机器学习平台是一套服务于专业算法工程师,整合云原生的工具+算力(GPU、CPU云服务器),进行一站式AI算法开发和迭代的平台。本方案将为您介绍如何在 MLP 基于 Meta-Llama-3.1-8B 的开源模型和 Megatron 的训练流程,进行模型微调并实现在线服务部署。
说明
在实践过程中,如果因网络等问题导致模型、数据集或量化工具等无法下载到 TOS bucket ,建议您可以先将其下载到开发机云盘中,再自行拷贝到 TOS 路径下。
本方案以 Meta-Llama-3.1-8B 模型为例,在开始执行操作前,请确认您已经完成以下准备工作:
已开通网络/TOS/CFS,具体操作详见更改预付费资源组的负载网络VPC--机器学习平台-火山引擎、控制台快速入门--对象存储-火山引擎、访问文件存储实例--大数据文件存储-火山引擎。
已购买 MLP 资源,详见创建资源组--机器学习平台-火山引擎。关于资源价格详情,请详见实例规格及定价--机器学习平台-火山引擎。
已创建开发机实例,其中关键参数配置如下。具体操作详见创建开发机--机器学习平台-火山引擎。
资源规格:配置以下资源规格。
CPU 实例:8C/64G/20GB云盘。
GPU 卡数:至少 8 卡,最佳实践采用 1 台 ml.pni2。
挂载配置:挂载 TOS bucket 和 CFS,具体操作详见训练代码如何访问TOS--机器学习平台-火山引擎。
镜像地址:在自定义镜像处配置下方镜像,填写 SSH key 并挂载 TOS。由于拉取的镜像较大,首次创建开发机时间预计 20 分钟。
vemlp-cn-beijing.cr.volces.com/preset-images/llm:megatron-lm-1.0
进入开发机。
登陆 账号登录-火山引擎。
在左侧导航栏单击开发机,在开发机列表页面中单击待操作的开发机名称,进入对应开发机内。
通过 SSH 远程登录开发机,具体操作详见通过SSH远程连接开发机--机器学习平台-火山引擎。
配置 volc configure。具体操作详见使用文档--机器学习平台-火山引擎。
在 Terminal 中执行以下命令,通过镜像源下载 Llama-3.1-8B 模型,并打开挂载的存储桶路径。
cd /vemlp-demo-models mkdir model-llama cd model-llama wget https://hf-mirror.com/hfd/hfd.sh chmod a+x hfd.sh export HF_ENDPOINT=https://hf-mirror.com apt-get update apt-get install aria2 apt-get install git-lfs ./hfd.sh meta-llama/Meta-Llama-3-8B --hf_username $HF_USER_NAME --hf_token $HF_TOKEN --exclude "*pth" --local-dir $ORIGINAL_MODEL_PATH
