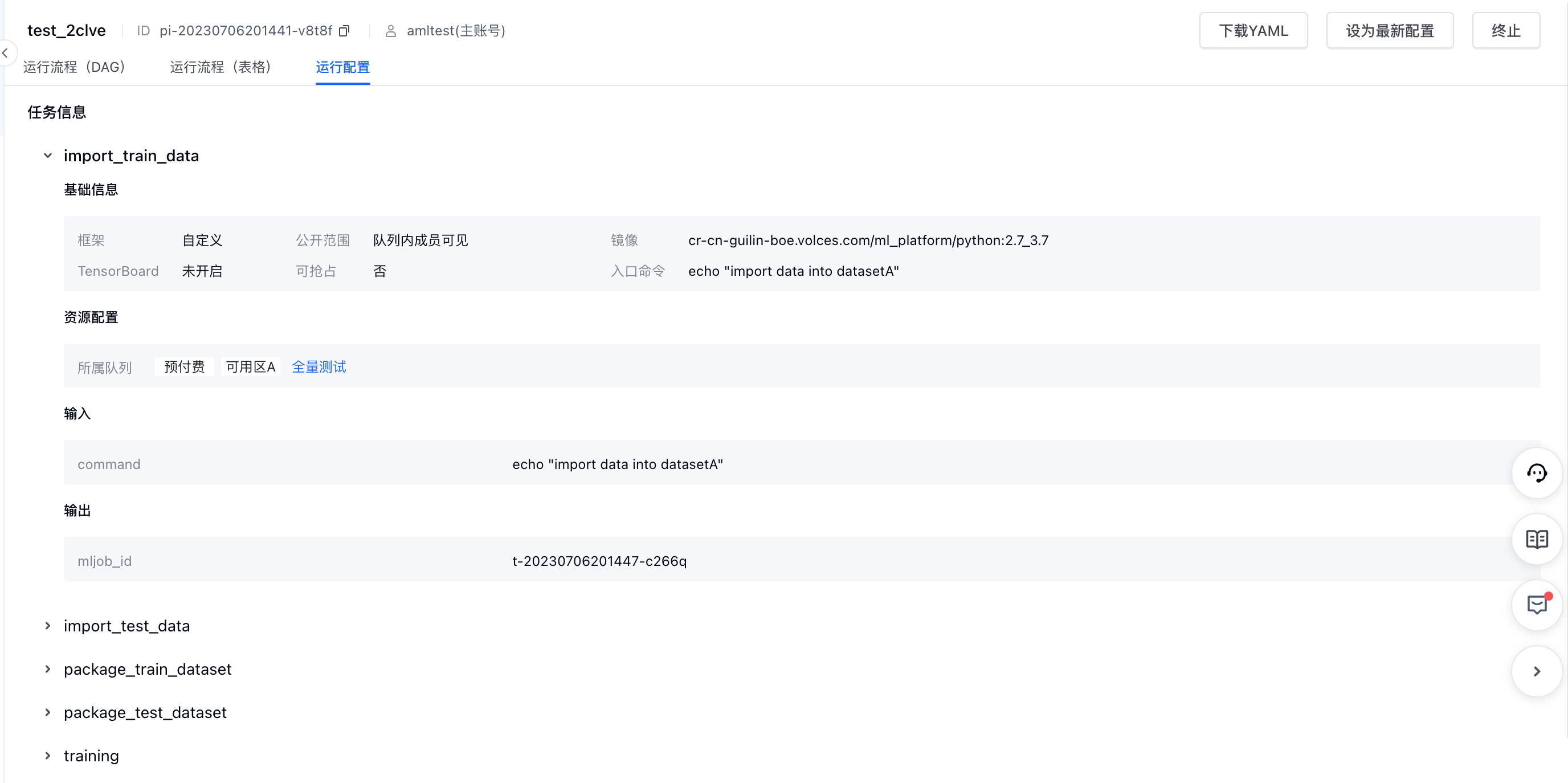
- 点击节点,可查看任务详情/日志
- 可切换至运行配置,查看工作流详细配置信息