机器学习平台是一套服务于专业算法工程师,整合云原生的工具+算力 (GPU、CPU云服务器),进行一站式AI算法开发和迭代的平台。本方案将为您介绍如何在 MLP 基于 Megatron-Core 进行 DeepSeek-V2-Lite 模型进行模型微调并实现在线服务部署。
说明
在实践过程中,如果因网络等问题导致模型、数据集或量化工具等无法下载到 TOS bucket ,建议您可以先将其下载到开发机云盘中,再自行拷贝到 TOS 路径下。
本方案以 DeepSeek-V2-Lite 模型为例,在开始执行操作前,请确认您已经完成以下准备工作:
已开通网络/TOS/CFS,具体操作详见更改预付费资源组的负载网络VPC--机器学习平台-火山引擎、控制台快速入门--对象存储-火山引擎、访问文件存储实例--大数据文件存储-火山引擎。
已购买 MLP 资源,详见创建资源组--机器学习平台-火山引擎。关于资源价格详情,请详见实例规格及定价--机器学习平台-火山引擎。
已创建开发机实例,其中关键参数配置如下。具体操作详见创建开发机--机器学习平台-火山引擎。
资源规格:配置以下资源规格。
CPU 实例:8C/64G/20GB云盘。
GPU 卡数:至少 8 卡,最佳实践采用一台 ml.pni2。
挂载配置:挂载 TOS bucket 和 CFS,具体操作详见训练代码如何访问TOS--机器学习平台-火山引擎。
镜像地址:在自定义镜像处配置下方镜像,填写 SSH key 并挂载 TOS。由于拉取的镜像较大,首次创建开发机时间预计20分钟。
vemlp-cn-beijing.cr.volces.com/preset-images/llm:megatron-lm-1.0
进入开发机。
登陆 账号登录-火山引擎。
在左侧导航栏单击开发机,在开发机列表页面中单击待操作的开发机名称,进入对应开发机内。
通过 SSH 远程登录开发机,具体操作详见通过SSH远程连接开发机--机器学习平台-火山引擎。
配置 volc configure。具体操作详见使用文档--机器学习平台-火山引擎。
在 Terminal 中执行以下命令,通过镜像源下载 deepseek-v2 模型,并打开挂载的存储桶路径。
cd /vemlp-demo-models mkdir model-deepseek-v2-lite cd model-deepseek-v2-lite export HF_ENDPOINT=https://hf-mirror.com pip3 install -U huggingface_hub huggingface-cli download --token $HF_TOKEN --resume-download deepseek-ai/DeepSeek-V2-Lite --local-dir $ORIGINAL_MODEL_PATH