其中运行 ./hfd.sh 文件,需要传入的参数列表说明如下:
| 参数 | 描述 |
|---|---|
| hf_user_name | 具有llama使用权限的Huggingface账号。 |
| hf_token | 具有llama使用权限的Huggingface账号的hf_token。 |
| original_model_path | 源safetensor路径。 |
说明
- --token/--hf_username/--hf_token等参数非必须,仅为部分 Repo 有 license 限制,需登录申请许可。如果必要,请在 https://huggingface.co/settings/tokens 获取 token 后进行下载。
- 推荐您将模型文件、训练数据集的下载、存放地址都设置在 TOS/VEPFS/SCFS 等共享存储内,之后在进行训练、推理等跨节点的任务时,可以更加轻松地挂载到不同的机器上。
在 Terminal 执行以下命令,下载 MLP 已准备好的数据集。
cd /vemlp-demo-models mkdir datasets-llama cd datasets-llama wget https://mlp-opentrail-demo.tos-cn-beijing.volces.com/dataset/finetune-dataset.tar.gz tar -zxf finetune-dataset.tar.gz
3.1 模型格式转换(safetensor to ckpt)
在 Terminal 中执行以下命令,可将 safetensor 无损转换成出 checkpoint 格式,并输出到启动参数(MEGATRON_LM_MODEL_PATH)配置的目标 checkpoint 路径中。格式转换预计耗时 3~4 min。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-utils/llama_convertor bash convertor.sh -s $ORIGINAL_MODEL_PATH -t $MEGATRON_LM_MODEL_PATH -tp 8 -pp 1 -n llama3.1-8b -e 0
其中运行 convertor.sh 脚本需要传入的参数说明如下:
| 参数 | 描述 |
|---|---|
