wget https://ml-platform-public-examples-cn-beijing.tos-cn-beijing.volces.com/python_sdk_installer/volcengine_ml_platform-1.1.7-py3-none-any.whl && pip install volcengine_ml_platform-1.1.7-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
在正式使用 SDK 之前需要先完成火山引擎账号的 AK / SK 的本地配置,用以在使用 SDK 访问机器学习平台时的身份校验。
- 登录火山引擎控制台并前往【密钥管理】查看当前账号的 AK / SK。
- 若当前账号为子账号,需要具备
AccessKeyFullAccess的 IAM 策略。
- 若当前账号为子账号,需要具备
请使用真实的 AK/SK 替换下列方法中的 <your access key> 和 <your secret access key>
方法一(通过配置文件配置):
mkdir -p $HOME/.volc cat <<EOF > $HOME/.volc/credentials [default] access_key_id = <your access key> secret_access_key = <your secret access key> EOF cat <<EOF > $HOME/.volc/config [default] region = cn-beijing # 填写所在地域,目前仅支持 cn-beijing EOF
方法二(通过代码配置):
import volcengine_ml_platform as vemlp vemlp.init( ak='<your access key>', sk='<your secret access key>', region='cn-beijing', )
方法三(通过环境变量配置):
export VOLC_ACCESSKEY='<your access key>' export VOLC_SECRETKEY='<your secret access key>' export VOLC_REGION=cn-beijing
