DeepSeek-R1-Zero 使用 GRPO 算法来进行强化学习(Reforcing Learning, RL)训练,探索了大语言模型在没有监督数据情况下发展推理能力的潜力。在训练过程中完全不依赖监督微调,通过固定规则的 reward 函数来引导模型学习后,模型发展出了自我反思,自我验证和生成长思维链(Chain of Thought , COT) 的能力。
veRL 是火山引擎推出的用于大语言模型(LLM)的强化学习库,具有灵活性、高效性且适用于生产环境。
- 灵活易用:通过混合编程模型,能轻松扩展多种强化学习算法。
- 速度快:集成现有先进的 LLM 训练和推理框架,实现高生成和训练吞吐量,进行高效的 Actor 模型重分片,减少内存冗余和通信开销。
- 开源生态:模块化 API 可实现与现有 LLM 框架(如 PyTorch FSDP、Megatron-LM 和 vLLM )的无缝集成;支持灵活的设备映射,可在不同 GPU 组合上部署模型;能与 HuggingFace 模型集成。已经通过gitHub开源,广受开发者关注。
在本教程中,您将了解在火山引擎机器学习平台(veMLP)上如何使用 veRL 进行 GRPO 强化学习训练。
目标
- 了解 GRPO 强化学习的基本原理
- 了解使用 veRL 进行模型强化学习的方法
- 在机器学习平台自定义任务模块上使用 veRL进行 GRPO 强化学习训练。
组件
本文将会使用如下组件:
- 火山引擎机器学习平台
- veRL 强化学习训练框架
- vePFS
在开始任务之前,需要配置 volc cli 或者 volc python sdk,如果您不知道您的 AK/SK,可以通过 https://console.volcengine.com/iam/keymanage/ 获得您当前身份的密钥对。
开发准备
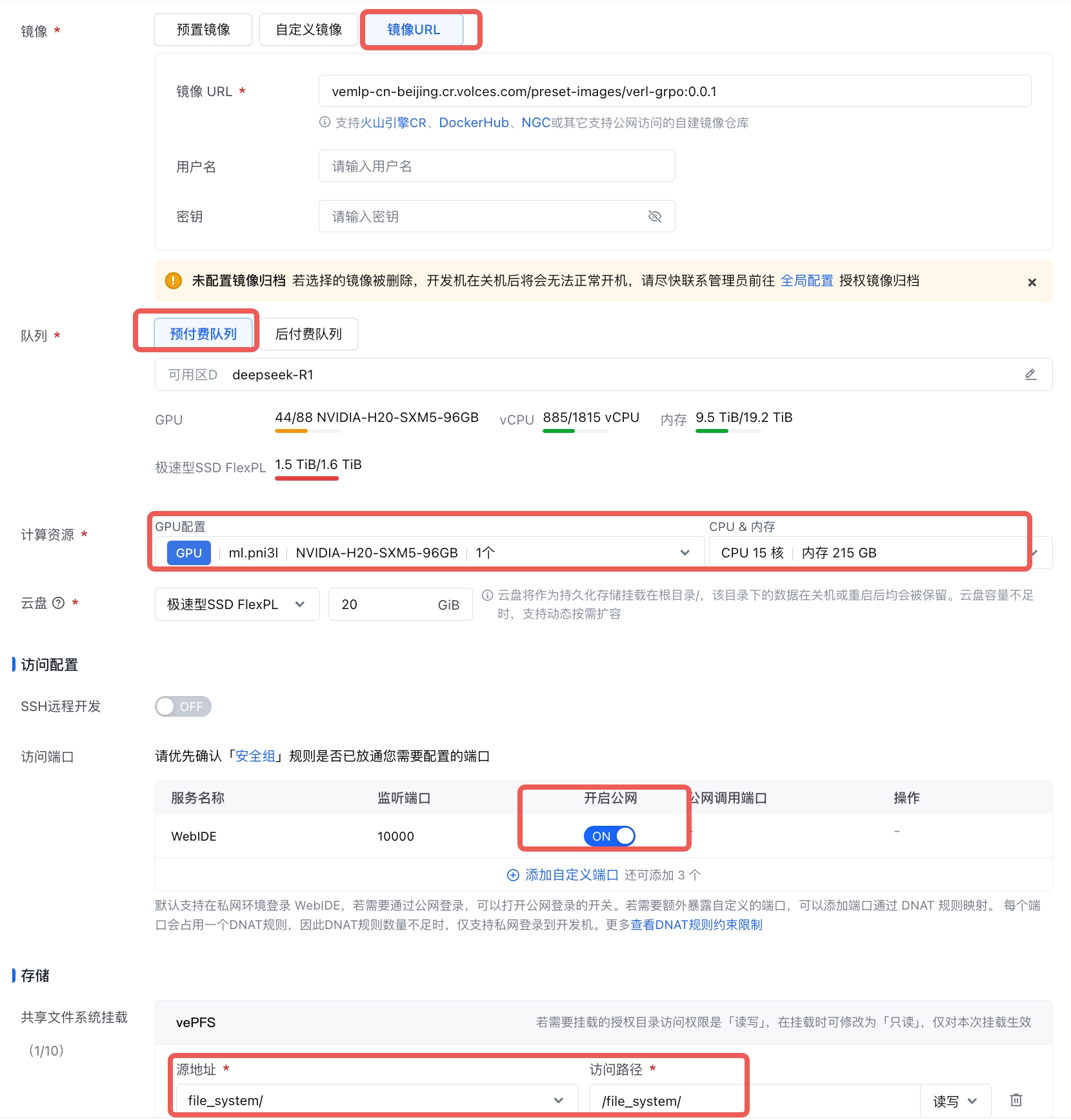
在机器学习平台创建开发机,选择好队列计算资源配置、访问配置、挂载共享文件系统后,即可创建。
- 需要用户在镜像入口采用镜像 url 的方式:并根据您所在的 region 修改 URL,例:
- 华北2:
vemlp-cn-beijing.cr.volces.com/preset-images/verl-grpo:0.0.1 - 华东2:
vemlp-cn-shanghai.cr.volces.com/preset-images/verl-grpo:0.0.1
- 华北2:
- 本文是将 vePFS 挂载到
/file_system目录,可根据您的具体情况进行调整。
登录到机器学习平台开发机 WebIDE,打开终端,新建 Jupyter Notebook 交互式开发环境,并选择合适的 Python 环境
# 查看当前 python 的环境路径,推荐选择 `~//miniconda3/bin/python` which python
环境变量配置
volc cli 配置
volc cli 为机器学习平台的命令行工具,可以以命令行的方式便捷的进行任务提交,任务管理等操作。预置镜像已经安装volc命令行工具,进行升级操作。
