说明
此功能为开白功能,且开白后不支持回滚(取消开白),请按需申请使用。
平台新增支持GPU与CPU规格灵活配比功能,旨在开放资源选择灵活度,提升GPU服务器上CPU/内存资源的利用率。
开发机/自定义任务/在线服务均支持GPU/CPU灵活配比功能。
页面交互
开发机路径:【开发机】-【创建开发机】-【环境配置-计算资源】
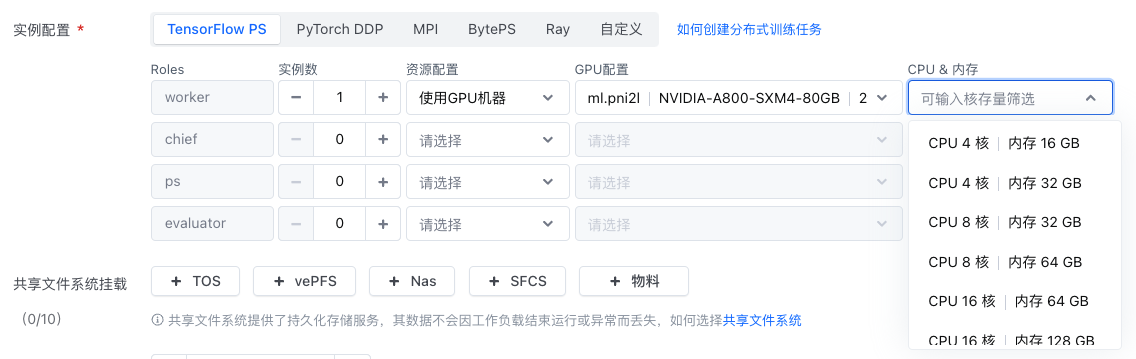
自定义任务路径:【自定义任务】-【创建自定义任务】-【资源配置-实例配置】
在线服务路径:【在线服务】-【创建服务】-【资源配置-计算资源】
以下说明为自定义任务中操作步骤:
- 点击自定义任务-创建自定任务,选择资源配置-实例配置。实例配置中支持选择GPU服务器以及CPU服务器。在使用GPU服务器时支持如下资源配置方式:
选择CPU服务器,则GPU规格置灰不可操作,仅可选择对应的CPU/内存资源。
选择GPU服务器,GPU卡数选择范围为0-8(详细取决队列GPU配额上限),可根据GPU选择的卡数选择对应的CPU/内存资源。
- 由于该种资源配置方式下,容易造成GPU资源碎片。因此当选择GPU机器而不分配GPU资源(选择0卡)时,建议启用「使用闲时资源」功能。此时造成碎片的CPU任务可能会被GPU任务抢占,以提升GPU利用率。
可选的GPU和CPU规格为队列配额上限,即若队列中无GPU资源,则此时不可见GPU规格选项。
命令行
- 在 volc cli中ml_task相关命令下增加对灵活配比方式指定资源的支持。
自定义任务yaml定义中对指定资源的结构体做了扩展。
非灵活配比方式提交自定义任务,格式不做变更。
# self define e.g text_classfication TaskName: "非灵活配比方式提交的任务" # description for this task Description: "" # entry point command Entrypoint: "sleep infinity" Tags: [] # the code path you want to upload locally UserCodePath: "" # remote path mount in training container RemoteMountCodePath: "" # user define env var Envs: [] # queue created under Resource Group, empty as default queue ResourceQueueID: "q-xxxxxxxxxx" # distributed framework, support: TensorFlow PS,PyTorch DDP,Horovod,BytePS Framework: "Custom" TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 Flavor: "ml.c2i.large" ActiveDeadlineSeconds: 864000 # enable tensor board or not EnableTensorBoard: false # storages Storages: [] ImageUrl: "vemlp-cn-beijing.cr.volces.com/preset-images/python:3.10" CacheType: "Cloudfs" # user define retry options RetryOptions: EnableRetry: true MaxRetryTimes: 5 IntervalSeconds: 120 PolicySets: - "Failed"开启灵活配比方式提交自定义任务后,指定资源格式作了对应扩展。
# self define e.g text_classfication TaskName: "灵活配比方式提交的gpu/cpu任务" # description for this task Description: "" # entry point command Entrypoint: "sleep inf" Tags: [] # the code path you want to upload locally UserCodePath: "" # remote path mount in training container RemoteMountCodePath: "" # user define env var Envs: [] # queue created under Resource Group, empty as default queue ResourceQueueID: "q-xxxxxxxxxx" # distributed framework, support: TensorFlow PS,PyTorch DDP,Horovod,BytePS Framework: "TensorFlowPS" TaskRoleSpecs: - RoleName: "worker" RoleReplicas: 1 # 当使用灵活配比方式提交的GPU任务时,填写以下参数。提交CPU任务时请注释掉 Flavor: "custom" ResourceSpec: Family: "ml.hpcpni2l" CPU: 105.000 Memory: 1875.000 GPUNum: 8 # 当使用灵活配比方式提交的CPU任务时,填写以下参数。提交GPU任务时请注释掉 Flavor: "custom" ResourceSpec: CPU: 2.000 Memory: 8.000 ActiveDeadlineSeconds: 864000 # enable tensor board or not EnableTensorBoard: false # storages Storages: [] ImageUrl: "vemlp-cn-beijing.cr.volces.com/preset-images/python:3.10" CacheType: "Cloudfs" # user define retry options RetryOptions: EnableRetry: false MaxRetryTimes: 5 IntervalSeconds: 120 PolicySets: []
submit 子命令
cli 端会对填写的CPU/内存做前置校验,只允许填写该用户在平台前端提交任务时可见的CPU/内存组合。
不允许未灵活配比开白的用户使用灵活配比方式提交,提交时会报错拦截。
- 允许灵活配比开白的用户使用之前非灵活配比方式提交,提交后会根据原方式下指定的Flavor自动转成对应的灵活配比方式的写法。
export 子命令
- 支持对"灵活配比方式"指定资源的任务的导出。
开白后仍然按原Flavor提交的方式新提交的负载(只可能是cli提交的)资源请求量相较原来会变小。
开白后用户使用原有yaml文件在混合队列提交任务时可能会出现部分不兼容情况,建议使用新的任务提交方式。
因为队列已申请quota的统计问题,存量的队列的Quota会变小。
这期间可能会出现存量队列超Quota。
存量的排队任务可能会有Quota但排队(用户可以重新按新的灵活配比方式提交这个任务)。
因为存量队列Quota变小,有可能出现一定提不到这个队列的存量负载。