指定实验项目和实验名称
通过init()定义当前训练的实验名称(name)以及希望被托管的实验项目(project),开始运行后即可通过「实验管理」模块在对应的项目内查看该次实验的数据和信息。
wandb.init( project="${experiment_name)", name="$(trial_name)", notes="$(trial_description)", tags="baseline" )
配置项:
project,必要参数。为实验项目的名称。长度上限128,支持中英文、数字及-_./@。
name,非必要参数。为当前实验的名称,长度上限128,支持中英文、数字及-_./@;如不指定,系统会随机生成
notes,非必要参数。为当前实验的描述,默认为空字符串
Tags, 非必要参数。为当前实验的标签信息,后续可用于分组归类和快速筛选
超参数记录
通过config指定或修改本次实验的超参数
更多示例请参考https://docs.wandb.ai/guides/track/config?q=config
#直接定义固定超参数数值,可在后续进行修改 wandb.init(config={"lr": 0.05}) wandb.config.epochs = 10 #config支持dict, argparse.Namespace, absl.FLAG,tf.app.flags。以下通过argparse作为示例 parser = argparse.ArgumentParser() parser.add_argument('-b', '--batch-size', type=int, default=84, metavar='N', help='input batch size for training (default: 64)') args = parser.parse_args() wandb.config.update(args) # 将所有的arguments作为超参数传入
记录为config的超参数数据,可在概述页面进行查看,并和其他trial进行对比。