| original_model_path | 源safetensor路径。 |
| megatron_lm_model_path | 目标checkpoint路径。 |
| tp | 模型并行度。 |
| pp | 流水并行度。 |
| n | 模型名称,如llama-7b、llama-13b、 llama-30b、llama-65b、llama2-7b、llama2-13b、llama2-70b、llama3-8b、llama3-70b等。 |
| e | 额外词汇大小(默认值:0)。 |
3.2 自定义任务分布式训练(指令微调)
最佳实践文档提供控制台与命令行两种方式的操作说明。
方式一:控制台
进入自定义任务控制台
配置环境
- 在自定义镜像处配置镜像。
vemlp-boe-cn-beijing.cr.volces.com/preset-images/megatron-lm:trail-2- 填写入口命令并定义环境变量。请注意 TOS 在开发机上挂载的路径与自定义任务中挂载的路径不一致,在入口命令填写数据集路径环境变量中填写模型路径时,需确保为自定义任务中挂载的路径。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-examples/llama3/ && /bin/bash run_finetune_megatron_llama.sh --model_size 8B --batch_size 1 --global_batch_size 32 --learning_rate 1e-5 --min_learning_rate 1e-6 --sequence_length 128 --padding_length 128 --extra_vocab_size 256 --precision bf16 --tensor_parallel 8 --pipeline_parallel 2 --activation_checkpoint sel --distributed_optimizer true --flash_attention false --sequence_parallel false --transformer_engine false --save_interval 100 --dataset_path /data/datasets-llama/finetune-dataset/alpaca_zh-llama3-train.json --valid_dataset_path /data/datasets-llama/finetune-dataset/alpaca_zh-llama3-valid.json --pretrain_checkpoint_path $CHECKPOINT_PATH --train_iters 1000 --lr_warmup_iters 10 --output_basepath $OUTPUT_PATH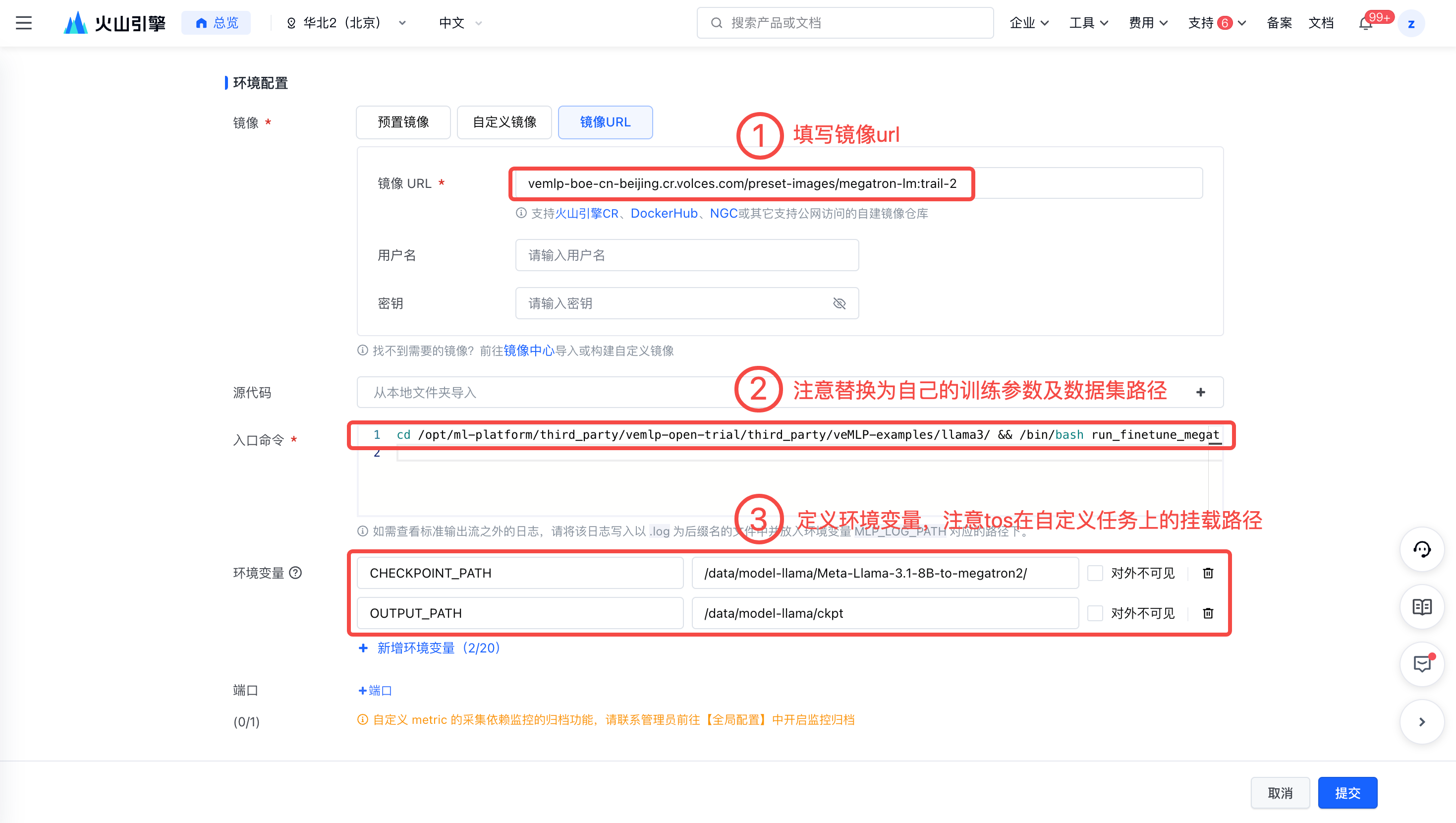
