机器学习平台
机器学习平台



文档指南

请输入


- 文档首页
 机器学习平台最佳实践样本数据的存储训练代码如何访问TOS
机器学习平台最佳实践样本数据的存储训练代码如何访问TOS

训练代码如何访问TOS
机器学习平台支持如下 2 种方式在训练代码中访问 TOS 的数据:
- 将 TOS 挂载为 POSIX 文件系统接口,然后训练代码像访问磁盘一样访问 TOS 中的对象。
- 具体的挂载方式,请参考【开发机】和【自定义任务】的产品界面及相关的帮助文档创建开发机、发起单机 / 分布式训练任务。
- TOS OpenAPI和SDK。
TOS 挂载为 POSIX 文件系统接口
运行在机器学习平台的训练容器中的各机器学习代码(支持 TensorFlow / PyTorch/ MXNet/ XGBoost等),可以通过火山引擎自研的 CloudFS 分布式文件系统将其转换为 POSIX 协议的接口,挂载到训练容器中。同时在 POSIX Client 端中提供一层缓存,加速第 2+ epoch 之后的访问速度。
下图为架构图,其中 CloudFS Fuse Client 和 GPU 部署在同一台 GPU 机器上,CloudFS 和 GPU 机器部署在同一个机房。
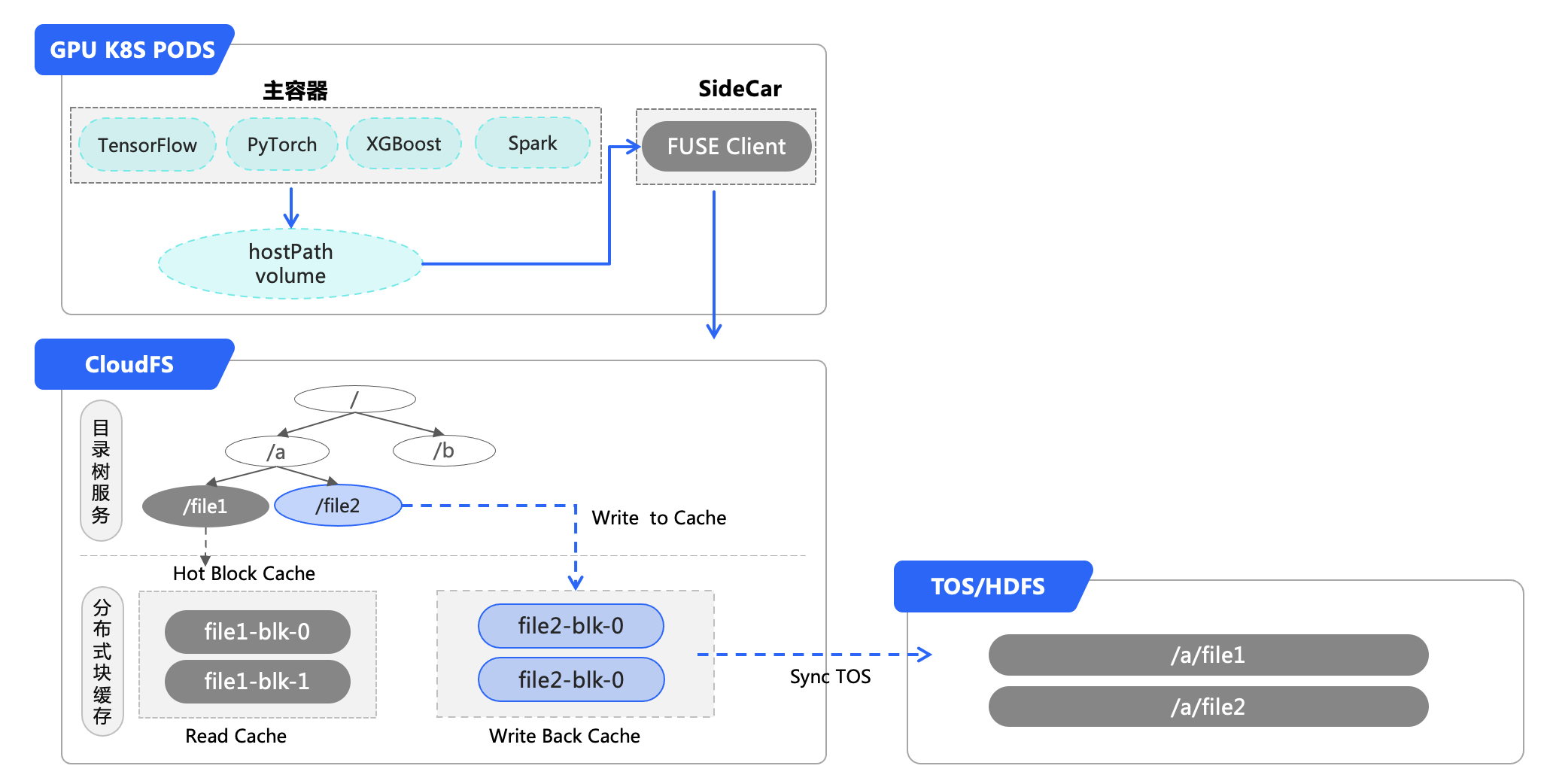
通过 CloudFS 挂载 TOS
文件追加写功能部分受限,支持以 append 模式创建、后缀为.log 打开的文件,其余方式打开的文件不支持追加写。
填写的 AK / SK 需要有 TOS 的读写权限,只读访问后续支持。
mv 操作限制文件数在 1w 以内。
动态向 TOS 中写入的新数据无法即时在挂载的共享文件系统中读到,需要在开发机、自定义任务的容器中执行如下指令手动刷新:
- 使用
cfs-cli刷新目录无法递归刷新,即对/dir1执行如下指令并不会刷新/dir1/sub_dir1这个子目录。
- 使用
cfs-cli ls <待刷新的目录>
最近更新时间:2025.02.10 19:36:02
这个页面对您有帮助吗?
有用
有用
无用
无用