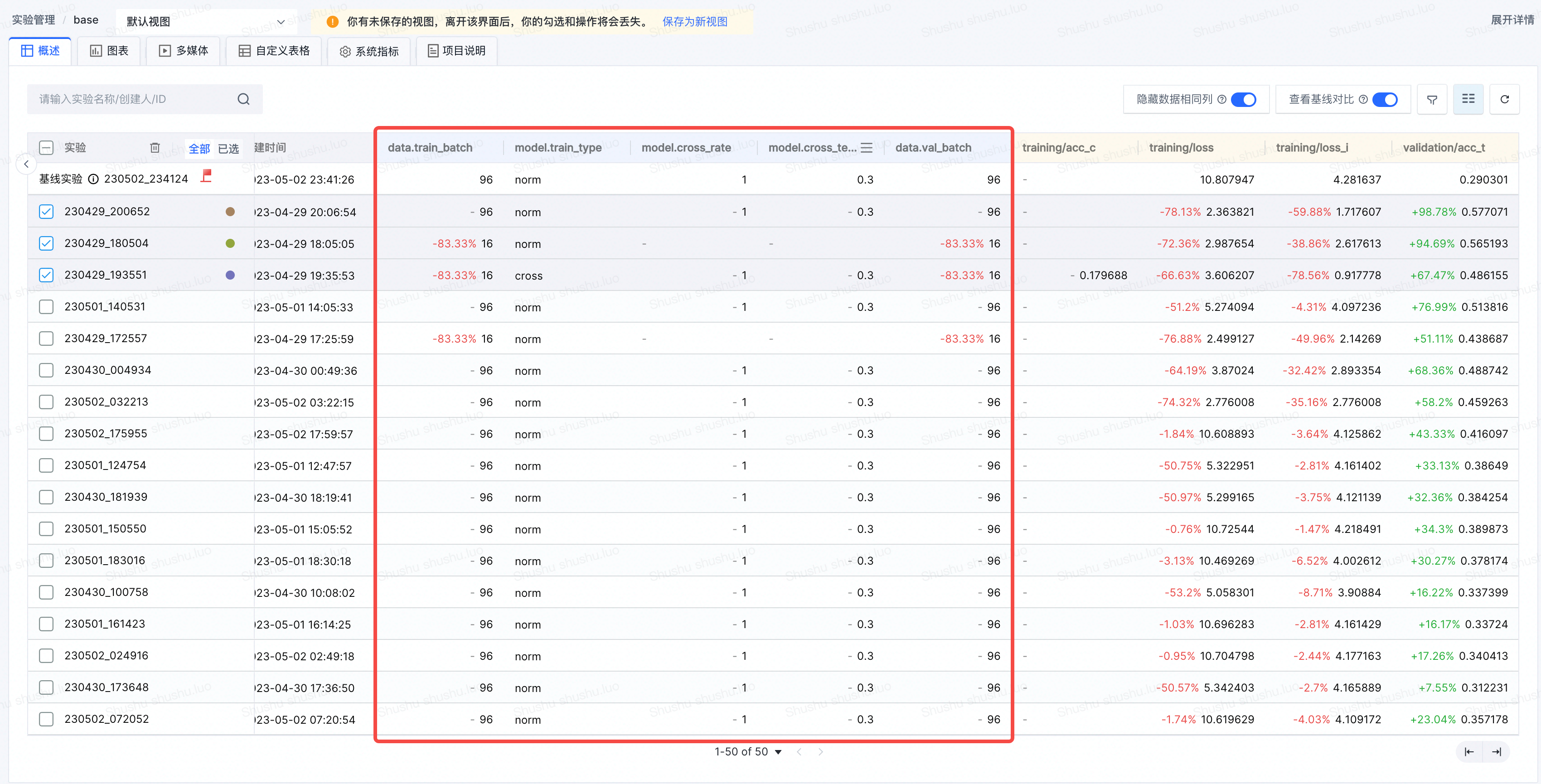
指标记录
通过summary指定或修改本次实验的指标
wandb.summary.loss = 0.1
记录为summary的指标数据,可在概述页面进行查看,并和其他trial进行对比。
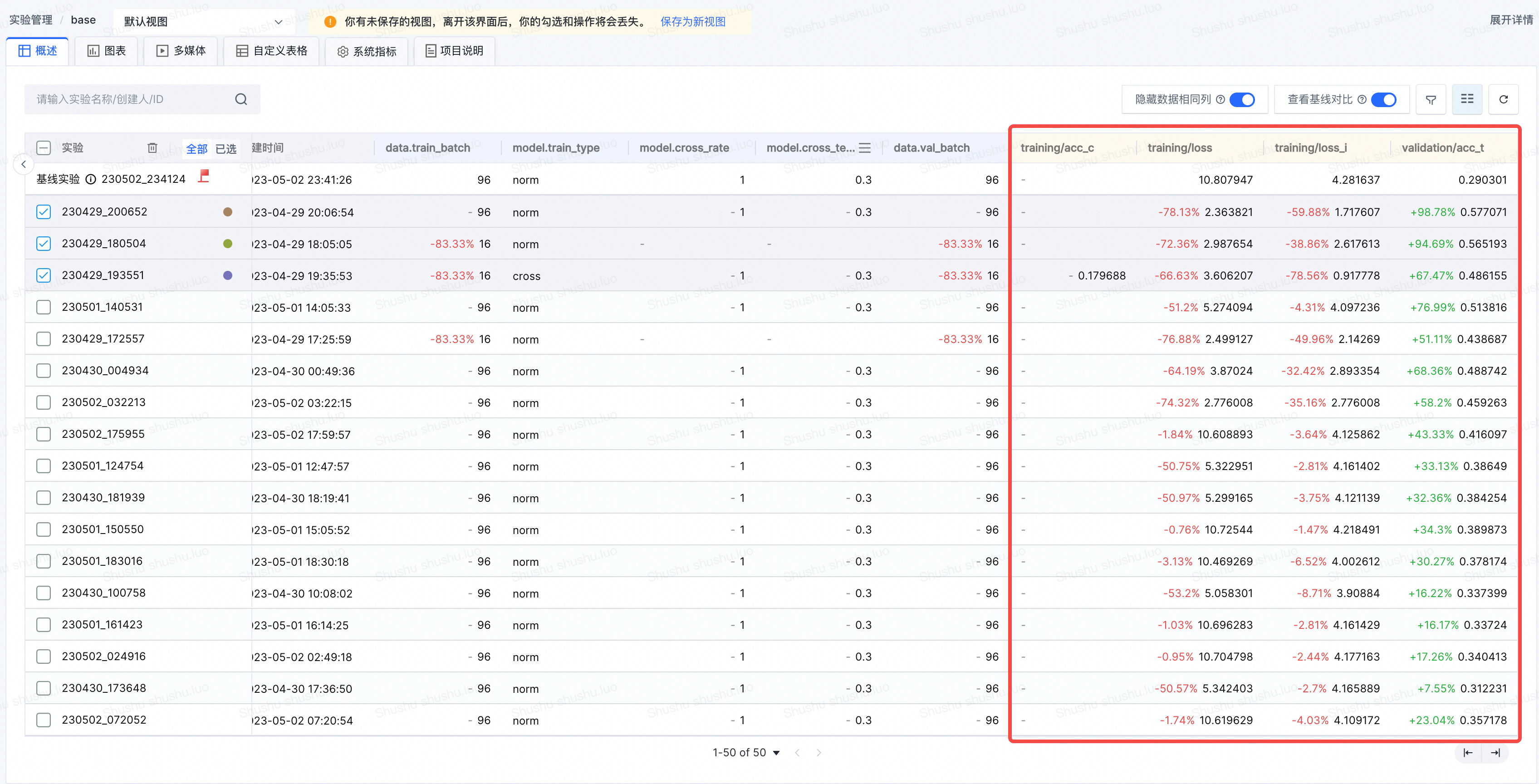
训练过程记录
用户可通过log方法记录不同类型的数据,已支持普通数值型数据
log方法提供了三个参数,如下所示:
data: Dict[str, Any]格式,value为int/float(scalar)或tracking定义的其他类型。
step: tracking log存在全局唯一的step概念,step强制递增(会过滤掉非递增的数据)
如果指定step,则以指定step为准
如果不指定step,则本次step等于global step + 1
commit: 如果本次step的数据分多次上传,可指定commit=False。commit=True后,global step自增1
def log(self, data: Dict[str, Any], step: Optional[int] = None, commit=True)
折线图
#默认通过全局step进行记录 for i in range(1000): wandb.log({"loss": random.random()}) # 定义:自定义X轴 wandb.define_metric("custom_step") # 定义:对希望通过自定义X轴进行记录的指标进行关联 wandb.define_metric("validation_loss", step_metric="custom_step") # 记录自定义X轴的计算方式,以及对应指标 for i in range(100): log_dict = { "train_loss": 1 / (i + 1), "custom_step": i**2, "validation_loss": 1 / (i + 1), } wandb.log(log_dict)
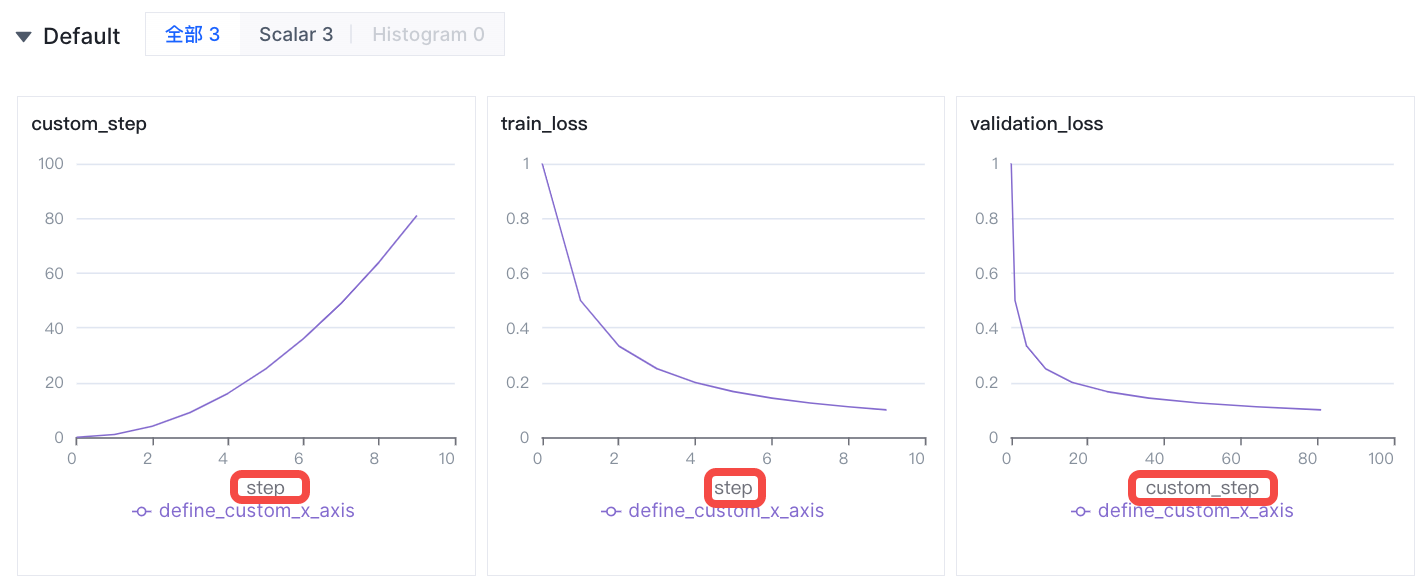