# 升级volc cli ! volc upgrade # 查看volc cli版本 ! volc v
可通过以下操作配置好 volc cli 和 jupyter notebook 需要的的环境依赖
如果您不知道您的 AK/SK,可以通过 API 访问密钥获得您当前身份的密钥对。
# 火山引擎认证配置(替换为你的 AK/SK) VOLC_ACCESS_KEY_ID = '**' VOLC_SECRET_ACCESS_KEY = '==' # 默认使用开发机所在的 region import os VOLC_REGION=os.environ['MLP_REGION'] # 一次性设置所有环境变量(Jupyter魔法命令) %set_env VOLC_ACCESS_KEY_ID={VOLC_ACCESS_KEY_ID} %set_env VOLC_SECRET_ACCESS_KEY={VOLC_SECRET_ACCESS_KEY} %set_env VOLC_REGION={VOLC_REGION} # 配置火山命令行工具(自动读取已设置的环境变量) ! volc configure --ak $VOLC_ACCESS_KEY_ID --sk $VOLC_SECRET_ACCESS_KEY --region $VOLC_REGION # 验证配置文件(可选) ! echo "volc config:" && cat ${HOME}/.volc/config ! echo "volc credentials:" && cat ${HOME}/.volc/credentials
镜像配置
这里配置该文档所提交的所有任务,所用到的镜像信息,会默认使用你开机机所在 region 的镜像,如有其他需求,请更换为您所在的区域,以获取更好的体验。
# 根据当前 region 生成镜像地址 image_url = f'vemlp-{VOLC_REGION}.cr.volces.com/preset-images/verl-grpo:0.0.1' print(f'image: {image_url}')
GRPO 的基本概念如下:
| 角色 | 概念 |
|---|---|
| Actor model | 策略模型,我们要优化的目标。策略模型会在 training 和 inference 两种模式之间来回切换,在 inference 阶段(RollOut),将随机选择一批prompt,迭代生成响应(顺序地一个一个生成 token)。在 training 阶段,将根据一批 prompt 所生成的响应、奖励,根据损失函数进行训练更新。 |
| Reference model | 参考模型,用于约束策略模型,防止其大幅偏离初始模型。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。参考模型只推理不更新,针对一批prompt只推理一次。 |
| Reward func | 奖励函数,只验证结果的正确性和格式,来对策略模型的输出进行打分。 |
GRPO的核心在于通过组内相对奖励来优化策略,而不是依赖传统的批评模型(critic model)。具体来说:
- 对于每个输入问题,模型会生成一组可能的输出。
- 这些输出结果不是单独评估,而是通过相互比较来打分,即通过计算每个输出相对于组内平均水平的表现来确定其优势。
- 这种方法消除了对独立评估器的需求,使得训练过程更加高效。
GRPO特别适用于需要复杂问题求解和长推理链的任务,例如数学推理、代码生成等
tosutil 配置(需要手动配置)
如果不使用平台预置好的数据集和模型,可跳过此步骤。
tosutil 是用于访问和管理火山引擎对象存储(TOS)的命令行工具。通过该命令行工具,您可进行本地与 TOS 之间的批量数据处理,以应对本地中小数据上云、云上中小数据下载、自动化脚本任务集成等常见业务场景。机器学习平台开发机已经预装了 tosutil 工具
! tosutil version
可通过以下操作配置好 tosutil 需要的的环境依赖,并声明共享存储的目录,方便后续提交任务使用相同的存储配置,本文以将 vePFS 挂载到 /file_system 目录为例
! tosutil config -i $VOLC_ACCESS_KEY_ID -k $VOLC_SECRET_ACCESS_KEY -e tos-$VOLC_REGION.ivolces.com -re $VOLC_REGION root_path = '/file_system' model_path = f'{root_path}/models' model_name = 'Qwen/Qwen2.5-32B-Instruct'
数据准备
当前我们已经预置了 gsm8k 和 countdown 数据集在镜像中,您可以直接使用。数据集的示例处理步骤如下:
- gsm8k 数据集:
cd /root/code/verl/examples/data_preprocess/ python3 gsm8k.py --local_dir /root/code/data/gsm8k
- countdown 数据集:
cd /root/code/TinyZero mkdir -p /root/code/TinyZero/data/countdown python examples/data_preprocess/countdown.py --template_type=qwen-instruct --local_dir=/root/code/TinyZero/data/countdown
机器学习平台预置模型下载
火山引擎提供TOS对象存储预置模型权重文件,方便客户自助复制,加速试验。以 Qwen/Qwen2.5-32B-Instruct 模型为例。
import os # cp 需要带-r 参数,否则不会下载目录;传输速度慢可以根据开发机的 CPU 数量调整 -j -p 并发参数 ! tosutil cp tos://preset-models-{VOLC_REGION}/{model_name}/ {model_path}/{os.path.dirname(model_name)} -r -u -j=32 -p=4 -nfj=16
使用 veRL 发起 GRPO 强化学习训练任务
