机器学习平台
机器学习平台






- 文档首页
 机器学习平台最佳实践自动驾驶BEVFormer模型在 MLP 上的最佳实践
机器学习平台最佳实践自动驾驶BEVFormer模型在 MLP 上的最佳实践

机器学习平台是一套服务于专业算法工程师,整合云原生的工具+算力 (GPU、CPU云服务器),进行一站式AI算法开发和迭代的平台。本方案将为您介绍如何在 MLP 使用 BEVFormer 模型进行训练。
本方案以 BEVFormer 模型为例,在开始执行操作前,请确认您已经完成以下准备工作:
已开通网络/vePFS,具体操作详见更改预付费资源组的负载网络VPC--机器学习平台-火山引擎、vePFS--机器学习平台-火山引擎。
已购买 MLP 资源,详见创建资源组--机器学习平台-火山引擎。关于资源价格详情,请详见实例规格及定价--机器学习平台-火山引擎。
已创建开发机实例,其中关键参数配置如下。具体操作详见创建开发机--机器学习平台-火山引擎。
资源规格:配置以下资源规格。
CPU 实例:8C/64G/20GB云盘。
GPU 卡数:至少 8 卡,最佳实践采用一台 ml.pni3l。
挂载配置:当您是多机训练任务时,需要挂载 vePFS 并行文件系统,详情配置信息请访问文件存储vePFS。
镜像地址:在自定义镜像处配置下方镜像,填写 SSH key 。由于拉取的镜像较大,首次创建开发机时间预计 20 分钟。
vemlp-cn-beijing.cr.volces.com/preset-images/bevformer:0.0.1
说明
BEVFormer的代码已预制在镜像里,默认目录为/root/code/BEVFormer,不需要重新下载。
进入开发机。
登陆 账号登录-火山引擎。
在左侧导航栏单击开发机,在开发机列表页面中单击待操作的开发机名称,进入对应开发机内。
通过 SSH 远程登录开发机,具体操作详见通过SSH远程连接开发机--机器学习平台-火山引擎。
配置 volc configure。具体操作详见使用文档--机器学习平台-火山引擎。
当前镜像中已经预制了 nuScenes V1.0 mini 数据集在
/root/code/BEVFormer/data目录内,您可以直接使用并进行后续训练,并跳过该章节后面的步骤。如果您想使用 V1.0 full 数据集进行训练,可以参照以下步骤下载并配置对应数据集。