其中运行 huggingface-cli 命令行,需要传入的参数列表说明如下:
| 参数 | 描述 |
|---|---|
| hf_token | 具有deepseek使用权限的Huggingface账号的hf_token。 |
| original_model_path | 源safetensor路径。 |
说明
- --token/--hf_username/--hf_token等参数非必须,仅为部分 Repo 有 license 限制,需登录申请许可。如果必要,请在 https://huggingface.co/settings/tokens 获取 token 后进行下载。
- 推荐您将模型文件、训练数据集的下载、存放地址都设置在 TOS/VEPFS/SCFS 等共享存储内,之后在进行训练、推理等跨节点的任务时,可以更加轻松地挂载到不同的机器上。
- 在实践过程中,如果因网络等问题导致模型、数据集或量化工具无法下载到TOS bucket,建议您可以先将其下载到开发机云盘中,再自行拷贝到TOS路径下。在这种情况下,请尽量选择更大的云盘容量(如100G)。
在Terminal执行以下命令,可以直接下载火山在镜像中预置的训练与精调数据集。
cd /vemlp-demo-models mkdir datasets-deepseek-v2-lite cd datasets-deepseek-v2-lite wget https://mlp-opentrail-demo.tos-cn-beijing.volces.com/dataset/oscar-en.tar.gz tar -xzvf oscar-en.tar.gz wget https://mlp-opentrail-demo.tos-cn-beijing.volces.com/dataset/finetune-dataset.tar.gz tar -xzvf finetune-dataset.tar.gz
3.1 模型格式转换(safetensor to ckpt)
在 Terminal 中执行以下命令,可将 safetensor 无损转换成出 checkpoint 格式,并输出到启动参数(MEGATRON_LM_MODEL_PATH)配置的目标 checkpoint 路径中。格式转换预计耗时 9~10 min。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-utils/deepseek_convertor bash convertor.sh -m A2.4B -s $ORIGINAL_MODEL_PATH -t $MEGATRON_LM_MODEL_PATH -tp 2 -pp 1 -ep 4 -te true -hf $ORIGINAL_MODEL_PATH -pr bf16
其中运行 convertor.sh 脚本需要传入的参数说明如下:
| 参数 | 描述 |
|---|---|
| original_model_path | 源 safetensor 路径。 |
| megatron_lm_model_path | 目标 checkpoint 路径。 |
| tp | 模型并行度。 |
| pp | 流水并行度。 |
| ep | 并行计算数。 |
te | 使用 Transformer Engine,取值如下:
|
| hf | HuggingFace checkpoint 的路径。 |
| pr | 训练精度:fp16 或 bf16 。 |
3.2 自定义任务分布式训练(指令微调)
最佳实践文档提供控制台与命令行两种方式的操作说明。
方式一:控制台
进入自定义任务控制台
配置环境
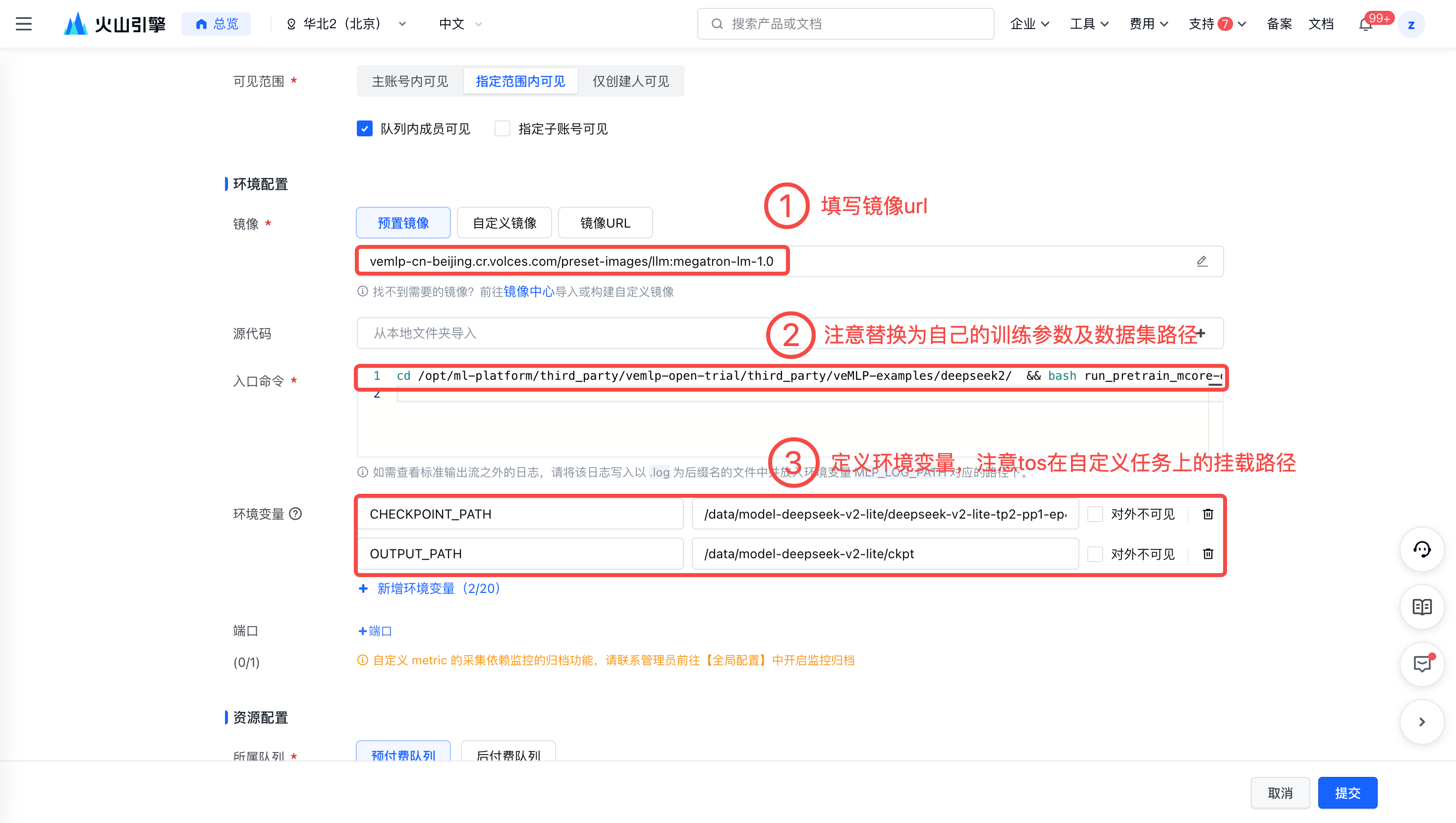
- 在预制镜像处选中 megatron-lm-1.0 或在镜像URL处配置如下镜像。
vemlp-cn-beijing.cr.volces.com/preset-images/llm:megatron-lm-1.0- 填写入口命令并定义环境变量。请注意tos在开发机上挂载的路径与自定义任务中挂载的路径不一致,在入口命令填写数据集路径环境变量中填写模型路径时,需确保为自定义任务中挂载的路径。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-examples/deepseek2/ bash run_pretrain_mcore-deepseek2.sh --model_size A2.4B --batch_size 1 --global_batch_size 8 --learning_rate 1e-5 --min_learning_rate 1e-6 --sequence_length 4096 --padding_length 4096 --precision bf16 --tensor_parallel 2 --pipeline_parallel 1 --context_parallel_size 1 --expert_parallel 4 --activation_checkpoint false --distributed_optimizer false --flash_attention true --sequence_parallel true --save_interval 10000 --dataset_path /data/datasets-deepseek-v2-lite/oscar-en/oscar-en-llama_text_document --pretrain_checkpoint_path $CHECKPOINT_PATH --train_tokens 10000000 --warmup_tokens 100 --output_basepath $OUTPUT_PATH --sft true --optimizer_offload false --train_iters 10000 --lr_warmup_iters 100