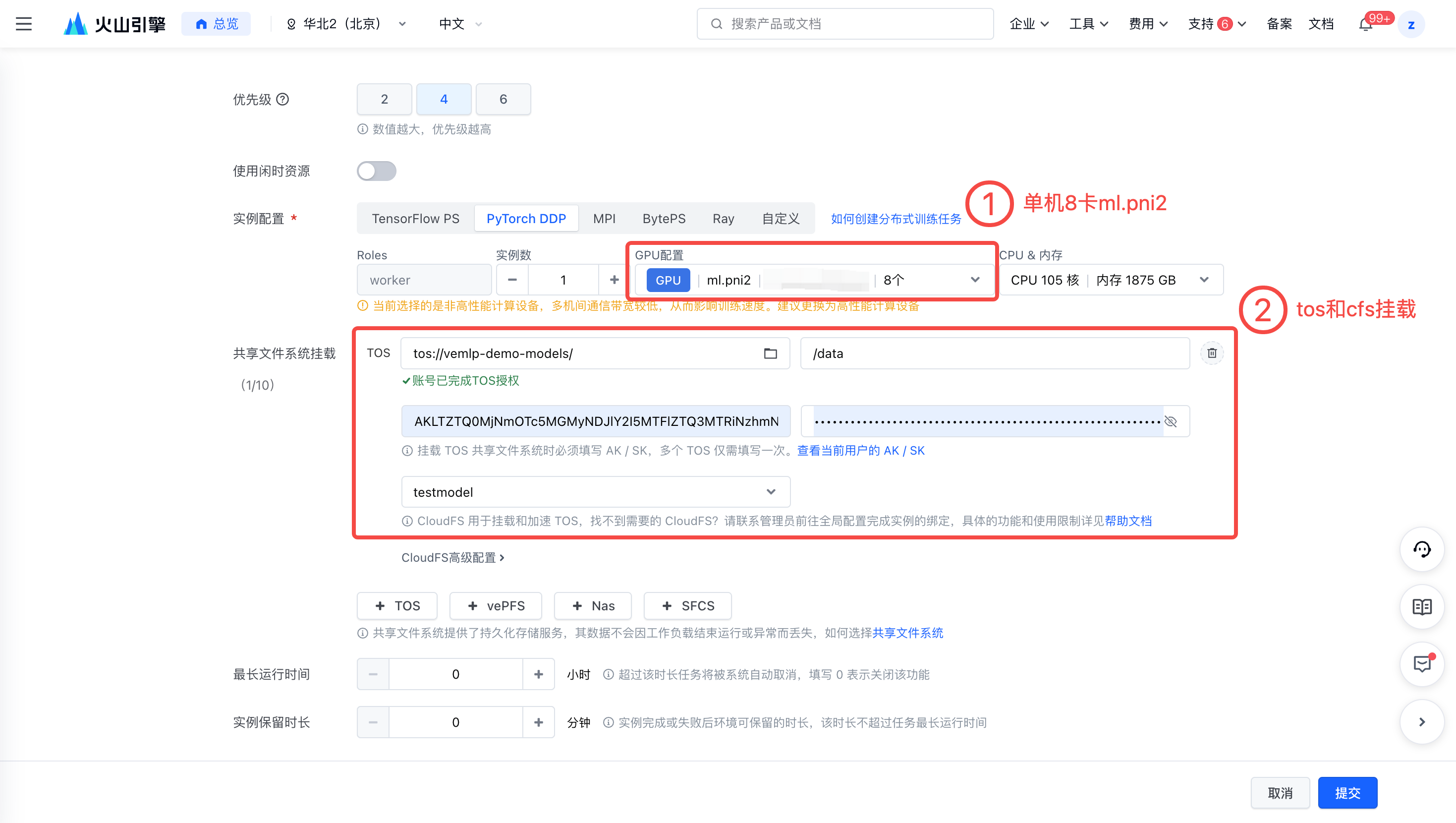
配置资源
选择合适的资源,最佳实践所用机器为单机 8 卡ml.pni2。
挂载 TOS 和 CFS。需要注意:TOS 在开发机上挂载的路径与自定义任务中挂载的路径不一致,在环境变量中填写模型路径时需确保为自定义任务中挂载的路径。
方式二:命令行
在 Terminal 中使用以下命令对 Meta-Llama-3.1-8B 进行预训练,具体操作步骤如下。
- 创建一个 demo.yaml 文件。
- 编辑 yaml 文件,填写镜像、资源规格、环境变量以及入口命令。
- 运行任务命令。如运行成果,在 Terminal 会出现 “创建任务成功,task_id=*****” 字样。完整训练时长预计为 2 小时左右。
volc ml_task submit --conf=/vemlp-demo-models/demo.yaml
demo.yaml 文件示例:
TaskName: "llama-8b" Description: "" Tags: [] ImageUrl: "vemlp-boe-cn-beijing.cr.volces.com/preset-images/megatron-lm:trail-2" ResourceQueueID: "q-**************" # 请替换为自己的队列ID # DL framework, support: TensorFlow PS,PyTorch DDP,Horovod,BytePS Framework: "PyTorchDDP" # Flavor代表机型,去 https://www.volcengine.com/docs/6459/72363 查询 TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 Flavor: "custom" ResourceSpec: Family: "ml.pni2" CPU: 105.000 Memory: 1875.000 GPUNum: 8 Envs: - Name: "CHECKPOINT_PATH" Value: "/data/model-llama/Meta-Llama-3.1-8B-to-megatron2/" - Name: "OUTPUT_PATH" Value: "/data/model-llama/ckpt" AccessType: "Queue" Storages: - Type: "Tos" MountPath: "/data" Bucket: "vemlp-demo-models" Prefix: "/" FsName: "testmodel" MetaCacheExpiryMinutes: "-1" Entrypoint: | cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-examples/llama3/ && /bin/bash run_finetune_megatron_llama.sh --model_size 8B --batch_size 1 --global_batch_size 32 --learning_rate 1e-5 --min_learning_rate 1e-6 --sequence_length 128 --padding_length 128 --extra_vocab_size 256 --precision bf16 --tensor_parallel 8 --pipeline_parallel 2 --activation_checkpoint sel --distributed_optimizer true --flash_attention false --sequence_parallel false --transformer_engine false --save_interval 100 --dataset_path /data/datasets-llama/finetune-dataset/alpaca_zh-llama3-train.json --valid_dataset_path /data/datasets-llama/finetune-dataset/alpaca_zh-llama3-valid.json --pretrain_checkpoint_path $CHECKPOINT_PATH --train_iters 1000 --lr_warmup_iters 10 --output_basepath $OUTPUT_PATH
其中运行 run_finetune_megatron_llama.sh 脚本,需要传入的参数列表说明如下:
| 参数 | 描述 |
|---|---|
| model_size | 模型结构参数量级:8B、70B或405B。 |
| batch_size | 一次迭代一个数据并行内的样本数。 |
| global_batch_size | 一次迭代多个数据并行的总样本数。 |
| learning_rate | 学习率。 |
| min_learning_rate | 最小学习率。 |
