导航
vePFS
最近更新时间:2024.01.10 10:46:38首次发布时间:2022.09.27 19:58:21
火山引擎 vePFS 是一种高吞吐、低延时、可扩展并行的文件系统,用户将 vePFS 挂载到开发机、自定义任务中即可实现高性能的数据读写。同时机器学习平台支持用户基于 vePFS Fileset 配置挂载权限,实现较为精细的权限管控。
相关概念
使用前提
- 当前用户拥有
MLPlatformAdminAccess的 IAM 策略(配置策略的方法详见权限管理)。- 如果以 IAM 中的用户组配置挂载权限,需要额外配置
IAMReadOnlyAccess的策略以获取用户组列表。
- 如果以 IAM 中的用户组配置挂载权限,需要额外配置
- 当前账号完成 VPC 的全局配置并在该 VPC 下创建 vePFS 实例及挂载点。
- 如果配置非根目录(
/)的挂载权限,需要具备vePFSFullAccess的 IAM 策略前往 vePFS 的控制台页面创建 Fileset。
- 如果配置非根目录(
使用步骤
- 登录机器学习平台,单击左侧导航栏中的【全局配置】进入对应页面。
- 单击【vePFS】中的【绑定实例】进入实例选择页面,选择一个符合条件的 vePFS 实例,提交表单后等待绑定完成。
若当前不存在可用的 vePFS 实例,请前往 vePFS 控制后创建。
绑定实例后也能通过【禁用】来临时限制用户在机器学习平台上使用 vePFS。
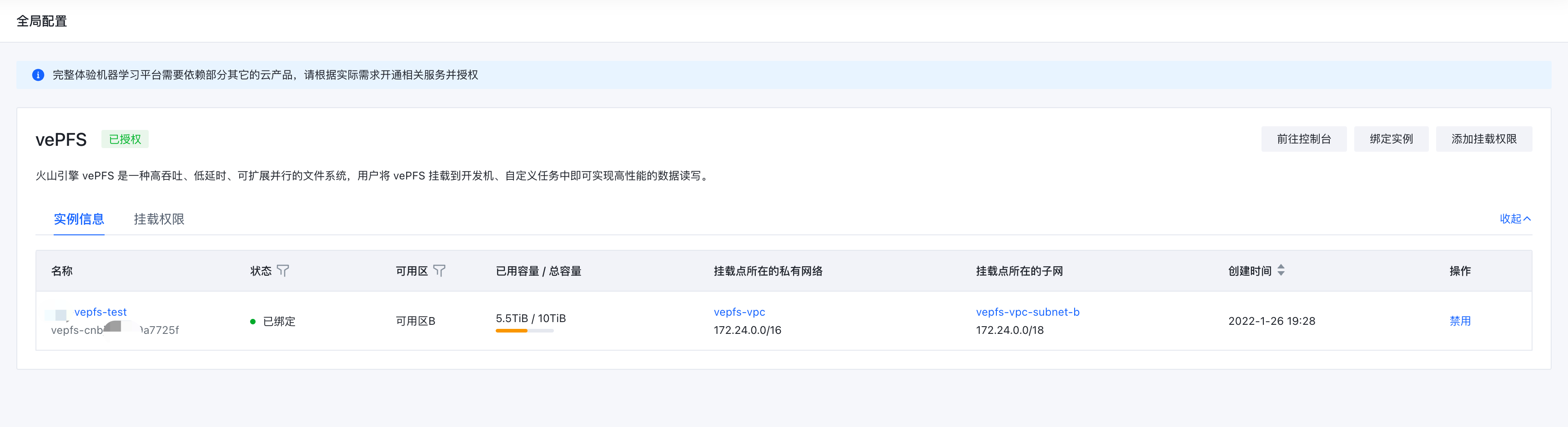
- 待实例绑定完成后,单击【添加挂载权限】进入对应页面后需要配置如下参数。