通过定义custom_step相关联指标,可以看到如图:
train_loss - 依然按照global step进行打点和展示
custom_step - 记为单独一个图表,以便观察global_step与custom_step间的关系
validation_loss - 展示为按custom_step记录的指标
直方图
for step in range(10): scores = [random.gauss(step, 1) for _ in range(200)] # table = wandb.Table(data=[[x] for x in scores], columns=["scores"]) wandb.log({"my_histogram": wandb.Histogram(scores)}, step=step)
观察分布随step的变化,可悬浮在单一step查看单个直方图的分布形态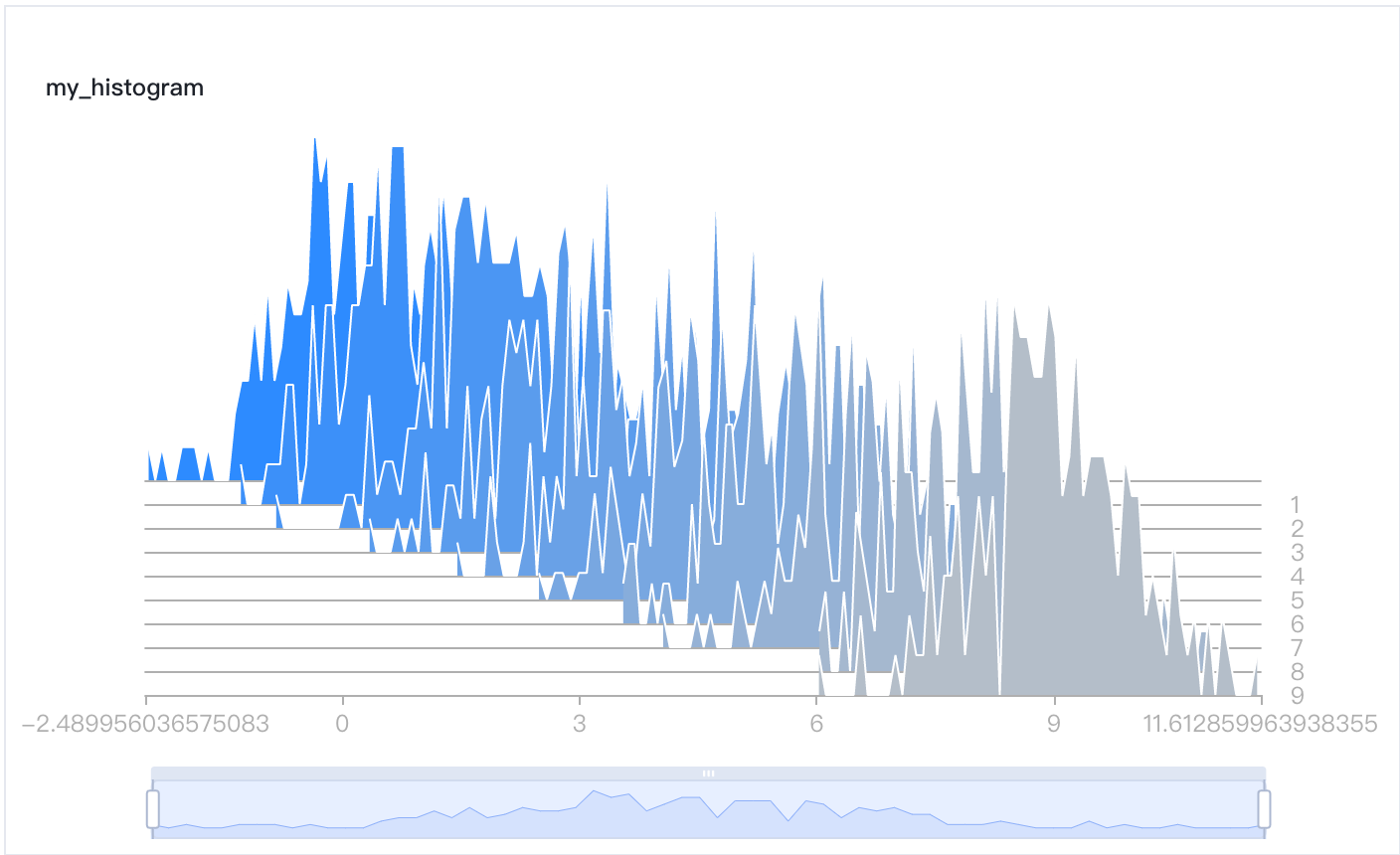
多媒体
用户可根据需求,将丰富的多媒体文件按step记录,包括文本,图片,音频和视频。
- 图片:默认缩略图片,可点击放大查看原图。
- 音频:默认预览波段图,可点击进行播放。
- 视频:支持gif/mp4/webm/ogg,可点击播放,双击全屏播放。
图片 image
wandb.log( { "images": [ wandb.Image( np.random.randint( low=0, high=256, size=(100 * (5 + 1), 100 * (5 + 1), 3), dtype=np.uint8, ), caption="test_caption", ) for _ in range(7) ], "image": wandb.Image( np.random.randint( low=0, high=256, size=(100, 100, 3), dtype=np.uint8, ), caption="test_caption", ), } )
音频 audio