| sequence_length | 序列长度。 |
| padding_length | Padding长度。 |
| extra_vocab_size | 在基础词汇表大小之外额外增加的词汇数量。 |
| precision | 训练精度:fp16、bf16或fp8。 |
| tensor_parallel | 模型并行度。 |
| pipeline_parallel | 流水并行度。 |
activation_checkpoint | 激活检查点模式,取值如下:
|
distributed_optimizer | 是否使用Megatron版Zero-1降显存优化器,取值如下:
|
flash_attention | 是否优先使用Flash Attention,取值如下:
|
sequence_parallel | 是否使用序列并行,取值如下:
|
transformer_engine | 是否使用tranformer_engine,取值如下:
|
| save_interval | 保存checkpoint文件的间隔。 |
| dataset_path | 训练数据集路径。 |
| valid_dataset_path | 验证数据集路径。 |
| pretrain_checkpoint_path | 预训练模型路径。 |
| train_iters | 训练Iter数。 |
| lr_warmup_iters | 预热Iter数。 |
| output_basepath | 训练输出日志文件路径。 |
3.3 模型格式转换(ckpt to safetensor)
在 Terminal 中执行以下命令,可将 checkpoint 无损转换回 safetensor 格式,并输出到启动参数(ORIGINAL_MODEL_PATH)配置的目标 checkpoint 路径中。
- 首先请确保 $MEGATRON_LM_MODEL_PATH 路径下存在 tokenizer.model 词表文件。如没有,则执行下面的命令行进行文件拷贝。
cp -f /vemlp-demo-models/model-llama/Meta-Llama-3.1-8B-to-megatron2/tokenizer.json /vemlp-demo-models/model-llama/ckpt/checkpoint/finetune-megatron-llama3-8B-tp-8-pp-2/iter_0001000/
- 运行 convertor.sh 脚本,预计转换时间2min。