| 参数名称 | 参数说明 |
|---|---|
| vePFS 实例 | 选择某个已绑定的 vePFS 实例,在该实例中进行细粒度的挂载权限隔离。 必填 。 |
授权目录 | 需要配置挂载权限的目录,支持针对根目录、Fileset 目录以及 Fileset 下的子目录进行配置 必填 。
|
授权范围 | 将上述目录授权给哪些用户使用,支持对主账号内所有用户开放或仅在指定范围内开放。 必填。
|
- 完成上述表单的提交后将生成一条挂载权限的配置记录,后续用户即可在创建开发机、自定义任务时以目录的粒度挂载 vePFS 共享文件系统。
- 如有需要,用户后续可通过【编辑】入口进行授权范围的动态修改或者通过【删除】入口删除该条记录,删除后挂载权限将回收。
- 如下图所示,该主账号下的所有子账号都能在创建开发机、自定义训练任务时挂载
/wch/fileset02/test这个 vePFS 中的目录,而/wch/fileset02/sub这个目录仅某些用户能使用。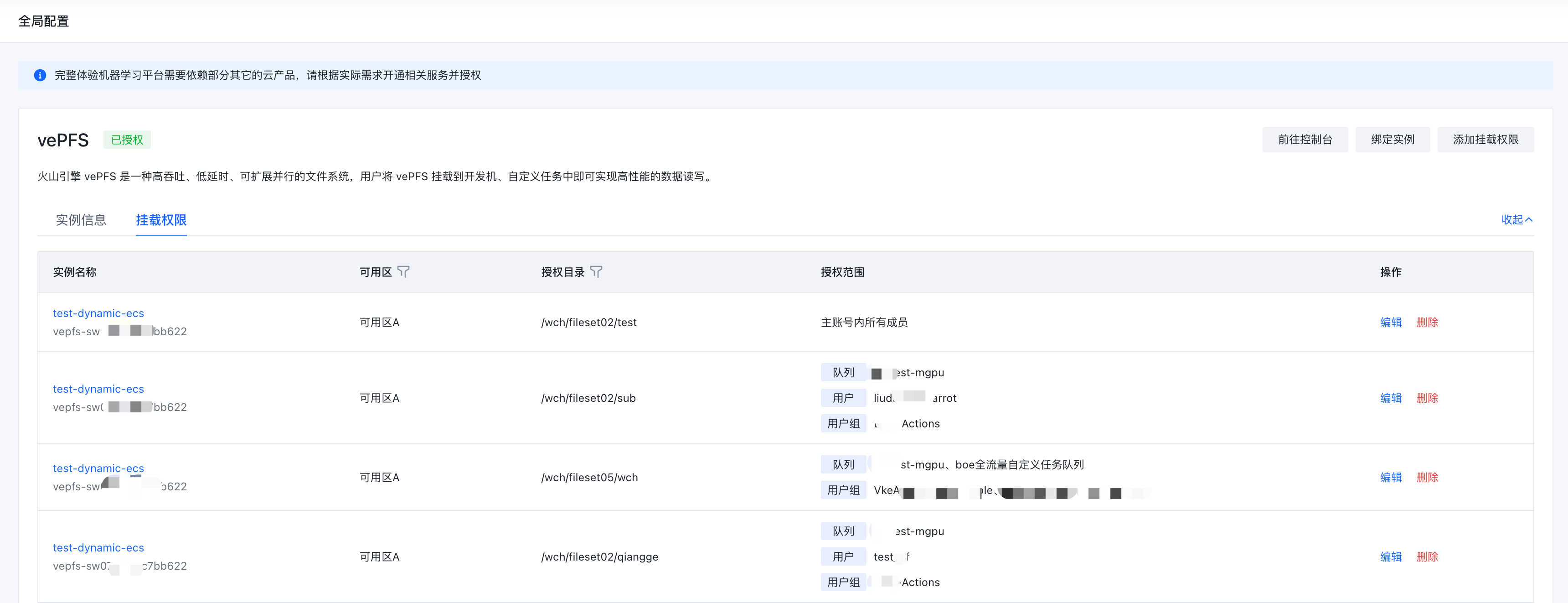
- 如下图所示,该主账号下的所有子账号都能在创建开发机、自定义训练任务时挂载
注意事项
- 若在机器学习平台挂载了两个vePFS实例,请注意以下事项:
- 通过CLI(命令行)和SDK挂载vePFS时,需要指定一个vePFS实例ID,否则无法提交挂载vePFS实例的负载任务。更多请参考命令行工具
- 使用vePFS存储TensorBoard日志同理,也需要指定实例ID。
- 若只有一个vePFS实例时,通过CLI(命令行)和SDK提交,无需指定vePFS实例ID(为空时默认使用全局配置绑定的实例)。