veRL 支持采用 Ray 多节点任务的形式对 Qwen32B 模型进行 GRPO 强化学习训练。 本文使用 gsm8k 数据集,以 Qwen32B 模型在 2 个 Hopper 节点进行分布式训练为例,展示强化学习微调模型的流程。
运行环境设置
您可通过以下方式获取相关运行配置
- 访问文件存储 vePFS获取关于vepfs的配置信息。
- 访问队列管理以获取队列ID
- 访问 实例规格与定价 获取您希望使用的规格
- 请确保本notebook挂载配置与下列文件系统配置完全一致
# 资源配置 queue='q-xx-gp9gt' # 队列 id flavor='ml.hpcpni3ln.45xlarge' replicas=2 # 文件系统配置 mount_path = "/file_system" # vepfs 挂载路径 storage_type = "Vepfs" vepfs_id = "vepfs-xxx" # vepfs id experiment_name="qwen2_3b_function_rm" # wandb 实验名称
设置训练参数
当前我们已经预置了一些调优后的参数,您还可以进一步自定义超参数。相关配置在 /root/code/verl/examples/grpo_trainer/train_mlp.sh 文件内。了解更多参数的含义和进行训练调优,可参考 verl 官方调优指南 perf_tunning 。
提交任务
首先配置自定义任务的启动参数,并通过 volc cli 命令行工具提交自定义任务。使用 Ray 框架进行分布式训练,执行下面的命令新建一个 demo-grpo-train-task.yaml 的任务配置文件:
import yaml # 定义配置内容 task_config = { "TaskName": "ray-verl-grpo-Qwen-32B", "Description": "Use Ray and verl rl Qwen-32B model", "Entrypoint": f'''export MODEL_PATH={model_path}/{model_name} export experiment_name={experiment_name} export NUM_NODE={replicas} cd /root/code/verl bash examples/grpo_trainer/train_mlp.sh ''', "Tags": [], "Envs": [], "ResourceQueueID": queue, #replace_with_your_ResourceQueueID "Framework": "Ray", "TaskRoleSpecs": [ #replace_with_your_TaskRoleSpecs { "RoleName": "head", "RoleReplicas": 1, "Flavor": flavor, }, { "RoleName": "worker", "RoleReplicas": replicas - 1, "Flavor": flavor, } ], "ActiveDeadlineSeconds": 