- 配置资源
选择合适的资源,最佳实践所用机器为单机 8 卡 ml.pni2。
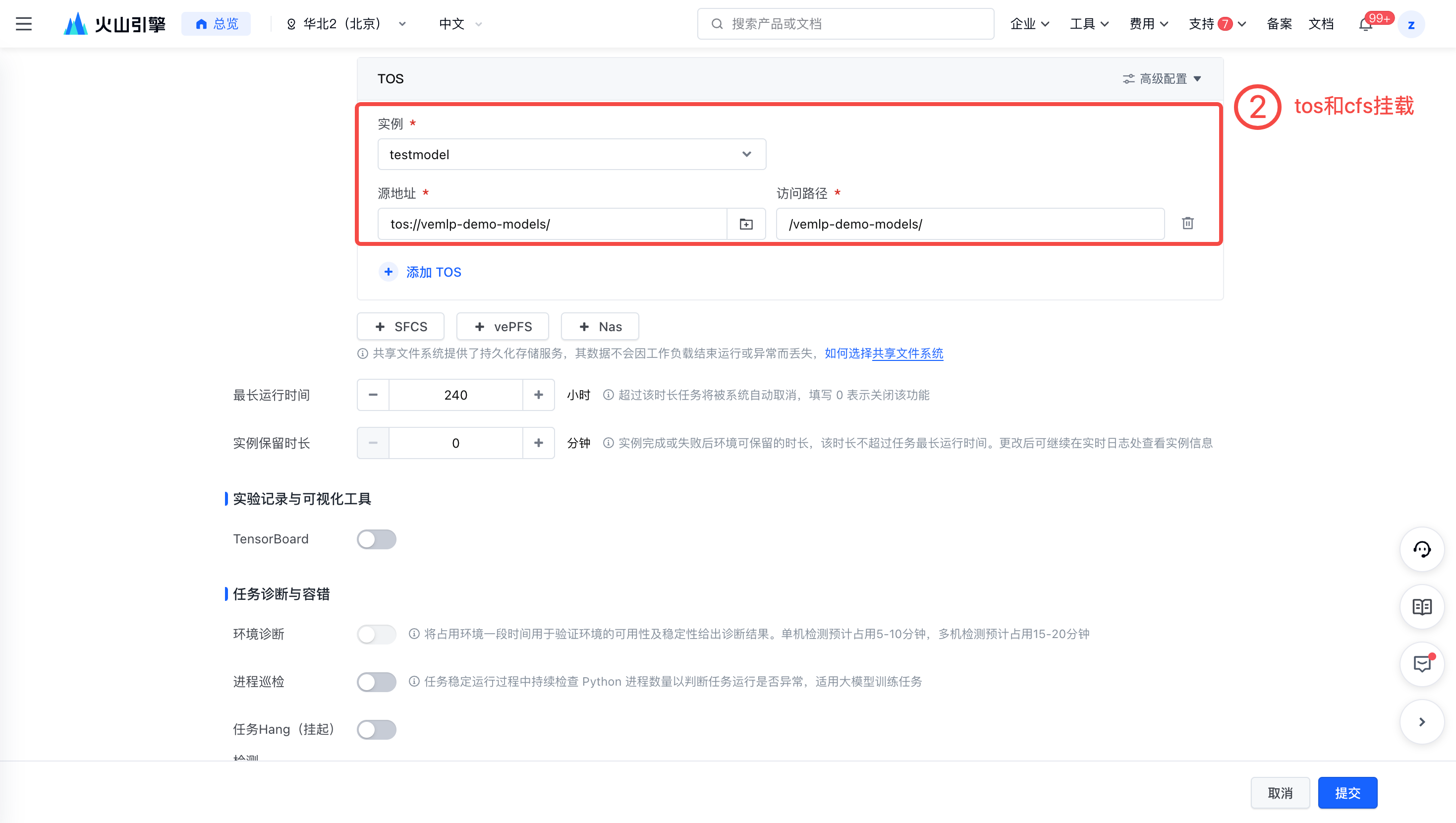
挂载 TOS 和 CFS。需要注意:tos在开发机上挂载的路径与自定义任务中挂载的路径不一致,在环境变量中填写模型路径时需确保为自定义任务中挂载的路径。

方式二:命令行
在 Terminal 中使用以下命令对 DeepSeek-V2-Lite 进行预训练,具体操作步骤如下。
- 创建一个 demo.yaml 文件。
- 编辑 yaml 文件,填写镜像、资源规格、环境变量以及入口命令。
- 运行任务命令。如运行成果,在 Terminal 会出现 “创建任务成功,task_id=*****” 字样。完整训练时长预计为 5 小时左右。
volc ml_task submit --conf=/vemlp-demo-models/demo.yaml
demo.yaml 文件示例:
TaskName: "deepseek-v2-lite" Description: "" Tags: [] ImageUrl: "vemlp-cn-beijing.cr.volces.com/preset-images/llm:megatron-lm-1.0" ResourceQueueID: "q-**************" #请替换为自己的队列ID # DL framework, support: TensorFlow PS,PyTorch DDP,Horovod,BytePS Framework: "PyTorchDDP" # Flavor代表机型,去 https://www.volcengine.com/docs/6459/72363 查询 TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 Flavor: "custom" ResourceSpec: Family: "ml.pni2" CPU: 105.000 Memory: 1875.000 GPUNum: 8 Envs: - Name: "CHECKPOINT_PATH" Value: "/data/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4/" - Name: "OUTPUT_PATH" Value: "/data/model-deepseek-v2-lite/ckpt" AccessType: "Queue" Storages: - Type: "Tos" MountPath: "/data" Bucket: "vemlp-demo-models" Prefix: "/" FsName: "testmodel" MetaCacheExpiryMinutes: "-1" Entrypoint: | cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-examples/deepseek2/ && bash run_pretrain_mcore-deepseek2.sh --model_size A2.4B --batch_size 1 --global_batch_size 8 --learning_rate 1e-5 --min_learning_rate 1e-6 --sequence_length 4096 --padding_length 4096 --precision bf16 --tensor_parallel 2 --pipeline_parallel 1 --context_parallel_size 1 --expert_parallel 4 --activation_checkpoint false --distributed_optimizer false --flash_attention true --sequence_parallel true --save_interval 10000 --dataset_path /data/datasets-deepseek-v2-lite/oscar-en/oscar-en-llama_text_document --pretrain_checkpoint_path $CHECKPOINT_PATH --train_tokens 10000000 --warmup_tokens 100 --output_basepath $OUTPUT_PATH --sft true --optimizer_offload false --train_iters 10000 --lr_warmup_iters 100
其中运行 run_finetune_megatron_llama.sh 脚本,需要传入的参数列表说明如下:
| 参数 | 描述 |
|---|---|
| model_size | 模型大小:如 A21B、A2.4B等。 |
| batch_size | 一次迭代一个数据并行内的样本数。 |
| global_batch_size | 一次迭代多个数据并行的总样本数。 |
| learning_rate | 学习率。 |
| min_learning_rate | 最小学习率。 |
| sequence_length | 序列长度。 |
| padding_length | Padding长度。 |
| precision | 训练精度:fp16、bf16或fp8。 |
| tensor_parallel | 模型并行度。 |
| pipeline_parallel | 流水并行度。 |
| context_parallel_size | 内容并行度。 |
| expert_parallel | 并行计算数。 |
activation_checkpoint | 激活检查点模式,取值如下:
|
distributed_optimizer | 是否使用 Distributed optimizer ,取值如下:
|
flash_attention | 是否优先使用 Flash Attention ,取值如下:
|
sequence_parallel | 是否使用序列并行,取值如下:
|
| save_interval | 保存checkpoint文件的间隔。 |
| dataset_path | 训练数据集路径。 |
| pretrain_checkpoint_path | 预训练模型路径。 |
| train_tokens | 训练的token数量。 |
| warmup_tokens | 预热的token数量。 |
| output_basepath | 训练输出日志文件路径。 |
sft | 是否使用Soft fine-tuning,取值如下:
|
| train_iters | 训练Iter数。 |
| lr_warmup_iters | 预热Iter数。 |
3.3 模型格式转换(ckpt to safetensor)
在 Terminal 中执行以下命令,可将 checkpoint 无损转换回 safetensor 格式,并输出到启动参数(ORIGINAL_MODEL_PATH)配置的目标 checkpoint 路径中。
- 首先请确保 $MEGATRON_LM_MODEL_PATH 路径下存在 tokenizer.model 词表文件。如没有,则执行下面的命令行进行文件拷贝。
cp -f /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4/tokenizer.json /vemlp-demo-models/model-deepseek-v2-lite/ckpt/checkpoint/finetune-mcore-deepseek-v2-A2.4B-lr-1e-5-minlr-1e-6-bs-1-gbs-8-seqlen-4096-pr-bf16-tp-2-pp-1-cp-1/iter_0010000/
- 运行 convertor.sh 脚本,预计转换时间2min。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-utils/deepseek_convertor bash convertor.sh -m A2.4B -s /vemlp-demo-models/model-deepseek-v2-lite/ckpt/checkpoint/finetune-mcore-deepseek-v2-A2.4B-lr-1e-5-minlr-1e-6-bs-1-gbs-8-seqlen-4096-pr-bf16-tp-2-pp-1-cp-1 -t /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4-vllm -tp 2 -pp 1 -ep 4 -te true -hf /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite -pr bf16 -M
4.1 复制文件
模型转换为 vllm 推理格式模型后,在 Terminal 执行下面的命令行,将训练前模型路径下的所有json后缀格式文件复制到推理模型文件下路径,和 .bin 文件同级。
cp -f /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4/*.json /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4-vllm/
4.2 创建推理服务
进入在线服务控制台。
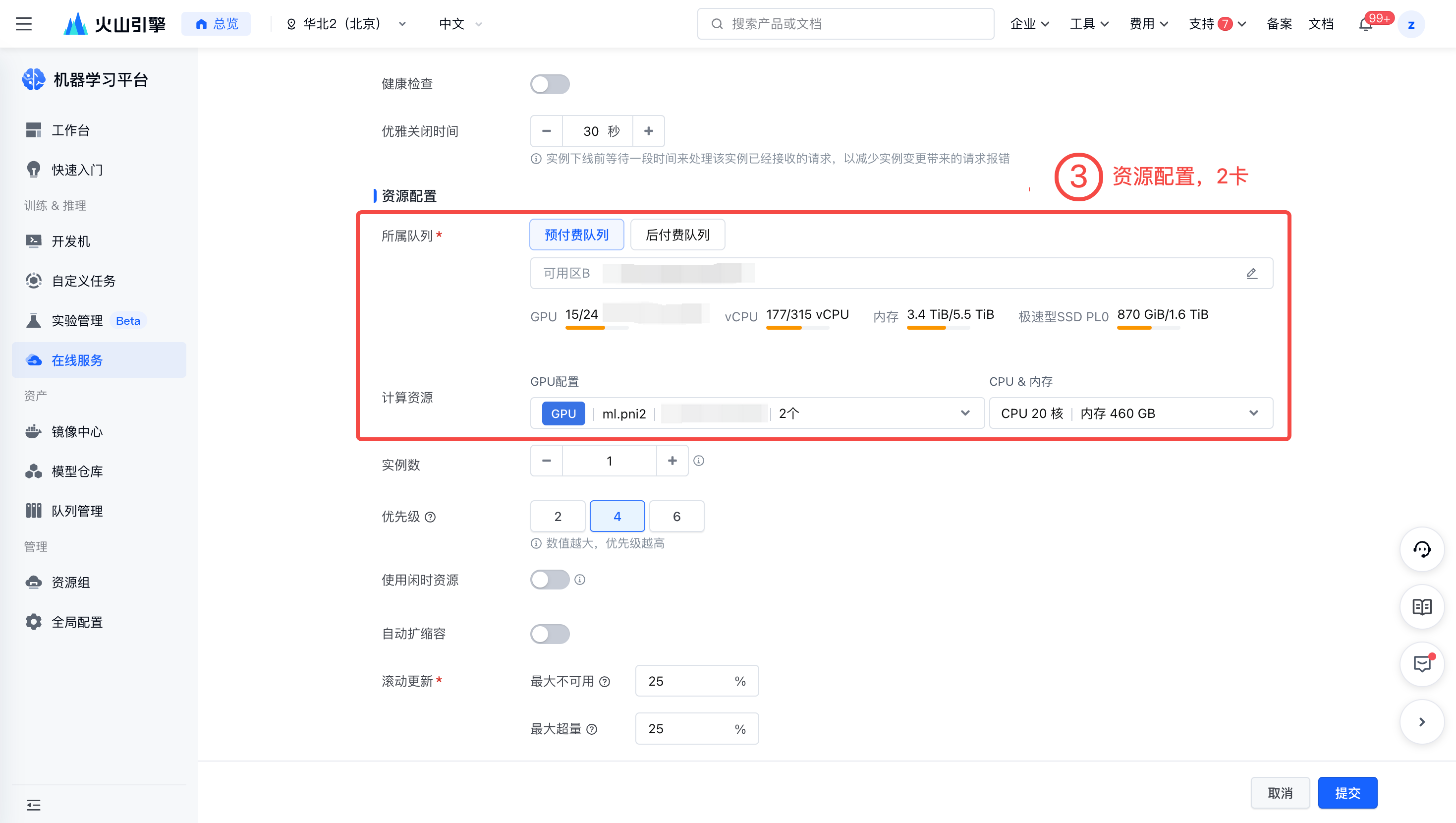
创建推理服务并进行资源部署。
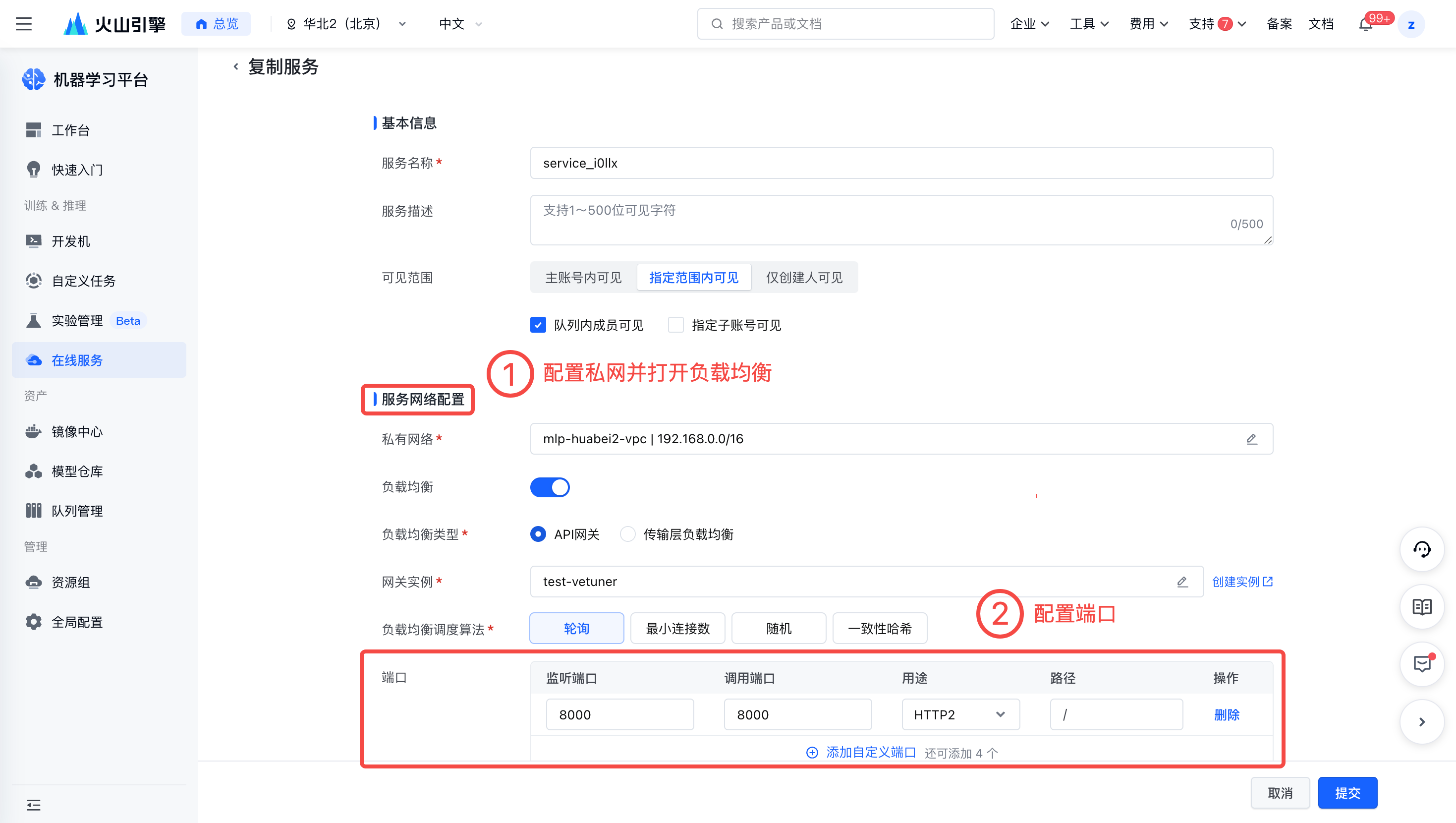
服务网络配置。
- 配置私有网络
- 打开负载均衡并配置端口。
在【服务管理】-【部署】处,点击新增部署。
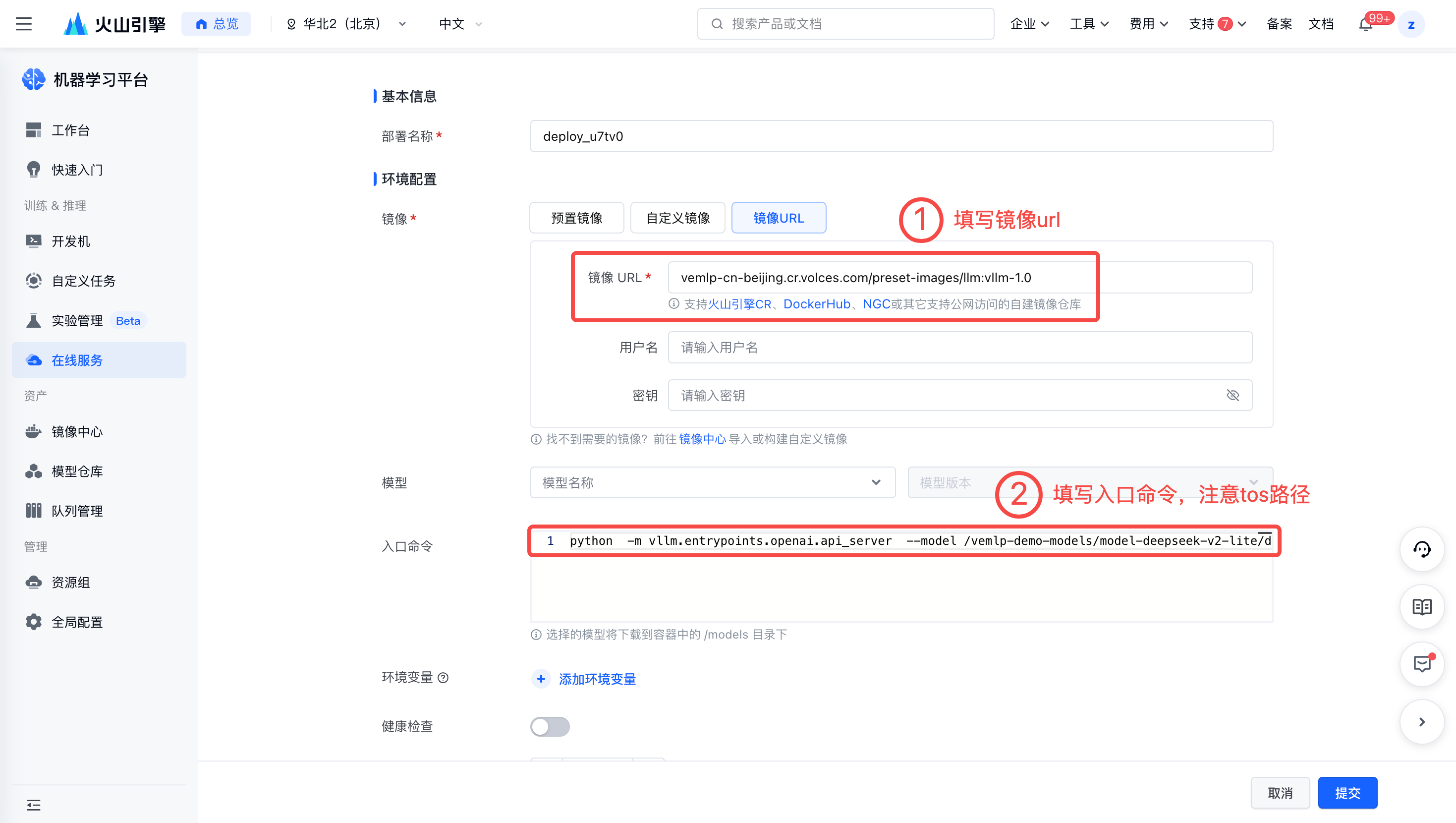
- 填写镜像URL。
vemlp-cn-beijing.cr.volces.com/preset-images/llm:vllm-1.0- 输入入口命令。请注意 TOS 在在线服务上挂载的路径。
python -m vllm.entrypoints.openai.api_server --model /vemlp-demo-models/model-deepseek-v2-lite/deepseek-v2-lite-tp2-pp1-ep4-vllm --served-model-name deepseek --tensor-parallel-size 2 --max-num-seqs 64 --trust-remote-code配置资源。最佳实践使用 2 卡 ml.pni2。
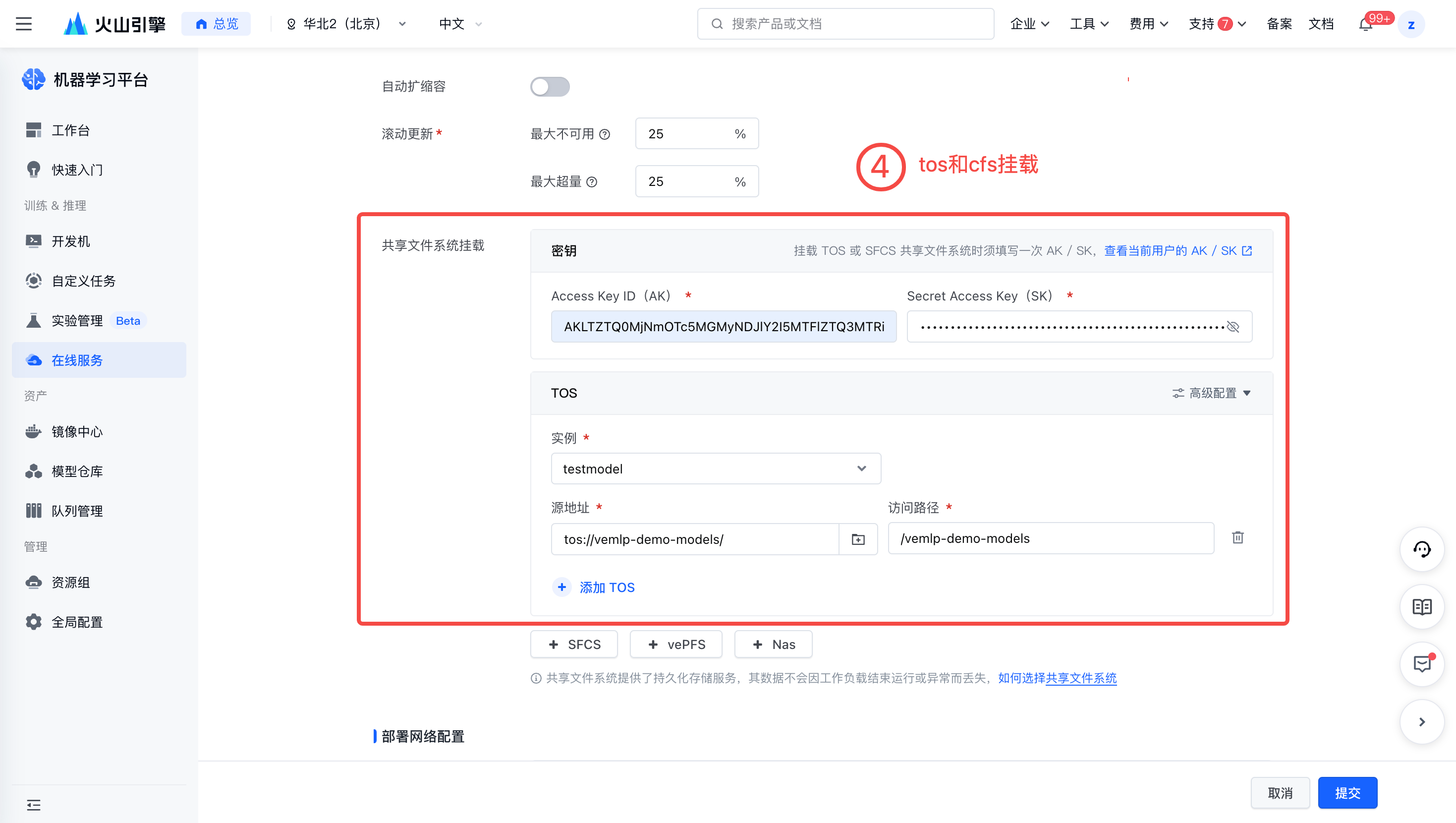
挂载 TOS 与 CFS。
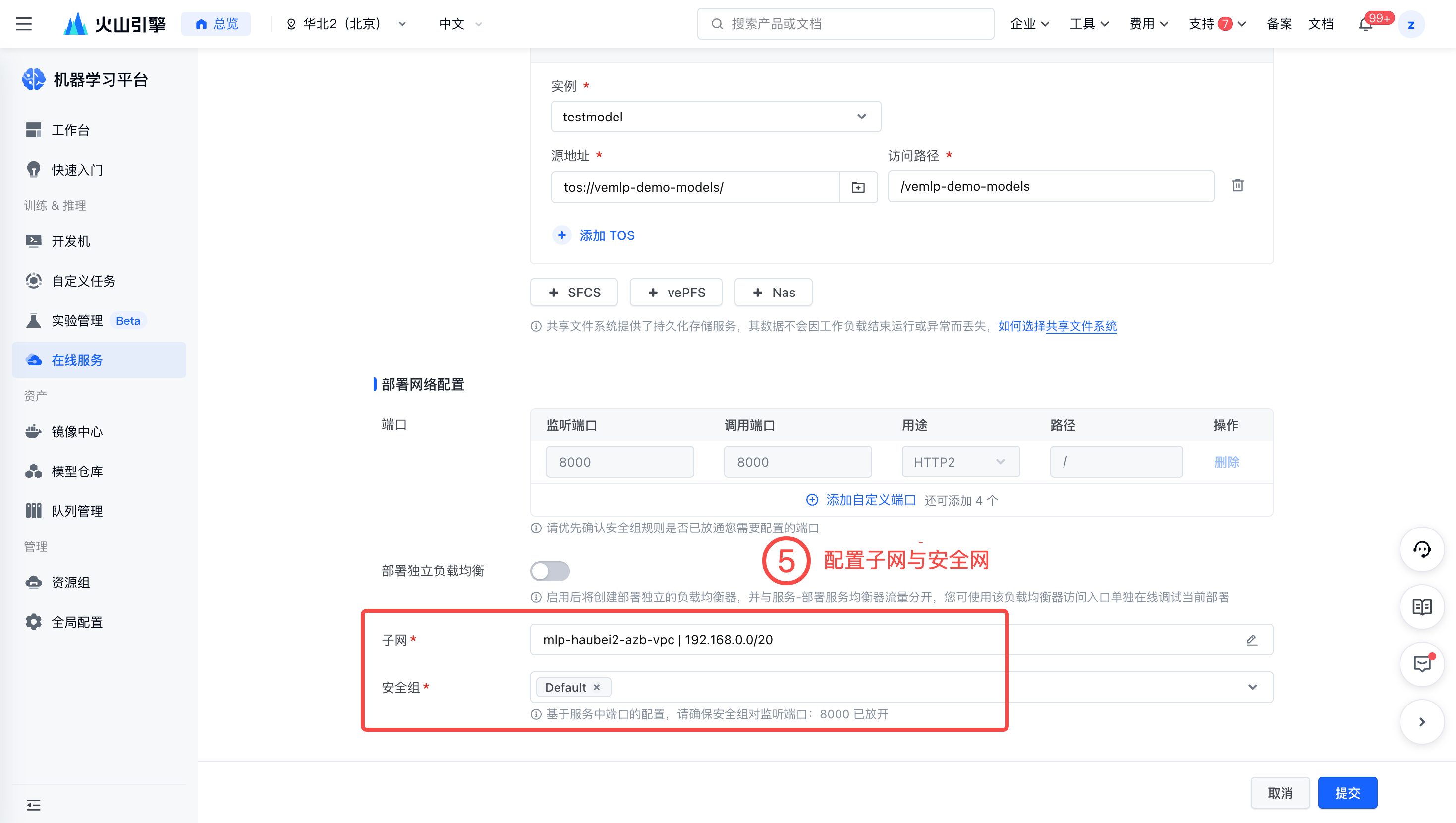
配置子网与安全组。
4.3 定义请求文件 request.py 并执行
- 创建 request.py 文件。脚本内容示例如下。
import requests import json # 定义请求,更换具体的ip地址 url = "http://192.168.0.49:8000/v1/completions" headers = { "Content-Type": "application/json" } data = { "model": "deepseek", "prompt": "San Francisco is a", "max_tokens": 100, "temperature": 0 } # 发送POST请求 response = requests.post(url, headers=headers, data=json.dumps(data)) # 打印响应内容 print(response.json())
- 执行命令请求。
python request.py
结果如下。
{{'id': 'cmpl-c4f2849f328f4a96ab756036745ec8ad', 'object': 'text_completion', 'created': 1733131866, 'mmodel': 'deepseek', 'choices': [{'index': 0, 'text':' city of many neighborhoods, each with its own unique character and charm. From the bustling streets of Chinatown to the quiet streets of the Marina, there is something for everyone in this vibrant city.\nOne of the most popular neighborhoods in San Francisco is the Mission District. This neighborhood is known for its vibrant nightlife, eclectic restaurants, and unique shops. The Mission District is also home to many art galleries and museums, making it a great place to explore the city's culture.\nAnother popular', 'logprobs': None, 'finish_reason': 'length','sstop_reason': None, 'prompt_logprobs': None}],'usage': {'prompt_tokens': 5, 'total_tokens's:105,'completion_tokens': 100}}