wandb.log( { "audios": [ wandb.Audio( np.random.randn(1000, 2), sample_rate=44100, caption="test_caption", ) for _ in range(7) ], "audio": wandb.Audio( np.random.randn(1000, 2), sample_rate=44100, caption="test_caption", ), } )
视频 video
wandb.log( { "videos": [ wandb.Video( np.random.randint( low=0, high=256, size=(10, 3, 100, 100), dtype=np.uint8 ), fps=4, caption="test_caption", ) for i in range(7) ], "video": wandb.Video( np.random.randint( low=0, high=256, size=(10, 3, 100, 100), dtype=np.uint8 ), fps=4, caption="test_caption", ), } )
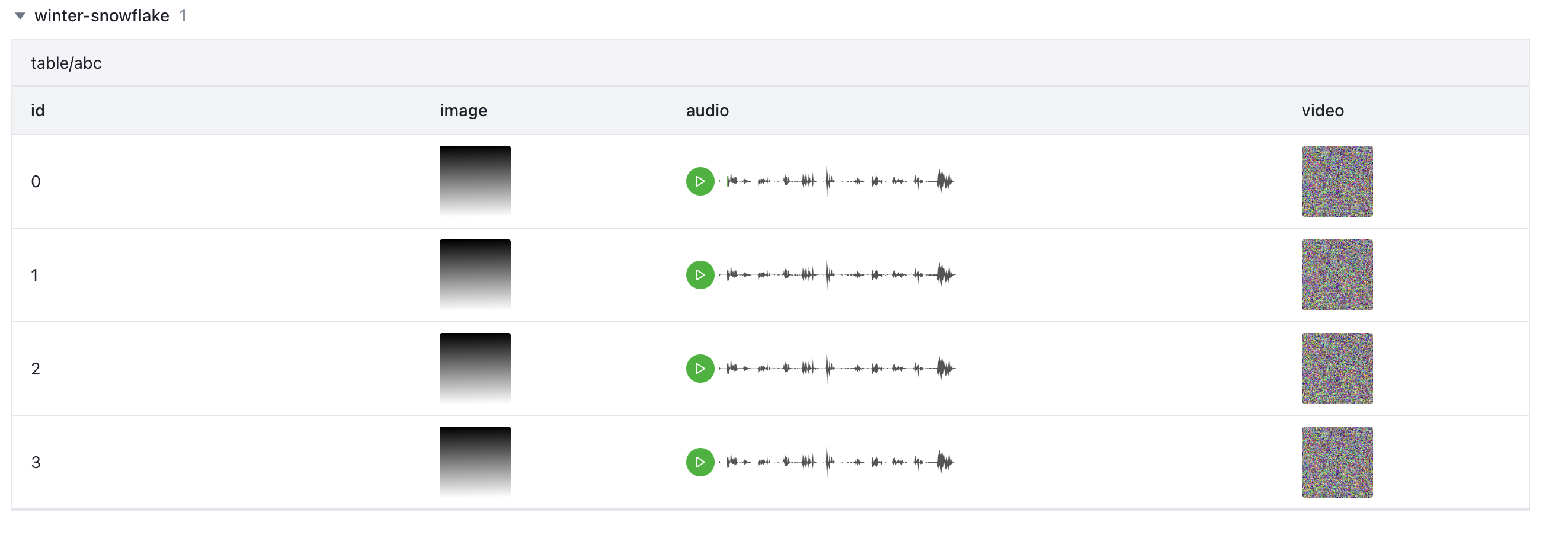
自定义表格
用户还可将实验中的任何数据定义为二维表格进行展示。
my_data = [] EXTS = ("gif","mp4","webm") for i in range(4): h,w,c=64,64,3 image_array1=np.random.randint( low=0,high=256,size=(100,100,3),dtype=np.uint8 ) frames=np.random.randint(low=0,high=256,size=(10,3,100,100),dtype=np.unit8) video=wandb.Video(frames,fps=4,format=EXTS[i % len(EXTS)]) my_data.append( [ i, wandb.Image(image_array1), wandb.Audio("/abc/test/sample_video.wav"), video, ], ) columns=["id", "image", "audio", "video"] my_table=wandb.Table(data=my_data,columns=columns) wandb.log({"table_key":my_table})
示例:自定义表格可记录每次实验内的各项数据,包括文本、图片、视频、音频,通过指定表格列名和数据行的2D array,进行展示
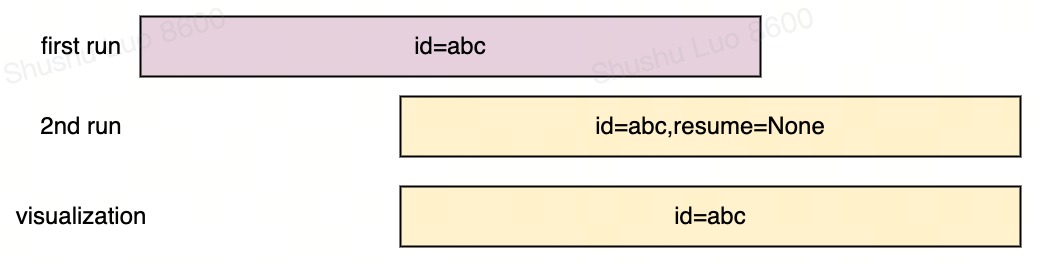
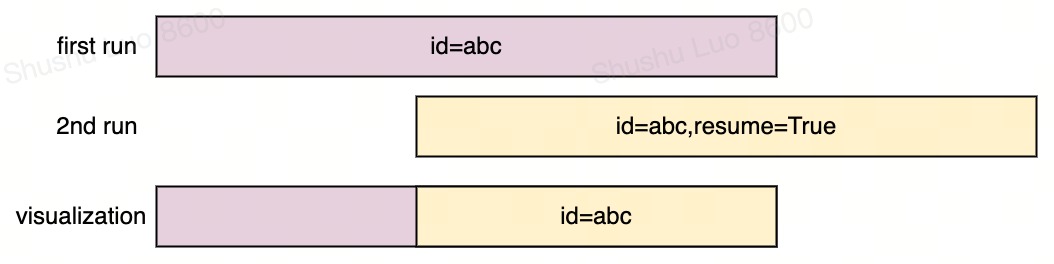
中断重跑 Resume
针对可抢占训练资源或意外中断的实验,本功能支持对实验数据进行继续补充
最佳实践法则:
没有明确希望进行中断续连先前实验数据需求时,选择默认(不指定ID 和 resume)
不希望自己数据因为重跑,fork等被污染,严格设置 resume="never"
不希望生成垃圾运行记录,希望覆盖数据的,设置wandb.init(id="abc", resume=None)
其他场景,参考不同的resume模式
| 场景 | SDK记录方式 | 预期 |
|---|---|---|
| 默认场景 | wandb.init(),不指定id/resume | 每次运行都会生成新的实验 |
开发机/本地调试场景: | wandb.init(id="abc", resume=None),会覆盖之前的运行记录 |
|
开发机/本地调试场景: | 方法一:wandb.init(id="abc", resume=True)。明确指定id,来继续track,适用于开发机在同时跑多项不同的实验,希望针对性的进行resume,不要记错乱了。 |
|
| 可抢占训练场景(跑到一半被kill了,排到资源后自动从上次继续训练) | 用户指定unique id by wandb.init(id="xyz", resume="allow"),再次运行时会load之前的一些变量,继续track | 同上,resume进行实验数据拼接 |
运行失败场景(和可抢占的区别是意外被kill了,没有提前指定id,还是希望能从上次继续训练) | 运行失败后,可以在前端查看该run的unique_id。后续指定wandb.init(id="$unique_id", resume="must"),继续track | resume=must时,系统会强制寻找对应实验进行拼接,无法找到时,会记为异常 |
训练复制场景(多人复用相同的训练配置,可能每个人对实验是否resume的需要不一样,尤其需要注意防止污染或覆盖) |
| * 指定WANDB_RESUME环境变量,默认never也可保障不被污染 |
自动同步Tensorboard
实时数据同步
对于即将提交训练,代码内已经包含tensorboard实验打点的用户,可通过指定在 wandb.init 指定 sync_tensorboard=True进行数据同步,减少代码改动。
目前仅针对折线图和指标记录进行同步。其他图表类型和超参数数据仍需按照本文档中的SDK语句进行补充。
import wandb from torch.utils.tensorboard import SummaryWriter wandb.init(project="demo-sync-tb", sync_tensorboard=True) with SummaryWriter("./board") as writer: max_step = 100 for step in range(max_step): writer.add_scalar("train/acc", step / max_step, global_step=step) writer.add_scalar("train/loss", 1 - step / max_step, global_step=step)
历史数据同步
对于已经训练完成的任务,希望通过实验管理模块将数据进行托管,并和新的训练数据进行对比,可以提供tensorboard日志目录,将数据导入至指定实验项目中。
import wandb wandb.TrackingApi().sync_tensorboard( "/home/user/repos/reckon/wandb/event/", # tf_event root dir project="ci", # project_name name="tfevent_file_name", # run_name )