864000, "EnableTensorBoard": False, #replace_with_your_Storages "Storages": [ { "MountPath": mount_path, "Type": storage_type, "VepfsId": vepfs_id, } ], "ImageUrl": image_url, #replace_with_you_image_url "RetryOptions": { "EnableRetry": False, "MaxRetryTimes": 5, "IntervalSeconds": 120, "PolicySets": [], }, } # 将配置写入到 ray-verl-grpo.yaml 文件中 import datetime verl_grpo_config_yaml = f'ray-verl-grpo-{datetime.datetime.now().strftime("%Y%m%d_%H%M%S")}.yaml' with open(verl_grpo_config_yaml, "w") as file: yaml.dump(task_config, file, default_flow_style=False) print(f"{verl_grpo_config_yaml} 文件已生成") ! volc ml_task submit --conf {verl_grpo_config_yaml}
通过 volc 命令行工具查询作业状态
! volc ml_task get --id t-20241021145150-qc49r --output json --format Status
通过 Ray Dashboard 观察作业的执行状态
发起训练任务后,可以在 Ray Dashboard 中查看详细任务运行状态和日志:
详细请参考:官方文档
训练性能对比参考
采用 Hopper 机型,在 Qwen 不同基础模型上进行训练的性能参数对比如下:
| 基础模型 | 设备规格 | 卡数 | ppo_mini_batch_size | micro_batch_size | 耗时(s)/step | 显存利用率(max) | MFU |
|---|---|---|---|---|---|---|---|
| Qwen/Qwen2.5-32B | ml.hpcpni3l (H20) | 2*8 | 256 | 动态 batch-size | 478.5 | 97% | 0.6495 |
| Qwen/Qwen2.5-32B | ml.hpcpni3l (H20) | 2*8 | 256 | 8 | 547.7 | 85% | 0.5131 |
| Qwen/Qwen2.5-14B | ml.hpcpni3l (H20) | 2*8 | 256 | 8 | 338.4 | 80% | 0.50428 |
| Qwen/Qwen2.5-1.5B | ml.hpcpni3l (H20) | 2*8 | 256 | 8 | 66.0 | 65% | 0.35187 |