cd /opt/ml-platform/third_party/vemlp-open-trial/third_party/veMLP-utils/llama_convertor bash convertor.sh -m /opt/ml-platform/third_party/vemlp-open-trial/third_party -s /vemlp-demo-models/model-llama/ckpt/checkpoint/finetune-megatron-llama3-8B-tp-8-pp-2/iter_0001000 -t /vemlp-demo-models/model-llama/vllm/ -tp 8 -pp 1 -n llama3.1-8b -e 0 -M
4.1 复制文件
模型转换为 vllm 推理格式模型后,在 Terminal 执行下面的命令行,将训练前模型路径下的所有json后缀格式文件复制到推理模型文件下路径,和 .bin 文件同级。
cp -f /vemlp-demo-models/model-llama/Meta-Llama-3.1-8B-to-megatron2/*.json /vemlp-demo-models/model-llama/vllm/
4.2 创建推理服务
进入在线服务控制台。
创建推理服务并进行资源部署。
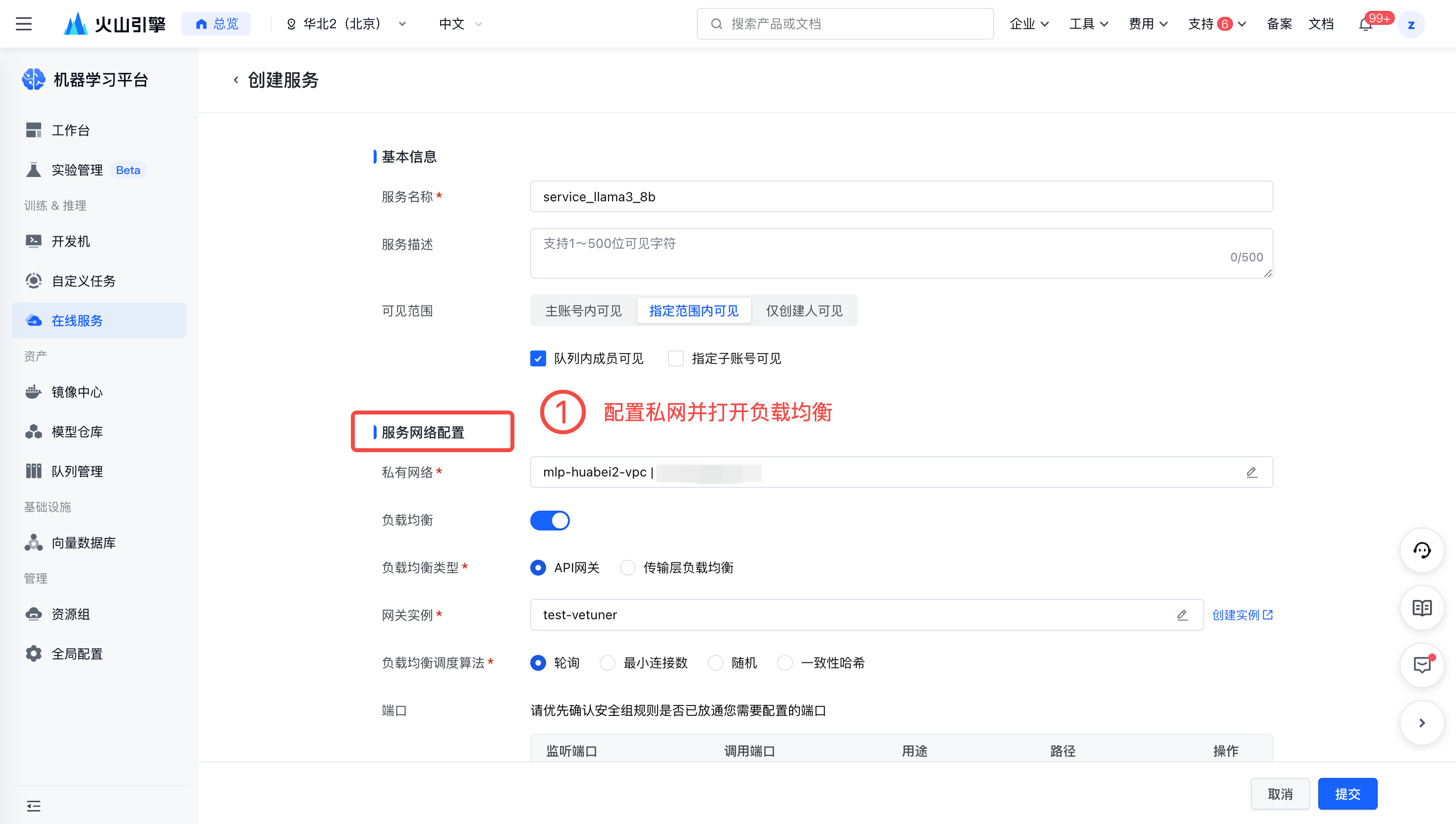
服务网络配置。
- 配置私有网络
- 打开负载均衡并配置端口。
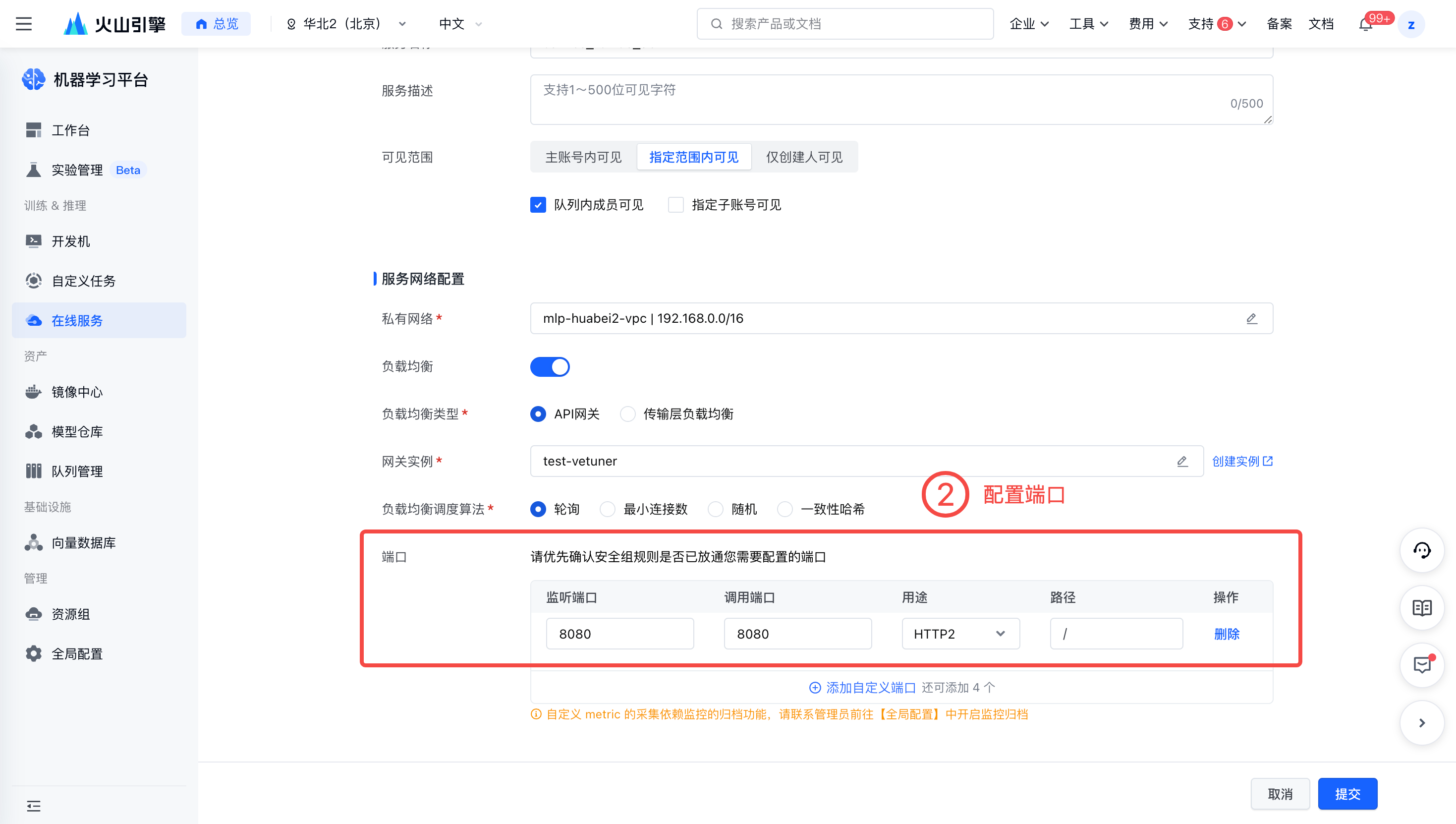
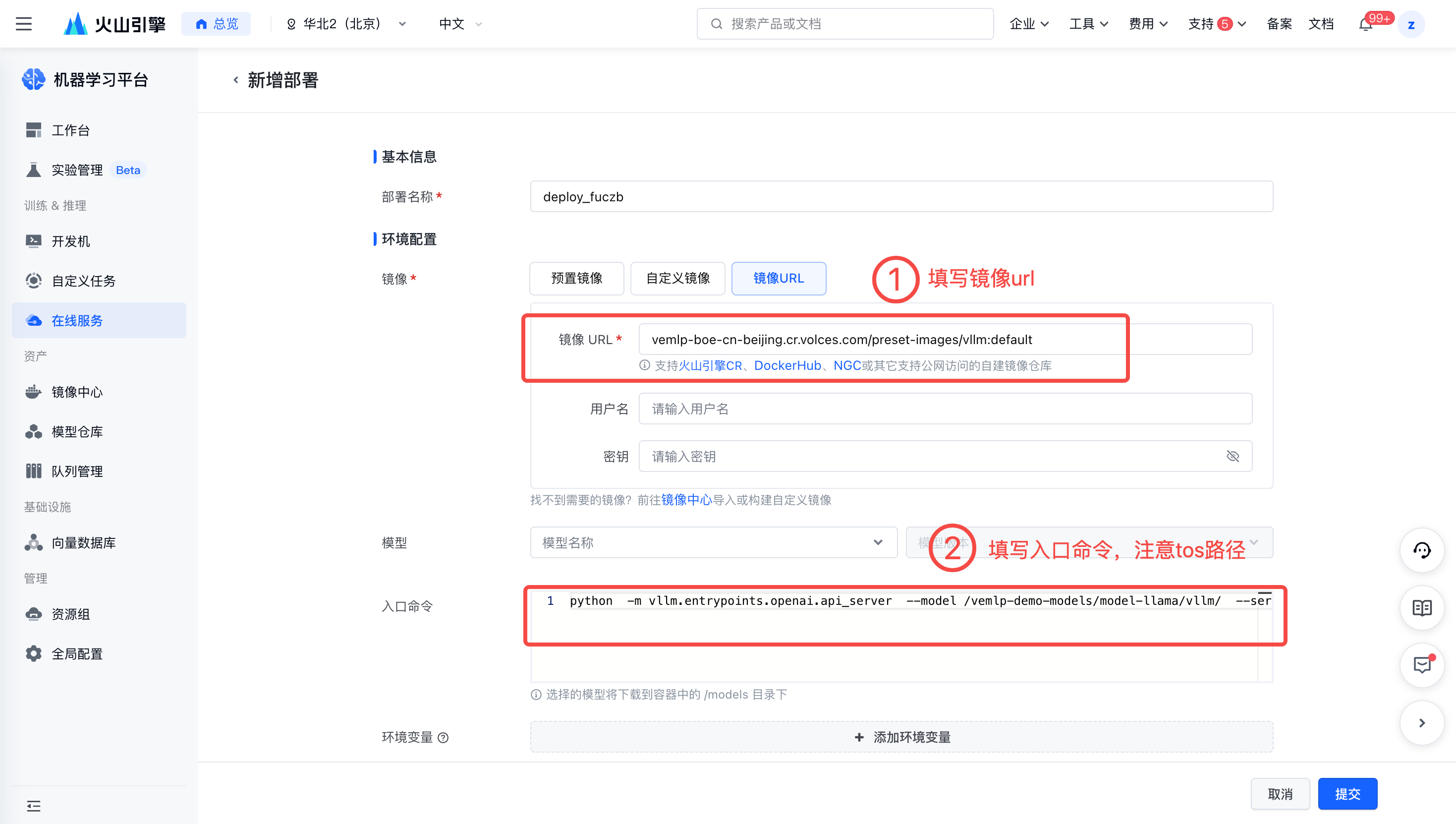
在【服务管理】-【部署】处,点击新增部署。
- 填写镜像URL。
vemlp-boe-cn-beijing.cr.volces.com/preset-images/vllm:default- 输入入口命令。请注意 TOS 在在线服务上挂载的路径。
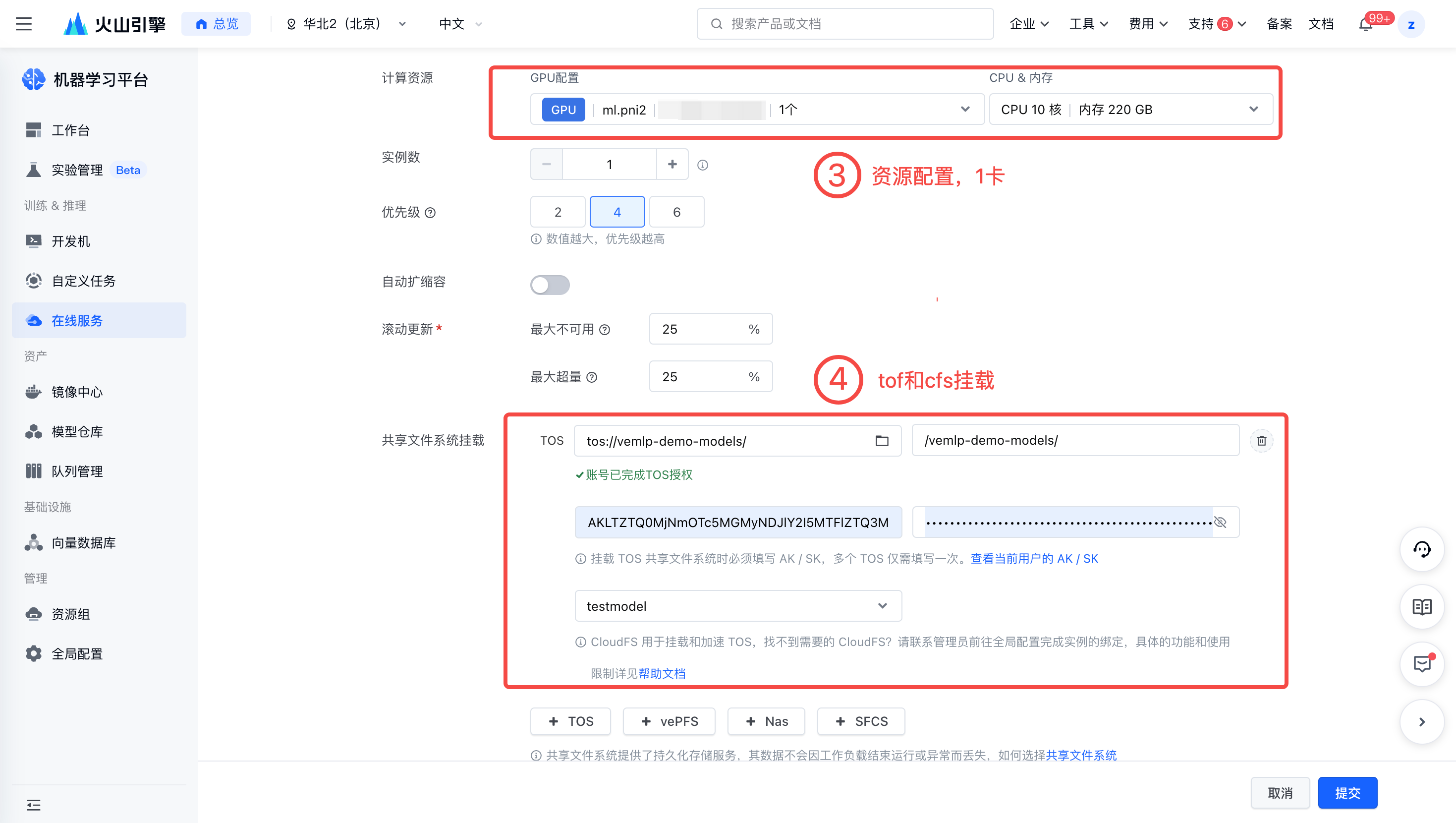
python -m vllm.entrypoints.openai.api_server --model /vemlp-demo-models/model-llama/vllm/ --served-model-name \"llama3\" --tensor-parallel-size 1 --max-num-seqs 64配置资源。最佳实践使用 1 卡 ml.pni2。
挂载 TOS 与 CFS。
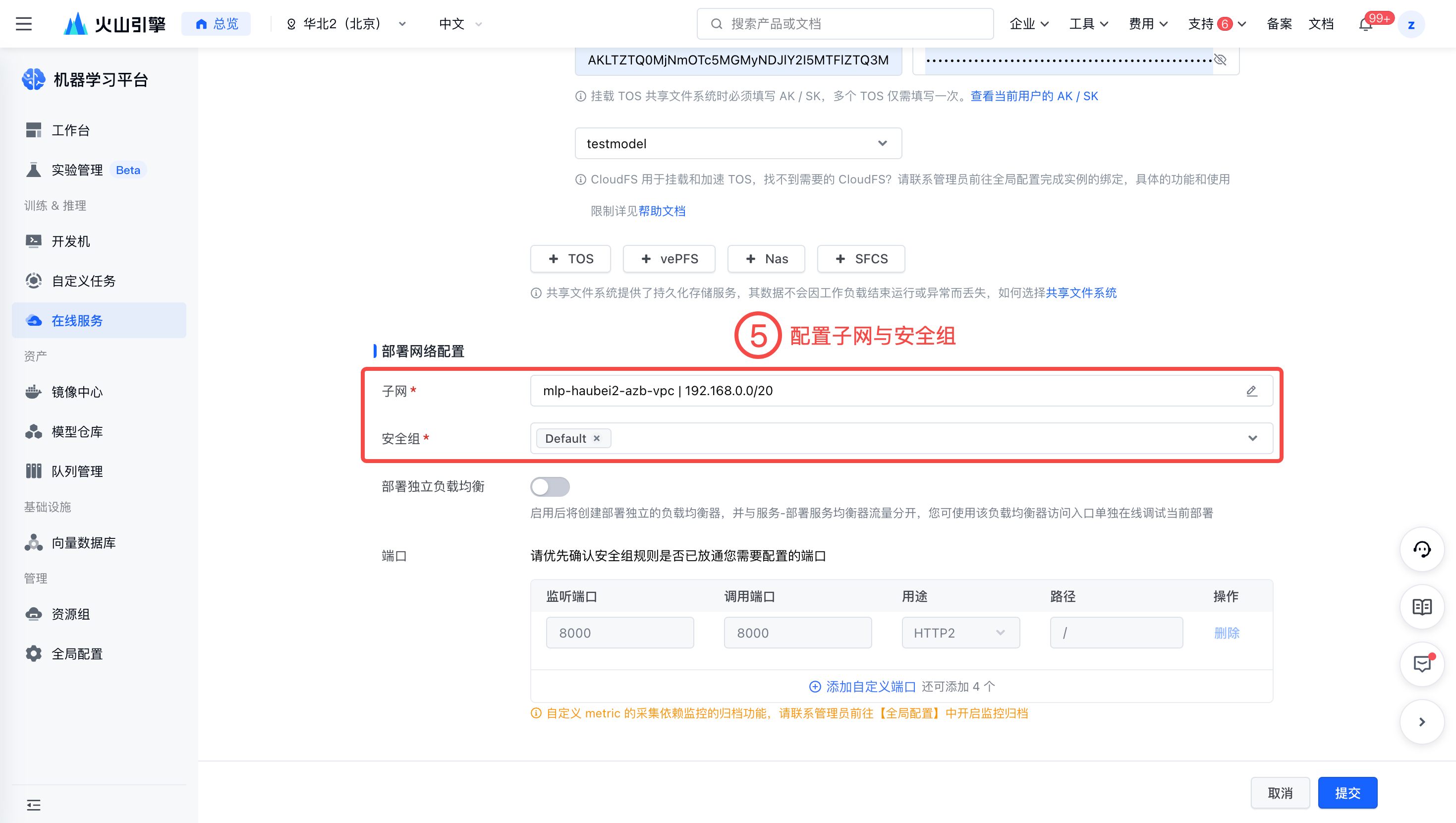
配置子网与安全组。
4.3 定义请求文件 request.py 并执行
- 创建 request.py 文件。脚本内容示例如下。
import requests import json # 定义请求,更换具体的ip地址 url = "http://101.126.23.138:8000/v1/completions" headers = { "Content-Type": "application/json" } data = { "model": "llama3", "prompt": "San Francisco is a", "max_tokens": 100, "temperature": 0 } # 发送POST请求 response = requests.post(url, headers=headers, data=json.dumps(data)) # 打印响应内容 print(response.json())
- 执行命令请求。
python request.py
结果如下。
{'id': 'cmpl-a40535c337134dd090863e69a7fbb240', 'object': 'text_completion', 'created': 1725420936, 'model': 'llama3', 'choices': [{'index': 0, 'text': " city of many neighborhoods, each with its own unique character and charm. Whether you're looking for a hipster haven, a family-friendly area, or a place to party, there's a neighborhood for you. Here are some of the best neighborhoods in San Francisco to check out:\nThe Mission: The Mission is a hipster haven with a vibrant arts scene, great food, and a lively nightlife. It's also home to the city's largest Latino population, making it a great place to experience authentic", 'logprobs': None, 'finish_reason': 'length', 'stop_reason': None, 'prompt_logprobs': None}], 'usage': {'prompt_tokens': 5, 'total_tokens': 105, 'completion_tokens': 100}}