wget https://d36yt3mvayqw5m.cloudfront.net/public/v1.0/v1.0-trainval_meta.tgz wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval01_blobs.tgz # 如果需要继续下载剩下的 9 个 part,可继续执行以下命令 # for part_num in {2..10}; do # if [ $part_num -lt 10 ]; then # wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval0${part_num}_blobs.tgz # else # wget https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval${part_num}_blobs.tgz # fi # done tar -xzvf v1.0-trainval_meta.tgz -C /root/code/BEVFormer/data tar -xzvf v1.0-trainval01_blobs.tgz -C /root/code/BEVFormer/data # 继续解压剩下的 9 个 part # for part_num in {2..10}; do # if [ $part_num -lt 10 ]; then # tar -xzvf v1.0-trainval0${part_num}_blobs.tgz -C /root/code/test # else # tar -xzvf v1.0-trainval${part_num}_blobs.tgz -C /root/code/test # fi # done cd /root/code/BEVFormer/ # 数据预处理 python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0 --canbus ./data
2.1 在开发机中进行训练调试
如果您使用的是 GPU 开发机,可以直接进入开发机内进行训练,启动训练命令如下。其中命令的最后一个参数为使用的 GPU 卡数。
cd /root/code/BEVFormer && sh ./tools/train.sh ./projects/configs/bevformer/bevformer_base.py 8
2.2 自定义任务分布式训练(指令微调)
最佳实践文档提供控制台与命令行两种方式的操作说明。
方式一:控制台
进入自定义任务控制台
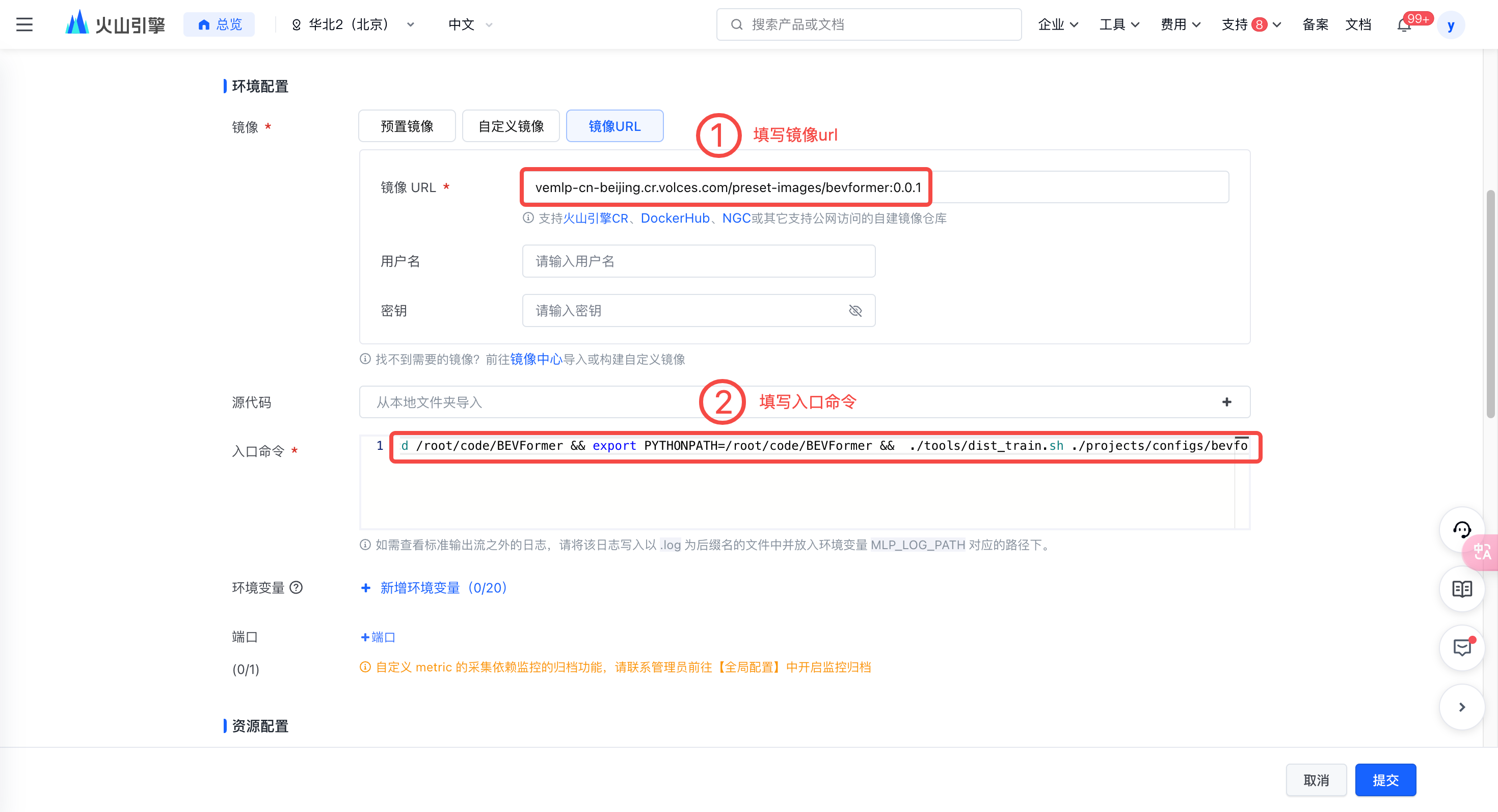
配置环境
- 在自定义镜像处配置镜像。
vemlp-cn-beijing.cr.volces.com/preset-images/bevformer:0.0.1- 填写入口命令并定义环境变量。请注意 vePFS 在开发机上挂载的路径与自定义任务中挂载的路径不一致,在入口命令填写数据集路径环境变量中填写模型路径时,需确保为自定义任务中挂载的路径。
cd /root/code/BEVFormer && export PYTHONPATH=/root/code/BEVFormer && ./tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py
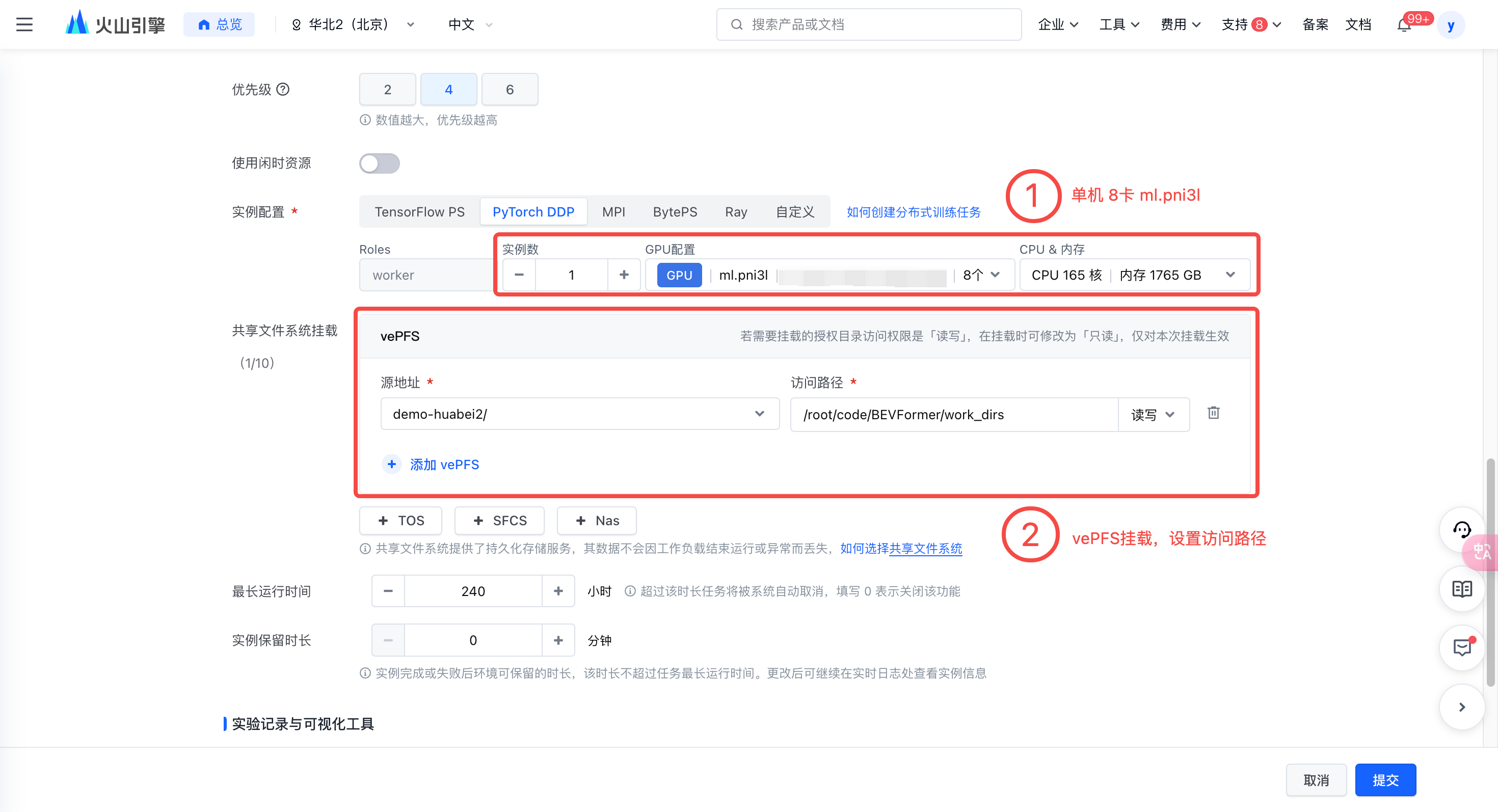
- 配置资源
选择合适的资源,最佳实践所用机器为单机 8 卡 ml.pni3l。
挂载 vePFS。需要注意:如果是多机训练任务,需配置共享存储到
/root/code/BEVFormer/work_dirs目录。
说明
此处挂载 vePFS 的共享存储访问路径为训练后模型的存储路径,您可以自行修改该路径,并在模型代码中同步修改。
方式二:命令行
在 Terminal 中使用以下命令对 BEVFormer 进行训练,具体操作步骤如下。
创建一个 demo-bevformer-train.yaml 文件。
编辑 yaml 文件,填写镜像、资源规格、环境变量以及入口命令。
运行任务命令。如运行成功,在 Terminal 会出现 “创建任务成功,task_id=*****” 字样。采用 nuScenes v1.0 mini 数据集的完整训练时长预计为 30 min左右。
您还可以进一步自定义超参数,如学习率和训练步数(epochs)等。相关配置在
projects/configs/bevformer/bevformer_base.py目录内。
volc ml_task submit --conf=demo-bevformer-train.yaml
demo-bevformer-train.yaml 文件示例:
TaskName: "BEVformer-demo-train" Description: "" Tags: [] ImageUrl: "vemlp-cn-beijing.cr.volces.com/preset-images/bevformer:0.0.1" ResourceQueueID: "q-**************" #请替换为自己的队列ID # DL framework, support: TensorFlow PS,PyTorch DDP,Horovod,BytePS Framework: "PyTorchDDP" # Flavor代表机型,去 https://www.volcengine.com/docs/6459/72363 查询 TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 Flavor: "custom" ResourceSpec: Family: "ml.pni3l" CPU: 165.000 Memory: 1765.000 GPUNum: 8 AccessType: "Queue" Storages: - Type: "Vepfs" MountPath: "/root/code/BEVFormer/work_dirs" #该路径可以修改 ReadOnly: "False" VepfsHostPath: "/mnt/vepfs-**************" #请替换为自己的文件系统ID VepfsId: "vepfs-**************" #请替换为自己的文件系统ID VepfsName: "demo-huabei2" #请替换为自己的文件系统名称 Entrypoint: | cd /root/code/BEVFormer && export PYTHONPATH=/root/code/BEVFormer && ./tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py
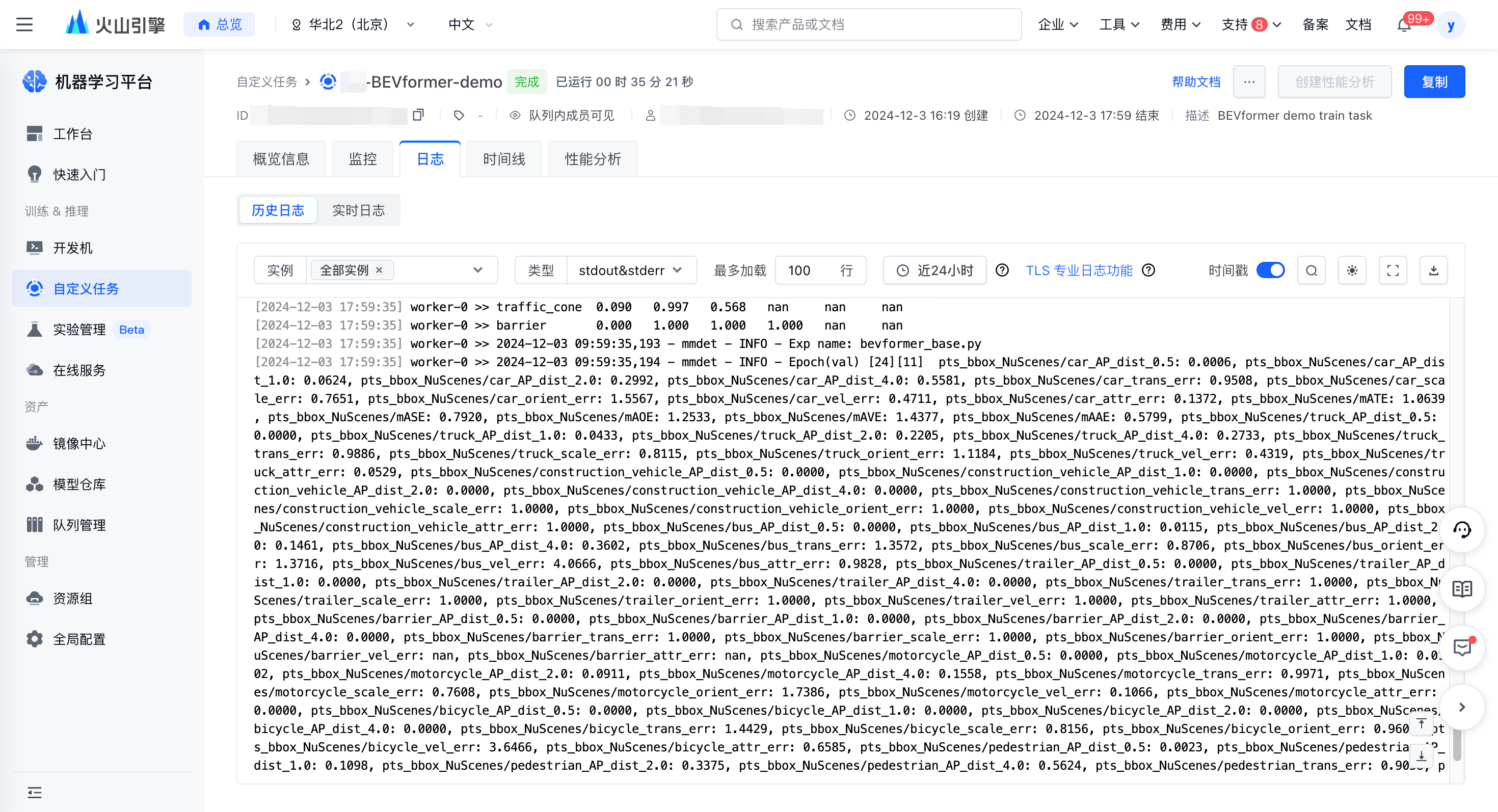
- 训练完成后,可以在任务日志处查看训练日志信息。