| Qwen/Qwen2.5-32B | ml.hpcpni3l (H20) | 8 | 256 | 8 | 985.9 | 99% | 0.5341 |
| Qwen/Qwen2.5-14B | ml.hpcpni3l (H20) | 8 | 256 | 8 | 445.3 | 88% | 0.51396 |
| Qwen/Qwen2.5-7B | ml.hpcpni3l (H20) | 8 | 256 | 8 | 222.1 | 86% | 0.67174 |
| Qwen/Qwen2.5-1.5B | ml.hpcpni3l (H20) | 8 | 256 | 8 | 101.9 | 67% | 0.38671 |
H20 机型和 A800 机型的性能对比如下:
| 基础模型 | 设备规格 | 卡数 | ppo_mini_batch_size | micro_batch_size | 耗时(s)/step | 显存利用率(max) | MFU |
|---|---|---|---|---|---|---|---|
| Qwen/Qwen2.5-32B | ml.hpcpni3l (H20) | 2*8 | 256 | 动态 batch-size | 478.5 | 97% | 0.6495 |
| Qwen/Qwen2.5-32B | ml.hpcpni2l(A800) | 2*8 | 256 | 动态 batch-size | 389.3 | 99% | 0.47 |
| Qwen/Qwen2.5-32B | ml.hpcpni3l (H20) | 2*8 | 256 | 8 | 547.7 | 85% | 0.5131 |
| Qwen/Qwen2.5-32B | ml.hpcpni2l(A800) | 2*8 | 256 | 8 | 431.5 | 89% | 0.34 |
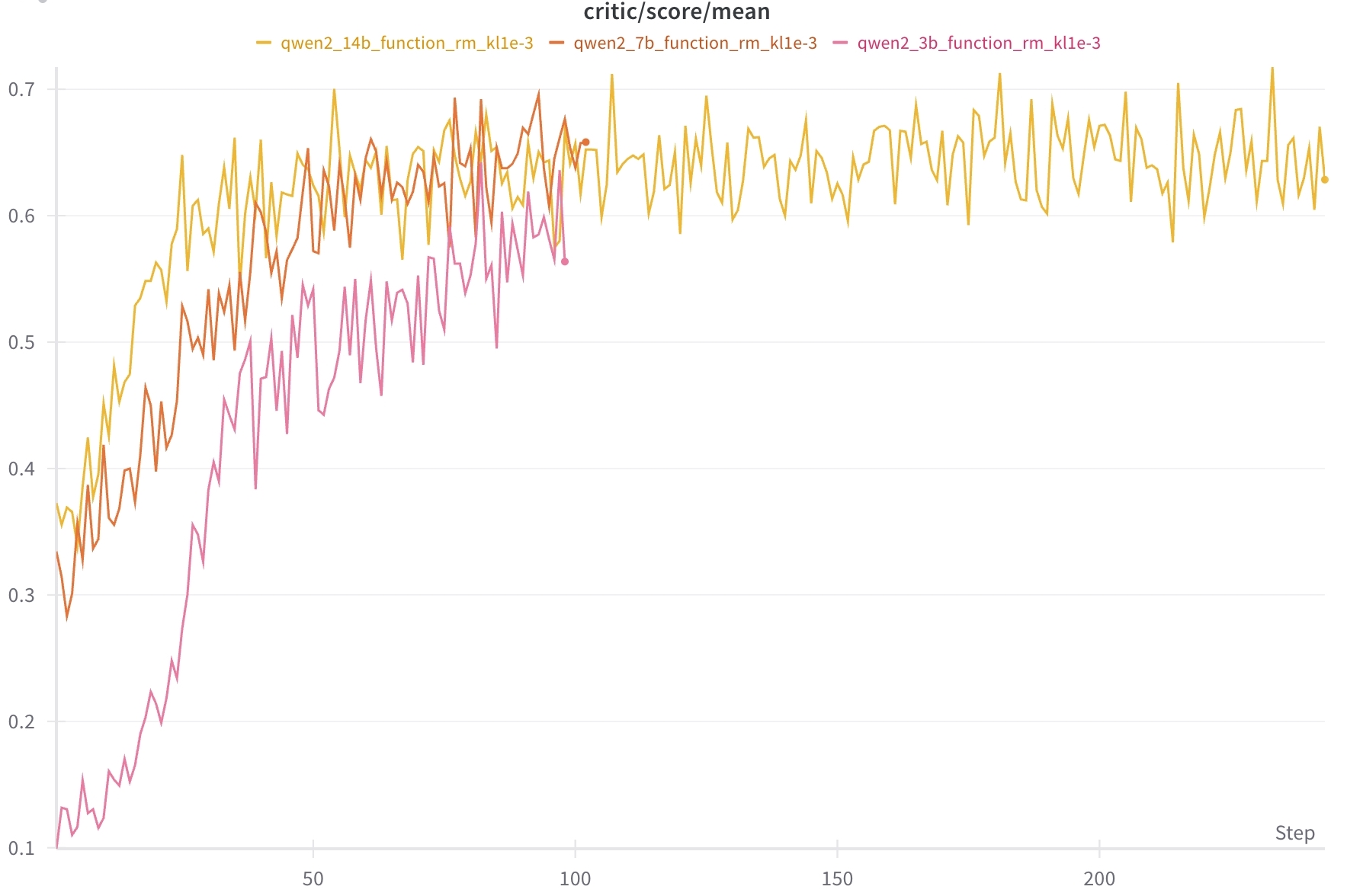
不同模型在不同 step 下的训练过程 critic/score/mean 指标对比如下: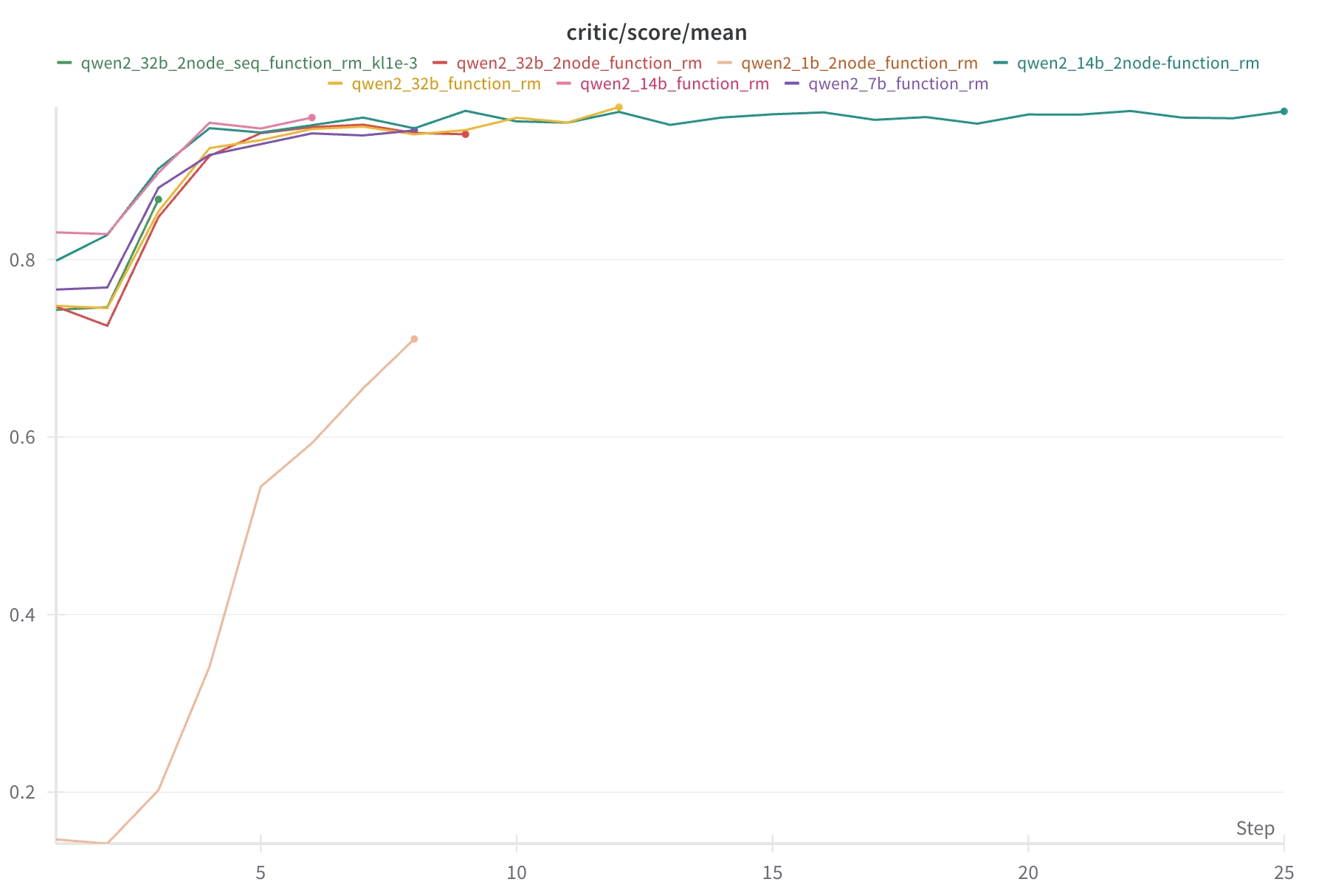
使用 TinyZero 项目复现 DeepSeek R1 Zero 的效果
TinyZero 是一个基于 veRL 的开源项目,在 countdown 和 multiplication 任务中复现了 DeepSeek-R1-Zero 的效果,通过 GRPO 强化学习训练,使用了基于规则的 rewards 函数,重点校验了结果的正确性和格式,在一定 step 训练之后,Qwen 3B 基础模型可以自行发展出自我验证和搜索能力。
我们在机器学习平台中可以复现该效果,下面介绍具体步骤。
设置训练参数
# 资源配置 queue='q-xx-gp9gt' # 队列 id flavor='ml.hpcpni3ln.45xlarge' # 文件系统配置 mount_path = "/file_system" # vepfs 挂载路径 storage_type = "Vepfs" vepfs_id = "vepfs-xxx" # vepfs id experiment_name="qwen2_3b_function_rm" # wandb 实验名称
执行下面的命令新建一个 demo-tinyzero-train-task.yaml 的任务配置文件:
import yaml # 定义配置内容 task_config = { "TaskName": "grpo-deepseek-r1-zero-reproduction", "Description": "Use grpo reproduction deepseek-r1-zero base on tinyzero ", "Entrypoint": f'''export MODEL_PATH={model_path}/{model_name} export experiment_name={experiment_name} cd /root/code/TinyZero bash scripts/train_mlp.sh''', "Tags": [], "Envs": [], "ResourceQueueID": queue, #replace_with_your_ResourceQueueID "Framework": "Ray", "TaskRoleSpecs": [ #replace_with_your_TaskRoleSpecs { "RoleName": "head", "RoleReplicas": 1, "Flavor": "ml.hpcpni3ln.45xlarge", } ], "ActiveDeadlineSeconds": 864000, "EnableTensorBoard": False, #replace_with_your_Storages "Storages": [ { "MountPath": mount_path, "Type": storage_type, "VepfsId": vepfs_id, } ], "ImageUrl": image_url, "RetryOptions": { "EnableRetry": False, "MaxRetryTimes": 5, "IntervalSeconds": 120, "PolicySets": [], }, } # 将配置写入到 ray-verl-grpo.yaml 文件中 import datetime tinyzero_config_yaml = f'tinyzero-{datetime.datetime.now().strftime("%Y%m%d_%H%M%S")}.yaml' with open(tinyzero_config_yaml, "w") as file: yaml.dump(task_config, file, default_flow_style=False) print(f"{tinyzero_config_yaml} 文件已生成") ! volc ml_task submit --conf {verl_grpo_config_yaml}
复现结果示例
一定步骤后,模型发展出了反思和自我验证的能力:
训练过程中的 critic/score/mean 指标演进过程如下: